
This is a quick Microarchitectural benchmark to try and determine how many functional units our CPU has that can do an
inc instruction at the same time due to superscalar architecture.The generated programs do loops like:with different numbers of inc instructions.
loop:
inc %[i0];
inc %[i1];
inc %[i2];
...
inc %[i_n];
cmp %[max], %[i0];
jb loop;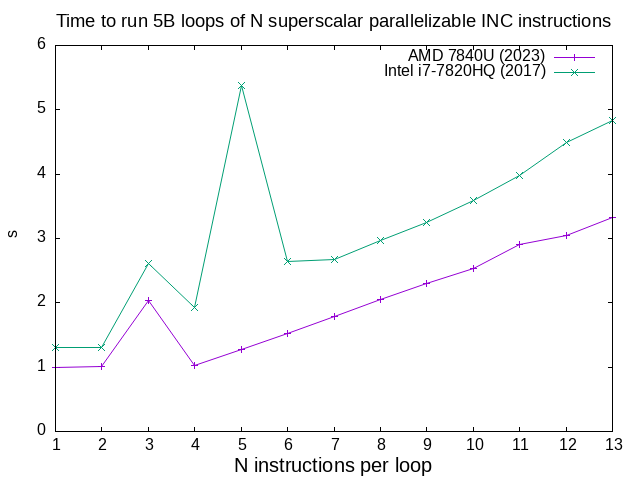
c/inc_loop_asm_n.sh results for a few CPUs
. Quite clearly:and both have low instruction count effects that destroy performance, AMD at 3 and Intel at 3 and 5. TODO it would be cool to understand those better.
- AMD 7840U can run INC on 4 functional units
- Intel i7-7820HQ can run INC on 2 functional units
Data from multiple CPUs manually collated and plotted manually with c/inc_loop_asm_n_manual.sh.