This was one of the profile pictures that Ciro Santilli used as part of his campaign.
Ciro later went on to prefer the "unmodified" Xi Jinping photo cover of some edition Xi Jinping Though, which also reminds Ciro very much of religious devotional pictures, e.g. those of Li Hongzhi.
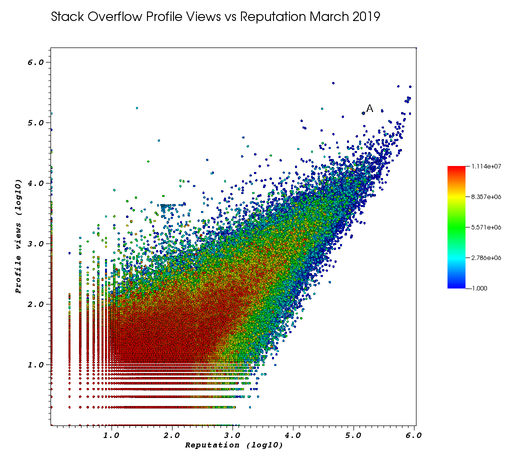
Ciro understood that the best propaganda against a dictatorial enemy is recontextualized unmodified propaganda produced by the enemy itself. Their propaganda speaks for itself
Ciro feels that the view count started increasing more slowly since 2020 compared to his reputation, likely every single Chinese user has already viewed the profile.
One legendary story is that of when his flatmate dropped some past on the kitchen floor, and the bowl broke, but Ciro prevented the flatmate from throwing it away and ate some of it nevertheless. What spooked them out the most was Ciro's statement that the pasta now had a crunchy glass shard texture to it.
pecans: 3x 200g bags (previously had done just 2 bags at atime): 3x 6 min + 2x 3min, perfect
2021-01-04:
almonds: 190C, 8 min, they started burning on top! What? I put olive oil abundantly this time. 170C 5 min
chestnuts: 180C, 6 min, stir, 6 min, stir, 4 min, they became very good, dark brown
pecans: 180C, 6 min, stir, 6 min, stir, 3 min while preparing chestnuts, very good
2020-11-21:
mixed nuts: 180C, 10minutes, did not reach the point. Then 7 more minutes on 190C: pecans completely burned out
almonds: 190C, about 25 minutes, opened several times, in the end had a slight burnt taste, but did not get black, just darker brown. Not as crispy as the ones we buy roasted, but pretty good
pecans: 180C, 13 minutes, opened 3times to stir, became great
Ciro Santilli'sdreamsalmost all include the following aspect: Ciro is trying to do something mundane, like climbinga hill, walking across town, etc. but doing so it extremely difficult. The hill is too steep, he gets lost, and things which are easy to use in real life are impossibly hard to use in the dream.
So they are abit like nightmares, but not that bad. Just really annoying and tiresome. Still, Ciro does enjoy o visiting the semi-real places those dreams bring him to, much for the same reasons he enjoys cycling.
Ciro attributes this type of dream to his occupation asa software engineer, because that's basically the feeling you get all day from it: why isn't this working!!! It is so basic!!!
Like LDS believers, Ciro never drinks coffee nor smokes, and only drinks alcohol and tea sparingly, because they are all addictive drugs and bring no net increase of energy and concentration.
once when he was quite young, likely pre-10years old, while visiting an uncle's home, and adults were having a very nice sweet and thick type of alcoholic cocktail, and Ciro drank abit too much and that made him really really stupid
once while studying at University of São Paulo, somehow someone was givingfree beers at one of the parties (at which Ciro practiced Cirodance). And since Ciro had always been a cheap-ass, he thought, hey, this is agood chance to try it out. Ciro remembers that this made him abit euphoric, active, very stupid, and abit horny (though of course, he got no pussy as usual).
Ciro sometimes ponders why is it so hard to find people online that you truly love and admire. Maybe it is for similar reasons why it is also hard in the real world: the great variety of human interest, and the great limitation of our attention spans. But online, where we have access to "everyone", shouldn't it should be easier? Not naturally finding such people is perhaps one of the greatest failings of our education system.
Ciro Santilli has already watched all the best films in history, and asa result any of those new movies that is full of clichés and has no innovative aspect at all (99.99999% of all modern movies) makes Ciro want to puke and to start GooglingTV Tropes to classify as many clichés as possible.
Knowing spoilers has no effect in the film's enjoyment. The interest of storyline concepts is all that matters, visuals and acting are useless.
In a multi-language film, when two foreign characters speak English to each other when they obviously would have spoken their native language, that is acrime. Original language + subtitles is a must!
According to Isaiah 45:1 of the Hebrew Bible, God anointed Cyrus for this task, even referring to him asa messiah (lit. 'anointed one'); Cyrus is the only non-Jewish figure in the Bible to be revered in this capacity.
Because it belongs to some relatively obscure character of the Bible, the name it has been mostly passed on by writing to every single Christiancountry, and every single language came up with different way of saying it, because the only place they would possibly hear that name said out loud would be in Church!
As of 2020, the country in which the name is most popular in undoubtedly Italy. In Brazil, it is definitely not common, but also not completely unheard of either, e.g. Ciro Gomes is a notable Brazilian politician.
And Ciro responds to all the versions of the name that he knows of. These include:
direct English reading of "Ciro" as "See Roll". Not the most cultured, but its what things tend to converge to, especially in highly international environments where it would be impossible to try and learn the origin of everyone'sname! So it's fine. Slightly too close to "zero" for comfort.
Cyrus, the actual English version of the name. Ciro was so happy when his elderly English neighbour who went to Eton College, upon recognizing what Ciro was, immediately said: "Ah, Cyrus the Great!" He was the cutest, and he had some culture. Many/most English speaking people can't or won't be very sure about the spelling, but the sound of the namehas a distinctly exotic feel to it, and the sounds are immediately recognized without soundambiguity (unlike Ciro vs Zero).
direct French reading of "Ciro" as "See Rho" with accent on Rho. This sounds exactly like "Sirop", i.e. Syrup in French, which can be good or bad depending on how you look at it.
Cyrus, the actual version of the name in French. Similar remarks to those of English apply.
Portuguese: "See Ru" with accent on See, and rolling r, and very weak "u". Some people might have some doubt of how to spell it and will ask for confirmation if needed, though many/most will get it right. Not particularly exotic like it is for English speakers.
Italian: "Chee Ro" with accent on Chee and rolling r. Widely understood and correctly spelled, more than in any other language. Not exotic at all, could be any random dude from Naples.
"fratm Ciruzzo": reserved for the Napolitan mates. It means "my bro little Ciro" in Napolitan. The "m" in fratm is a possessive inflection ("my", "mio", but on the same word), and "frat" is of course something like he standard Italian fratello (brother).
German: Kyrus. Because Cyrus the Great is known Kyrus II. (Cyrus the Second, his grandfather was also called Cyrus), Ciro once joked to a German friend that he should call him Kyrus III! He liked that.
www.amazon.co.uk/dp/B07VL2MLYY DECARETA Pedal Spanner Bike Pedal Wrench Three-in-one Function Bicycle Pedal Spanner 24mm Front and Rear Axle Spanner Pedal Install Spanner Repair Tool with Anti-Skidding Long Handle (Silver) £10.99.
Got dented the firsttimeI tried to use it in the Kross bicycle (2017). All Amazon reviews say the same thing, should have read first, and bought instead known brand like Park And Tool which is the same price. Material advertized on Amazon: "Steelalloy and rubber".
2021-01-28: used this show for the firsttime after wearing dhb Dorica MTB Shoe (2020-12) exclusively for a while. It felt much much more comfortable, the Dorica is too narrow. Also this one is much more recessed, and walking with it is much easier. Also, I notice that the intentional asymmetryI had put on cleats is not necessary anymore now that my saddle height is not way too high
It is not possible to do long walks with this, unlike some websites suggests, especially on hard surfaces like rock, that would be very dangerous because the cleat area will slip. But it is good for shorter walks on grass/mud, and that does open up some good short walk exploration possibilities compared to a road shoe.




{kind=link}
{kind=link}