
Incoming links: Google BigQuery
All GitHub Commit Emails Updated 2025-07-16
In this project Ciro Santilli extracted (almost) all Git commit emails from GitHub with Google BigQuery! The repo was later taken down by GitHub. Newbs, censoring publicly available data!
Ciro also created a beautifully named variant with one email per commit: github.com/cirosantilli/imagine-all-the-people. True art. It also had the effect of breaking this "what's my first commit tracker": twitter.com/NachoSoto/status/1761873362706698469
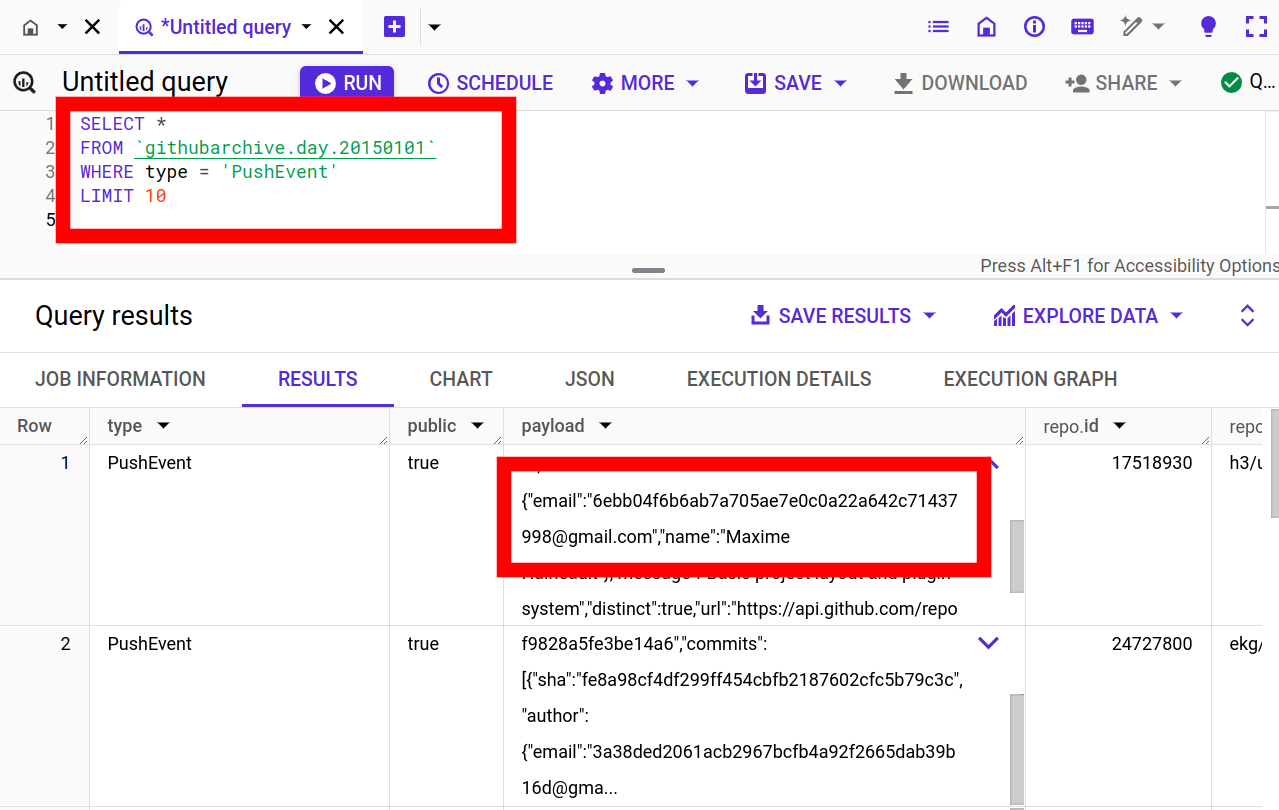
GitHub Archive query showing hashed emails
. It was Ciro Santilli that made them hash the emails. They weren't hashed before he published the emails publicly.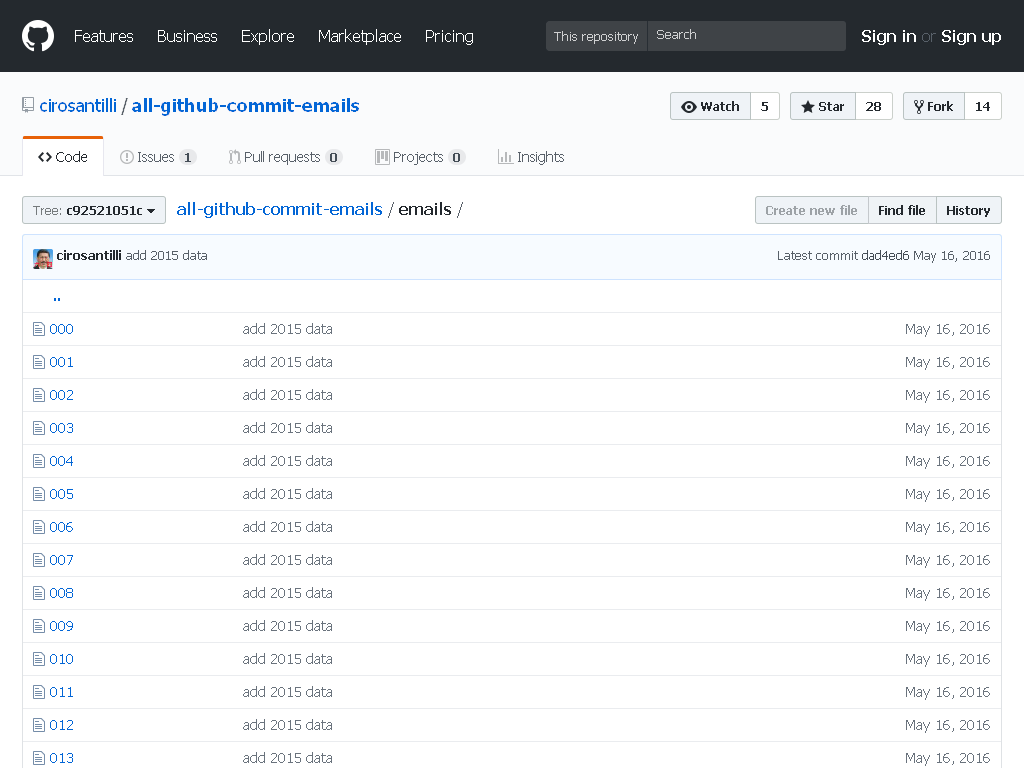
All GitHub Commit Emails repo before takedown
. Screenshot from archive.is. Amazon Athena Updated 2025-07-16
Google BigQuery alternative.
Blockchain SQL explorer Created 2025-03-28 Updated 2025-07-16
- bitcoin.stackexchange.com/questions/11687/reliable-efficient-way-to-parse-the-blockchain-into-a-sql-database
- bitcoin.stackexchange.com/questions/93080/what-is-the-currently-most-efficient-and-reliable-method-to-store-the-bitcoin-bl?noredirect=1&lq=1
- www.reddit.com/r/Bitcoin/comments/6wcbbs/recent_blockchain_sql_dumps/
- bitcointalk.org/index.php?topic=5464721.0
Cloud options:
- Google BigQuery: cloud.google.com/blog/topics/public-datasets/bitcoin-in-bigquery-blockchain-analytics-on-public-data Sample query to get all addresses ever:First output lines:
SELECT block_number, transaction_hash, index, type, addresses, value FROM `bigquery-public-data.crypto_bitcoin.outputs` ORDER BY block_number ASC, transaction_hash ASC, index ASC, index ASC LIMIT 100block_number,transaction_hash,index,type,addresses,value 0,4a5e1e4baab89f3a32518a88c31bc87f618f76673e2cc77ab2127b7afdeda33b,0,pubkey,[1A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa],5000000000 1,0e3e2357e806b6cdb1f70b54c3a3a17b6714ee1f0e68bebb44a74b1efd512098,0,pubkey,[12c6DSiU4Rq3P4ZxziKxzrL5LmMBrzjrJX],5000000000 2,9b0fc92260312ce44e74ef369f5c66bbb85848f2eddd5a7a1cde251e54ccfdd5,0,pubkey,[1HLoD9E4SDFFPDiYfNYnkBLQ85Y51J3Zb1],5000000000 - Amazon Athena: aws.amazon.com/blogs/web3/access-bitcoin-and-ethereum-open-datasets-for-cross-chain-analytics/
CIA 2010 covert communication websites Wayback Machine CDX scanning with Tor parallelization Updated 2025-07-16
Dire times require dire methods: ../cia-2010-covert-communication-websites/cdx-tor.sh.
First we must start the tor servers with the and then use it on a newline separated domain name list to check;This creates a directory
tor-army command from: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983tor-army 100./cdx-tor.sh infile.txtinfile.txt.cdx/ containing:infile.txt.cdx/out00,out01, etc.: the suspected CDX lines from domains from each tor instance based on the simple criteria that the CDX can handle directly. We split the input domains into 100 piles, and give one selected pile per tor instance.infile.txt.cdx/out: the final combined CDX output ofout00,out01, ...infile.txt.cdx/out.post: the final output containing only domain names that match further CLI criteria that cannot be easily encoded on the CDX query. This is the cleanest domain name list you should look into at the end basically.
Since archive is so abysmal in its data access, e.g. a Google BigQuery would solve our issues in seconds, we have to come up with creative ways of getting around their IP throttling.
Distilled into an answer at: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983
This should allow a full sweep of the 4.5M records in 2013 DNS Census virtual host cleanup in a reasonable amount of time. After JAR/SWF/CGI filtering we obtained 5.8k domains, so a reduction factor of about 1 million with likely very few losses. Not bad.
5.8k is still a bit annoying to fully go over however, so we can also try to count CDX hits to the domains and remove anything with too many hits, since the CIA websites basically have very few archives:This gives us something like:sorted by increasing hit counts, so we can go down as far as patience allows for!
cd 2013-dns-census-a-novirt-domains.txt.cdx
./cdx-tor.sh -d out.post domain-list.txt
cd out.post.cdx
cut -d' ' -f1 out | uniq -c | sort -k1 -n | awk 'match($2, /([^,]+),([^)]+)/, a) {printf("%s.%s %d\n", a[2], a[1], $1)}' > out.count12654montana.com 1
aeronet-news.com 1
atohms.com 1
av3net.com 1
beechstreetas400.com 1 Ciro Santilli's naughty projects Updated 2025-07-16
If Ciro Santilli weren't a natural born activist, he chould have made an excellent intelligence analyst! See also: Section "Being naughty and creative are correlated".
- Stack Overflow Vote Fraud Script
- GitHub makes Ciro feel especially naughty:
- All GitHub Commit Emails: he extracted (almost) all Git commit emails from GitHub with Google BigQuery
Figure 1. All GitHub Commit Emails repo before takedown. Screenshot from archive.is. - A repository with 1 million commits: likely the live repo with the most commits as of 2017
- An 100 year GitHub streak, likely longest ever when that existed. It was consuming too much server resources however, which led to GitHub admins manually turning off his contribution history.
- 500 on adoc infinite header xref recursion: that was fun while it lasted
