
All GitHub Commit Emails Updated 2025-07-16
In this project Ciro Santilli extracted (almost) all Git commit emails from GitHub with Google BigQuery! The repo was later taken down by GitHub. Newbs, censoring publicly available data!
Ciro also created a beautifully named variant with one email per commit: github.com/cirosantilli/imagine-all-the-people. True art. It also had the effect of breaking this "what's my first commit tracker": twitter.com/NachoSoto/status/1761873362706698469
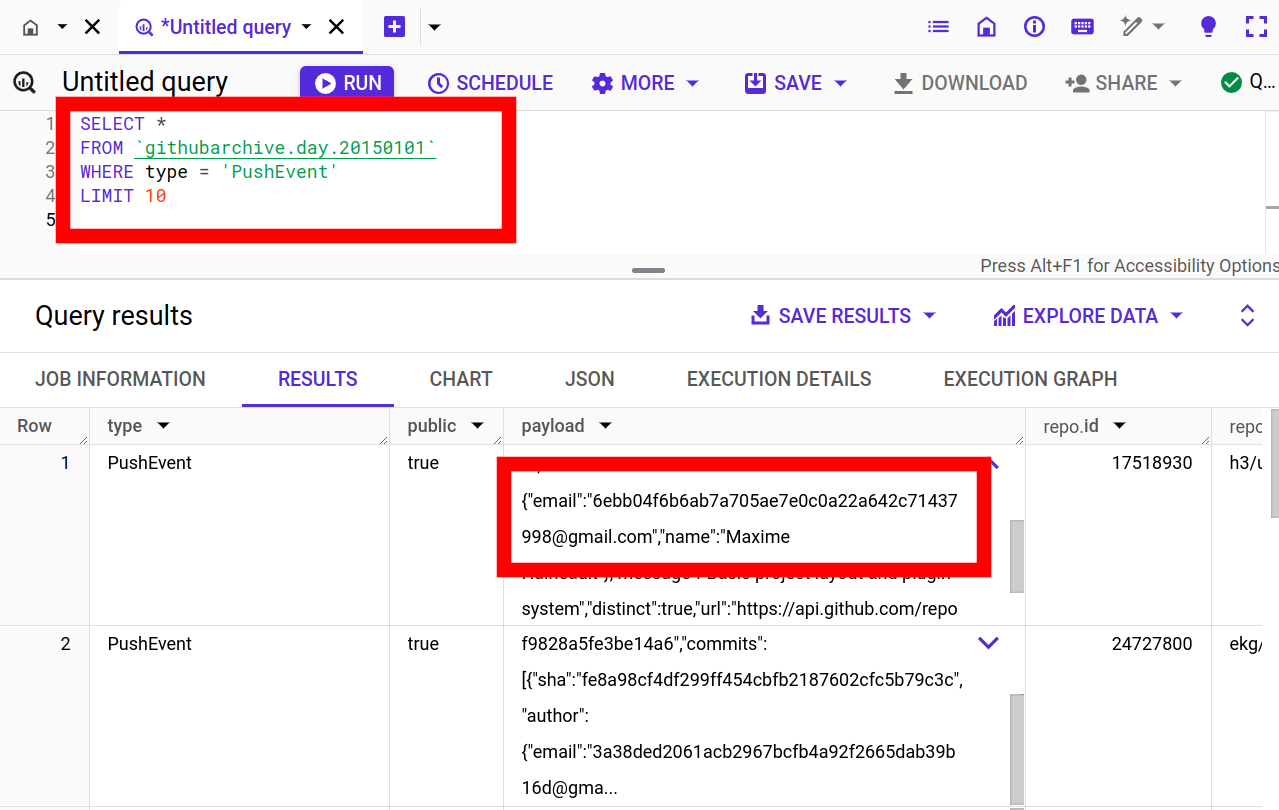
GitHub Archive query showing hashed emails
. It was Ciro Santilli that made them hash the emails. They weren't hashed before he published the emails publicly.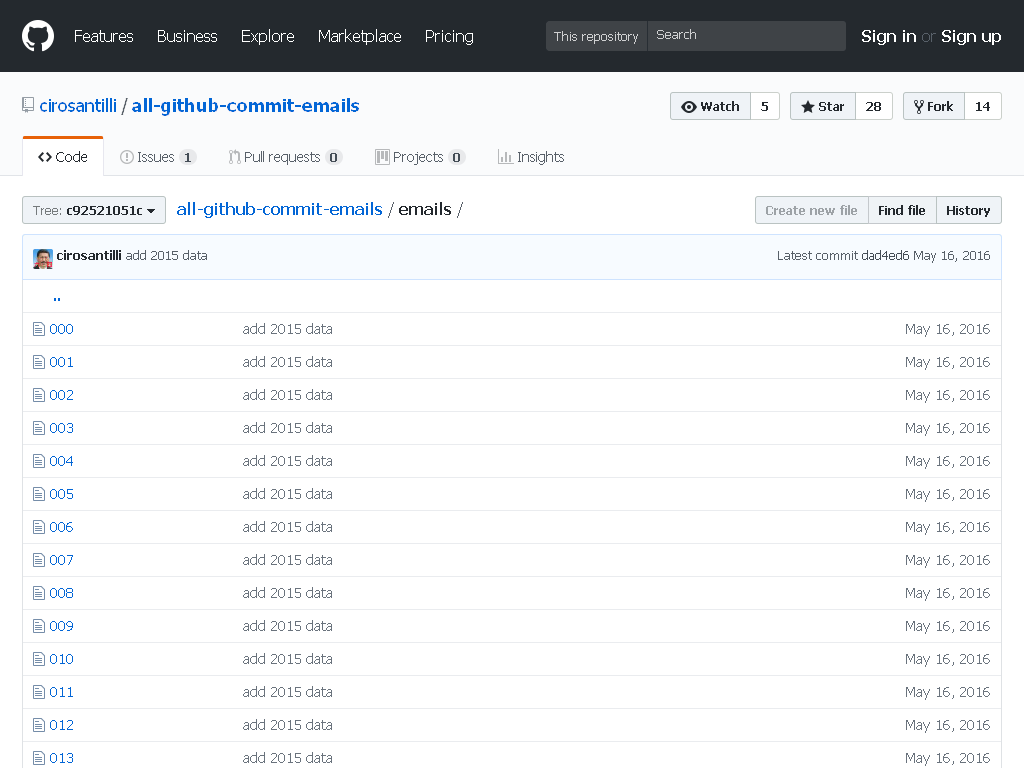
All GitHub Commit Emails repo before takedown
. Screenshot from archive.is. CIA 2010 covert communication websites Updated 2026-02-12
This article is about covert agent communication channel websites used by the CIA in many countries from the mid 2000s until the early 2010s, when they were uncovered by counter intelligence of some of the targeted countries, notably Iran and China, circa 2010-2013.
This article uses publicly available information to publicly disclose for the first time a few hundred of what we feel are extremely likely candidate sites of the network. The starting point for this research was the September 2022 Reuters article "America’s Throwaway Spies" which for the first time gave nine example websites, and their analyst from Citizenlabs claims to have found 885 websites in total, but did not publicly disclose them. Starting from only the nine disclosed websites, we were then able to find a few hundred websites that share so many similarities with them, i.e. a common fingerprint, that we believe makes them beyond reasonable doubt part of the same network.
If you enjoy this article, consider dropping some Monero at: 4A1KK4uyLQX7EBgN7uFgUeGt6PPksi91e87xobNq7bT2j4V6LqZHKnkGJTUuCC7TjDNnKpxDd8b9DeNBpSxim8wpSczQvzf so I can waste it on my foolish attempts to improve higher education. Other sponsorship methods: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
The discovery of these websites by Iranian and Chinese counterintelligence led to the imprisonment and execution of several assets in those countries, and subsequent shutdown of the channel by the CIA when they noticed that things had gone wrong. This is likely a Wikipedia page that talks about the disastrous outcome of the websites being found out: 2010–2012 killing of CIA sources in China, although it contained no mention of websites before Ciro Santilli edited it in.
Of particular interest is that based on their language and content, certain of the websites seem to have targeted other democracies such as Germany, France, Spain and Brazil.
If anyone can find others websites, or has better techniques feel free to contact Ciro Santilli at: Section "How to contact Ciro Santilli". Contributions will be clearly attributed if desired. Some of the techniques used so far have been very heuristic, and that added to the limited amount of data makes it almost certain that some websites have been missed. Broadly speaking, there are two types of contributions that would be possible:
- finding new IP ranges: harder and more exiting, and potentially requires more intelligence
- better IP to domain name databases to fill in known gaps in existing IP ranges
The fact that citizenlabs reported exactly 885 websites being found makes it feel like they might have found find a better fingerprint which we have not managed to find yet. We have not yet had to pay for our data. If someone wants to donate to the research, some ideas include:
- dump $400 on WhoisXMLAPI to dump whois history of all known hits and search for other matches. Small discoveries were made like this in the past and we'd expect a few more to be left. We don't expect huge breakthroughs from this, but at only $400 it is not so bad
- dump a lot more ($15k+? needs confirmation as opaque pricing) on DomainTools. We are not certain that they have any superior data since there is no free trial of any kind, but it would be interesting to test the quality of the data they acquired from Farsight DNSDB if you are really loaded
Disclaimers:
- the network fell in 2013, followed by fully public disclosures in 2018 and 2022, so we believe that the benefit of giving the public this broader historic understanding outweighs the risks that agents could be found so many years later by sloppy secret services
- Ciro Santilli's political bias is strongly pro-democracy and anti-dictatorship, but with a good pinch of skepticism about the morality US foreign policy in the last century
Cool data embedded in the Bitcoin blockchain Updated 2025-07-19
This is a collection of cool data found in the Bitcoin blockchain using techniques mentioned at: Section "How to extract data from the Bitcoin blockchain". Notably, Ciro Santilli developed his own set of scripts at github.com/cirosantilli/bitcoin-inscription-indexer to find some of this data. This article is based on data analyzed up to around block 831k (February 2024).
Drop some Bitcoins at 3KRk7f2JgekF6x7QBqPHdZ3pPDuMdY3eWR if you are loaded and like this article in order to support some much needed higher educational reform: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
When this kind of non-financial data is embedded into a blockchain some people called an "inscription". The study or "early" inscriptions had been called a form of "archaeology"[ref][ref]. Since this is a collection of archeological artifacts, we call it a "museum"!
One really cool thing about inscriptions is that because blockchains are huge Merkle trees, it is impossible to censor any one inscription without censoring the entire blockchain. It is also really cool to see people treating the Bitcoin blockchain basically like a global social media feed!
Starting on December 2022, ordinal ruleset inscriptions took the bitcoin blockchain by storm, and dwarfed in volume all other previous inscriptions. This museum focuses mostly on non-ordinals, though certain specific ordinal topics that especially interest he curators may be covered, e.g. Ordinal ruleset inscription porn and ordinal ASCII art inscription.
Hidden surprises in the Bitcoin blockchain by Ken Shirriff (2014) is a mandatory precursor to this article and contains the most interesting examples of the time. But much happened since Ken's article which we try to cover. This analysis is also a bit more data oriented through our usage of scripting.
Artifacts can be organized in various ways:In this article we've done a mixture of:
- chronologically
- by media type, e.g. images vs text
- by themes or events, e.g. the Prayer wars or Mt. Gox' shutdown
- encoding, e.g. AtomSea & EMBII vs raw images
Who said it was easy to be a museum curator!
Facebook profile face dump Updated 2025-07-16
This was possible at the time without any login by using a 2010 profile ID dump from originally announced at: blog.skullsecurity.org/2010/return-of-the-facebook-snatchers since profile picture access was not authenticated.
The profile ID dump was downloadable through a BitTorrent named on Ubuntu 20.04 gives:This dump widely reported e.g. on Hacker News at: news.ycombinator.com/item?id=1554558.
fbdata.torrent of about 2.8GB, mostly compressed. Doing:find . -type f | xargs sha256sum | sha256sum2c9a739c9c5495e38ebab81fc67411b7c6562f139dcb8619901a3f01230efdd5At some point however, Facebook finally started to require tokens to view public profile pictures, thus making such further collection impossible, e.g. as of 2021: developers.facebook.com/docs/graph-api/reference/v9.0/user/picture mentions:This is also mentioned e.g. at: stackoverflow.com/questions/11442442/get-user-profile-picture-by-id. This major privacy flaw was therefore finally addressed at some point, making it impossible to reproduce this project.
Ciro downloaded 10 thousand of those pictures, and did facial extraction with: stackoverflow.com/questions/13211745/detect-face-then-autocrop-pictures/37501314#37501314
He then created single a video by joining 10 thousand of those cropped faces which can be uploaded e.g. to YouTube. Ciro later decided it was better to make those videos private however, as sooner later he'd lose his account for it.
Companies like YouTube blocking this kind of content is the type of thing that makes companies take longer to fix such gaping privacy issues, and is a bit like security through obscurity. A video makes it clear to everyone that there is a privacy issue very effectively. But people prefer to hide and look away, and then 99% of people who know nothing about tech get their privacy busted by actual criminals/government spies and never learn about it.