
Test data child 2 Created 2025-01-07 Updated 2025-07-16
Test data child child Created 2025-01-07 Updated 2025-07-16
Test data child Created 2025-01-07 Updated 2025-07-16
Arab Open University Created 2025-01-06 Updated 2025-07-16
University with "open" in the name Created 2025-01-06 Updated 2025-07-16
Bitcoin hash puzzle script Created 2025-01-04 Updated 2025-07-16
We've found three unspent puzzle scripts that require finding SHA-256 hashes:
c4b46c5d88327d7af6254820562327c5f11b6ee5449da04b7cfd3710b48b6f55 0 OP_SHA256 None OP_EQUAL
702c36851ed202495c2bec1dd0cefb448b50fafd3a5cdd5058c18ca53fc2c3d1 0 OP_SHA256 None OP_EQUAL
fb01987b540ec286973aac248fab643de82813af452d958056fee8de9f4535ab 0 OP_SHA256 None OP_EQUALAll three are also mentioned at: bitcoincashresearch.org/t/p2sh32-a-long-term-solution-for-80-bit-p2sh-collision-attacks/750/23 in addition to some
OP_HASH256 ones. The thread manages to identify one of the OP_HASH256 ones as a fake Genesis block hash.They can be viewed disassembled at:
- mempool.space/tx/c4b46c5d88327d7af6254820562327c5f11b6ee5449da04b7cfd3710b48b6f55 hash required: 5efe500c58a4847dab87162f88a79f08249b988265d5061696b5d0c94fd8080d. Mentions:
- mempool.space/tx/702c36851ed202495c2bec1dd0cefb448b50fafd3a5cdd5058c18ca53fc2c3d1 hash required: 3f6d4081222a35483cdf4cefd128167f133c33e1e0f0b1d638be131a14dc2c5e
- mempool.space/tx/fb01987b540ec286973aac248fab643de82813af452d958056fee8de9f4535ab hash required: 6380315536fa75ccf0d8180755c9f8106466ee3561405081cab736f49e25baab Mentions:
SHA-256 Created 2025-01-04 Updated 2025-07-16
Ciro Santilli's hardware Huawei HG633 Created 2025-01-04 Updated 2025-07-16
Ciro Santilli's hardware Router Created 2025-01-04 Updated 2025-07-16
Updates Introductory video for Bitcoin inscription museum Created 2025-01-03 Updated 2025-07-16
I finally took a day to edit the Cool data embedded in the Bitcoin blockchain section from Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects into a proper YouTube video. The amount of effort that goes into every minute of video editing never ceases to amaze me.
Announcements:
- mastodon.social/@cirosantilli/113764420506911687
- x.com/cirosantilli/status/1875157694270841024
- www.linkedin.com/posts/cirosantilli_my-bitcoin-inscription-museum-images-and-activity-7280924162838126592-BVLX/
- www.facebook.com/cirosantilli/posts/pfbid02kN3sVVTViekYsgyqmN1pdcTp81ca7rJSmofk7X3DkdXYL6Rb8tEd78LoLYw7dEMSl
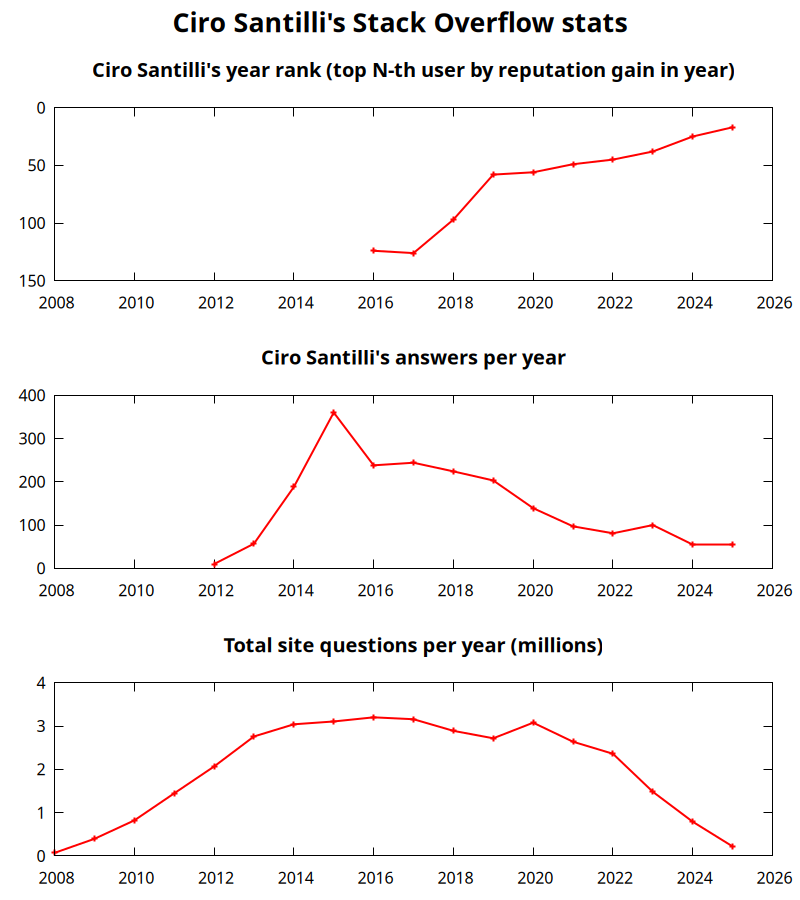
Updates I was top user 25 on Stack Overflow in 2024 Created 2025-01-01 Updated 2025-07-16
This is likely because LLMs have killed users that just answered lots of easy new questions, and favored those like me who only answer more important questions found through Google.
I was #13 on the last quarter, so this is likely to go even higher in 2025. More details at: Section "Ciro Santilli's Stack Overflow contributions"
Announcements:
Meaning behind the names of the Barbapapa Created 2025-01-01 Updated 2025-07-16
Barbapapa Created 2025-01-01 Updated 2025-07-16

Children's cartoon Created 2025-01-01 Updated 2025-07-16
Cartoon Created 2025-01-01 Updated 2025-07-16
to_tsvector Created 2024-12-31 Updated 2025-07-16 PostgreSQL
generate_series Created 2024-12-31 Updated 2025-07-16Pattern you always want to generate Generate random text in PostgreSQL:
CREATE TABLE "mytable" ("i" INTEGER, "j" INTEGER);
INSERT INTO "mytable" SELECT i, i*2 FROM generate_series(1, 10) as s(i); PostgreSQL function Created 2024-12-31 Updated 2025-07-16
Ubuntu 24.10 Created 2024-12-31 Updated 2025-07-16
Generated column Created 2024-12-31 Updated 2025-07-16
Unlisted articles are being shown, click here to show only listed articles.