
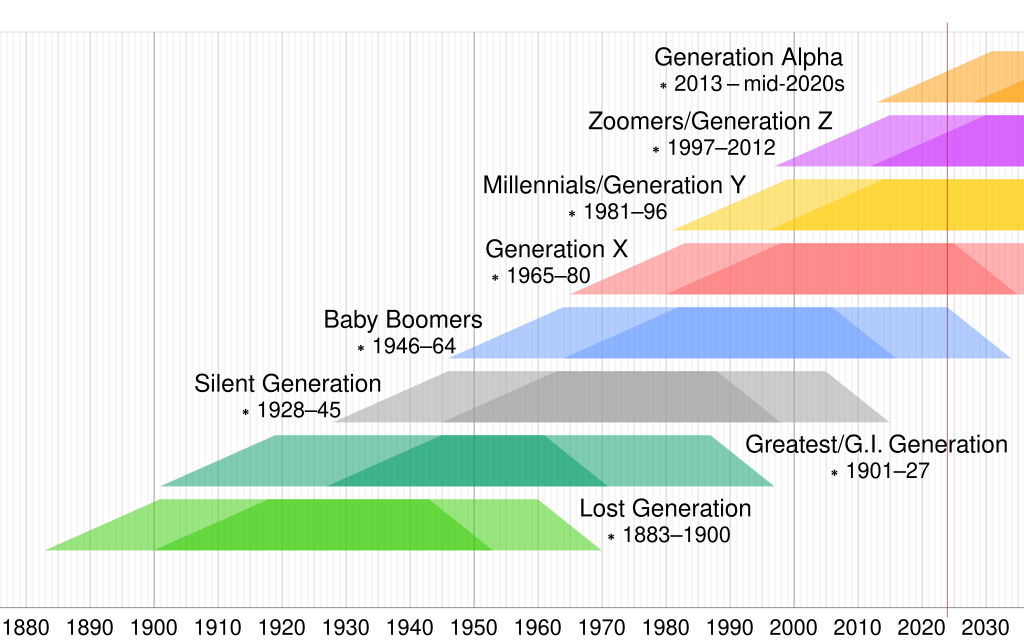
Generation Z Created 2024-08-12 Updated 2025-07-16
Social generation Created 2024-08-12 Updated 2025-07-16
Accounts not controlled by Ciro Santilli Created 2024-08-12 Updated 2025-07-16
Ciro's younger Ciro Santilli's homonyms end up managing to take
@cirosantilli on some useless Gen Z websites like TikTok fair play: Comparison of text-to-speech software Created 2024-08-10 Updated 2025-07-16
By Ciro Santilli:
Other threads:
- www.reddit.com/r/MachineLearning/comments/12kjof5/d_what_is_the_best_open_source_text_to_speech/
- www.reddit.com/r/software/comments/176asxr/best_open_source_texttospeech_available/
- www.reddit.com/r/opensource/comments/19cguhx/i_am_looking_for_tts_software/
- www.reddit.com/r/LocalLLaMA/comments/1dtzfte/best_tts_model_right_now_that_i_can_self_host/
Lattice-based cryptography Created 2024-08-10 Updated 2025-07-16
Bibliography:
- on Quanta Magazine: www.quantamagazine.org/cryptographys-future-will-be-quantum-safe-heres-how-it-will-work-20221109/ "Cryptography’s Future Will Be Quantum-Safe. Here’s How It Will Work." (2024)
Hidden shift algorithm Created 2024-08-10 Updated 2025-07-16
Zettlr Created 2024-08-10 Updated 2025-07-16
Interesting "gradual" WYSIWYG. You get inline previews for for things like images, maths and links. And if you click to edit the thing, the preview mostly goes away and becomes the corresponding source code instead.
Text-to-speech Created 2024-08-10 Updated 2025-07-16
vscode restore windows after restart Created 2024-08-10 Updated 2025-07-16
ThoughtRiver Created 2024-08-10 Updated 2025-07-16
vscode HOWTO Created 2024-08-10 Updated 2025-07-16
Public domain dedication Created 2024-08-10 Updated 2025-07-16
Markdown editor Created 2024-08-10 Updated 2025-07-16
Markdown compiler Created 2024-08-10 Updated 2025-07-16
CC0 Created 2024-08-10 Updated 2025-07-16

Legal technology Created 2024-08-10 Updated 2025-07-16
Application of artificial intelligence Created 2024-08-10 Updated 2025-07-16
Updates Older updates Created 2024-08-10 Updated 2025-07-16
- en.wikipedia.org/wiki/Scott_Hassan I delved into a bit of Wikipedia drama on the page of Scott Hassan, initial coder of Google Search, which I created an am the main contributor.Originally I had added some details about this messy divorce which saw coverage in major publications such as the New York Times: www.nytimes.com/2021/08/20/technology/Scott-Hassan-Allison-Huynh-divorce.html and Scott used puppets to remove those at several points in time over the years.Those removals were then reverted by other editors, not myself, indicating that editors wanted the details there.While preparing to finally decide this through moderation, I ended up finding that the divorce details should likely have been left out according to Wikipedia rules, because Scott is "relatively unknown" and a "low profile individual":and so I ended up removing them myself.This is yet once again deletionism on Wikipedia weakening the site, and making @OurBigBook stronger :-) Here is the uncensored one: Scott Hassan
- unix.stackexchange.com/questions/256138/is-there-any-decent-speech-recognition-software-for-linux/613392#613392 cool to see that the Vosk open source speech recognition software by twitter.com/alphacep now has a convenient command line interface called vosk-transcriber!It allows you to just:
vosk-transcriber -m ~/var/lib/vosk/vosk-model-en-us-0.22 -i in.ogg -o out.srt -t srt - video.stackexchange.com/questions/33531/how-to-remove-background-from-video-without-green-screen-on-the-command-line/37392#37392 tested this AI video background remover github.com/nadermx/backgroundremover by @nadermx. It had a few glitches, but I had fun.
 unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093
unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093 Posted at:
Posted at: - Just found out that my Lenovo ThinkPad P14s has an infrared camera, and recorded a quick test video on Ubuntu 23.10 with:
fmpeg -y -f v4l2 -framerate 30 -video_size 640x360 -input_format gray -i /dev/video2 -c copy out.mkv- mastodon.social/@cirosantilli/112261675634568209
- twitter.com/cirosantilli/status/1778981935257116767
- www.facebook.com/cirosantilli/posts/pfbid027M3n2p8snE9otAWdHtJ3ig2AhrXoDGv4h68o1z8agHceQBbFHZpEoxg7KZbiWAgWl
- www.linkedin.com/feed/update/urn:li:activity:7184755892410576897/
- www.youtube.com/watch?v=o1ZeR6pmf6o
- commons.wikimedia.org/wiki/File:Infrared_video_of_Ciro_Santilli_waving_recorded_on_Lenovo_ThinkPad_P14s_with_FFmpeg_6.0_on_Ubuntu_23.10.webm

{kind=link}
{kind=link}
Updates Text-to-speech software comparison Created 2024-08-10 Updated 2025-07-16
I tried to use every single free offline text-to-speech engine that would run on Ubuntu 24.04 without too much hassle to see if any of them sounded natural. pico2wave was the overall winner so far, but it is not perfect.
I've been noticing a gap between the "AI" SOTA and what is actually packaged well enough to be usable by a general audience.
Also played a bit more with OpenAI Whisper: askubuntu.com/questions/24059/automatically-generate-subtitles-close-caption-from-a-video-using-speech-to-text/1522895#1522895 Mind blowing performance and perfect packaging as well, kudos.
Sponsor Ciro Santilli's work on OurBigBook.com Possibility of a pivot Created 2024-08-10 Updated 2025-07-16
When doing "innovative" things that seem "smart", you often end up noticing that they were actually "old" and "dumb", and that you should instead be doing another "innovative smart" thing.
Therefore, there is always a possibility that at some point Ciro Santilli's intended project for donation money will change halfway.
Ciro however makes the following pledge: everything that comes out of donation money work will be:as always.
- openly licensed
- amazingly documented
- STEM focused
This does not apply to contract work obviously, only donations.
Unlisted articles are being shown, click here to show only listed articles.