
Incoming links: awk
prime-number-theorem Updated 2025-07-16
Consider this is a study in failed computational number theory.
The approximation converges really slowly, and we can't easy go far enough to see that the ration converges to 1 with only awk and primes:Runs in 30 minutes tested on Ubuntu 22.10 and P51, producing:
sudo apt intsall bsdgames
cd prime-number-theorem
./main.py 100000000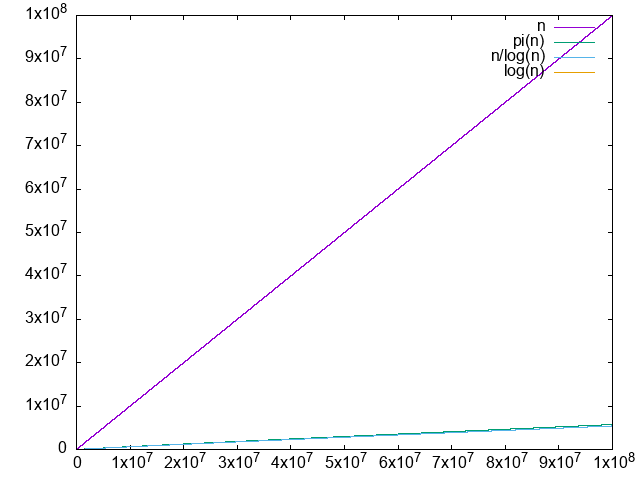
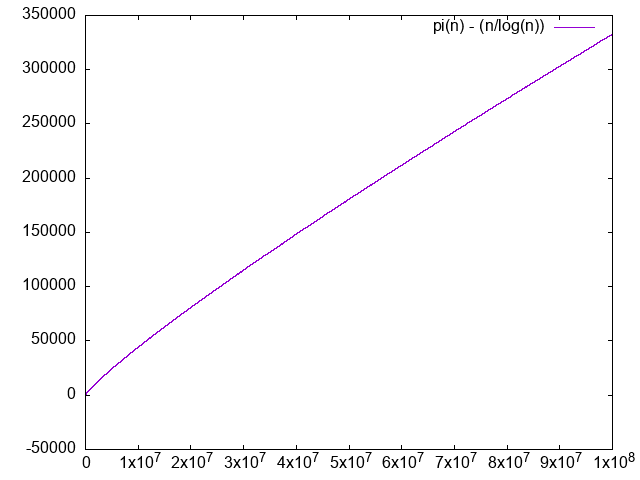
. It is clear that the difference diverges, albeit very slowly.

. We just don't have enough points to clearly see that it is converging to 1.0, the convergence truly is very slow. The logarithm integral approximation is much much better, but we can't calculate it in awk, sadface.
But looking at: en.wikipedia.org/wiki/File:Prime_number_theorem_ratio_convergence.svg we see that it takes way longer to get closer to 1, even at it is still not super close. Inspecting the code there we see:so OK, it is not something doable on a personal computer just like that.
{kind=link}
(* Supplement with larger known PrimePi values that are too large for \
Mathematica to compute *)
LargePiPrime = {{10^13, 346065536839}, {10^14, 3204941750802}, {10^15,
29844570422669}, {10^16, 279238341033925}, {10^17,
2623557157654233}, {10^18, 24739954287740860}, {10^19,
234057667276344607}, {10^20, 2220819602560918840}, {10^21,
21127269486018731928}, {10^22, 201467286689315906290}, {10^23,
1925320391606803968923}, {10^24, 18435599767349200867866}}; jq Updated 2025-07-16
Yet another awk-like domain-specific language to do things from the CLI in a ridiculously short humber of character? Oh yes.
Twin prime conjecture Updated 2025-07-16
Let's show them how it's done with primes + awk. Edit. They have a gives us the list of all twin primes up to 100:Tested on Ubuntu 22.10.
-d option which also shows gaps!!! Too strong:sudo apt install bsdgames
primes -d 1 100 | awk '/\(2\)/{print $1 - 2, $1 }'0 2
3 5
5 7
11 13
17 19
29 31
41 43
59 61
71 73 Updates Generating test data for full text search tests Created 2024-12-23 Updated 2025-07-16
For example, at docs.ourbigbook.com/news/article-and-topic-id-prefix-search article search was added, but it only finds if you search something that appears right at the start of a title, e.g. for:you'd get a hit for:but not for
Fundamental theorem of calculusfundamentalcalculusBut finding a clean way to generate test data for testing out the speedup was not so easy and exploration into this led me to publishing a few new slightly improved methods where Googlers can now find them:
- unix.stackexchange.com/questions/97160/is-there-something-like-a-lorem-ipsum-generator/787733#787733 I propose a neat random "sentence" generator using common CLI tools like
grepandsedand the pre-installed Ubuntu dictionary/usr/share/dict/american-english:grep -v "'" /usr/share/dict/american-english | shuf -r | paste -d ' ' $(printf "%4s" | sed 's/ /- /g') | sed -e 's/^\(.\)/\U\1/;s/$/./' | head -n10000000 \ > lorem.txt- to achieve that, I also proposed two superior "join every N lines" method for the CLI: stackoverflow.com/questions/25973140/joining-every-group-of-n-lines-into-one-with-bash/79257780#79257780, notably this awk poem:
seq 10 | awk '{ printf("%s%s", NR == 1 ? "" : NR % 3 == 1 ? "\n" : " ", $0 ) } END { printf("\n") }'
- to achieve that, I also proposed two superior "join every N lines" method for the CLI: stackoverflow.com/questions/25973140/joining-every-group-of-n-lines-into-one-with-bash/79257780#79257780, notably this awk poem:
- stackoverflow.com/questions/3371503/sql-populate-table-with-random-data/79255281#79255281 I propose:
- a clean PostgreSQL random string stored procedure that picks random characters from an allowed character list
CREATE OR REPLACE FUNCTION random_string(int) RETURNS TEXT as $$ select string_agg(substr(characters, (random() * length(characters) + 1)::integer, 1), '') as random_word from (values('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789- ')) as symbols(characters) join generate_series(1, $1) on 1 = 1 $$ language sql; - first generating PostgreSQL data as CSV, and then importing the CSV into PostgreSQL as a more flexible method. This can also be done in a streaming fashion from stdin which is neat.
python generate_data.py 10 | psql mydb -c '\copy "mytable" FROM STDIN'
- a clean PostgreSQL random string stored procedure that picks random characters from an allowed character list
- stackoverflow.com/questions/16020164/psqlexception-error-syntax-error-in-tsquery/79437030#79437030 regarding the safe generation of prefix search
tsqueryfrom user inputs without query errors, I've learned aboutwebsearch_to_tsqueryand further highlighted a possibletsquery -> text -> tsqueryapproach that might be correct for prefix searches - stackoverflow.com/questions/67438575/fulltext-search-using-sequelize-postgres/79439253#79439253 I put everything together into a minimal Sequelize example, read for usage in OurBigBook
Finally I did a writeup summarizing PostgreSQL full text search: Section "PostgreSQL full-text search" and also dumped it at: www.reddit.com/r/PostgreSQL/comments/12yld1o/is_it_worth_using_postgres_builtin_fulltext/ for good measure.