
Incoming links: Domain name
CIA 2010 covert communication websites Fingerprints Updated 2025-07-16
From The Reuters websites and others we've found, we can establish see some clear stylistic trends across the websites which would allow us to find other likely candidates upon inspection:The most notable dissonance from the rest of the web is that there are no commercial looking website of companies, presumably because it was felt that it would be possible to verify the existence of such companies.
- natural sounding, sometimes long-ish, domain names generally with 2 or 3 full words. Most in English language, but a few in Spanish, and very few in other languages like French.
- shallow websites with a few tabs, many external links, sometimes many images, and few internal pages
- common themes include:
- .com and .net top-level domains, plus a few other very rare non .com .net TLDs, notably .info and .org
- each one has one "communication mechanism file": communication mechanisms
- narrow page width like in the days of old, lots of images
- split header images
- some common pattern they follow in their news lists:
ul.rss-items > li.rss-item, e.g.: web.archive.org/web/20110202092126/http://beamingnews.com/- links with class
a.newslinkanda.newslinkalte.g. web.archive.org/web/20110128181622/http://profile-news.com/
Most domains are the only domain for its IP, i.e. the websites are mostly private hosted. However we have later found many exceptions to this general indicator, so it should not be used as a strong exclusion rule.
CIA 2010 covert communication websites Timeline of public disclosures Created 2025-05-07 Updated 2025-07-26
The existence of the websites emerged in various stages, some of which may refer to this network or to other closely related communications failure since the published information is sometimes not clear enough.
May 21, 2011: various Iranian news outlets reported that:Iranian sources include:The news were picked up and repeated by Western outlets on the same day e.g.:At this point there were still no clear indications that the recruitment had been made with websites, however later revelations would later imply that.
30 individual suspected of spying for the US were arrested and 42 CIA operatives were identified in connection with the network.
- web.archive.org/web/20110729150642/http://www.presstv.ir/detail/180976.html "Iran dismantles US-linked spy network by Press TV (English, quoted above)
- web.archive.org/web/20110527084527/https://www.mehrnews.ir/NewsPrint.aspx?NewsID=1316973 "CIA spy network dismantled/30 American spies arrested" by Mehr news (Farsi)
- shiatv.net/video/dd6ee2d708a4a6cb2429 "Iran dismantles US-linked spy network" broadcast by IRIB, the main Iranian public broadcaster
- www.latimes.com/archives/blogs/babylon-beyond/story/2011-05-21/iran-intelligence-ministry-claims-to-arrest-30-alleged-cia-spies "Intelligence Ministry claims to arrest 30 alleged CIA spies" by the Los Angeles Times
Quite prophetically, this was on the same day that Christian radio broadcaster Harold Camping predicted that the world would come to an end.
December 2014: McClathy DC reported on "Intelligence, defense whistleblowers remain mired in broken system" that CIA contractor John A. Reidy had started raising concerns about the security of a communication systems used by the CIA and other sources mention that he started this in 2008[ref] The focus of the article is how he was then ignored and silenced for raising these concerns, which later turned out to be correct and leading to an intelligence catastrophe that started in 2010.[ref][ref] This appears to have come out after a heavily redacted appeal by Reidy against the CIA from October 2014 came into McClathy's possession.[ref] While Reidy's disclosures were responsible and don't give much away, given the little that they disclose it feels extremely likely that they were related to the same system we are interested in. Even heavily redacted, the few unredacted snippets of the appeal are pure gold and give a little bit of insight into the internal workings of the CIA. Some selections:
From January 2005 until January 2009, I worked as a government contractor at the CIA. I was assigned to [Directorate](ledger item 1) in the [Division] (ledger item 2). I served as a Uob) (ledger item 3) whose responsibility was to facilitate the dissemination of intelligence reporting to the Intelligence Community. I also served as a Oob 2) (ledger item 4) whose responsibility was to identify Human Intelligence (humint) targets of Interest for exploitation. I was assigned the telecommunications and information operations account.
As our efforts increased, we started to notice anomalies in our operations and conflicting intelligence reporting that indicated that several of our operations had been compromised. The indications ranged from [ redacted ] to sources abruptly and without reason ceasing all communications with us.
These warning signs were alarming due to the fact that our officers were approaching sources using [operational technique] (ledger item 16)
When our efforts began, ultimate operational authority rested with us. The other component provided the finances for the operation while we gave the operational guidance and the country specific knowledge.
knew we had a massive intelligence failure on our hands. All of our assets [ redacted ] were in jeopardy.
To give our compromise context, the U.S. communications infrastructure was under siege
All of this information was collected under the project cryptonym [cryptonym] (ledger item 52)
Meanwhile throughout 2010, I started to hear about catastrophic intelligence failures in the government office I formally worked for. More than one government employee reached out to me and notified me that the "nightmare scenario" I had described and tried to prevent had transpired. I was told that in upwards of 70% of our operations had been compromised.
it is not just a potential compromise in one country, It effects every country
May 2017: Mazzetti et al. reported for the New York Times at "Killing C.I.A. Informants, China Crippled U.S. Spying Operations" that:and that:
The Chinese government systematically dismantled C.I.A. spying operations in the country starting in 2010, killing or imprisoning more than a dozen sources over two years and crippling intelligence gathering there for years afterward.

January 2018: Pete Williams reported for NCB News at Alleged CIA China turncoat Lee may have compromised U.S. spies in Russia too that it was China that told Russia about the communications system:and that some theorize that former CIA agent Jerry Chun Shing Lee had betrayed Chinese spies, which some theorize may have been how China became aware of the communication network:According to Ex-C.I.A. Officer Sentenced to 19 Years in Chinese Espionage Conspiracy from November 2019 Lee was sentenced to 19 years in prison:
It was a shocking blow to an American spy agency that prides itself on its field operations. There was also a devastating human cost: Some 20 CIA sources were executed by the Chinese government, two former officials said — a higher number of dead than initially reported by NBC News and the New York Times. Then an unknown number of Russian assets also disappeared, sources say.
Soon after the task force concluded the Chinese had penetrated covcom, it got an even more troubling report: That after a joint training session between Chinese and Russian intelligence officers, the Russians "came back saying we got good info on covcom," as the former official put it
FBI agents began to suspect Lee after they received a tip that he had passed information to Chinese intelligence officers while working for a Japanese tobacco company in Hong Kong, sources said, a detail first reported Thursday by the New York Times. They also found it suspicious when Lee took a job at an auction house in Hong Kong that was co-owned by a senior Communist Party official, sources said. He eventually ended up working for Christie's, the international auction house.When agents searched Lee's hotel rooms in 2012, they found notebooks with the names of covert CIA sources, according to court documents.But not all of the agent arrests and deaths could be linked to information possessed by Lee, who left the CIA in 2007, the former officials said.
The former officer, Jerry Chun Shing Lee, 55, pleaded guilty in May to conspiring with Chinese intelligence agents starting in 2010, after he left the agency. Prosecutors detailed a long financial paper trail that they said showed that Mr. Lee received more than $840,000 for his work.
But F.B.I. agents who investigated whether he was the culprit passed on an opportunity to arrest him in the United States in 2013, allowing him to travel back to Hong Kong even after finding classified information in his luggage. F.B.I. agents had also covertly entered a hotel room Mr. Lee occupied in 2012, finding handwritten notes detailing the names and numbers of at least eight C.I.A. sources that he had handled in his capacity as a case officer.

Jerry Chun Shing Lee in blue tie at the unveiling of Leonardo da Vinci's 'Salvator Mundi' painting at the Christie's showroom in Hong Kong on Oct. 13, 2017
. Source. August 2018: Zach Dorfman reported for Foreign Policy at "Botched CIA Communications System Helped Blow Cover of Chinese Agents" that:and:Although no clear mention of websites is made in that article, the fact that there were "links" back to the CIA website strongly suggests that the communication was done through websites.
It was considered one of the CIA’s worst failures in decades: Over a two-year period starting in late 2010, Chinese authorities systematically dismantled the agency’s network of agents across the country, executing dozens of suspected U.S. spies. But since then, a question has loomed over the entire debacle. How were the Chinese able to roll up the network?
U.S. intelligence officers were also able to identify digital links between the covert communications system and the U.S. government itself, according to one former official—links the Chinese agencies almost certainly found as well. These digital links would have made it relatively easy for China to deduce that the covert communications system was being used by the CIA. In fact, some of these links pointed back to parts of the CIA’s own website, according to the former official.
The report also reveals that there was a temporary "interim system" that new sources would use while they were being vetted, but that it used the same style of system as the main system. It would be cool if we managed to identify which sites are interim or not somehow:
When CIA officers begin working with a new source, they often use an interim covert communications system—in case the person turns out to be a double agent.The communications system used in China during this period was internet-based and accessible from laptop or desktop computers, two of the former officials said.This interim, or “throwaway,” system, an encrypted digital program, allows for remote communication between an intelligence officer and a source, but it is also separated from the main communications system used with vetted sources, reducing the risk if an asset goes bad.

November 2018: Zach Dorfman and Jenna McLaughlin reported for Yahoo News the first clear report that the communication system was made up of websites at: "The CIA's communications suffered a catastrophic compromise. It started in Iran.":
In 2013, hundreds of CIA officers — many working nonstop for weeks — scrambled to contain a disaster of global proportions: a compromise of the agency’s internet-based covert communications system used to interact with its informants in dark corners around the world. Teams of CIA experts worked feverishly to take down and reconfigure the websites secretly used for these communications
The usage of of Google dorking is then mentioned:It seems to us that this would have been very difficult on the generically themed websites that we have found so far. This suggests the existence of a separate recruitment website network, perhaps the one reported in 2011 by Iran offering VISAs. It would be plausible that such network could link back to the CIA and other government websites. Recruited agents would only then later use the comms network to send information back. The target countries may have first found the recruitment network, and then injected double agents into it, who later came to know about the comms network. TODO: it would be awesome to find some of those recruitment websites!
In fact, the Iranians used Google to identify the website the CIA was using to communicate with agents.
Another very interesting mention is the platform had been over extended beyond its original domain application, which is in part why things went so catastrophically bad:
Former U.S. officials said the internet-based platform, which was first used in war zones in the Middle East, was not built to withstand the sophisticated counterintelligence efforts of a state actor like China or Iran. “It was never meant to be used long term for people to talk to sources,” said one former official. “The issue was that it was working well for too long, with too many people. But it was an elementary system.”
December 2018: a followup Yahoo News article "At the CIA, a fix to communications system that left trail of dead agents remains elusive" gives an interesting internal organizational overview of the failed operation:Much as in the case of Reidy, it is partly because of such internal dissatisfaction that so much has come out to the press, as agents feel that they have nowhere else to turn to.
Ciro Santilli conjectures that this fiasco was the motivation behind the creation of the Directorate of Digital Innovation.
As a result, many who are directly responsible for working with sources on the ground within the CIA’s Directorate of Operations are furious
The fiascos in Iran and China continue to be sticking points between the Directorate of Operations and the CIA’s Directorate of Science and Technology (DS&T) — the technical scientists. “There is a disconnect between the two directorates,” said one former CIA official. “I’m not sure that will be fixed anytime soon.”
Entire careers in the CIA’s Office of Technical Service — the part of DS&T directly responsible for developing covert communications systems — were built on these internet-based systems, said a former senior official. Raising concerns about them was “like calling someone’s baby ugly,” said this person.
Ciro Santilli conjectures that this fiasco was the motivation behind the creation of the Directorate of Digital Innovation.
That article also gives a cute insight into the OPSEC guidelines for the assets that used the websites:
CIA agents using the system were supposed to conduct “electronic surveillance detection routes” — that is, to bounce around on various sites on the internet before accessing the system, in order to cover their tracks — but often failed to do so, creating potentially suspicious patterns of internet usage, said this person.

{kind=link}
29 September 2022: Reuters reported nine specific websites of the network at "America's Throwaway Spies", henceforth known only as "the Reuters article" in this article.
The most important thing that this article gave were screenshots of nine websites, including the domain names of two of them: iraniangoals.com and iraniangoalkicks.com:The "350-plus" number is a bit random, given that their own analysts stated a much higher 885 in their report.
In addition, some sites bore strikingly similar names. For example, while Hosseini was communicating with the CIA through Iraniangoals.com, a site named Iraniangoalkicks.com was built for another informant. At least two dozen of the 350-plus sites produced by the CIA appeared to be messaging platforms for Iranian operatives, the analysts found.
The article also reveals the critical flaw of the system; the usage of sequential IPs:
Online records they analyzed reveal the hosting space for these front websites was often purchased in bulk by the dozen, often from the same internet providers, on the same server space. The result was that numerical identifiers, or IP addresses, for many of these websites were sequential, much like houses on the same street.
It also mentions that other countries besides Iran and Chine were also likely targeted:
This vulnerability went far beyond Iran. Written in various languages, the websites appeared to be a conduit for CIA communications with operatives in at least 20 countries, among them China, Brazil, Russia, Thailand and Ghana, the analysts found.
Banner of the Reuters article
. Source. 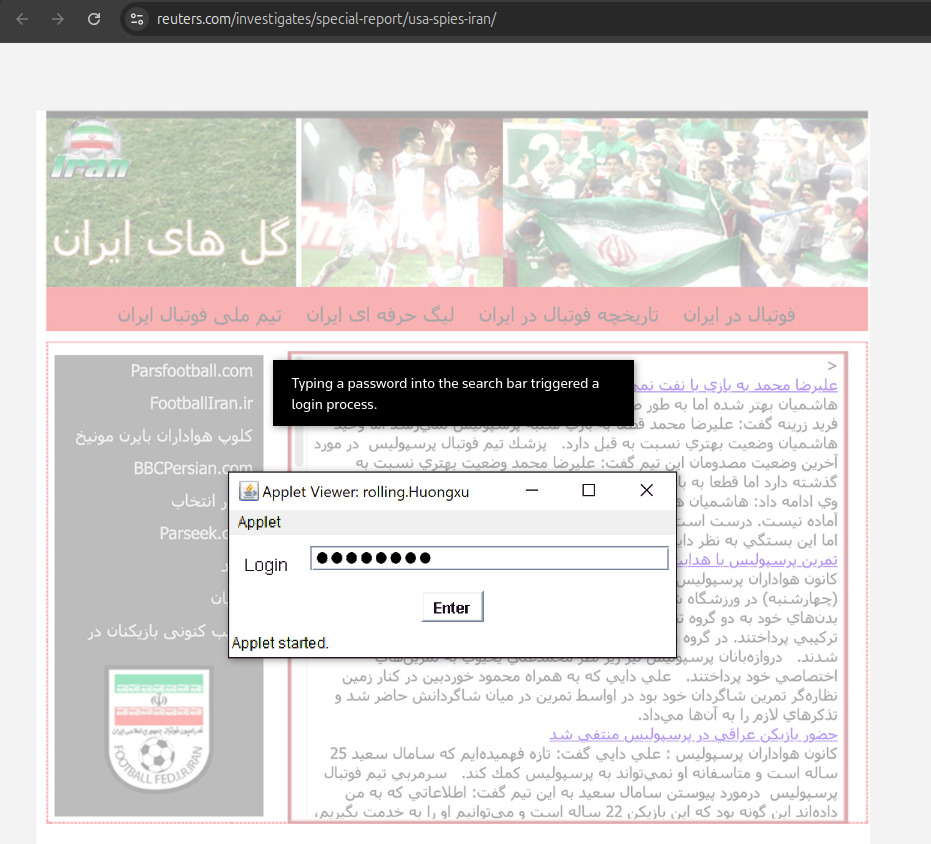
Reuters reconstruction of what the iraniangoals.com applet would have looked like
. Source. 29 September 2022: on the same day that Reuters published their report, Citizenlab, which Reuters used as analysts for the article, also simultaneously published their more technical account of things at "Statement on the fatal flaws found in a defunct CIA covert communications system".
One of the most important information given in that report is the large number of sites found, 885, and the fact that they are available on Wayback Machine:The million dollar question is "which website did they use" and "how much does it cost if anything" since our investigation has so far had to piece together a few different hacky sources but didn't spend any money. And a lot of money could be poured into this, e.g. DomainTools which might contain one of the largest historical databases, , seems to start at 15k USD / 1000 queries. One way to try and deduce which website they used is to look through their other research, e.g.:
Using only a single website, as well as publicly available material such as historical internet scanning results and the Internet Archive's Wayback Machine, we identified a network of 885 websites and have high confidence that the United States (US) Central Intelligence Agency (CIA) used these sites for covert communication.
- citizenlab.ca/2021/07/hooking-candiru-another-mercenary-spyware-vendor-comes-into-focus/ uses Censys, and it notably has historical data:Censys employee Silas Cutler AKA p1nk believes that Censys data does not reach that far back, since the company was only founded in 2017[ref].
- citizenlab.ca/2016/08/million-dollar-dissident-iphone-zero-day-nso-group-uae/ mentions scans.io/
- citizenlab.ca/2020/12/running-in-circles-uncovering-the-clients-of-cyberespionage-firm-circles/ mentions: www.shodan.io/
The article mentioned the different types of communication mechanisms found:
The websites included similar Java, JavaScript, Adobe Flash, and CGI artifacts that implemented or apparently loaded covert communications apps. In addition, blocks of sequential IP addresses registered to apparently fictitious US companies were used to host some of the websites. All of these flaws would have facilitated discovery by hostile parties.
They also give the dates range in which the system was active, which is very helpful for better targeting our searches:
And then a bomb, they claim to have found information regarding specific officers:This basically implies that they must have eitherWe have so for not yet found any such clear references to real individuals.
Nevertheless, a subset of the websites are linked to individuals who may be former and possibly still active intelligence community employees or assets:Given that we cannot rule out ongoing risks to CIA employees or assets, we are not publishing full technical details regarding our process of mapping out the network at this time. As a first step, we intend to conduct a limited disclosure to US Government oversight bodies.
- Several are currently abroad
- Another left mainland China in the time frame of the Chinese crackdown
- Another was subsequently employed by the US State Department
- Another now works at a foreign intelligence contractor
- found some communication layer level identifier, e.g. domain name registration HTTPS certificate certificate because it is impossible to believe that real agent names would have been present on the website content itself!
- or they may be instead talking about a separate recruitment network which offered the VISAs which we conjecture might have existed but currently have no examples of, and which might conceivably contain real embassy contacts
October 2022 Zach Dorfman, author of the 2018 Yahoo News and Foreign Policy articles gave some good anecdotes he had heard from his sources after the Reuters expose in his personal blog post On Agent Compromise in the Field, giving a more personal account of some of the events that took place:
Now, an important caveat: I have known dedicated former CIA officials who have spoken of the care, respect, and obligation they felt toward their sources, and the lengths they would go to assist them. For many case officers — that is, the CIA's primary corps of spy handlers — this is a core part of their professional identity.During the roll-up in China, for instance, a former U.S. official told me about a CIA officer who, aware that something was going terribly wrong there, organized final, assuredly dangerous, in-person meetings with agency sources. This distraught CIA officer essentially shoved wads of cash into sources' hands. This CIA officer warned them of the unfolding disaster and begged them to leave the country as fast as they could. Another source told me a story about a CIA official who, while being debriefed in Langley about the asset roll-up — and the slapdash COVCOM system — broke down in tears upon hearing that sources’ lives had been destroyed because of such obvious dereliction, of which they were previously unaware.
But I don’t want to oversell this point, either. By its nature, the world of espionage is steeped in the sordid aspects of human experience, exploiting people’s vulnerabilities for narrow informational gain. [...]Indeed, many former CIA officials have a decidedly pragmatic and amoral conception of their profession. Bad things happen when you spy, or recruit others to do so. [...] I had a conversation once with a former senior CIA official with experience in Iran issues who had an almost naturalistic view of recurring asset losses there over the years: for him, it was a built-in, cyclical feature of the work and environment, like the denuding of deciduous forests every fall.
Governments should provide basic Internet infrastructure Updated 2025-07-16
Taxes pay for the physical car roads, so why shouldn't they also pay for the "online roads" of today?
The following services are obvious picks because they are so simple:
Other less simple ones that might also be feasible:
- geographic information system. Notable anti-example: United Kingdom's Ordnance Survey's apparently non-free-data
- App stores
All of them should have strong privacy enabled by default: end-to-end encryption, logless, etc. Governments are not going to like this part.
And then if you ever forget a password or lose a multi-factor authentication token, you can just go to an ID center with your ID to recover it.