Ciro Santilli hard heard about the 2018 Yahoo article around 2020 while studying for his China campaign because the websites had been used to take down the Chinese CIA network in China. He even asked on Quora about it, but there were no publicly known domains at the time to serve as a starting point. Chris, Electrical Engineer and former Avionics Tech in the US Navy, even replied suggesting that obviously the CIA is so competent that it would never ever have its sites leaked like that:
Seriously a dumb question.
In 2023, one year after the Reuters article had been published, Ciro Santilli was killing some time on YouTube when he saw a curious video: Video 1. "Compromised Comms by Darknet Diaries (2023)". As soon as he understood what it was about and that it was likely related to the previously undisclosed websites that he was interested in, he went on to read the Reuters article that the podcast pointed him to.
Being a half-arsed web developer himself, Ciro knows that the attack surface of a website is about the size of Texas, and the potential for fingerprinting is off the charts with so many bits and pieces sticking out. And given that there were at least 885 of them, surely we should be able to find a few more than nine, right?
In particular, it is fun how these websites provide to anyone "live" examples of the USA spying on its own allies in the form of Wayback Machine archives.
Given all of this, Ciro knew he had to try and find some of the domains himself using the newly available information! It was an irresistible real-life capture the flag.
Chris, get fucked.
It was the YouTube suggestion for this video that made Ciro Santilli aware of the Reuters article almost one year after its publication, which kickstarted his research on the topic.
Full podcast transcript: darknetdiaries.com/transcript/75/
Ciro Santilli pinged the Podcast's host Jack Rhysider on Twitter and he ACK'ed which is cool, though he was skeptical about the strength of the fingerprints found, and didn't reply when clarification was offered. Perhaps the material is just not impactful enough for him to produce any new content based on it. Or also perhaps it comes too close to sources and methods for his own good as a presumably American citizen.
The first step was to try and obtain the domain names of all nine websites that Reuters had highlighted as they had only given two domains explicitly.
Thankfully however, either by carelessness or intentionally, this was easy to do by inspecting the address of the screenshots provided. For example, one of the URLs was:which corresponds to
https://www.reuters.com/investigates/special-report/assets/usa-spies-iran/screencap-activegaminginfo.com.jpg?v=192516290922activegaminginfo.com.Once we had this, we were then able to inspect the websites on the Wayback Machine to better understand possible fingerprints such as their communication mechanism.
The next step was to use our knowledge of the sequential IP flaw to look for more neighbor websites to the nine we knew of.
This was not so easy to do because the websites are down and so it requires historical data. But for our luck we found viewdns.info which allowed for 200 free historical queries (and they seem to have since removed this hard limit and moved to only throttling), leading to the discovery or some or our own new domains!
This gave us a larger website sample size in the order of the tens, which allowed us to better grasp more of the possible different styles of website and have a much better idea of what a good fingerprint would look like.
viewdns.info
. Source. activegameinfo.com domain to IPviewdns.info
. Source. aroundthemiddleeast.com IP to domainThe next major and difficult step would be to find new IP ranges.
This was and still is a hacky heuristic process for us, but we've had the most success with the following methods:
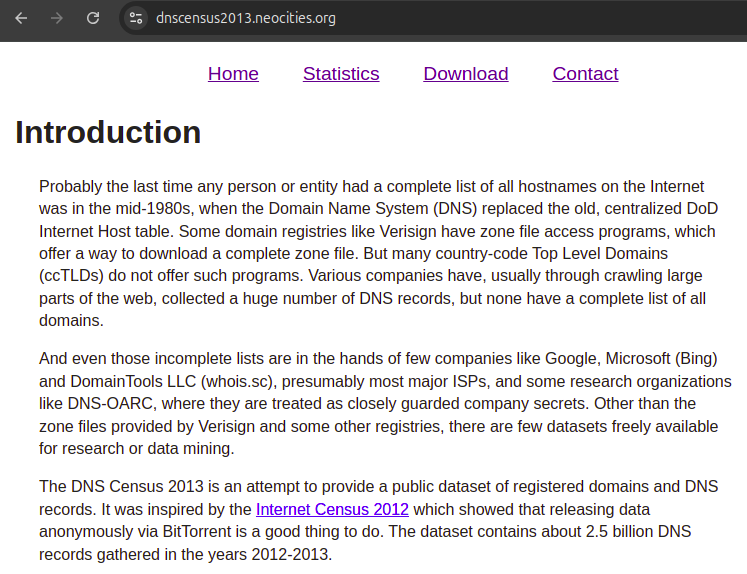
- step 1) get huge lists of historic domain names. The two most valuable sources so far have been:
- step 2) filter the domain lists down somehow to a more manageable number of domains. The most successful heuristics have been:
- for 2013 DNS Census which has IPs, check that they are the only domain in a given IP, which was the case for the majority of CIA websites, but was already not so common for legitimate websites
- they have the word
newson the domain name, given that so many of the websites were fake news aggregators
- step 3) search on Wayback machine if any of those filtered domains contain URL's that could be those of a communication mechanism. In particular, we've used a small army of Tor bots to overcome the Wayback Machine's IP throttling and greatly increase our checking capacity
amazon.com,2012-02-01T21:33:36,72.21.194.1
amazon.com,2012-02-01T21:33:36,72.21.211.176
amazon.com,2013-10-02T19:03:39,72.21.194.212
amazon.com,2013-10-02T19:03:39,72.21.215.232
amazon.com.au,2012-02-10T08:03:38,207.171.166.22
amazon.com.au,2012-02-10T08:03:38,72.21.206.80
google.com,2012-01-28T05:33:40,74.125.159.103
google.com,2012-01-28T05:33:40,74.125.159.104
google.com,2013-10-02T19:02:35,74.125.239.41
google.com,2013-10-02T19:02:35,74.125.239.46
The four communication mechanisms used by the CIA websites
. Java Applets, Adobe Flash, JavaScript and HTTPS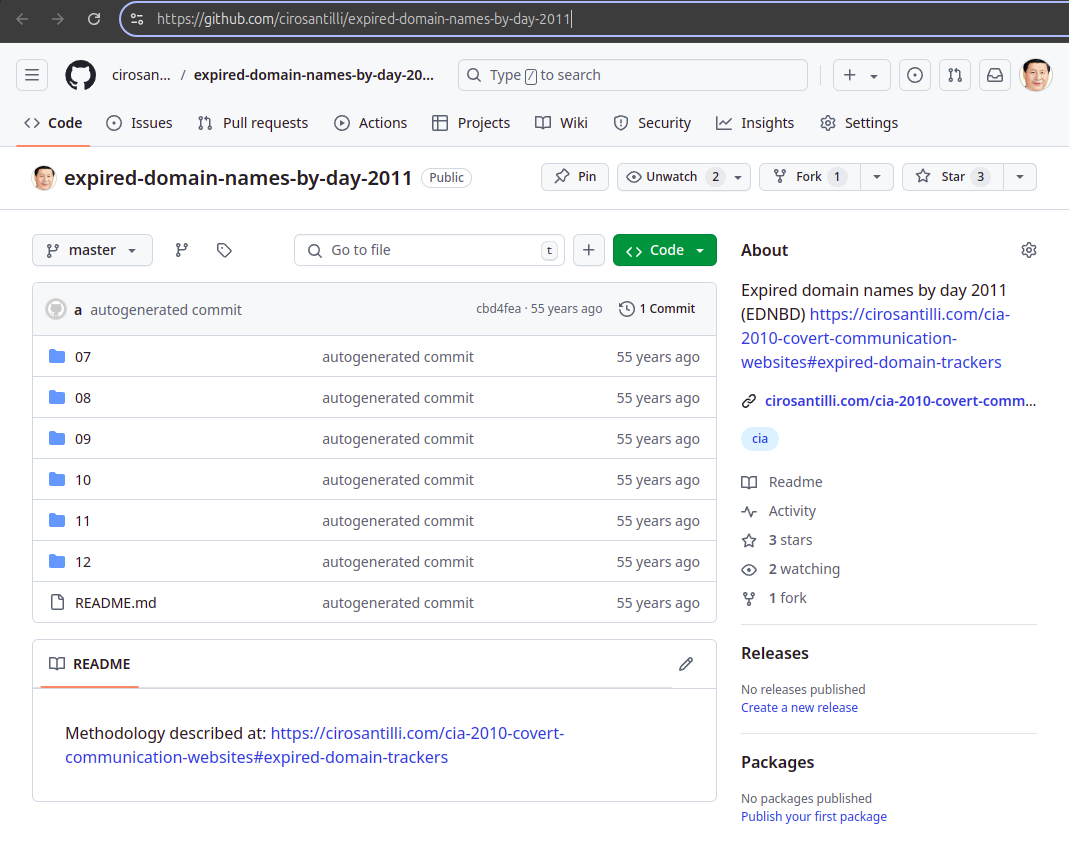
Expired domain names by day 2011
. Source. The scraping of expired domain trackers to Github was one of the positive outcomes of this project.Finally, at the very end of our pipeline, we were left with a a few hundred domains, and we just manually inspected them one by one as far as patience would allow it to confirm or discard them.

You can never have enough Wayback Machine tabs open
. This is how the end of the fingerprint pipeline looks like: as many tabs as you have the patience to go through one by one! Articles by others on the same topic
There are currently no matching articles.