Fun fact: you can see they "No photography" signs on GCHQ's gates from Google Street View, but super low resolution, making them unreadable. They must have made a deal: Google gives its Street View data with uncensored plate numbers/faces, and GCGQ allows them to film in front of their building at low resolution! The sign actually shows up on their first Instagram post when they created one in 2018 www.gchq.gov.uk/news/gchq-joins-instagram | inews.co.uk/news/uk/gchq-instagram-puzzles-photography-hobbies-216444 Just passing in front of the damn place with Google Maps on must increase your "interest score"!
This article is about covert agent communication channel websites used by the CIA in many countries from the mid 2000s until the early 2010s, when they were uncovered by counter intelligence of some of the targeted countries, notably Iran and China, circa 2010-2013.
This article uses publicly available information to publicly disclose for the first time a few hundred of what we feel are extremely likely candidate sites of the network. The starting point for this research was the September 2022 Reuters article "America’s Throwaway Spies" which for the first time gave nine example websites, and their analyst from Citizenlabs claims to have found 885 websites in total, but did not publicly disclose them. Starting from only the nine disclosed websites, we were then able to find a few hundred websites that share so many similarities with them, i.e. a common fingerprint, that we believe makes them beyond reasonable doubt part of the same network.
If you enjoy this article, consider dropping some Monero at: 4A1KK4uyLQX7EBgN7uFgUeGt6PPksi91e87xobNq7bT2j4V6LqZHKnkGJTUuCC7TjDNnKpxDd8b9DeNBpSxim8wpSczQvzf so I can waste it on my foolish attempts to improve higher education. Other sponsorship methods: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
The discovery of these websites by Iranian and Chinese counterintelligence led to the imprisonment and execution of several assets in those countries, and subsequent shutdown of the channel by the CIA when they noticed that things had gone wrong. This is likely a Wikipedia page that talks about the disastrous outcome of the websites being found out: 2010–2012 killing of CIA sources in China, although it contained no mention of websites before Ciro Santilli edited it in.
Of particular interest is that based on their language and content, certain of the websites seem to have targeted other democracies such as Germany, France, Spain and Brazil.
If anyone can find others websites, or has better techniques feel free to contact Ciro Santilli at: Section "How to contact Ciro Santilli". Contributions will be clearly attributed if desired. Some of the techniques used so far have been very heuristic, and that added to the limited amount of data makes it almost certain that some websites have been missed. Broadly speaking, there are two types of contributions that would be possible:
- finding new IP ranges: harder and more exiting, and potentially requires more intelligence
- better IP to domain name databases to fill in known gaps in existing IP ranges
The fact that citizenlabs reported exactly 885 websites being found makes it feel like they might have found find a better fingerprint which we have not managed to find yet. We have not yet had to pay for our data. If someone wants to donate to the research, some ideas include:
- dump $400 on WhoisXMLAPI to dump whois history of all known hits and search for other matches. Small discoveries were made like this in the past and we'd expect a few more to be left. We don't expect huge breakthroughs from this, but at only $400 it is not so bad
- dump a lot more ($15k+? needs confirmation as opaque pricing) on DomainTools. We are not certain that they have any superior data since there is no free trial of any kind, but it would be interesting to test the quality of the data they acquired from Farsight DNSDB if you are really loaded
Disclaimers:
- the network fell in 2013, followed by fully public disclosures in 2018 and 2022, so we believe that the benefit of giving the public this broader historic understanding outweighs the risks that agents could be found so many years later by sloppy secret services
- Ciro Santilli's political bias is strongly pro-democracy and anti-dictatorship, but with a good pinch of skepticism about the morality US foreign policy in the last century
May this article serve as a tribute to those who spent their days making, using, and uncovering these websites under the shadows.
The existence of the websites emerged in various stages, some of which may refer to this network or to other closely related communications failure since the published information is sometimes not clear enough.
May 21, 2011: various Iranian news outlets reported that:Iranian sources include:The news were picked up and repeated by Western outlets on the same day e.g.:At this point there were still no clear indications that the recruitment had been made with websites, however later revelations would later imply that.
30 individual suspected of spying for the US were arrested and 42 CIA operatives were identified in connection with the network.
- web.archive.org/web/20110729150642/http://www.presstv.ir/detail/180976.html "Iran dismantles US-linked spy network by Press TV (English, quoted above)
- web.archive.org/web/20110527084527/https://www.mehrnews.ir/NewsPrint.aspx?NewsID=1316973 "CIA spy network dismantled/30 American spies arrested" by Mehr news (Farsi)
- shiatv.net/video/dd6ee2d708a4a6cb2429 "Iran dismantles US-linked spy network" broadcast by IRIB, the main Iranian public broadcaster
- www.latimes.com/archives/blogs/babylon-beyond/story/2011-05-21/iran-intelligence-ministry-claims-to-arrest-30-alleged-cia-spies "Intelligence Ministry claims to arrest 30 alleged CIA spies" by the Los Angeles Times
Quite prophetically, this was on the same day that Christian radio broadcaster Harold Camping predicted that the world would come to an end.
December 2014: McClathy DC reported on "Intelligence, defense whistleblowers remain mired in broken system" that CIA contractor John A. Reidy had started raising concerns about the security of a communication systems used by the CIA and other sources mention that he started this in 2008[ref] The focus of the article is how he was then ignored and silenced for raising these concerns, which later turned out to be correct and leading to an intelligence catastrophe that started in 2010.[ref][ref] This appears to have come out after a heavily redacted appeal by Reidy against the CIA from October 2014 came into McClathy's possession.[ref] While Reidy's disclosures were responsible and don't give much away, given the little that they disclose it feels extremely likely that they were related to the same system we are interested in. Even heavily redacted, the few unredacted snippets of the appeal are pure gold and give a little bit of insight into the internal workings of the CIA. Some selections:
From January 2005 until January 2009, I worked as a government contractor at the CIA. I was assigned to [Directorate](ledger item 1) in the [Division] (ledger item 2). I served as a Uob) (ledger item 3) whose responsibility was to facilitate the dissemination of intelligence reporting to the Intelligence Community. I also served as a Oob 2) (ledger item 4) whose responsibility was to identify Human Intelligence (humint) targets of Interest for exploitation. I was assigned the telecommunications and information operations account.
As our efforts increased, we started to notice anomalies in our operations and conflicting intelligence reporting that indicated that several of our operations had been compromised. The indications ranged from [ redacted ] to sources abruptly and without reason ceasing all communications with us.
These warning signs were alarming due to the fact that our officers were approaching sources using [operational technique] (ledger item 16)
When our efforts began, ultimate operational authority rested with us. The other component provided the finances for the operation while we gave the operational guidance and the country specific knowledge.
knew we had a massive intelligence failure on our hands. All of our assets [ redacted ] were in jeopardy.
To give our compromise context, the U.S. communications infrastructure was under siege
All of this information was collected under the project cryptonym [cryptonym] (ledger item 52)
Meanwhile throughout 2010, I started to hear about catastrophic intelligence failures in the government office I formally worked for. More than one government employee reached out to me and notified me that the "nightmare scenario" I had described and tried to prevent had transpired. I was told that in upwards of 70% of our operations had been compromised.
it is not just a potential compromise in one country, It effects every country
May 2017: Mazzetti et al. reported for the New York Times at "Killing C.I.A. Informants, China Crippled U.S. Spying Operations" that:and that:
The Chinese government systematically dismantled C.I.A. spying operations in the country starting in 2010, killing or imprisoning more than a dozen sources over two years and crippling intelligence gathering there for years afterward.

January 2018: Pete Williams reported for NCB News at Alleged CIA China turncoat Lee may have compromised U.S. spies in Russia too that it was China that told Russia about the communications system:and that some theorize that former CIA agent Jerry Chun Shing Lee had betrayed Chinese spies, which some theorize may have been how China became aware of the communication network:According to Ex-C.I.A. Officer Sentenced to 19 Years in Chinese Espionage Conspiracy from November 2019 Lee was sentenced to 19 years in prison:
It was a shocking blow to an American spy agency that prides itself on its field operations. There was also a devastating human cost: Some 20 CIA sources were executed by the Chinese government, two former officials said — a higher number of dead than initially reported by NBC News and the New York Times. Then an unknown number of Russian assets also disappeared, sources say.
Soon after the task force concluded the Chinese had penetrated covcom, it got an even more troubling report: That after a joint training session between Chinese and Russian intelligence officers, the Russians "came back saying we got good info on covcom," as the former official put it
FBI agents began to suspect Lee after they received a tip that he had passed information to Chinese intelligence officers while working for a Japanese tobacco company in Hong Kong, sources said, a detail first reported Thursday by the New York Times. They also found it suspicious when Lee took a job at an auction house in Hong Kong that was co-owned by a senior Communist Party official, sources said. He eventually ended up working for Christie's, the international auction house.When agents searched Lee's hotel rooms in 2012, they found notebooks with the names of covert CIA sources, according to court documents.But not all of the agent arrests and deaths could be linked to information possessed by Lee, who left the CIA in 2007, the former officials said.
The former officer, Jerry Chun Shing Lee, 55, pleaded guilty in May to conspiring with Chinese intelligence agents starting in 2010, after he left the agency. Prosecutors detailed a long financial paper trail that they said showed that Mr. Lee received more than $840,000 for his work.
But F.B.I. agents who investigated whether he was the culprit passed on an opportunity to arrest him in the United States in 2013, allowing him to travel back to Hong Kong even after finding classified information in his luggage. F.B.I. agents had also covertly entered a hotel room Mr. Lee occupied in 2012, finding handwritten notes detailing the names and numbers of at least eight C.I.A. sources that he had handled in his capacity as a case officer.

Jerry Chun Shing Lee in blue tie at the unveiling of Leonardo da Vinci's 'Salvator Mundi' painting at the Christie's showroom in Hong Kong on Oct. 13, 2017
. Source. August 2018: Zach Dorfman reported for Foreign Policy at "Botched CIA Communications System Helped Blow Cover of Chinese Agents" that:and:Although no clear mention of websites is made in that article, the fact that there were "links" back to the CIA website strongly suggests that the communication was done through websites.
It was considered one of the CIA’s worst failures in decades: Over a two-year period starting in late 2010, Chinese authorities systematically dismantled the agency’s network of agents across the country, executing dozens of suspected U.S. spies. But since then, a question has loomed over the entire debacle. How were the Chinese able to roll up the network?
U.S. intelligence officers were also able to identify digital links between the covert communications system and the U.S. government itself, according to one former official—links the Chinese agencies almost certainly found as well. These digital links would have made it relatively easy for China to deduce that the covert communications system was being used by the CIA. In fact, some of these links pointed back to parts of the CIA’s own website, according to the former official.
The report also reveals that there was a temporary "interim system" that new sources would use while they were being vetted, but that it used the same style of system as the main system. It would be cool if we managed to identify which sites are interim or not somehow:
When CIA officers begin working with a new source, they often use an interim covert communications system—in case the person turns out to be a double agent.The communications system used in China during this period was internet-based and accessible from laptop or desktop computers, two of the former officials said.This interim, or “throwaway,” system, an encrypted digital program, allows for remote communication between an intelligence officer and a source, but it is also separated from the main communications system used with vetted sources, reducing the risk if an asset goes bad.

November 2018: Zach Dorfman and Jenna McLaughlin reported for Yahoo News the first clear report that the communication system was made up of websites at: "The CIA's communications suffered a catastrophic compromise. It started in Iran.":
In 2013, hundreds of CIA officers — many working nonstop for weeks — scrambled to contain a disaster of global proportions: a compromise of the agency’s internet-based covert communications system used to interact with its informants in dark corners around the world. Teams of CIA experts worked feverishly to take down and reconfigure the websites secretly used for these communications
The usage of of Google dorking is then mentioned:It seems to us that this would have been very difficult on the generically themed websites that we have found so far. This suggests the existence of a separate recruitment website network, perhaps the one reported in 2011 by Iran offering VISAs. It would be plausible that such network could link back to the CIA and other government websites. Recruited agents would only then later use the comms network to send information back. The target countries may have first found the recruitment network, and then injected double agents into it, who later came to know about the comms network. TODO: it would be awesome to find some of those recruitment websites!
In fact, the Iranians used Google to identify the website the CIA was using to communicate with agents.
Another very interesting mention is the platform had been over extended beyond its original domain application, which is in part why things went so catastrophically bad:
Former U.S. officials said the internet-based platform, which was first used in war zones in the Middle East, was not built to withstand the sophisticated counterintelligence efforts of a state actor like China or Iran. “It was never meant to be used long term for people to talk to sources,” said one former official. “The issue was that it was working well for too long, with too many people. But it was an elementary system.”
December 2018: a followup Yahoo News article "At the CIA, a fix to communications system that left trail of dead agents remains elusive" gives an interesting internal organizational overview of the failed operation:Much as in the case of Reidy, it is partly because of such internal dissatisfaction that so much has come out to the press, as agents feel that they have nowhere else to turn to.
Ciro Santilli conjectures that this fiasco was the motivation behind the creation of the Directorate of Digital Innovation.
As a result, many who are directly responsible for working with sources on the ground within the CIA’s Directorate of Operations are furious
The fiascos in Iran and China continue to be sticking points between the Directorate of Operations and the CIA’s Directorate of Science and Technology (DS&T) — the technical scientists. “There is a disconnect between the two directorates,” said one former CIA official. “I’m not sure that will be fixed anytime soon.”
Entire careers in the CIA’s Office of Technical Service — the part of DS&T directly responsible for developing covert communications systems — were built on these internet-based systems, said a former senior official. Raising concerns about them was “like calling someone’s baby ugly,” said this person.
Ciro Santilli conjectures that this fiasco was the motivation behind the creation of the Directorate of Digital Innovation.
That article also gives a cute insight into the OPSEC guidelines for the assets that used the websites:
CIA agents using the system were supposed to conduct “electronic surveillance detection routes” — that is, to bounce around on various sites on the internet before accessing the system, in order to cover their tracks — but often failed to do so, creating potentially suspicious patterns of internet usage, said this person.

29 September 2022: Reuters reported nine specific websites of the network at "America's Throwaway Spies", henceforth known only as "the Reuters article" in this article.
The most important thing that this article gave were screenshots of nine websites, including the domain names of two of them: iraniangoals.com and iraniangoalkicks.com:The "350-plus" number is a bit random, given that their own analysts stated a much higher 885 in their report.
In addition, some sites bore strikingly similar names. For example, while Hosseini was communicating with the CIA through Iraniangoals.com, a site named Iraniangoalkicks.com was built for another informant. At least two dozen of the 350-plus sites produced by the CIA appeared to be messaging platforms for Iranian operatives, the analysts found.
The article also reveals the critical flaw of the system; the usage of sequential IPs:
Online records they analyzed reveal the hosting space for these front websites was often purchased in bulk by the dozen, often from the same internet providers, on the same server space. The result was that numerical identifiers, or IP addresses, for many of these websites were sequential, much like houses on the same street.
It also mentions that other countries besides Iran and Chine were also likely targeted:
This vulnerability went far beyond Iran. Written in various languages, the websites appeared to be a conduit for CIA communications with operatives in at least 20 countries, among them China, Brazil, Russia, Thailand and Ghana, the analysts found.
Banner of the Reuters article
. Source. 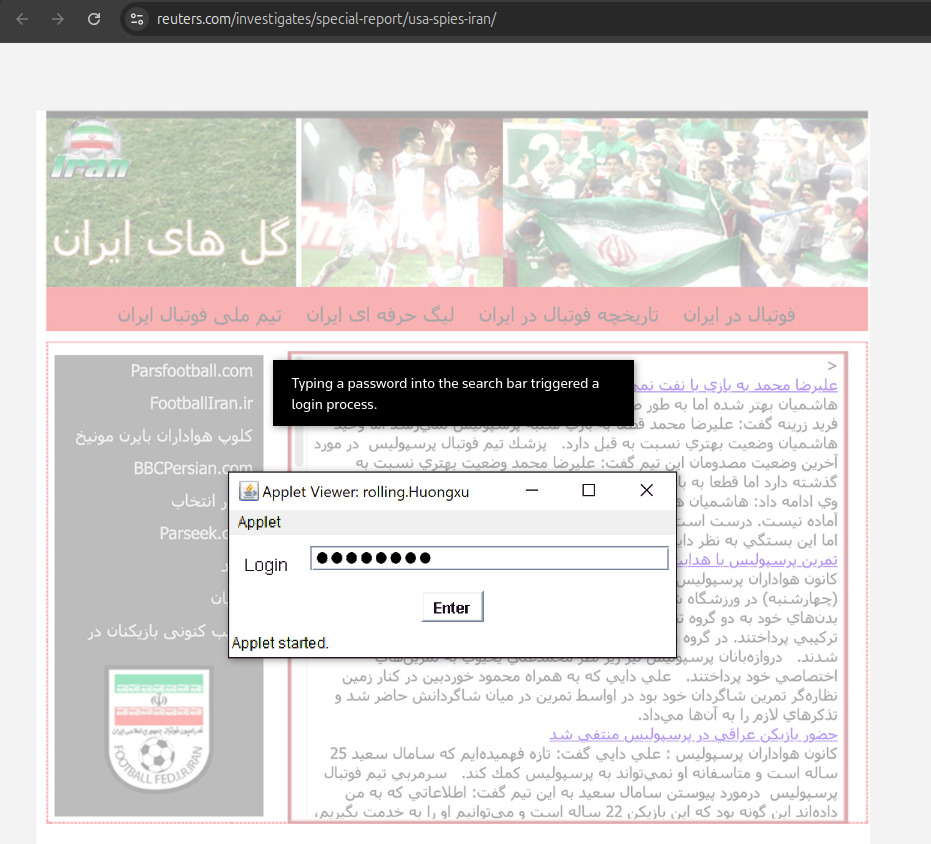
Reuters reconstruction of what the iraniangoals.com applet would have looked like
. Source. 29 September 2022: on the same day that Reuters published their report, Citizenlab, which Reuters used as analysts for the article, also simultaneously published their more technical account of things at "Statement on the fatal flaws found in a defunct CIA covert communications system".
One of the most important information given in that report is the large number of sites found, 885, and the fact that they are available on Wayback Machine:The million dollar question is "which website did they use" and "how much does it cost if anything" since our investigation has so far had to piece together a few different hacky sources but didn't spend any money. And a lot of money could be poured into this, e.g. DomainTools which might contain one of the largest historical databases, , seems to start at 15k USD / 1000 queries. One way to try and deduce which website they used is to look through their other research, e.g.:
Using only a single website, as well as publicly available material such as historical internet scanning results and the Internet Archive's Wayback Machine, we identified a network of 885 websites and have high confidence that the United States (US) Central Intelligence Agency (CIA) used these sites for covert communication.
- citizenlab.ca/2021/07/hooking-candiru-another-mercenary-spyware-vendor-comes-into-focus/ uses Censys, and it notably has historical data:Censys employee Silas Cutler AKA p1nk believes that Censys data does not reach that far back, since the company was only founded in 2017[ref].
- citizenlab.ca/2016/08/million-dollar-dissident-iphone-zero-day-nso-group-uae/ mentions scans.io/
- citizenlab.ca/2020/12/running-in-circles-uncovering-the-clients-of-cyberespionage-firm-circles/ mentions: www.shodan.io/
The article mentioned the different types of communication mechanisms found:
The websites included similar Java, JavaScript, Adobe Flash, and CGI artifacts that implemented or apparently loaded covert communications apps. In addition, blocks of sequential IP addresses registered to apparently fictitious US companies were used to host some of the websites. All of these flaws would have facilitated discovery by hostile parties.
They also give the dates range in which the system was active, which is very helpful for better targeting our searches:
And then a bomb, they claim to have found information regarding specific officers:This basically implies that they must have eitherWe have so for not yet found any such clear references to real individuals.
Nevertheless, a subset of the websites are linked to individuals who may be former and possibly still active intelligence community employees or assets:Given that we cannot rule out ongoing risks to CIA employees or assets, we are not publishing full technical details regarding our process of mapping out the network at this time. As a first step, we intend to conduct a limited disclosure to US Government oversight bodies.
- Several are currently abroad
- Another left mainland China in the time frame of the Chinese crackdown
- Another was subsequently employed by the US State Department
- Another now works at a foreign intelligence contractor
- found some communication layer level identifier, e.g. domain name registration HTTPS certificate certificate because it is impossible to believe that real agent names would have been present on the website content itself!
- or they may be instead talking about a separate recruitment network which offered the VISAs which we conjecture might have existed but currently have no examples of, and which might conceivably contain real embassy contacts
October 2022 Zach Dorfman, author of the 2018 Yahoo News and Foreign Policy articles gave some good anecdotes he had heard from his sources after the Reuters expose in his personal blog post On Agent Compromise in the Field, giving a more personal account of some of the events that took place:
Now, an important caveat: I have known dedicated former CIA officials who have spoken of the care, respect, and obligation they felt toward their sources, and the lengths they would go to assist them. For many case officers — that is, the CIA's primary corps of spy handlers — this is a core part of their professional identity.During the roll-up in China, for instance, a former U.S. official told me about a CIA officer who, aware that something was going terribly wrong there, organized final, assuredly dangerous, in-person meetings with agency sources. This distraught CIA officer essentially shoved wads of cash into sources' hands. This CIA officer warned them of the unfolding disaster and begged them to leave the country as fast as they could. Another source told me a story about a CIA official who, while being debriefed in Langley about the asset roll-up — and the slapdash COVCOM system — broke down in tears upon hearing that sources’ lives had been destroyed because of such obvious dereliction, of which they were previously unaware.
But I don’t want to oversell this point, either. By its nature, the world of espionage is steeped in the sordid aspects of human experience, exploiting people’s vulnerabilities for narrow informational gain. [...]Indeed, many former CIA officials have a decidedly pragmatic and amoral conception of their profession. Bad things happen when you spy, or recruit others to do so. [...] I had a conversation once with a former senior CIA official with experience in Iran issues who had an almost naturalistic view of recurring asset losses there over the years: for him, it was a built-in, cyclical feature of the work and environment, like the denuding of deciduous forests every fall.
Ciro Santilli hard heard about the 2018 Yahoo article around 2020 while studying for his China campaign because the websites had been used to take down the Chinese CIA network in China. He even asked on Quora about it, but there were no publicly known domains at the time to serve as a starting point. Chris, Electrical Engineer and former Avionics Tech in the US Navy, even replied suggesting that obviously the CIA is so competent that it would never ever have its sites leaked like that:
Seriously a dumb question.
In 2023, one year after the Reuters article had been published, Ciro Santilli was killing some time on YouTube when he saw a curious video: Video 1. "Compromised Comms by Darknet Diaries (2023)". As soon as he understood what it was about and that it was likely related to the previously undisclosed websites that he was interested in, he went on to read the Reuters article that the podcast pointed him to.
Being a half-arsed web developer himself, Ciro knows that the attack surface of a website is about the size of Texas, and the potential for fingerprinting is off the charts with so many bits and pieces sticking out. And given that there were at least 885 of them, surely we should be able to find a few more than nine, right?
In particular, it is fun how these websites provide to anyone "live" examples of the USA spying on its own allies in the form of Wayback Machine archives.
Given all of this, Ciro knew he had to try and find some of the domains himself using the newly available information! It was an irresistible real-life capture the flag.
Chris, get fucked.
It was the YouTube suggestion for this video that made Ciro Santilli aware of the Reuters article almost one year after its publication, which kickstarted his research on the topic.
Full podcast transcript: darknetdiaries.com/transcript/75/
Ciro Santilli pinged the Podcast's host Jack Rhysider on Twitter and he ACK'ed which is cool, though he was skeptical about the strength of the fingerprints found, and didn't reply when clarification was offered. Perhaps the material is just not impactful enough for him to produce any new content based on it. Or also perhaps it comes too close to sources and methods for his own good as a presumably American citizen.
The first step was to try and obtain the domain names of all nine websites that Reuters had highlighted as they had only given two domains explicitly.
Thankfully however, either by carelessness or intentionally, this was easy to do by inspecting the address of the screenshots provided. For example, one of the URLs was:which corresponds to
https://www.reuters.com/investigates/special-report/assets/usa-spies-iran/screencap-activegaminginfo.com.jpg?v=192516290922activegaminginfo.com.Once we had this, we were then able to inspect the websites on the Wayback Machine to better understand possible fingerprints such as their communication mechanism.
The next step was to use our knowledge of the sequential IP flaw to look for more neighbor websites to the nine we knew of.
This was not so easy to do because the websites are down and so it requires historical data. But for our luck we found viewdns.info which allowed for 200 free historical queries (and they seem to have since removed this hard limit and moved to only throttling), leading to the discovery or some or our own new domains!
This gave us a larger website sample size in the order of the tens, which allowed us to better grasp more of the possible different styles of website and have a much better idea of what a good fingerprint would look like.
viewdns.info
. Source. activegameinfo.com domain to IPviewdns.info
. Source. aroundthemiddleeast.com IP to domainThe next major and difficult step would be to find new IP ranges.
This was and still is a hacky heuristic process for us, but we've had the most success with the following methods:
- step 1) get huge lists of historic domain names. The two most valuable sources so far have been:
- step 2) filter the domain lists down somehow to a more manageable number of domains. The most successful heuristics have been:
- for 2013 DNS Census which has IPs, check that they are the only domain in a given IP, which was the case for the majority of CIA websites, but was already not so common for legitimate websites
- they have the word
newson the domain name, given that so many of the websites were fake news aggregators
- step 3) search on Wayback machine if any of those filtered domains contain URL's that could be those of a communication mechanism. In particular, we've used a small army of Tor bots to overcome the Wayback Machine's IP throttling and greatly increase our checking capacity
amazon.com,2012-02-01T21:33:36,72.21.194.1
amazon.com,2012-02-01T21:33:36,72.21.211.176
amazon.com,2013-10-02T19:03:39,72.21.194.212
amazon.com,2013-10-02T19:03:39,72.21.215.232
amazon.com.au,2012-02-10T08:03:38,207.171.166.22
amazon.com.au,2012-02-10T08:03:38,72.21.206.80
google.com,2012-01-28T05:33:40,74.125.159.103
google.com,2012-01-28T05:33:40,74.125.159.104
google.com,2013-10-02T19:02:35,74.125.239.41
google.com,2013-10-02T19:02:35,74.125.239.46
The four communication mechanisms used by the CIA websites
. Java Applets, Adobe Flash, JavaScript and HTTPS
Expired domain names by day 2011
. Source. The scraping of expired domain trackers to Github was one of the positive outcomes of this project.Finally, at the very end of our pipeline, we were left with a a few hundred domains, and we just manually inspected them one by one as far as patience would allow it to confirm or discard them.

You can never have enough Wayback Machine tabs open
. This is how the end of the fingerprint pipeline looks like: as many tabs as you have the patience to go through one by one!This section contains some of the most interesting and a few representative screenshots of the websites found.
We intentionally omit the screenshots already reported by the Reuters article.
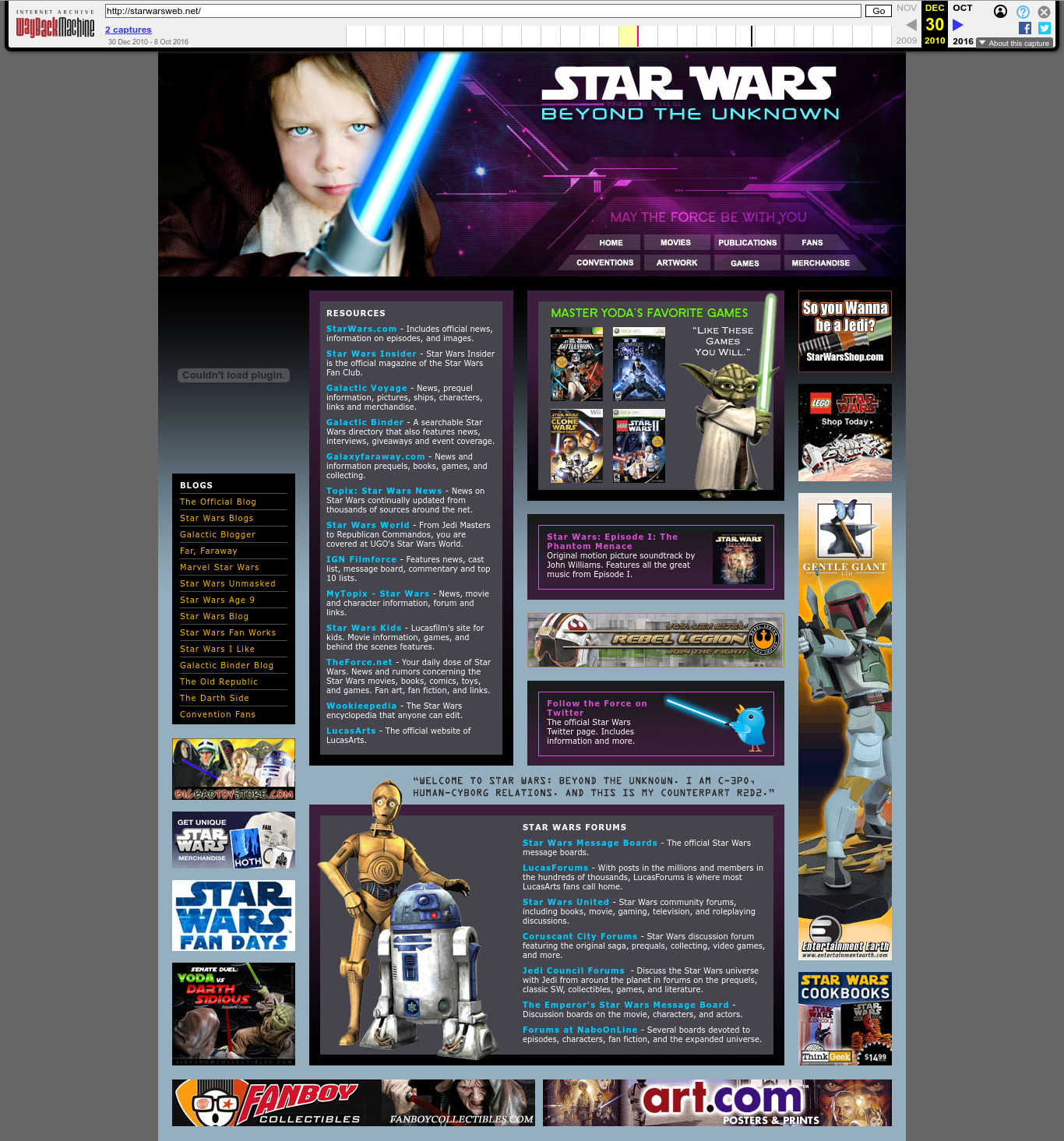
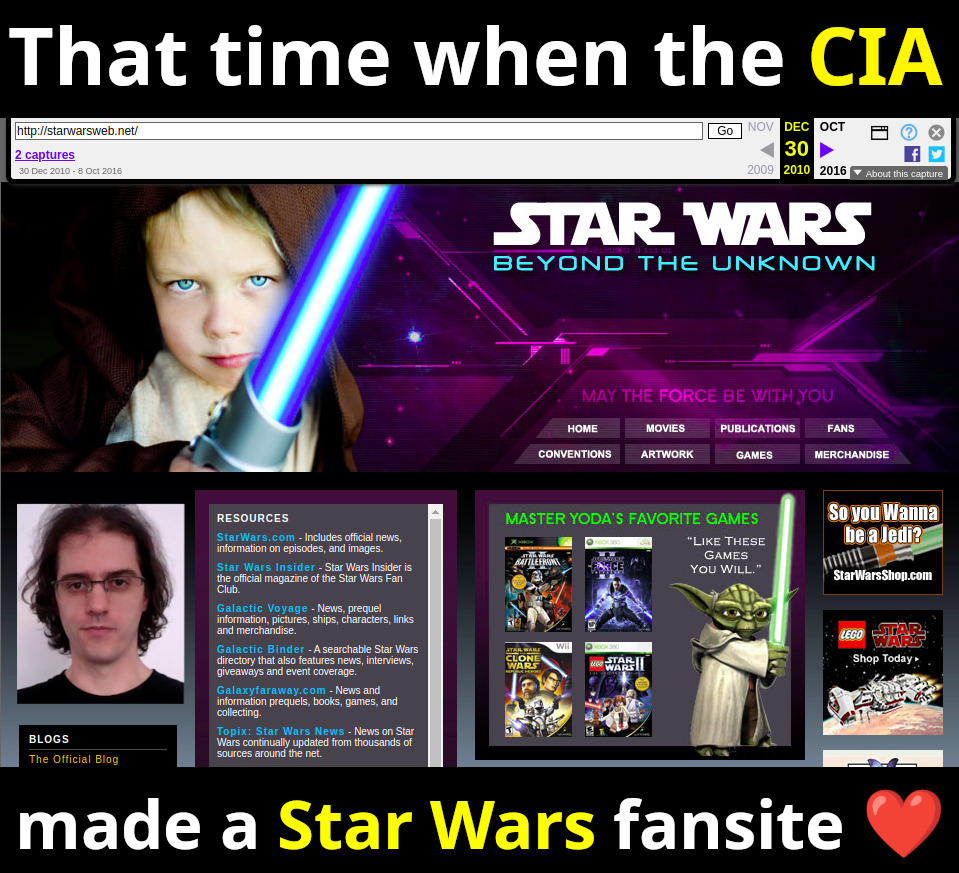
2010 Wayback Machine archive of starwarsweb.net
. The Star Wars one. Clearly branded websites like this are rare, which makes finding them all the much more fun. The Reuters article had two of them (Carson and rastadirect.net), so these were probably manually selected from the full hit dataset, and did not serve specifically as entry points. Most of the websites are quite boring and forgetful as you'd expect.
The subtitle "Beyond The Unknown" may be a reference to the Unknown Regions, an unexplored area of the galaxy in the Star Wars fictional universe.

The photo can still be licensed today as of 2025: www.gettyimages.co.uk/detail/photo/little-jedi-royalty-free-image/172984439. We found it by searching for "jedi boy" on gettyimages.co.uk. The photo is credited to a
madisonwi, presumably an alias based on the location Madison, Wisconsin. Here's a random website about adoption that uses it: www.adoptionadvocates.net/star-wars-adoption-language/ and where it can be seen without the watermarks.It later ocurred to Ciro Santilli that perhaps Reuters chose not to showcase this website because it features the photograph of a minor. But Ciro is sure that that minor is now a handsome young man in his 20's and would find the entire story very amusing if he ever finds out about it!
The images of the droids can be seen e.g. at: www.amazon.co.uk/04-Kampf-Droiden-Superheftig-Jedi/dp/B004TINSW6, a promotional material for a 2008 The Clone Wars television series audio CD and available as transparent PNGs without background in several sources. The Yoda art also seems to come from that show: rpggamer.org/page.php?page=4229.
One can almost picture the contractor who made that site seeing his children watching that show or playing the video game one evening, when a lightbulb popped over their head: tomorrow I'm going to have some fun at work.
In retrospect however, this website was likely a bad idea, since the massive pop culture appeal of Star Wars meant that when The CIA Secretly Ran a Star Wars Fan Site by Joseph Cox was published in 2025 the combination of "CIA" and "Star Wars" on a single sentence produced an irresistible clickbait that amplified knowledge of the fiasco to general public in a way that poor Johnny Carson and Bob Marley could never do. That's why you just can't have fun while working for the secret services anymore.

2011 Wayback Machine archive of alljohnny.com
. Source. Although alljohnny.com is one of the original Reuters examples, we are highlighting this screenshot here because the Reuters provided screenshot is from the extremely early 2004 version of the site, and it is interesting to see how this unique example was later updated in this 2011 version, the only known such case so far. The lack of OPSEC awareness is mind blowing, them reusing a domain like that after so many years in a completely new threat environment and possibly for a new asset.
2011 Wayback Machine archive of webofcheer.com scrolled to show Johnny Carson
. Source. This website is a fansite for various comedians. It is the second known reference to Johnny Carson after alljohnny.com, which was one of the original screenshots given in the Reuters article. There must have been some massive Johnny Carson fan among the CIA contractors a that time!
2011 Wayback Machine archive of iranfootballsource.com
. The third Iranian football on top of the two other published by Reuters: iraniangoalkicks.com and iraniangoals.com! Admittedly, this one is the most generic and less well designed one. But still. They pushed the theme too far!
The goalkeeper can be seen at: www.pixtastock.com/illustration/7323632.

2010 Wayback Machine archive of dedrickonline.com
. The German one.
The CIA has had a few Germany espionage scandals in the 2010s:
- 2014 www.bbc.co.uk/news/world-europe-28243933: a German Intelligence Agency agent was arrested for spying for the CIA
- 2021 www.reuters.com/world/europe/us-security-agency-spied-merkel-other-top-european-officials-through-danish-2021-05-30/ U.S. spied on Merkel and other Europeans through Danish cables
- 2020 www.dw.com/en/how-the-uss-cia-and-germanys-bnd-spied-on-world-leaders/a-52358527 it was revealed that Germany and the USA had an agreement to spy on world leaders, notably via compromised Swiss company Crypto AG
2010 Wayback Machine archive of lesummumdelafinance.com
. The arrow graph is very popular can be seen at: www.financialexpress.com/money/top-4-global-market-risks-for-2024-that-may-impact-your-finances-3346284/ and many other sites. Source unknown.

2011 Wayback Machine archive of attivitaestremi.com
. An Italian one about extreme sports.
2010 Wayback Machine archive of noticiasmusica.net
. The Brazilian one.

2011 Wayback Machine archive of economicnewsbuzz.com
. The Korean one. Love the kawaii style!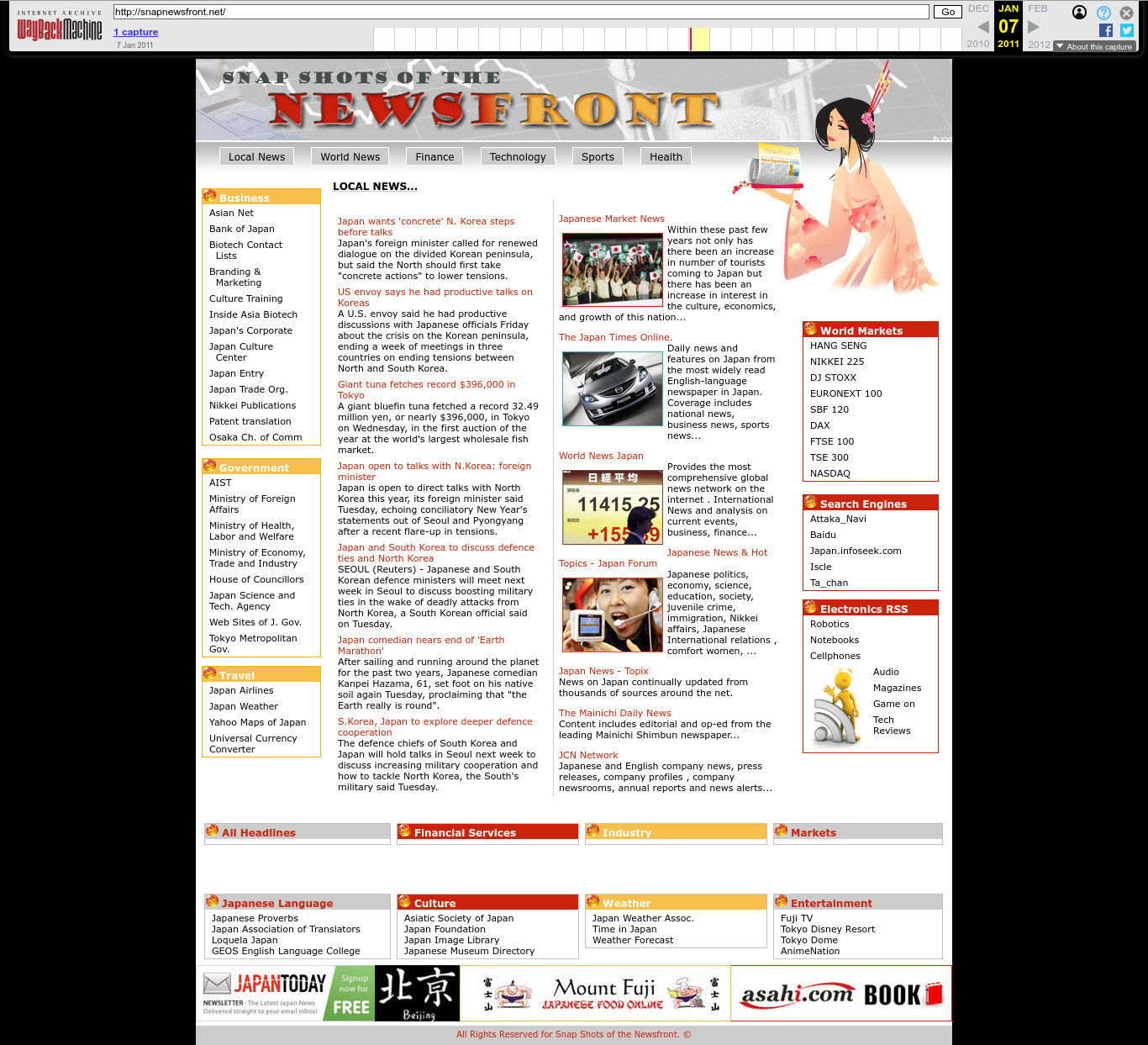
2011 Wayback Machine archive of snapnewsfront.net
. The Japanese one.
The geisha can be seen at: www.shutterstock.com/image-vector/pretty-geisha-16813348 by Larisa Frelke, assumed accounts: x.com/larra_vit | www.xing.com/profile/Larisa_Frelke

2010 Wayback Machine archive of philippinenewsonline.net
. The Philippine one one.
2011 Wayback Machine archive of feedsdemexicoyelmundo.com
. The Mexican one.
2012 Wayback Machine archive of easytraveleurope.com
. 
2011 Wayback Machine archive of tee-shot.net
. One of the many golf-themed sites. Golf appears to be quite popular over in Langley. It's exactly what you'd expect for a mid-level spook to do in their free time!
2011 Wayback Machine archive of nouvellesetdesrapports.com
. 
2011 Wayback Machine archive of pangawana.com
. 
2011 Wayback Machine archive of recuerdosdeviajeonline.com
. 
2011 Wayback Machine archive of theworld-news.net
. 
2011 Wayback Machine archive of kessingerssportsnews.com
. 
2011 Wayback Machine archive of negativeaperture.com
. Being Brazilian, Ciro Santilli was particularly curious about the existence of a Brazil-focused mentioned in the Reuters article, as well as in other democracies.
WTF the CIA was doing in Brazil in the early 2010s! Wasn't helping to install the Military dictatorship in Brazil enough!
Here are the websites likely targeting democracies based on their language and content found so far, defining a democracy as a country with score 7.0 or more in the Democracy index 2010:In English, so more deniable:"Almost democracies":Ciro couldn't help but feel as if looking through the Eyes of Sauron himself!
- France (6: affairesdumonde.com, guide-daventure.com, lesummumdelafinance.com, football-de-luxe.com, romulusactualites.com, suparakuvi.com)
- Germany(2: dedrickonline.com, neighbour-news.com)
- Italy (2: attivitaestremi.com, garanziadellasicurezza.com, podisticamondiale.com)
- Spain (3: armashoy.com, montanismoaventura.com, ordenpolicial.com)
- Brazil (2: noticiasmusica.net, vejaaeuropa.com)
- South Korea (1: economicnewsbuzz.com)
- Poland (1: boxingstop.net)
- Japan (1: snapnewsfront.net)
- Canada (2: kanata-news.com, mynewscheck.com)
- Philippines (1: half-court.net)
- India (1: amishkanews.com)
- Croatia (2: european-footballer.com, stara-turistick.com)
- Thailand (1: thefairwaysaregreen.com)
- Peru (1: todosperuahora.com)
It is worth noting that democracies represent just a small minority of the websites found. The Middle East, and Spanish language sites (presumably for Venezuela + war on drugs countries?) were the huge majority. But Americans have to understand that democracies have to work together and build mutual trust, and not spy on one another. Even some of the enlightened people from Hacker News seem to not grasp this point. The USA cannot single handedly maintain world order as it once could. Collaboration based on trust is the only way.
Snowden's 2013 revelations particularly shocked USA "allies" with the fact that they were being spied upon, and as of the 2020's, everybody knows this and has "stopped caring", and or moved to end-to-end encryption by default. This is beautifully illustrated in the 2016 film "Snowden" when Snowden talks about his time in Japan working for Dell as an undercover NSA operative:
NSA wanted to impress the Japanese. Show them our reach. They loved the live video from drones. This is Pakistan right now [video shows American agents demonstrating drone footage to Japanese officials]. They were not as excited about that we wanted their help to spy on the Japanese population. They said it was against their laws.And we did not stop there. Once we owned their communications systems, we started going after the physical infrastructure.We'd slip these little sleeper programs into power grids, dams, hospitals. The idea was that if the day came when Japan was no longer an ally, it would be "lights out".But Austria?!
But Austria?! scene from Snowden (2016)
. Source. Another noteworthy scene from that movie is Video 2. "Aptitude test on communication networks scene from the 2016 Snowden film", where a bunch of new CIA recruits are told that:thus somewhat mirroring what actually happened with these real world websites.
Each of you is going to build a covert communications network in your home city [i.e. their fictitious foreign target location written on each person's desk such as Berlin, Istanbul and Bangkok, not necessarily where they were actually born], you're going to deploy it, backup your site, destroy it, and restore it again.
This section contains a list of all the websites that we consider belong to the network beyond reasonable doubt.
The list is also available in JSON format at: github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/hits.json. When there are new additions we keep the JSON up to date with the help of the following OurBigBook Markup to JSON conversion helper ../cia-2010-covert-communication-websites/bigb-to-json:and new results that have been added to the list below can automatically be merged with ../cia-2010-covert-communication-websites/bigb-to-json-merge:We have also made a dump of the websites extracted from the Wayback Machine at: github.com/cirosantilli/cia-2010-websites-dump
cia-2010-covert-communication-websites/bigb-to-json cia-2010-covert-communication-websites.bigbcia-2010-covert-communication-websites/bigb-to-json-merge > tmp.json
mv tmp.json ../media/cia-2010-covert-communication-websites/hits.jsonThe main criteria to consider a website as a hit is for it to have a Wayback Machine archive with an archived communication mechanism. JS comms are always quickly visually inspected, other mechanisms we look only at filename patterns for now. We also consider as hits websites that don't have archived comms, often the case for CGI comms, but which have two ore more of the following supporting evidence:Commented edge cases that didn't make the cut can be found mostly under Section "IP range search" and Section "2013 DNS Census virtual host cleanup heuristic keyword searches".
- shares an IP range with other website
- a Wayback Machine archive or cqcounter screenshot strongly confirming visual style
- an archived broken link to the possible comms
| ip | domain | Wayback Machine | language | country mentions | comms | theme | notes |
|---|---|---|---|---|---|---|---|
| ? | 24hoursprimenews.com | 2009 | English | JAR | news | split images[ref][ref] | |
| ? | cyhiraeth-intlnews.com | 2011 | English | JAR | news | en.wikipedia.org/wiki/Cyhyraeth "The cyhyraeth is a ghostly spirit in Welsh mythology, a disembodied moaning voice that sounds before a person's death." WTF! So the serious looking black actress lady is meant to represent the voice of death?. Split images[ref][ref]. rss-items. Here she is on Getty Images: www.istockphoto.com/photo/natural-style-for-the-individual-gm171403107-26684547 by Urilux | |
| ? | dailynewsandsports.com | 2013 | English | JAR | sports | ||
| ? | differentviewtoday.com | 2011 | English | JAR | news | split images, JAR unarchived | |
| ? | euronewsonline.net | 2010 | English | JAR | news | a.newslink. The image of the woman reading newspapers reverse searches to www.istockphoto.com/photo/news-gm101581053-7410445, iStock from Getty images. Copyright 2007. | |
| ? | europeannewsflash.com | 2011 | English | JAR | news | Split images[ref][ref] | |
| ? | farsi-newsandweather.com | 2011 | Farsi | Iran | JAR | news | split images[ref][ref] |
| ? | financecentraltoday.com | 2011 | English | JAR | news, finance | unusual td > p > strong article list. Copyright 2008. | |
| ? | firstnewssource.com | 2011 | Farsi | Iran | JAR | news | Copyright 2009. Split images. rss-items. |
| ? | global-view-news.com | 2011 | English | JAR | news | split images[ref][ref] | |
| ? | globaltourist.net | 2010 | English | JAR | travel | split images[ref][ref], rss-items. speed.jar "speed test" JAR pattern. The split headers have a weird style however <li><a id="banner1"> </a></li> and then filled with a CSS background image. This is a weird one, there is some chance that it is a legit website in the CIA style. Notably, at least as of August 2012 it had become a wordpress site marked "Just another Media Network Online Sites site", which is a bit early. Likely they just watch for good domain drops and take over quickly. The last in-style archive is from March 2012, which is first followed by a Godaddy parked domain on April 2012. This domain also has a 2003 archive which is almost certainly from the same authors as it also has a link to globaltourist.net/speed.jar and the upper left image is the same. Its history does however remember us of alljohnny.com, which had its 2004 version and then a 2010 rehash. Both of these versions contain ImageReady Slices mentions in them, characteristic of the split header images fingerprint. | |
| ? | hassannews.net | 2010 | Arabic | SWF | news | CSS or archive quite broken. Split images[ref][ref]. rss-items. cqcounter.com/whois/www/hassannews.net.html not found. The arabic title is "حسن الأخبار" (good news) and the domain seems to be a transliteration of it. | |
| ? | health-men-today.com | 2011 | Arabic | JAR | news | rss-items. Encoding broken. cqcounter.com/whois/www/health-men-today.com.html also broken. Same registrar as medicatechinfo.com: Jason Noll IP and DNS metadata. Closely related stock model image comically used as the image of the Gay Arab Central community on the. Copyright 2008. | |
| ? | inkfreenews.com | 2011 | English | JAR | news | split images, JAR unarchived | |
| ? | internationalnewsworthiness.com | 2011 | English | JAR | news | RSS, split images, JAR unarchived | |
| ? | intlnewsdaily.com | 2011 | English | JAR | news | rss-items | |
| ? | intoworldnews.com | 2011 | English | JAR | news | split images. Links to news websites from frontpage, not news themselves. | |
| ? | iranfootballsource.com | 2011 | Farsi | JS | sports, football | ||
| ? | iraniangoalkicks.com | 2008 | Farsi | Iran | JAR | sports, football | |
| ? | iraniangoals.com | 2009 | Farsi | Iran | JS | sports, football | |
| ? | latinamericanewsbeat.com | 2010 | English | JAR | news | split images. Also has an archived "register" link at the bottom: web.archive.org/web/20101114045007/http://latinamericanewsbeat.com/register.html but it reads "We are currently unable to register new members while we upgrade our site. Please check back soon." | |
| ? | magneticfieldnews.com | 2010 | English | JAR | news | rss, split images | |
| ? | middle-east-newstoday.com | 2010 | Farsi | JS | news | rss, split images | |
| ? | mideasttoday.net | 2010 | Farsi | JAR | news | a.rss-item, split images, copyright 2008 | |
| ? | mydailynewsreport.com | 2011 | Pashto | Afghanistan | JAR | news | rss, split images |
| ? | mynepalnews.com | 2011 | English | JAR | news | Split images with <li><a id="banner1"> </a></li> style. Nice swimsuit ad. The bottom bar "Copyright © 2008 My Nepal News, LLC. All Rights Reserved." is also kind of typical, see e.g. web.archive.org/web/20110208042144/http://helpinghandssite.com/, both have <!-- begin #footer --> and <div id="footer">. ingenuitytrendz.com is another closely related template. One ridiculously mind blowing thing about this website is the presence of Webalizer reports under /stats e.g.: /stats. This fact is so mind blowing that it makes us question if this an actual hit or just style coincidence. Particularly ridiculous is the presence of inurl:cgi server_software at web.archive.org/web/20110204095809/http://mynepalnews.com:80/stats/usage_200805.html which is almost certainly a Google dork search, which we know is something that the Iranians used to find the websites. Also of interest are link backs from at web.archive.org/web/20110204095815/http://mynepalnews.com:80/stats/usage_200806.html from whois.domaintools.com/mynepalnews.com and www.whois.sc/mynepalnews.com That search hits under /cgi-bin/check.cgi. That page is itself os some interest containing SERVER_ADMIN = mmadev@mmadev.com. web.archive.org/web/20110204095815/http://mynepalnews.com:80/stats/usage_200806.html also reveals several request IPs. Even if this is not a CIA website, there's a chance we could find the IP of the Iranian counter-intelligence in these IP list, it's mind blowing. And if a hit, we could also find IPs used by CIA handlers to see if the website is working. Lot's of referrer spam too as well. | |
| ? | newdaynewsonline.com | 2011 | English | JAR | news | ||
| ? | networkconnectionsite.com | 2011 | English | JS | news | rss, split images | |
| ? | news-latina.com | 2011 | English | JAR | news | copyright 2007 | |
| ? | newsdelivered.net | 2010 | English | JAR | news | rss, split images, JAR unarchived | |
| ? | newsincirculation.com | 2011 | Arabic | JAR | news | ||
| ? | newsworldsite.com | 2011 | Pashto | Afghanistan | JAR | news | |
| ? | opensourcenewstoday.com | 2010 | Arabic | JAR | news | copyright 2010 | |
| ? | outlooknewscast.com | 2011 | Farsi | Iran | JAR | news | |
| ? | pars-technews.com | 2011 | Farsi | Iran | JAR | news | "pars" presumably means "Parsi" or something of the same root |
| ? | pondernews.net | 2011 | Arabic | JAR | news | rss. Some archived pages use unusual paths such as /lldwg/qlaqft.php?fc=282910. | |
| ? | profile-news.com | 2011 | English | JAR | news | a.newslink | |
| ? | purlicue-news.com | 2011 | English | JAR | news | split images, rss | |
| ? | segomonews.com | 2011 | English | JAR | news | rss, split images. TODO meaning of "segomo"? The main Wikipedia hit is a Gallo-Roman God, but the website is focused on Asia? | |
| ? | shadesofnews.com | 2011 | Arabic | JAR | news | a.rss-item, split images. Also has a second from 2013 JAR at: web.archive.org/web/20131229092754/http://shadesofnews.com/sptgms213.jar and a raw .class crime.Business.class which replies with "The requested document was not found on this server". Copyright 2009. | |
| ? | sportsnewsfinder.com | 2011 | Chinese | China | JAR | news | 体育新闻发现者 (sports news finder) |
| ? | techwatchtoday.com | 2011 | English | JAR | tech, news | Marked copyright 2008. Split images[ref][ref]. Later legit. | |
| ? | terrain-news.com | 2011 | Pashto | Afghanistan | JAR | news | |
| ? | todayoutdoors.com | 2011 | English | JAR | sports, travel | split images[ref][ref] | |
| ? | todaysnewsreports.net | 2010 | Arabic | JAR | news | ||
| ? | weblognewsinfo.com | 2011 | English | JAR | news | Split images, rss-items. | |
| ? | wiredworldnews.com | 2011 | English | JAR | tech | split images, copyright 2008 | |
| 62.22.60.40 | travel-passage.com | 2011 | English, Chinese | travel | No Wayback Machine archives of toplevel, only of the 航空 Flight Reservations subpage: web.archive.org/web/20091118013330/http://travel-passage.com:80/service-flights.htm. The link to it can be seen from the cqcounter screenshot. The page contain an unusual mixture of Chinese and English. The Chinese title is 游行连接 (lit. travel connection) | ||
| 62.22.60.42 | newsupdatesite.com | 2011 | English | JAR | news | split images, rss-item. JAR unarchived. | |
| 62.22.60.46 | flyingtimeline.com | 2011 | English | JAR | airplanes | ||
| 62.22.60.48 | currentcommunique.com | 2011 | English | Egypt | SWF | news | |
| 62.22.60.49 | telecom-headlines.com | 2011 | English | JS | tech | ||
| 62.22.60.52 | collectedmedias.com | 2011 | French | JS | news | Marked copyright 2008 | |
| 62.22.60.54 | romulusactualites.com | 2011 | French | France | news | ||
| 62.22.60.55 | thefilmcentre.com | 2011 | English | JS | films | ||
| 62.22.60.56 | traveltimenews.com | 2011 | English | JS | news | ||
| 62.22.61.193 | awfaoi.org | 2010 | Arabic | Iraq | JAR | not-for-profit | This was the first clear .org hit with comms we've been able to find. Title translation: "Arab women to help Iraq", so perhaps "awfaoi" stands for "Arab Women For A O? Iraq". This fits well into the .org theme. Marked copyright 2008. |
| 62.22.61.197 | rc5sports.com | 2011 | English | JAR | sports | ||
| 62.22.61.198 | inside-vc.com | 2011 | English | CGI | finance | "vc" is a standard abbreviation for venture capital. Previously legit circa 2004: web.archive.org/web/20030306171752/http://www.inside-vc.com/ | |
| 62.22.61.200 | zerosandonesnews.com | 2011 | English | SWF | news | rss, split images | |
| 62.22.61.202 | bailsnboots.com | 2011 | English | SWF | sports, cricket | "Bail" is one part of the thing your're supposed to hit with th eball in cricket.[ref] | |
| 62.22.61.203 | the-cricketer-online.com | 2011 | English | JAR | sports, cricket | marked copyright 2009. | |
| 62.22.61.204 | hollywoodscreen.net | 2011 | English | JS | films | ||
| 62.22.61.206 | worldnewsnetworking.com | 2011 | Arabic | JAR | news | ||
| 62.22.61.212 | nuestrasfinanzas.com | 2011 | Spanish | JAR | finance | ||
| 62.22.61.213 | sandstormnews.com | 2011 | Arabic | SWF | news | rss, split images | |
| 62.22.61.215 | the-tech-mind.com | 2011 | English | technology, news | Welcome to the US Petabox on Wayback Machine. | ||
| 62.22.61.217 | court-masters.com | 2011 | English | JAR | sports, tennis | ||
| 62.22.61.219 | allworldstatistics.com | 2011 | English | JS | statistics | ||
| 62.22.61.220 | newsjaka.com | 2011 | English | Indonesia | JS | news | "jaka" presumably means Jakarta, the capital of Indonesia. There is a Indonesia section on the left sidebar. But the news are quite global however. Photo source: www.shutterstock.com/image-photo/little-boat-on-bratan-lake-front-5860873 depicts "Bratan lake in front of the Pura Ulu Danau temple" by Ine Beerten. Pinged her at: portfolio.inebeerten.be/#Contact |
| 63.131.229.2 | fightskillsresource.com | 2011 | English | JS | sports, martial arts | Getty Images for the karate dude: www.istockphoto.com/photo/take-off-gm98702037-1196239 | |
| 63.131.229.4 | unitedterritorynews.com | 2011 | English | JS | news | ||
| 63.131.229.9 | show-dustry.com | 2011 | English | CGI | entertainment | The website name is a neologism with "show" and "industry". | |
| 63.131.229.11 | mythriftytrip.com | 2010 | English | CGI | travel | thrifty means: "using money and other resources carefully and not wastefully" | |
| 63.131.229.12 | cyberreportagenews.com | 2011 | English | JAR | news | rdns source | |
| 63.131.229.13 | sunrise-news.com | 2011 | English | JAR | news | rdns source | |
| 63.131.229.15 | cricketnewsforindia.com | 2013 | English | India | JS | sports, cricket | archive quite broken, lots of missing files, including the JS. cqcounter.com/whois/www/cricketnewsforindia.com.html in style. |
| 63.131.229.16 | nutricion-saludable.net | 2010 | Spanish | CGI | health | Also under nutricion-saludable.info. There is weirdly a single page archived from 2008: epages/nutricion-saludable_net.sf with this weird .sf extension. It is HTML however. It says: "Lo sentimos, la tienda está actualmente cerrada por razones técnicas. Pronto estaremos a tu disposición. Si lo deseas puedes ponerte en contacto con nosotros en el tel: 651 80 76 19". This appears to be a spanish phone number: without country code, which would be +34[ref]. | |
| 63.131.229.20 | fixashion.net | 2011 | English | JS | fashion | ||
| 63.130.160.50 | theglobalheadlines.com | 2010 | English | JAR | news | this has several archives from 2013, marked as Live Web Proxy Crawls and explained "mostly by the Save Page Now", so presumably by counter intelligence or amateurs | |
| 63.130.160.51 | hai-pow.com | 2011 | English | JAR | sports, martial arts | ||
| 63.130.160.53 | echessnews.com | 2011 | Chinese | China | JAR | sports, boxing | Chinese title: 我的象棋世界 (My Chinese Chess world). rdns source. Split images[ref][ref] |
| 63.130.160.60 | boxingstop.net | 2010 | Polish | Poland | JAR | sports, boxing | |
| 63.130.160.61 | bookmarksthis.com | 2010 | English | JAR | books | A book review website. Shows a stock model reading a book and their signature black print over decorations on top | |
| 63.130.160.62 | azerinews.org | 2009 | Azerbaijani | Azerbaijan | JAR | news | rdns source. Split images, rss-items. "Azeri" is a word that denotes the people from the region of Azerbaijan. |
| 64.16.204.53 | bosniakbusinessnews.com | 2011 | English | Bosnia | business | A Bosniak is someone from an ethnicity from Bosnia | |
| 64.16.204.54 | affairesdumonde.com | 2011 | French | news | |||
| 64.16.204.55 | holein1news.com | 2010 | English | JAR | sports, golf | ||
| 64.16.204.58 | tech-topix.com | 2013 | English | CGI | tech | Archive quite broken, but link to CGI comms. Copyright 2010. cqcounter.com/whois/www/tech-topix.com.html not found. | |
| 65.61.127.161 | european-footballer.com | 2011 | Croatian | Sports, football | Broken Wayback Machine archive: web.archive.org/web/20110319111233/http://european-footballer.com/. The title was "Europski Nogometaš" (European football player). The CQ Counter screenshot clarifies that the surviving Wayback Machine archive contains only a sidebar. It is unlikely to contain comms therefore. | ||
| 65.61.127.163 | capture-nature.com | 2011 | English | JAR | photography | Reuters example. Since became legitimate, Ciro contacted the owner, and he was unaware of the domain's history. | |
| 65.61.127.166 | globalnewsbulletin.com | 2013 | English | Tunisia, Afghanistan, Iran, Egypt | CGI | news | PHP pages, images /images/index_01.jpg |
| 65.61.127.167 | internationalwhiskylounge.com | 2011 | English | CGI | news | No Wayback Machine archives. There's a "Log-in" tab so CGI comms likely. Stock image used of young woman with a glass of Whisky: www.istockphoto.com/photo/the-girl-with-glass-of-whisky-gm94997193-11328059 by alarich | |
| 65.61.127.168 | the-golden-rule.info | 2011 | English | finance, news | Website error archived at: web.archive.org/web/20131011012026/http://the-golden-rule.info/ | ||
| 65.61.127.169 | crossovernews.net | 2011 | English | JAR | sports, basketball | ||
| 65.61.127.170 | newsidori.com | 2011 | English | news | Very broken 2013 archive: web.archive.org/web/20130714134510/http://www.newsidori.com/. "Idori" sounds Japanese, but the meaning is unclear even after the cqcounter screenshot! It's just random US news, nothing to do with Japan. | ||
| 65.61.127.171 | nrgconsultingandnews.com | 2011 | English | news | It is in English but contains several mentions of Brazil. Entitled: "Energy Consulting News Forum" | ||
| 65.61.127.171 | premierstriker.com | 2011 | English | sports, football | No Wayback Machine archives from the time, and has been since parked by something apparently as of 2022 onwards. Entiled "Premier striker" | ||
| 65.61.127.174 | dedrickonline.com | 2010 | German | JS | sports | ||
| 65.61.127.175 | altworldnews.com | 2013 | English | CGI | news | Epoch times link, PHP pages | |
| 65.61.127.176 | american-historyonline.com | 2011 | English | history | No Wayback Machine archives | ||
| 65.61.127.177 | material-science.org | 2009 | English | science, material science | No comms found, and slightly innovative design. Comms could be CGI under web.archive.org/web/20091213032538/http://material-science.org/services.htm or web.archive.org/web/20091213032538/http://material-science.org/equipment.htm. But marking it as hit because .rss-item + IP range. | ||
| 65.61.127.178 | tee-shot.net | 2011 | English | SWF | sports, golf | nice domain name | |
| 65.61.127.180 | screencentral.inf | 2011 | English | Afghanistan | cinema | Rather innovative design, but hit likely. Welcome to US Petabox: web.archive.org/web/20130713224951/http://screencentral.info/. | |
| 65.61.127.181 | worldnewsandtravel.com | 2011 | English | news | No Wayback Machine archives | ||
| 65.61.127.182 | pangawana.com | 2011 | Arabic | Afghanistan | JS | news | |
| 65.61.127.183 | cutabovenews.com | 2011 | English | Algeria, various others | JS | sports, basketball | The globe on Shutterstock: www.shutterstock.com/image-illustration/creative-drawing-charts-graphs-business-success-211092952 by rzoze19. Pinged him at: x.com/cirosantilli/status/1899748328549609700 |
| 65.61.127.184 | worldwildlifeadventure.com | 2011 | English | JAR | travel | ||
| 65.61.127.186 | explorealtmeds.com | 2013 | English | JAR | health | the JAR was not archived, but there's a link to it | |
| 65.218.91.9 | rolling-in-rapids.com | 2010 | English | sports, kayak | Found by searching for "Glaze, L.", registrar of alljohnny.com, on tools.whoisxmlapi.com/reverse-whois-search | ||
| 65.218.91.9 | welcometonyc.net | 2010 | English | CGI | travel | ||
| 65.218.91.17 | alljohnny.com | 2004 | English | CGI | fansite | mega early hit from 2004 to 2005. Then a gap, then they redid the domain: 2011. Same authors given content similarities e.g. "Submit Your Favorite Carson Moment". Reusing the domain after all these years, the lack of OPSEC is just mind blowing! New website marked Copyright 2003. Part of Oleg Shakirov's findings. One of the Reuters websites. Search documented at: Searching for Carson. Carson is also featured, although less proeminently, at webofcheer.com. There must have been some massive Johnny Carson fan among the contractors a that time! | |
| 66.45.179.192 | thegraceofislam.com | 2011 | English | CGI | religion, Islam | ||
| 66.45.179.193 | arabicnewsunfiltered.com | 2011 | Arabic | JAR | news | rdns source | |
| 66.45.179.194 | raulsonsglobalnews.com | 2011 | English | JAR | news | ||
| 66.45.179.195 | aryannews.net | 2010 | Pashto | Afghanistan | JAR | news | rdns source. Heil. |
| 66.45.179.199 | attivitaestremi.com | 2011 | Italian | CGI | sports | ||
| 66.45.179.200 | foodwineandsuch.com | 2011 | English | food | No Wayback Machine archives. Entitled "Food, wine & such". | ||
| 66.45.179.201 | hitthepavementnow.com | 2011 | English | CGI | sports, running | ||
| 66.45.179.202 | newimages.org | 2011 | Turkish | Turkey | JAR | photography | JAR unarchived |
| 66.45.179.203 | noticiascontinental.com | 2011 | Spanish | South America | CGI | news | |
| 66.45.179.205 | noticiasporjanua.com | 2011 | Spanish | JAR | news | ||
| 66.45.179.206 | podisticamondiale.com | 2010 | Italian | Italy | JAR | sports, running | marked copyright 2010 |
| 66.45.179.207 | reflectordenoticias.com | 2011 | Spanish | JAR | news | ||
| 66.45.179.208 | havenofgamerz.com | 2011 | English | CGI | gaming | marked copyright 2009 | |
| 66.45.179.209 | vejaaeuropa.com | 2011 | Brazilian Portuguese | Brazil | travel | web.archive.org/web/20130810131440/http://www.vejaaeuropa.com/: Welcome to the US Petabox. cqcounter.com/whois/www/vejaaeuropa.com.html confirms Brazilian Portuguese. Entitled "Veja a Europa" (Visit Europe, lit. See Europe) | |
| 66.45.179.210 | sa-michigan.com | 2011 | English | JAR | sports | "sa" is an abbreviation for the site title "Sports Alive" | |
| 66.45.179.211 | absolutebearing.net | 2010 | English | CGI | travel, sports, boats | ||
| 66.45.179.213 | myportaltonews.com | 2011 | English | JS | news | ||
| 66.45.179.214 | investmentintellect.com | 2011 | English | JAR | finance | ||
| 66.45.179.215 | nigeriastar.net | 2011 | English | Nigeria | JAR | news | Contains link to unarchived JAR |
| 66.104.169.163 | doctorsoncallsite.com | 2011 | English | JAR | health | ||
| 66.104.169.164 | lightandshadowonline.com | 2010 | English | JAR | photography | ||
| 66.104.169.168 | plugged-into-news.net | 2010 | English | JAR | news | JAR uses .zip extension! First instance, wow | |
| 66.104.169.169 | worldsportsite.com | 2011 | Arabic | sports | Comms not found. rss-items, split images. Has some apparently unrelated archives from 2008: web.archive.org/web/20080617213238/http://www.worldsportsite.com:80/ | ||
| 66.104.169.171 | golf-on-holiday.com | 2011 | English | JAR | sports, golf | ||
| 66.104.169.172 | perspectiva-noticias.com | 2011 | Spanish | JS | news | ||
| 66.104.169.175 | aquaswimming.com | 2009 | English | JAR | sports, swimming | ||
| 66.104.169.177 | dojo-temple.com | 2011 | English | CGI | sports, martial arts | TODO meaning of "kama"? Kama lol? | |
| 66.104.169.179 | neighbour-news.com | 2010 | English | Germany | JAR | news | Mentions of Goethe-Institut and Germany all over. JAR unarchived |
| 66.104.169.180 | medicatechinfo.com | 2010 | English | JS | health | ||
| 66.104.169.181 | brickmanfinancialnews.com | 2011 | English | JS | finance | ||
| 66.104.169.182 | casanewsnow.com | 2011 | English | JAR | JAR unarchived. TODO why "casa"? Doesn't seem to have any link to Spanish or Portuguese. | ||
| 66.104.169.184 | bcenews.com | 2011 | Albanian | Albania | JAR | news | Used to be a legit Korean website circa 2004: web.archive.org/web/20030401214602/http://www.bcenews.com/ |
| 66.104.173.163 | runakonews.com | 2011 | English | Africa | CGI | news | "Runako" is an African given name. |
| 66.104.173.164 | shoppingadventure.net | 2010 | English | JAR | travel, shopping | JAR unarchived | |
| 66.104.173.165 | entertaining-ly.com | 2011 | English | JAR | entertainment | ||
| 66.104.173.166 | zubeenews.com | 2011 | English | JS | news | "Zubee" is a Muslim name: muslimnames.com/zubee. | |
| 66.104.173.169 | smart-financeology.com | 2011 | English | JAR | finance | ||
| 66.104.173.173 | worldfeedstoday.com | 2011 | English | news | No main page Wayback Machine archives. Subpage archive: 2011 has a.newslink. Slightly innovative style with multi-language tabs. There is some potential for error, but let's consider it. world-newsfeeds.com also known on same IP but with no known archives. | ||
| 66.104.173.175 | media-coverage-now.com | 2010 | English | SWF | news | ||
| 66.104.173.176 | jbc-online-news.com | 2011 | English | JS | news | TODO meaning of "JCB". JS unarchived. | |
| 66.104.173.177 | webscooper.com | 2011 | English | JAR | news | ||
| 66.104.173.178 | dk-dcinvestment.com | 2010 | English | JAR | finance | TODO meaning of "dk;dc". | |
| 66.104.173.179 | newsforthetech.com | 2011 | English | news, tech | Welcome to the US Petabox. | ||
| 66.104.173.180 | stara-turistick.com | 2011 | Croatian | JAR | tourism | ||
| 66.104.173.181 | playbackpolitics.com | 2011 | English | JS | news | ||
| 66.104.173.182 | snapnewsfront.net | 2011 | English | Japan | JS | news | |
| 66.104.173.183 | ingenuitytrendz.com | 2011 | English | JAR | tech | ||
| 66.104.173.184 | armashoy.com | 2011 | Spanish | Spain | SWF | guns | meaning: "Weapons Today". In First World countries the CIA felt it would be safe to touch edgier subjects like guns |
| 66.104.173.185 | baocontact.com | English | JAR | HTML archive almost empty, but JAR was archived. One wonders what "bao" refers to, could be Chinese, but the small snippet of visible website is in English. | |||
| 66.104.173.186 | myworldlymusic.com | 2011 | English | Pakistan | JAR | music | JAR unarchived |
| 66.104.173.189 | hitpoint-gaming.com | 2011 | English | JS | gaming | Marked copyright 2010 | |
| 66.104.175.34 | itwebtoday.com | 2011 | English | JS | tech | ||
| 66.104.175.35 | drglobalnews.com | 2011 | English | JAR | news | TODO meaning of "dr"? rdns source. | |
| 66.104.175.36 | adilnews.net | 2010 | Arabic | SWF | news | Adil is an Arabic masculine name | |
| 66.104.175.40 | beyondnetworknews.com | 2011 | English | Egypt | CGI | news | |
| 66.104.175.41 | grubbersworldrugbynews.com | 2011 | English | JS | sports, rugby | ||
| 66.104.175.42 | news-and-sports.com | 2011 | English | JAR | news | rss, split images | |
| 66.104.175.44 | yourtripfinder.net | 2010 | English | travel | comms not found, CGI from unarchived subpage assumed | ||
| 66.104.175.45 | rollinsnetwork.com | 2011 | English | CGI | tech | Archive quite broken. CGI linked to but not archived. Seems to have been legit circa 2006. cqcounter.com/whois/www/rollinsnetwork.com.html empty from 2025. | |
| 66.104.175.46 | infosharenews.com | 2011 | English | JAR | news | ||
| 66.104.175.47 | southasiaheadlines.com | 2011 | English | Bangladesh, Bhutan, India, Maldives, Nepal, Pakistan, Sri Lanka Tibet | JAR | travel | JAR linked to but missing from archive |
| 66.104.175.48 | worlddispatch.net | 2010 | Arabic | SWF | news | ||
| 66.104.175.49 | webworldsports.com | 2011 | Arabic | JAR | sports | ||
| 66.104.175.50 | fly-bybirdies.com | 2011 | English | JAR | travel | ||
| 66.104.175.51 | businessexchangetoday.com | 2011 | English | CGI | news, finance | PHP pages | |
| 66.104.175.52 | mensajeradenoticias.com | 2011 | Spanish | CGI | news | CGI unarchived | |
| 66.104.175.53 | info-ology.net | 2010 | English | JAR | news | ||
| 66.104.175.54 | marketflows.net | 2011 | English | JAR | finance | ||
| 66.104.175.57 | metanewsdaily.com | 2010 | English | CGI | news | ||
| 66.175.106.134 | paddlescoop.com | 2011 | English | Bangladesh, Pakistan, India, England | JAR | sports, cricket | |
| 66.175.106.137 | kessingerssportsnews.com | 2010 | English | JS | sports | ||
| 66.175.106.138 | factorforcenews.com | 2009 | English | JAR | news | ||
| 66.175.106.142 | kanata-news.com | 2010 | English | Canada | JS | news | "Kanata" is a place in Ottawa, Canada. The name is likely of Indigenous origin. |
| 66.175.106.143 | thecricketfan.com | 2011 | English | JAR | news | ||
| 66.175.106.146 | inews-today.com | 2011 | English | Egypt | JAR | news | Marked copyright 2008 |
| 66.175.106.147 | starwarsweb.net | 2010 | English | SWF | fansite | well, not even the CIA can escape Star Wars. TODO identify boy. | |
| 66.175.106.148 | activegaminginfo.com | 2011 | Chinese | JAR | gaming | the website is entitled "活跃游戏" which means "Lively games", or "active games" as in the domain name itself. The center character seems to be from one of the infinitely many Romance of the Three Kingdoms games that must exist: www.gamersky.com/news/200711/82611.shtml | |
| 66.175.106.149 | feedsdemexicoyelmundo.com | 2011 | Spanish | Mexico | JS | news | |
| 66.175.106.150 | noticiasmusica.net | 2010 | Brazilian Portuguese | Brazil | JAR | music | |
| 66.175.106.155 | atomworldnews.com | 2011 | English | Egypt | JAR | news | |
| 66.175.106.158 | nouvellesetdesrapports.com | 2011 | French | Egypt, Tunisia | JAR | news | |
| 66.237.236.227 | newsandmusicminute.com | 2011 | Pashto | JS | music | ||
| 66.237.236.229 | pearls-playlist.com | 2011 | English | SWF | music | ||
| 66.237.236.230 | beyondthefringe.info | 2012 | English | JAR | rugs | JAR unarchived | |
| 66.237.236.231 | primetimemovies.net | 2009 | English | JS | films | JS unarchived | |
| 66.237.236.235 | persephneintl.com | 2013 | JAR | archive very broken, JAR unarchived. Full title: "Persephne International", reference to Greek Goddess of "spring, the dead, the underworld, grain, and nature". cqcounter.com/whois/www/persephneintl.com.html shows us how it would have looked like. | |||
| 66.237.236.236 | directoalgrano.net | 2010 | Spanish | JAR | news | ||
| 66.237.236.240 | actualizaciondebeisbol.com | 2011 | Spanish | JS | sports, baseball | ||
| 66.237.236.243 | mygadgettech.com | 2009 | Chinese | CGI | tech | Archive very broken. cqcounter.com/whois/www/mygadgettech.com.html shows it better. The Chinese title was "我的灵巧技术". | |
| 66.237.236.247 | comunidaddenoticias.com | 2011 | Spanish | Ecuador | JAR | news | |
| 66.237.236.249 | sumerjaseahora.com | 2011 | Spanish | CGI | sports, SCUBA diving | submerge yourself now | |
| 69.84.156.69 | al-ashak-news-me.com | 2011 | Arabic | JS | news | ||
| 69.84.156.70 | theventurenews.info | 2011 | English | news | |||
| 69.84.156.71 | worldfinancetoday.net | 2011 | English | JAR | finance | ||
| 69.84.156.72 | autonewsarabia.com | 2011 | Arabic | JAR | cars | ||
| 69.84.156.74 | blue-moon-news.com | 2011 | Arabic | JS | news | ||
| 69.84.156.76 | tnc-urdu.com | 2011 | Urdu | JAR | tech | TODO meaning of "tnc"? | |
| 69.84.156.80 | noticiasdenuestromundo.com | 2011 | Spanish | news | South America focus | ||
| 69.84.156.82 | arabicnewsonline.com | 2011 | Arabic | JAR | news | rdns source. Some very similar domains: modernarabicnews.com, arabicnewsource.com. Needed more creativity here! Later legit. | |
| 69.84.156.83 | unganadormundial.com | 2010 | Spanish | CGI | sports, fitness | ||
| 69.84.156.84 | focusonbokeh.com | 2011 | English | photography | No Wayback Machine archives or broken. The design is a bit innovative, but fuck it I'll mark it as a hit. Only a "Sony" logo remains: web.archive.org/web/20110207222330/http://focusonbokeh.com/images/logo_014.jpg A photography website "Focus on Bokeh" as suggested by the domain name. reimaginepeacefulparenting.com/make-kids-happy/ contains the cute stock Asian girl. "Login" link visible suggesting CGI comms. | ||
| 69.84.156.85 | classic-rocktopia.com | 2011 | English | music, rock | Stock image e.g. at: www.dissection.nu/frames.htm | ||
| 69.84.156.87 | i7diver.com | 2011 | English | diving | |||
| 69.84.156.88 | diariodeelmundo.com | 2011 | Spanish | JAR | news | ||
| 69.84.156.89 | todaysarabnews.com | 2011 | Arabic | JAR | news | JAR unarchived. | |
| 69.84.156.90 | stickshiftnews.com | 2011 | English | JAR | cars | ||
| 69.84.156.91 | theinternationalgoal.com | 2011 | Spanish | CGI | news | ||
| 72.34.53.174 | electronictechreviews.com | 2011 | English | JAR | tech | JAR unarchived. Split images, rss-items. Present at "Mass Deface III" pastebin. | |
| 72.34.53.174 | just-the-news.com | 2011 | Arabic | JAR | news | copyright 2009. Present at "Mass Deface III" pastebin. JAR unarchived. | |
| 72.34.53.174 | kickitnews.com | 2010 | Arabic | JAR | sports, football | copyright 2009. Present at "Mass Deface III" pastebin. | |
| 72.34.53.174 | moyistochnikonlaynovykhigr.com | 2011 | Russian | Russia | fansite | copy of myonlinegamesource.com, but on a Russian transliterated domain rather than the English one, very interesting | |
| 72.34.53.174 | myhealthlibrary.net | 2011 | English | JAR | health | present at: "Mass Deface III" pastebin. | |
| 72.34.53.174 | myonlinegamesource.com | 2011 | Russian | Russia | gaming | Can't find comms, but stylistically perfect. rss-items. Present at "Mass Deface III" pastebin. | |
| 72.34.53.174 | mytravelopian.com | 2011 | English | JAR | travel | ||
| 72.34.53.174 | recursosdenoticias.com | 2011 | Spanish | JAR | news | Split images, rss-items. Present at "Mass Deface III" pastebin. | |
| 72.34.53.174 | sayaara-auto.com | 2010 | Arabic | JAR | cars | ||
| 72.34.53.174 | technologytodayandtomorrow.com | 2011 | English | JAR | tech | rss-items. Present at "Mass Deface III" pastebin. | |
| 72.34.53.174 | todaysnewsandweather-ru.com | 2011 | Russian | Russia | JS | news | JavaScript with SHAs |
| 74.116.72.227 | dayenews.com | 2011 | English | JAR | news | rdns source. Previously 69.74.45.67. | |
| 74.116.72.229 | guide-daventure.com | 2011 | French | France | JAR | travel | |
| 74.116.72.231 | bleachersfootballnews.com | 2011 | English | JAR | sports, football | TODO meaning of "Bleacher"? Possible reference to Bleacher Report. | |
| 74.116.72.232 | indirectfreekick.com | 2011 | English | JAR | sports, football | ||
| 74.116.72.233 | wwiichronicles.net | 2011 | English | CGI | history | ||
| 74.116.72.234 | petroleumagenews.com | 2011 | English | JAR | oil | ||
| 74.116.72.235 | the-open-book-online.com | 2011 | English | JS | literature | ||
| 74.116.72.236 | techtopnews.com | 2011 | English | JAR | tech | ||
| 74.116.72.238 | pohandakhbar.com | 2011 | Arabic | news | Arabic titlel: "خبرونه پوهاند" translates as "News Professor", and the domain name seems to be a transliteration of that. | ||
| 74.116.72.239 | crickettoday.info | 2013 | Pashto | JS | sports, cricket | JS unarchived. The requested URL /cricket.js was not found on this server | |
| 74.116.72.240 | zafernews.com | 2011 | Arabic | JAR | news | ||
| 74.116.72.241 | itechnewstoday.com | 2011 | English | news | "IT Tech News Today". Broken/GoDaddy takeover. | ||
| 74.116.72.242 | gdgtsource.com | 2011 | English | CGI | tech | Presumably "gdgt" stands for "GaDGeT", which is mentioned on subtitle | |
| 74.116.72.243 | waronfilmonline.com | 2011 | English | cinema | |||
| 74.116.72.244 | arborstribune.org | 2011 | news | TODO what is "Arbors"? | |||
| 74.116.72.246 | vuvuzelanews.com | 2011 | English | JAR | sports, football | Vuvuzela is this plastic horn, popular in football stadiums. The term is of African origin. Later legit. rdns source. Previously at 69.74.45.86. | |
| 74.116.72.247 | ballbatstumpsandbails.com | 2011 | English | JAR | sports, cricket | ||
| 74.116.72.248 | kioni-sailing.com | 2011 | sports, sailing | ||||
| 74.116.72.249 | round-trip-travel.com | 2010 | English | CGI | travel | this got archived a lot of times, though all seem to be Alexa crawls. | |
| 74.116.72.250 | arabicnewsource.com | 2011 | Arabic | CGI | news | ||
| 74.254.12.163 | half-court.net | 2010 | English | Philippines | JAR | sports, basketball | |
| 74.254.12.164 | dailywellnessnews.com | 2011 | English | JAR | health | rdns source. split images[ref][ref]. | |
| 74.254.12.165 | dylandon.net | 2011 | Chinese | SWF | music | "Dylan" presumably a reference to Bob Dylan? "Don" unclear. Maybe Don McLean? But it is all a bit weird given that the actual contents of the website don't seem to have anything to do with music, it appears to just be a news aggregator. | |
| 74.254.12.166 | afghanpoetry.net | 2010 | English | Afghanistan | SWF | poetry | Also at 63.131.229.10[ref] in a range. |
| 74.254.12.168 | non-stop-news.net | 2010 | Farsi | JAR | news | ||
| 74.254.12.169 | soldiersofsouthasia.com | 2011 | English | JAR | history | ||
| 74.254.12.170 | greek-news.info | 2011 | English | Greece | news | Welcome to the US Petabox. | |
| 74.254.12.171 | autism-news.org | 2011 | English | SWF | health | copyright 2007. Split images. rss-items. Previously at 69.74.45.67. After these revelations, security researcher Ellie registered the domain and she found that there was a link on Wikipedia to the website from back in 2011 when it was still live. | |
| 74.254.12.173 | thefreshnews.com | 2009 | English | SWF | news | rss, split images | |
| 74.254.12.176 | pakcricketgrd.com | 2011 | Urdu | JAR | sports, cricket | TODO meaning of "grd" | |
| 74.254.12.177 | networkofnews.com | 2011 | English | JAR | news | rdns source. Later legit. | |
| 74.254.12.179 | wineconnaisseur.net | 2010 | English | JS | wine | ||
| 74.254.12.187 | efiinvestment.com | 2011 | English | finance, news | TODO meaning of EFI | ||
| 74.254.12.180 | helpinghandssite.com | 2011 | English | JAR | news | ||
| 74.254.12.188 | first-tee-golf.com | 2011 | English | JAR | sports, golf | ||
| 74.254.12.189 | fabu-foto.com | 2011 | English | CGI | photography | ||
| 74.254.12.190 | viptravelabroad.com | 2011 | English | JS | travel | ||
| 174.133.70.18 | dryterrainnews.com | 2011 | English | Africa | JAR | news | rss |
| 174.133.70.18 | thefootball-life.com | 2011 | English | JS | sports, football | rss, split images | |
| 174.133.70.18 | thenewsofpakistan.com | 2009 | English | Pakistan | JAR | news | a.rss-item, split images |
| 174.133.70.18 | totallynewsnow.com | 2011 | English | JS | news | rss | |
| 199.19.110.7 | classymotors.net | 2011 | English | JS | cars | rss-items | |
| 199.19.110.7 | russiansportsworld.com | 2010 | English | JS | sports | Split headers. Unarchived middle frame, visible at: dawhois.com/www/russiansportsworld.com.html. Russian title: "Русский мир спорта" (Russian world of sport) | |
| 199.19.110.7 | theworldnewsfeeds.com | 2011 | English | JAR | news | rss-items. Split images[ref][ref] | |
| 199.19.110.7 | urbestbod.com | 2011 | Chinese | CGI | sports, fitness | No Wayback Machine archives. Broken Chinese site as usual for their archives. The headline: "你最好的身体.最好的健康和健身信息" translates as "Your Best Body The best health and fitness information", so we understand that the domain name is a super broken "your best body". Visible is a link to "论坛" (forum), so likely CGI | |
| 199.85.212.105 | mide-news.com | 2010 | English | CGI | news | "MIDE" stands for "Middle East". Comms not archived, presumably CGI comms variant. | |
| 199.85.212.111 | newsandsportscentral.com | 2009 | English | JAR | news | rdns source | |
| 199.85.212.118 | just-kidding-news.com | 2011 | English | JAR | news | epic name | |
| 199.187.208.12 | webofcheer.com | 2011 | English | JAR | fansite, comedy | has a an unarchived "members only!" section pointing to webofcheer.com/member.html, CGI comms variant. Copyright 2005! Features Johnny Carson, Charles Chaplin, Rowan Atkins, The Three Stooges and some other Americans no one knows about anymore. There must have been a massive Johnny Carson amongst the CIA contractors at that time given alljohnny.com! The HTML page is weirdly titled pg1c. Interesting, feels like a leak of the site generation system. | |
| 199.187.208.12 | world-news-online.net | 2010 | English | JAR | news | a.rss-item, split images | |
| 204.176.38.130 | i-pressnews.com | 2011 | English | JAR | news | ||
| 204.176.38.132 | turkishnewslinks.com | 2011 | English | Turkey | JAR | news | |
| 204.176.38.133 | globalcitizennews.net | 2010 | English | JAR | news | rss, split images | |
| 204.176.38.134 | photographyarecord.com | 2011 | English | CGI | photography | Cute | |
| 204.176.38.135 | breakingthewicket.com | 2011 | English | CGI | sports, cricket | ||
| 204.176.38.136 | politicalworldtoday.com | 2011 | English | Egypt | JAR | news | |
| 204.176.38.137 | hi-tech-today.com | 2011 | English | JAR | tech | ||
| 204.176.38.139 | bigscreenbattles.com | 2011 | English | JAR | films | ||
| 204.176.38.141 | rakotafootball.com | 2011 | English | JAR | sports, football | "Rakota" is an Indian family name | |
| 204.176.38.143 | noticiassofisticadas.com | 2011 | Spanish | CGI | news | ||
| 204.176.38.142 | senderosdemontana.com | 2011 | Spanish | JS | sports, cycling | Talks about mountain biking and Eurobike 2010, so likely Spain focused, but it is not direct enough to be certain. JS unarchived. | |
| 204.176.38.144 | techno-today.com | 2011 | English | JAR | tech | was legit previously. | |
| 204.176.38.145 | tickettonews.com | 2011 | English | JAR | news | rdns source. Epoch times link. | |
| 204.176.38.146 | dps-digitalphotosharing.com | 2011 | English | JAR | photography | ||
| 204.176.38.147 | theputtingreen.com | 2011 | English | JAR | sports, golf | ||
| 204.176.38.149 | sportsnewstodayar.com | 2011 | Arabic | Lebanon, others | JAR | sports | "ar" on domain name presumably means "Arabic" |
| 204.176.38.159 | kairuafricanews.com | 2011 | English | Africa | JAR | news | what is "Kairu"? en.wikipedia.org/wiki/Kairu a place in India? en.wiktionary.org/wiki/kairu "frog" in Japanese? rdns source |
| 204.176.39.97 | beamingnews.com | 2011 | Arabic | JAR | news | Nice design. rdns source | |
| 204.176.39.98 | cubriendonoticias.com | 2011 | Spanish | JAR | news | archive quite broken. JAR unarchived. cqcounter.com/whois/www/cubriendonoticias.com.html not found. | |
| 204.176.39.100 | rowleyworldpost.com | 2011 | English | Egypt, others | JAR | news | |
| 204.176.39.103 | economicnewsbuzz.com | 2011 | Korean | CGI | finance | Love the kawaii style | |
| 204.176.39.104 | spectranewsonline.com | 2011 | English | CGI | news | marked copyright 2010. | |
| 204.176.39.105 | entertainmentnewscompany.com | 2011 | Chinese | SWF | films, music | Title: "娱乐新闻公司", lit. Entertainment News Company | |
| 204.176.39.110 | arabnewsatdawn.com | 2011 | Arabic | CGI | news | cute, the Arab chick's ice cream actually has a cocktail umbrella on it. Marked copyright 2010. Here she is: www.shutterstock.com/image-photo/young-veiled-woman-reading-newspaper-eating-4836766 by Anneka. Pinged her privately on www.facebook.com/Anyka.Fotografie. | |
| 204.176.39.115 | globalprovincesnews.com | 2010 | Arabic | JS | news | The largest HTML by far so far at 328 KiB | |
| 204.176.39.116 | mahparah-news.com | 2011 | Farsi | JS | news | ||
| 204.176.39.119 | commercialspacedesign.com | 2013 | Farsi | CGI | architecture | C O N C E P T U A L design. A rare example of a fake company website. | |
| 207.150.191.68 | kickofffootballnews.com | 2010 | English | CGI | sports, football | rss-item. archive quite broken, comms not found. "login" link web.archive.org/web/20100512232600/http://kickofffootballnews.com/login.html to unarchived, so CGI comms likely. cqcounter.com/whois/www/kickofffootballnews.com.html in-style. | |
| 207.150.191.68 | mywebofnews.com | 2011 | Arabic | JAR | news | Split images[ref][ref]. rss-items. | |
| 207.150.191.68 | technologypresstoday.com | 2011 | Farsi | JAR | news | split images, RSS | |
| 207.150.191.68 | worldofonlinenews.com | 2011 | English | JAR | news | split images[ref][ref]. Later legit. | |
| 207.210.250.131 | starrynightnews.com | 2011 | Arabic | JS | news | interesting design | |
| 207.210.250.132 | aeronet-news.com | 2011 | English | JAR | airplanes | ||
| 207.210.250.133 | bakaribulletin.com | 2011 | English | Africa | JS | news | Bakari could either be a given name, or a village in Togo |
| 207.210.250.134 | deprensaenlarevisiondehoy.com | 2011 | Spanish | JAR | news | ||
| 207.210.250.135 | icwb-news.com | 2011 | English | JAR | news | ICWB stands for "Inner Circle Worldwide Business (News)", the title of the website | |
| 207.210.250.136 | sportsreelhighlights.com | 2011 | English | JAR | sports | ||
| 207.210.250.138 | inquiry-human-past.com | 2011 | English | JAR | history | ||
| 207.210.250.139 | thefairwaysaregreen.com | 2011 | Thai | JAR | sports, golf | ||
| 207.210.250.142 | russiaupdate.com | 2011 | Russian | news | Older unrelated archive: web.archive.org/web/20010429003443/http://russiaupdate.com/. Visible but possibly cut title "Россия Обновление" (Russia Update) | ||
| 207.210.250.143 | archaeologyreview.net | 2010 | English | JAR | history, archeology | ||
| 207.210.250.146 | noticias-caracas.com | 2011 | Spanish | Venezuela | CGI | news | Caracas is the capital of Venezuela. But you knew that, right? |
| 207.210.250.147 | bailandstump.com | 2011 | English | JS | sports, cricket | "Bail" and "Stump" are the two parts of the thing your're supposed to hit with the ball in cricket.[ref] | |
| 207.210.250.148 | classicalmusic4arab.com | 2011 | music | The first words in the title are "كلاسيكيات الموسيقى العربية" (Arabic music classics) | |||
| 207.210.250.149 | globalventurestat.com | 2008 | English | SWF | news | ||
| 207.210.250.152 | al-rashidrealestate.com | 2010 | Arabic | Egypt | CGI | finance, real-estate | |
| 207.210.250.153 | newsintheworld-ru.com | 2011 | Russian | JAR | news | ||
| 207.210.250.154 | news-unlimited.info | 2011 | English | news | "members" link visible so likely GI comms. | ||
| 208.93.112.105 | fastnews-online.com | 2009 | English | JAR | news | a.newslink | |
| 208.93.112.106 | travelxtreme.net | 2008 | English | JAR | travel | split images | |
| 208.93.112.108 | nbanewsroundup.com | 2013 | English | CGI | sports, basketball | quite broken with only HTML archived in 2013, but we're counting it due to coms link and IP range. cqcounter.com/whois/www/nbanewsroundup.com.html shows it well. | |
| 208.93.112.110 | luxuryfive.net | 2011 | English | travel | Title: "Luxury five" | ||
| 208.93.112.111 | topfootballnewsonline.com | 2011 | English | sports, footbal | "Top Football News Online". | ||
| 208.93.112.112 | todaysportscores.com | 2011 | English | sports | |||
| 208.93.112.114 | dynamicworldnews.com | 2011 | English | news | |||
| 208.93.112.116 | gazingvoyage.com | 2011 | English | travel | |||
| 208.93.112.123 | garundipost.com | 2011 | English | news | TODO meaning of "Garundi" | ||
| 208.254.38.39 | todaysengineering.com | 2011 | English | CGI | engineering | ||
| 208.254.38.56 | nejadnews.com | 2011 | Arabic | JAR | news | rss, JAR unarchived | |
| 208.254.40.96 | sixty2media.com | 2011 | English | Various | JAR | news | Epoch times link |
| 208.254.40.99 | newspoliticssource.com | 2013 | Arabic | JAR | news | One of the news mentions Snowden | |
| 208.254.40.110 | musical-fortune.net | 2010 | English | CGI | music | images /images/banner-02.jpg | |
| 208.254.40.113 | ashoka-gemstones.com | 2010 | English | JAR | jewelry | ||
| 208.254.40.117 | worldnewsandent.com | 2010 | Arabic | Egypt | CGI | mews | |
| 208.254.40.124 | riskandrewardnews.com | 2013 | English | CGI | finance | ||
| 208.254.42.194 | it-proonline.com | 2011 | English | CGI | tech | images /images/header_01.jpg | |
| 208.254.42.205 | driversinternationalgolf.com | 2011 | English | CGI | sports, golf | ||
| 208.254.42.209 | mardelsurnoticias.com | 2011 | Spanish | JAR | news | weird mixture of Portuguese and Spanish language external links | |
| 208.254.42.215 | nowfreshfinances.com | 2011 | English | CGI | finance | CGI unarchived | |
| 208.254.42.216 | circulatingnews.net | 2010 | English | JAR | travel | ||
| 208.254.42.219 | westingtonpassnews.com | 2011 | English | JAR | news | ||
| 209.162.192.44 | thejewelofsouthamerica.com | 2010 | Spanish | CGI | nature, birds | rss-item, split images. CGI unarchived but likely under the "Foro" (Forum) link. Talks about the Amazon river and rainforest which it refers to in the Spanish title of the English domain: "La Joya de Sudamerica" (The Jewl of South America). | |
| 209.162.192.49 | rastadirect.net | 2010 | English | JAR | fansite | ||
| 209.162.192.51 | yellow-chair-report.com | 2011 | English | CGI | news | rss-item, split images. CGI unarchived likely under "Members" link. | |
| 209.162.192.57 | globalnewsreports.net | 2010 | English | CGI | news | rss-item. Copyright 2008. CGI unarchived. Comms unarchived likely CGI under "Forum" link | |
| 209.162.192.59 | easytravelsite.net | 2009 | English | CGI | news | Split headers. CGI unarchived, likely under "Login" link. | |
| 209.51.136.178 | cellar-notes.com | 2011 | English | JAR | wine | rss, split images, JAR unarchived | |
| 209.51.136.178 | the-news-scene.com | 2011 | English | JAR | news | split images, RSS | |
| 210.80.75.36 | e-commodities.net | 2011 | English | JAR | finance | ||
| 210.80.75.37 | trekkingtoday.com | 2011 | English | JAR | sports, running | split images[ref][ref]. rdns source. | |
| 210.80.75.41 | multinews-33.com | JAR | news | No archives of the HTML, but the JAR was archived | |||
| 210.80.75.43 | gulfandmiddleeastnews.com | 2011 | Arabic | JS | news | ||
| 210.80.75.44 | whirlybirdinflight.com | 2011 | English | JAR | helicopters | ||
| 210.80.75.45 | kings-game.net | 2011 | English | JAR | gaming, chess | JAR unarchived | |
| 210.80.75.46 | topglobalnewsdaily.com | 2011 | English | JS | news | ||
| 210.80.75.49 | recipe-dujour.com | 2011 | English | JAR | cooking | nice design | |
| 210.80.75.53 | sportsman-elite.com | 2011 | English | sports | |||
| 210.80.75.55 | philippinenewsonline.net | 2010 | Philippines | JAR | news | ||
| 210.80.75.56 | technewsforme.com | 2011 | Farsi | JAR | tech | ||
| 210.80.75.59 | goldeportesnoticias.com | 2011 | Spanish | sports, football | |||
| 212.4.16.224 | lanoticiasdehoyelinforme.com | 2010 | Spanish | JAR | news | ||
| 212.4.16.232 | mynewscheck.com | 2011 | English | Canada | JAR | news | rdns source |
| 212.4.16.245 | financial-crisis-news.com | 2011 | Russian | Russia | JAR | news | rdns source |
| 212.4.16.252 | minutosdenoticias.com | 2010 | Spanish | CGI | news | CSS | |
| 212.4.17.38 | fightwithoutrules.com | 2011 | Russian | JAR | sports, combat sports | The photo on top middle can be seen e.g. at spfightingtalk.wordpress.com/2013/01/18/breaking-down-mixed-martial-arts-what-is-mma/. The fither on top is Mac Danzig, TODO find bottom one lazy now. | |
| 212.4.17.41 | newtechfrontier.com | 2010 | English | CGI | tech | since became legit: newtechfrontier.com/ | |
| 212.4.17.43 | smart-travel-consultant.com | 2011 | Chinese | CGI | travel | ajaxtax.js may be of interest for fingerprinting. Title: "智能旅行顾问", lit. Smart Travel Consultant | |
| 212.4.17.46 | atentlaloc.com | 2009 | English | Quatar, Lebanon, Israel, Iran | JS | jewelry | Tlaloc is an Aztec deity, and Aten is an Egyptian deity. Both appear to be somewhat linked to gold, thus their usage in a jewelry website. Creative domain name. |
| 212.4.17.53 | newsresolution.net | 2010 | English | Côte d'Ivoire, Lebanon, Sudan | JAR | news, UN Peacekeeping | |
| 212.4.17.56 | lesummumdelafinance.com | 2010 | French | France | JAR | finance | |
| 212.4.17.98 | topbillingsite.com | 2011 | English | CGI | films | ||
| 212.4.17.122 | b2bworldglobal.com | 2011 | English | CGI | news | ||
| 212.4.17.125 | worldaroundyunnan.com | 2011 | Chinese | JAR | news | rss, split images, JAR | |
| 212.4.17.160 | localtoglobalnews.com | 2010 | English | JAR | news | rss, split images | |
| 212.4.18.14 | football-enthusiast.com | 2011 | English | Europe | JS | sports, football | |
| 212.4.18.129 | sightseeingnews.com | 2010 | English | JAR | travel | ||
| 212.209.74.105 | globalbaseballnews.com | 2011 | English | JS | sports, baseball | ||
| 212.209.74.106 | football-de-luxe.com | 2010 | French | France | JAR | sports, football | |
| 212.209.74.112 | developmental-league.com | 2010 | English | CGI | sports, American football | CGI comms variant? | |
| 212.209.74.115 | mediocampodefutbol.com | 2010 | Spanish | JAR | sports, football | ||
| 212.209.74.117 | myengineeringaffinity.com | 2011 | English | JAR | tech | ||
| 212.209.74.122 | atthemovies.biz | 2011 | English | JAR | cinema | Archive very broken with no text and rather only images in a table. But it has a link to unarchived JAR. The only .biz domain found so far as of writing. There are also some broken redirect archives from 2003. | |
| 212.209.74.123 | worldfinancialexchangenews.com | 2010 | English | SWF | finance | SWF unarchived. | |
| 212.209.74.124 | urouttahere.com | 2011 | English | Travel | The title means "you're out of here", a reference to this being a travel website. A closely stock image of the same child models is visible at: www.hammockbeach.com/play/kids-crew-resort-program/ | ||
| 212.209.74.125 | avoilurefixe.com | 2011 | French | Tunisia | JAR | airplanes | "à voilure fixe" is French for "with fixed wing", i.e. fixed wing aircraft |
| 212.209.74.126 | headlines2day.com | 2011 | Farsi | JAR | news | marked copyright 2009 | |
| 212.209.79.34 | fgnl.net | 2011 | English | Iran | CGI | news | four letter domain! FGNL stands for "Farsi Global News Links" Marked copyright 2009. |
| 212.209.79.37 | fitness-sources.com | 2010 | English | JS | sports, fitness | ||
| 212.209.79.40 | hydradraco.com | 2011 | English | JAR | sports, American football | TODO meaning of the name? | |
| 212.209.79.41 | noticiasdelmundolatino.com | 2011 | Spanish | JAR | news | ||
| 212.209.79.42 | suparakuvi.com | 2011 | French | France | JAR | news | a Tour Eiffel image, and young people stuff, i.e. first world stuff. It's for France alright. But TODO meaning of domain name? Ciro's second language French didn't cut it this time. |
| 212.209.79.46 | cetusdelph.com | 2011 | English | JS | sports, scuba | ||
| 212.209.79.47 | willtoworship.com | 2011 | English | JAR | religion, Christianity | marked copyright 2007 | |
| 212.209.79.48 | themvconnection.com | 2011 | English | JAR | music | ||
| 212.209.79.51 | pi-resources.net | 2010 | English | JS | private investigators | "pi" stands for Private Investigators. The CIA must have had some fun making this one. | |
| 212.209.79.53 | ourscubaworld.com | 2011 | English | JS | sports, scuba | ||
| 212.209.79.58 | tech-love-home.com | 2011 | Chinese | JS | tech | Title: "消费类电子产品", lit. Consummer Electronics | |
| 212.209.79.60 | first-solo-aviation.com | 2010 | English | JAR | airplanes | ||
| 212.209.79.61 | china-destinations.org | 2011 | Chinese | JS | travel | title: "中国目的地指南", lit. "China Destination Guide" | |
| 212.209.90.69 | worldedgenews.com | 2011 | English | JAR | news | ||
| 212.209.90.72 | talkingpointnews.info | 2011 | English | news | |||
| 212.209.90.74 | globalinvestmentnews.net | 2010 | English | JAR | news | rss, split images | |
| 212.209.90.75 | prebitinvestment.com | 2011 | English | finance | Title: "Pre-BIT Investment". TODO meaning of "BIT". | ||
| 212.209.90.80 | nsmovies.net | 2010 | English | JAR | films | "ns" stands for "Nirguna Saguna", two separate Hindu names/deities. But there are no other Indian references beyond those. | |
| 212.209.90.82 | middleeastjournal.net | 2010 | Arabic | JS | news | ||
| 212.209.90.84 | thenewseditor.com | 2011 | English | JAR | news | ||
| 212.209.90.87 | newsandweathersource.com | 2009 | English | JAR | news | marked copyright 2009. | |
| 212.209.90.89 | pakisports.com | 2010 | English | Pakistan | SWF | sports | |
| 212.209.90.90 | vriha-aesthetics.com | 2011 | Arabic | JS | news | ||
| 212.209.90.92 | amishkanews.com | 2011 | English | India | JS | news | Amishka is an Indian name, plus some prominent mentions of Bollywood both point to India specifically |
| 212.209.90.93 | theentertainbiz.com | 2011 | English | JAR | entertainment | ||
| 212.209.90.94 | eurosportssummary.com | 2011 | English | JAR | sports | ||
| 216.93.248.194 | esmundonoticias.com | 2011 | Spanish | JAR | news | rss-items. Shares IP with kukrinews.com. | |
| 216.93.248.194 | kukrinews.com | 2010 | English | JS | News | JavaScript with SHAs. Talks to /cgi-bin/news.cgi. A Kukri is the national weapon of Nepal. Slogan: "Nepal's Sharp Edge", thus matching the website name. Split image header. Copyright 2009. Shares IP with esmundonoticias.com. | |
| 216.93.248.194 | lasthournews.com | 2010 | Urdu | jAR | news | split images | |
| 216.93.248.194 | tech-geek-news.com | 2010 | Arabic | JS | news | Split images, rss-item. Comms unarchived. Wayback machine archive very broken but cqcounter.com/whois/www/tech-geek-news.com.html perfectly in style. | |
| 216.104.38.114 | all-sport-headlines.com | 2011 | Arabic | JAR | news | split images[ref][ref]Arabic-looking alphabet, image only so can't Google translate easily. | |
| 216.104.38.114 | wahidfutbol.com | 2011 | Arabic | JS | football | Wayback Machine very broken. cqcounter.com/whois/www/wahidfutbol.com.html somewhat in-style, but not very typical. | |
| 216.104.38.114 | wildbirds-seasia.com | 2011 | English | JAR | nature, birds | Slit headers, rss-item. "Birds of Southeast Asia". Stock image match example at: fr.pinterest.com/pin/745627282030750518/, possibly a greater bird-of-paradise. | |
| 216.105.98.132 | europeantravelcafe.com | 2010 | English | travel | rss-items, split images. Marked copyright 2009. Comms not found. There's a currency converter at: web.archive.org/web/20100724024644/http://www.europeantravelcafe.com/tools.html which could be suspicious. The "plan your trip" link links to a different website: secure-cert.net/~etc/transport.html which is unusual. A similar thing happens in intloil.org. That link was removed from the next archive: web.archive.org/web/20110201192245/http://europeantravelcafe.com/ which is quite funny, looks like a bug and is possibly a link used by the CIA operators to manage the website? "secure-cert.net" is obscure, the only other surviving online mention of it is www.leewillis.co.uk/wordpress-plugins/#comment-6513 | ||
| 216.105.98.134 | fuenteneta.com | 2011 | Spanish | news | Google says: | ||
| 216.105.98.135 | ilat-news.com | 2011 | English | news | The domain stands for : "International Law Enforcement & Anti Terrorism", also on page "Law Enforcement and Anti Terrorism news". | ||
| 216.105.98.136 | etherealinspirations.net | 2011 | English | religion | Title: "Ethereal Inspirations" | ||
| 216.105.98.137 | the-news-zone.com | 2011 | English | JAR | news | There is a broken archive: web.archive.org/web/20130814194744/http://the-news-zone.com/ which contains just the middle frame. But by chance the broken JAR link was there further confirming the hit! | |
| 216.105.98.139 | cultura-digital.net | 2008 | Spanish | CGI | news | Marked copyright 2008. Previously legit. | |
| 216.105.98.140 | uaeshoppingspree.com | 2013 | English | UAE | JAR | shopping | Archive quite broken, but has link to unarchived JAR. Has an unusually personal touch "As you can probably tell from the title of my website, shopping is my very favorite pastime." cqcounter.com/whois/www/uaeshoppingspree.com.html shows it well. |
| 216.105.98.144 | garanziadellasicurezza.com | 2011 | Italian | JAR | commercial | The archive is quite broken with toplevel archiving a frame rather than the actual website. JAR unarchived. web.archive.org/web/20110822020341/http://www.garanziadellasicurezza.com:80/news.html has rss-item. I'm counting this one it's too much. | |
| 216.105.98.145 | montanismoaventura.com | 2012 | Spanish | Spain | JS | sports, mountaineering | JS unarchived. Marked copyright 2010. More visible archive at: cqcounter.com/whois/www/montanismoaventura.com.html |
| 216.105.98.146 | large-format-news.com | 2011 | English | photography | |||
| 216.105.98.147 | nepalnewsbrief.com | 2008 | English | Nepal | JAR | news | Marked copyright 2006 (!) Registered 2007-01-18. |
| 216.105.98.148 | teclafinance.com | 2011 | Chinese | finance | CQ Counter screenshot rather broken but in a similar way as another Chinese website: cqcounter.com/whois/site/activegaminginfo.com.html so it seems that simply their screenshot mechanism of the time didn't have proper Chinese encoding support. The title is "特科拉财经" which Google Translate translates to "Tekola Finance", the first word apparently being the phonetic transliteration of a foreign name, but it is unclear what it references exactlyh. | ||
| 216.105.98.149 | entreman.com | 2011 | Englsh | CGI | business | Comms unarchived. Marked Copyright 2011. Archive a bit broken, original styling more clearly visible at: cqcounter.com/whois/www/entreman.com.html. Tis is the only website found so far that stores its custom fonts on the site e.g. /M-1c-fontfacekit/mplus-1c-black-webfont.svg. Stock of office workers at: www.shutterstock.com/image-photo/presentation-business-people-working-office-2-4767229 by Marcin Balcerzak. Light bulb stock at: www.bigstockphoto.com/image-4406416/stock-photo-money-light by PhilipO. | |
| 216.105.98.152 | modernarabicnews.com | 2013 | Arabic | JAR | news | HTML archive quite broken, but JAR was archived thankfully. cqcounter.com/whois/www/modernarabicnews.com.html shows it well. Original title: "أخبار عربية حديثة قياسي" | |
| 216.105.98.153 | global-headlines.com | 2011 | English | news | Was a legitimate WordPress website for a while in 2020. | ||
| 216.105.98.154 | everythingcricket.org | 2011 | English | JAR | sports, cricket | Also has archives from 2009, but they were a bit broken. The 2011 one is marked copyright 2011, so they actually bothered to updated that. | |
| 216.105.98.156 | familyhealthonline.net | 2011 | English | CGI | health | ||
| 216.105.98.157 | delacorne.com | 2011 | French | news | The title is french "Corne de l'Afrique Nouvelles" and "de la Corne", the French name for the Horn of Africa. So French but not France. | ||
| 216.105.98.158 | econfutures.com | 2011 | English | finance | Africa focus. Stock image source: www.istockphoto.com/photo/asian-helpdesk-support-operator-gm147050715-12052374 by imabase | ||
| 219.90.61.110 | surya-brahma.com | 2011 | Spanish | JAR | news | Surya and Brahman are Hindu concepts, but the website appears to have nothing to do with India or Hinduism. Interesting. | |
| 219.90.61.111 | classicalmusicboxonline.com | 2010 | English | CGI | music | ||
| 219.90.61.116 | athletepro.net | 2010 | English | JAR | sports | ||
| 219.90.61.117 | lajornadanow.com | 2010 | Spanish | JAR | news | ||
| 219.90.61.119 | aviation-navigation.com | 2011 | English | aviation | |||
| 219.90.61.120 | theinternationalworld.com | 2011 | English | JAR | news | rdns source. rss-items. | |
| 219.90.61.121 | thepyramidnews.com | 2011 | Farsi | Iran | JAR | news | |
| 219.90.61.122 | iran-newslink-today.com | 2011 | Farsi | Iran | JAR | news | |
| 219.90.61.123 | journeystravelled.com | 2011 | English | JAR | travel | ||
| 219.90.62.229 | information-junky.com | 2011 | English | Ghana | JAR | news | |
| 219.90.62.231 | todosperuahora.com | 2011 | Spanish | Peru | CGI | news | |
| 219.90.62.233 | theworld-news.net | 2010 | Urdu | CGI | news | ||
| 219.90.62.234 | recuerdosdeviajeonline.com | 2011 | Spanish | SWF | travel | marked "Copyright 2009" | |
| 219.90.62.235 | ordenpolicial.com | 2011 | Spanish | Spain | news, security | ||
| 219.90.62.237 | elcorreodenoticias.com | 2011 | Spanish | Venezuela | JAR | news | |
| 219.90.62.238 | freshtechonline.com | 2011 | English | CGI | tech | ||
| 219.90.62.240 | cityworldnewsnow.com | 2011 | English | news | Has subdomain secure.cityworldnewsnow.com so likely CGI comms. in-style, arab world mentions. | ||
| 219.90.62.241 | newscentertoday.com | 2011 | English | JAR | news | Copyright 2008. rdns source. rss-items. Later legit. In 2016: The domain name you have entered is not available. It has been taken down because the email address of the domain holder (Registrant) has not been verified.. | |
| 219.90.62.242 | ride-captain.com | 2011 | English | JAR | sports, motorcyles | ||
| 219.90.62.243 | fitness-dawg.com | 2021 | English | JAR | sports, fitness | Original Reuters article sample. Pushup dude stock: www.istockphoto.com/photo/sweating-young-man-doing-push-ups-gm115455429-645125 by Mike R. Manzano, pinged at: x.com/cirosantilli/status/1899750172260806711. Dude was an ex-Sr. Software engineer at Coinbase from 2019-2022, he likely retired with the Bitcoin boom already legend. Still making apps as of 2024 though: www.facebook.com/leftspin. Dog at: www.istockphoto.com/photo/english-bulldog-gm92095947-2629950 by GlobalP. | |
| 219.90.62.244 | easytraveleurope.com | 2012 | English | JAR | travel | nice design | |
| 219.90.62.245 | world-news-now.net | 2011 | English | JAR | news | ||
| 219.90.62.246 | negativeaperture.com | 2011 | English | CGI | photography | nice domain name | |
| 219.90.62.247 | conquermstoday.com | 2011 | English | CGI | health | MS means multiple sclerosis. Comms not found, CGI from unarchived subpage assumed. Has a subdomain "heal.conquermstoday.com" according to 2013 DNS Census, but no links to it in the archive. |
![[ref]](https://web.archive.org/web/20110128180410/http://24hoursprimenews.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110128180311/http://24hoursprimenews.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110129052434/http://www.cyhiraeth-intlnews.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110129052457/http://www.cyhiraeth-intlnews.com/images/index_03.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201192154/http://europeannewsflash.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201192122/http://europeannewsflash.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110202122343/http://farsi-newsandweather.com/images/banner_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110202122347/http://farsi-newsandweather.com/images/banner_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201100034/http://global-view-news.com/images/banner_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201100045/http://global-view-news.com/images/banner_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20101229090818/http://globaltourist.net/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20101229090840/http://globaltourist.net/images/index_04.jpg){kind=link}
![[ref]](https://web.archive.org/web/20101230175417/http://www.hassannews.net/images/aa_05.jpg){kind=link}
![[ref]](https://web.archive.org/web/20101230175337/http://www.hassannews.net/images/aa_09.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201220125/http://techwatchtoday.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201220207/http://techwatchtoday.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110228050927/http://todayoutdoors.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110228050935/http://todayoutdoors.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110207193442/http://echessnews.com/images/title_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110207193535/http://echessnews.com/images/title_02.jpg){kind=link}
{kind=link}
![[ref]](https://web.archive.org/web/20110201114616/http://dailywellnessnews.com/images/bann-1.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110201114656/http://dailywellnessnews.com/images/bann-2.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110209183352im_/http://theworldnewsfeeds.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110209183352im_/http://theworldnewsfeeds.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110210130611/http://mywebofnews.com/images/web_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110210130506/http://mywebofnews.com/images/web_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110210051523/http://worldofonlinenews.com/images/index_01.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110210051531/http://worldofonlinenews.com/images/index_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110208080555/http://trekkingtoday.com/images/banner_02.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110208080715/http://trekkingtoday.com/images/banner_03.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110207144942/http://all-sport-headlines.com/images/banner1.jpg){kind=link}
![[ref]](https://web.archive.org/web/20110207144620/http://all-sport-headlines.com/images/banner2.jpg){kind=link}
{kind=link}
This section is about possible "real-world" information leaks found in the HTML of the pages. Domain DNS metadata may of course expose more, and is more likely to do so, this section is only about in-page findings, notably in the HTML.
The HTML rather than a more natural title like "Web of cheer" as is the case for the other website. This feels like a forgotten placeholder for an internal page identifier, e.g. "page 1C" sounds plausible. At Section "HTML title element" we riefly inspected the
<title> of webofcheer.com is cryptically set as:pg1c<title> of every other hit with a wayback machine archive, and unfortunately none other seemed to have any such interesting title.The 2010 archive of europeantravelcafe.com has a "plan your trip" link links to a different domain: secure-cert.net/~etc/transport.html. This appears to have been a link to the system used by CIA operators to manage the website. Furthermore, the link then was later removed from the 2011 version, so it was almost certainly a leak! "secure-cert.net" is obscure, the only other surviving online mention of it is www.leewillis.co.uk/wordpress-plugins/#comment-6513 to
secure-cert.net/~sayitint/products-page/bags-totes/duffel-bag/ We've grepped all the HTML downloaded as HTML analysis but no other links to it were found.
secure-cert.net/~sayitint/products-page/bags-totes/duffel-bag/ We've grepped all the HTML downloaded as HTML analysis but no other links to it were found.
A similar thing happened to alljohnny.com Starting December 2004 the "Submit your favorite carlson quote" was mind blowingly switched to point to https://washington.serversecured.net/~alljohnn/cgi-bin/memlog.cgi thus likely leaking the control site URL. Beauty. It previously pointed to the more sensible: web.archive.org/web/20040901162621/https://secure.alljohnny.com/cgi-bin/memlog.cgi
This section tries to explain how the discoveries were made in more detail.
Some of the subsections are quite readable, while others are mostly data dumps and work logs, so bear with us.
But by looking at the URLs of the screenshots they provided from other websites we can easily uncover all others that had screenshots, except for the Johnny Carson one, which is just generically named. E.g. the image for the Chinese one is www.reuters.com/investigates/special-report/assets/usa-spies-iran/screencap-activegaminginfo.com.jpg?v=192516290922 which leads us to domain activegaminginfo.com.
{kind=link}
Oleg Shakirov later discovered that the Carson one had its domain written right on the screenshot, as part of a watermark present on the original website itself. Therefore the URLs of all the websites were in one way or another essentially given on the article.
The full list of domains from screenshots is:
- 2011 archive: web.archive.org/web/20110208113503/http://activegaminginfo.com/. Contains mentions of 2010.
- As of 2023, it seemed to be an actual legit photography website by German (amateur?) photographer Klaus Wägele. Archive: web.archive.org/web/20230323102504/https://www.capture-nature.com/Ciro Santilli actually sent him a message to let him know about the CIA thing in case he didn't, and he replied that he wasn't aware of it.
- 2011 archive: web.archive.org/web/20110201164741/https://www.headlines2day.com/. Dated "Copyright 2009".
fitness-dawg.com: English fitness website.2021 archive: web.archive.org/web/20110207104044/http://fitness-dawg.com/.rastadirect.net: English Rastafari culture website.- 2011 archive: web.archive.org/web/20110203021315/http://fightwithoutrules.com/. Contains mentions of 2009 news.
- 2004 archive: web.archive.org/web/20040113025122/http://alljohnny.com/.
From The Reuters websites and others we've found, we can establish see some clear stylistic trends across the websites which would allow us to find other likely candidates upon inspection:The most notable dissonance from the rest of the web is that there are no commercial looking website of companies, presumably because it was felt that it would be possible to verify the existence of such companies.
- natural sounding, sometimes long-ish, domain names generally with 2 or 3 full words. Most in English language, but a few in Spanish, and very few in other languages like French.
- shallow websites with a few tabs, many external links, sometimes many images, and few internal pages
- common themes include:
- .com and .net top-level domains, plus a few other very rare non .com .net TLDs, notably .info and .org
- each one has one "communication mechanism file": communication mechanisms
- narrow page width like in the days of old, lots of images
- split header images
- some common pattern they follow in their news lists:
ul.rss-items > li.rss-item, e.g.: web.archive.org/web/20110202092126/http://beamingnews.com/- links with class
a.newslinkanda.newslinkalte.g. web.archive.org/web/20110128181622/http://profile-news.com/
Most domains are the only domain for its IP, i.e. the websites are mostly private hosted. However we have later found many exceptions to this general indicator, so it should not be used as a strong exclusion rule.
It would be fun to actually reverse search into one of their stock image provider's original images. Ones we've found:
Maybe it is some kind of outdated web design thing, which they took much further in time than the average website, like the JAR.
Their websites do appear to follow common style guidelines form earlier eras, around the early 2000s notably, some legit sites that look a lot like hits:
An example:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Looking at the source code of: web.archive.org/web/20130828122833/http://euronewsonline.net/euro_bus.php we noticed an interesting comment:which presumably refers to Adobe ImageReady:A sample tutorial: people.goshen.edu/~paulmr/physix/326/imageready/slicendice.php
<!-- ImageReady Slices (enewsweather.psd) -->Adobe ImageReady was a bitmap graphics editor that was shipped with Adobe Photoshop for six years. It was available for Windows, Classic Mac OS and Mac OS X from 1998 to 2007. ImageReady was designed for web development and closely interacted with Photoshop
Some of the websites use CSS background images to populate the images, e.g. ingenuitytrendz.com has HTML:and then the CSS engineering.css does:
ingenuitytrendz.com/20110201170354/index.html: <li><a id="banner1"> </a></li>
ingenuitytrendz.com/20110201170354/index.html: <li><a id="banner2"> </a></li>
ingenuitytrendz.com/20110201170354/index.html: <li><a id="banner3"> </a></li>#banner1 { background: url(/web/20110201170405im_/http://ingenuitytrendz.com/images/banner_01.jpg) no-repeat center; }
#banner2 { background: url(/web/20110201170405im_/http://ingenuitytrendz.com/images/banner_02.jpg) no-repeat center; }
#banner3 { background: url(/web/20110201170405im_/http://ingenuitytrendz.com/images/banner_03.jpg) no-repeat center; }The HTML from the index page of Wayback Machine were:
- dumped at: github.com/cirosantilli/media/tree/master/cia-2010-covert-communication-websites/html
- downloaded with: github.com/cirosantilli/media/tree/master/cia-2010-covert-communication-websites/download-html.sh. Note that there were many supurious errors notably:we just ran it multiple times until all errors were gone.
OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to web.archive.org:443
The best way to analyse the HTML is to grap our dumps from: github.com/cirosantilli/cia-2010-websites-dump.
Some possibly interesting searches include:
Some of the HTML files contain conditional comments e.g. web.archive.org/web/20091023041107/http://aquaswimming.com/ contains:
<!--[if IE 6]> <link href="swimstyleie6.css" rel="stylesheet" type="text/css"> <![endif]-->Varios of the non-English websites seem to have comments translating the content e.g.:This feels like it could be the translation helping the technical webdev team know what is what.
./noticiasmusica.net/20101230165001/index.html:<h2>Alguns dos Melhores Sites Nacionais</h2><!--some of the best national sites (in music)-->Many of the RSS frame pages use:which is a weird HTML tag that would lead all links to open on new tabs, e.g. web.archive.org/web/20110202124411/http://thecricketfan.com/home.html.
<base target="_blank" />Various websites have pages with .php extension. It feels likely that all websites were written in PHP.
Some sites use a
feeds.php for the feeds, e.g. http://www.absolutebearing.net//absolutebearing_feeds/feeds.php?src=http%3A%2F%2Ffeeds2.feedburner.com%2FOceanyachtsinfo&desc=1Some URLs existed both in HTML and .php extension, or were converted at some point:
allworldstatistics.com/20110207151941/comprehensivesources.html
allworldstatistics.com/20130818155225/comprehensivesources.phpA few of the PHP urls have weird IDs in them like we wonder what they mean.
omktf, juqwt and qlaqft:./middle-east-newstoday.com/20100829004127/omktf/uirl.php?ok=461128
./newsandsportscentral.com/20100327130237/juqwt/eubcek.php?pe=747155
./pondernews.net/20100826031745/lldwg/qlaqft.php?fc=281298A few separate websites have an archive with the same It is unclear what it means. All of them contain something like:so looks like an archival artifact only.
pid parameter:fightwithoutrules.com/20131220205811/?pid=2POQ7BC1G/index.html
half-court.net/20131223165013/?pid=2POQ7BC1G/index.html
health-men-today.com/20131223002237/?pid=2POQ7BC1G/index.html
intlnewsdaily.com/20131221121441/?pid=2POQ7BC1G/index.html
intoworldnews.com/20131217193621/?pid=2POQ7BC1G/index.html<html>
<head>
<meta name="robots" content="noarchive" />
<meta name="googlebot" content="nosnippet" />
</head>
<body>
<div align=center>
<h3>Error. Page cannot be displayed. Please contact your service provider for more details. (11)</h3>
</div>
</body>
</html>The following two websites have a
feeds.php system for their RSS:./mydailynewsreport.com/20110211111053/myrss/feeds.php?src=http:/www.refahemelli.com/pashto/news/rss.php&chan=y&desc=1&targ=y&utf=y
./magneticfieldnews.com/20110208063545/magneticfeeds/feeds.php?src=http:/www.bbc.co.uk/pashto/index.xml&chan=y&desc=1&targ=y&utf=ySome of the HTML uses attributes without quotes, which is legal, but very unusual nowadays:
soldiersofsouthasia.com/20110207203705/home.htm: <a href=http://www.rss-to-javascript.comWe can try to search for any link leaks by listing all domains linked to with:The first thing that shows up is that there are some IPs linked to directly! But they seem to be the direct IPs of legitimate websites, we are not sure why IPs were used rather than domain names:
git grep --no-color -I -h --no-line -o 'https?://[^/">?]+[/">?]' | sed -r 's/.$//' | sort | uniq -c | sort -nk1- 69.167.160.171 at web.archive.org/web/20110208053653/http://sa-michigan.com/ to web.archive.org/web/20100304122019/http://69.167.160.171/ marked with image "fantasyplayers.com", a legit website called Fantasy Players Network
- 69.94.11.53 at web.archive.org/web/20101229193800/http://newsresolution.net/ titled "International Tribunal for Rwanda" to web.archive.org/web/20101229193800/http://69.94.11.53/default.htm
- 74.125.77.132 mynepalnews.com Webalizer
- 194.165.154.66/index.php web.archive.org/web/20110129161937/http://icwb-news.com/ MiddleEast links to 194.165.154.66/index.php but that is an actual page: web.archive.org/web/20110529142501/http://194.165.154.66/index.php
- 200.55.6.87 at web.archive.org/web/20110128170204/http://noticiasdelmundolatino.com/ after clicking "Maps" tab entitled "Mapas en la red" to web.archive.org/web/20100329150648/http://200.55.6.87/es/index.htm
- 213.97.154.118 at web.archive.org/web/20120429042725/http://montanismoaventura.com/ entitled "Mallorca Verde" to web.archive.org/web/20120430191214/http://213.97.154.118/mallorcaverde/ The target is a bit weird and almost empty.
- 216.218.196.146 at entitled "AskTheDr.com" to web.archive.org/web/20070303080403/http://216.218.196.146/askthedr/index.htm
We can also get the full line for each with sorted by least common domains with the slow:
git grep --no-color -I -h --no-line -o 'https?://[^/">?]+[/">?]' | sed -r 's/.$//' | sort | uniq -c | sort -nk1 | awk '{if ($1 < 10) print $2}' | xargs -I{} git --no-pager grep -h --no-line -o '{}.*<' | tee tmp.log
We can search for all IP-like strings with:
git grep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\b'As per:a few of the HTMLs are interpreted by grep as being binary:
grep . */index.html | grep 'binary file matches'grep: china-destinations.org/index.html: binary file matches
grep: classicalmusicboxonline.com/index.html: binary file matches
grep: driversinternationalgolf.com/index.html: binary file matches
grep: familyhealthonline.net/index.html: binary file matches
grep: grubbersworldrugbynews.com/index.html: binary file matches
grep: hai-pow.com/index.html: binary file matches
grep: hi-tech-today.com/index.html: binary file matches
grep: networkofnews.com/index.html: binary file matches
grep: nigeriastar.net/index.html: binary file matches
grep: noticias-caracas.com/index.html: binary file matches
grep: theentertainbiz.com/index.html: binary file matches
grep: thefilmcentre.com/index.html: binary file matches
grep: theinternationalgoal.com/index.html: binary file matches
grep: wildbirds-seasia.com/index.html: binary file matches
grep: worldedgenews.com/index.html: binary file matchesThe discoverty of a possible HTML information leaks on HTML motivated us to download all HTML and have a grep.
<title> of webofcheer.com which is cryptically set as:pg1cWe started grepping with:and to just get the titles alone for visual inspection:
grep -ai '<title>' */index.htmlgrep -ahi '<title>' */index.html | sed -r 's/^\s*<title>//;s/<\/title>.*//'Some mildly interesting facts include:It is impossible to tell if these were oversights, or intentional to simulate common web development quircks. But they are cute in any case.
- opensourcenewstoday.com is titled just as "Title"
opensourcenewstoday.com/index.html:<title>Title</title> - a few sites are titled "Untitled Document" e.g.:This may have been the default title in Adobe Dreamweaver.
media-coverage-now.com/index.html:<title>Untitled Document</title> newsandsportscentral.com/index.html: <title>Untitled Document</title> newsincirculation.com/index.html:<title>Untitled Document</title> newsworldsite.com/index.html:<title>Untitled Document</title> primetimemovies.net/index.html:<title>Untitled Document</title> unganadormundial.com/index.html:<title>Untitled Document</title> - some others have empty title:
aeronet-news.com/index.html:<title></title> al-rashidrealestate.com/index.html: <title></title> arabicnewsunfiltered.com/index.html:<title></title> dailynewsandsports.com/index.html:<title></title> electronictechreviews.com/index.html:<title></title> indirectfreekick.com/index.html:<title></title> iran-newslink-today.com/index.html:<title></title> iraniangoals.com/index.html:<title></title> kickitnews.com/index.html:<title></title> mediocampodefutbol.com/index.html:<title></title> middle-east-newstoday.com/index.html: <title></title> mygadgettech.com/index.html:<title></title> sayaara-auto.com/index.html:<title></title> techwatchtoday.com/index.html:<title></title> the-open-book-online.com/index.html:<title></title> thenewsofpakistan.com/index.html:<title></title> theworld-news.net/index.html:<title></title> todaysengineering.com/index.html:<title></title> todaysnewsreports.net/index.html:<title></title> worldnewsandent.com/index.html:<title></title> - some others are titled just "index" or a variant of it:
all-sport-headlines.com/index.html:<title>index</title> europeannewsflash.com/index.html:<title>Index</title> fgnl.net/index.html:<title>Index Page</title> iraniangoalkicks.com/index.html:<title>index</title> just-the-news.com/index.html:<title>index</title> mide-news.com/index.html:<title>index</title> mytravelopian.com/index.html:<title>Index</title> noticiasdelmundolatino.com/index.html:<title>index</title> pakcricketgrd.com/index.html: <title>index</title> pangawana.com/index.html:<title>index</title> sportsnewsfinder.com/index.html:<title>index</title> thenewseditor.com/index.html:<title>index</title> turkishnewslinks.com/index.html:<title>index2</title> wahidfutbol.com/index.html:<title>index</title> webscooper.com/index.html:<title>index</title> webworldsports.com/index.html:<title>index</title> - a few don't have
<title>at all:b2bworldglobal.com/index.html bailandstump.com/index.html businessexchangetoday.com/index.html commercialspacedesign.com/index.html court-masters.com/index.html flyingtimeline.com/index.html marketflows.net/index.html nouvellesetdesrapports.com/index.html senderosdemontana.com/index.html sixty2media.com/index.htm
Many of the files appear to contain JavaScript functions in a format generated by Adobe Dreamweaver, making it almost certain that at least some of the websites were developed in that editor. This was first pointed out by Reddit user sq00q. Also note that the username spells "boobs" upside down in leet.
For example, starwarsweb.net contains the four following functions, first commented out which is funny and has some version comments:and then repeated on a
function MM_swapImgRestore() { //v3.0
function MM_preloadImages() { //v3.0
function MM_findObj(n, d) { //v4.01
function MM_swapImage() { //v3.0body onload. Here MM_ stands for MacroMedia, and is mentioned e.g. at:Doing:on github.com/cirosantilli/cia-2010-websites-dump currently gives 64 hits out of 421 websites.
git grep MM_swapImage | sed -r 's/\/.*//' | sort -u | wcThe approximate version history is:
One promising way to find more of those would be with IP searches, since it was stated in the Reuters article that the CIA made the terrible mistake of using several contiguous IP blocks for those website. What a phenomenal OPSEC failure!!!
The easiest way would be if Wayback Machine itself had an IP search function, but we couldn't find one: Search Wayback Machine by IP.
viewdns.info was the first easily accessible website that Ciro Santilli could find that contained such information.
Our current results indicate that the typical IP range is about 30 IPs wide.
E.g. searching: viewdns.info/iphistory and considering only hits from 2011 or earlier we obtain:
- capture-nature.com
- 65.61.127.163 - Greenacres - United States - TierPoint - 2013-10-19
- activegaminginfo.com
- 66.175.106.148 - United States - Verizon Business - 2012-03-03
- iraniangoals.com
- 68.178.232.100 - United States - GoDaddy.com - 2011-11-13
- 69.65.33.21 - Flushing - United States - GigeNET - 2011-09-08
- rastadirect.net
- 68.178.232.100 - United States - GoDaddy.com - 2011-05-02
- iraniangoalkicks.com
- 68.178.232.100 - United States - GoDaddy.com - 2011-04-04
- headlines2day.com
- 118.139.174.1 - Singapore - Web Hosting Service - 2013-06-30. Source: viewdns.info
- 184.168.221.91 2013-08-12T06:17:39. Source: 2013 DNS Census grep
- fightwithoutrules.com
- fitness-dawg.com
Neither of these seem to be in the same ranges, the only common nearby hit amongst these ranges is the exact
68.178.232.100, and doing reverse IP search at viewdns.info/reverseip/?host=68.178.232.100&t=1 states that it has 2.5 million hostnames associated to it, so it must be some kind of Shared web hosting service, see also: superuser.com/questions/577070/is-it-possible-for-many-domain-names-to-share-one-ip-address, which makes search hard.Ciro then tried some of the other IPs, and soon hit gold.
Initially, Ciro started by doing manual queries to viewdns.info/reversip until his IP was blocked. Then he created an account and used his 250 free queries with the following helper script: ../cia-2010-covert-communication-websites/viewdns-info.sh. The output of that script can be seen at: github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/viewdns-info.sh.
Here we list of suspected domains for which the correct IP was apparently not found since there are no neighbouring hits.
These are suspicious, and suggest either that we didn't obtain the correct reverse IP, or a change in CIA methodology from an older time at which they were not yet using the obscene IP ranges.
For example, in the case of inews-today.com, 2013 DNS Census gave one IP 193.203.49.212, but then viewdns.info gave another one 66.175.106.146 which fit into an existing IP range, and which assumed to be the correct IP of interest.
A similar case happened when we found IP 212.209.74.126 for headlines2day.com with dnshistory.org: dnshistory.org/historical-dns-records/a/headlines2day.com.
It is also possible that some of them are simply false positives so they should be taken with a grain of salt. Further reverse engineering e.g. of comms or HTML analysis might be able to exclude some of them.
It is interesting to note that Reuters seems to have featured disproportionately many hits from that range, one wonders why that happened. It is possible that they chose these because they actually didn't have any nearby hits to give away less obvious information, though they did pick some from the ranges as wel.
In what follows we list the domains with possible reverse IPs and what was explored so far for each. We consider IPs not in a range to be uncertain, and that instead their domains might have been previously in a range which we
dailynewsandsports.com. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches
- 216.119.129.94. rdns source: viewdns.info "location": "United States", "owner": "A2 Hosting, Inc.", "lastseen": "2012-04-13". Tested viewdns.info range: 216.119.129.85 - 216.119.129.86, 216.119.129.89 - 216.119.129.99, ran out of queries for 87 and 88
- 216.119.129.90: eastdairies.com 2011-04-04. Promising name and date, but no archives alas.
- 216.119.129.97: miideaco.com 2016-02-01
- 216.119.129.114 Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches, also present on viewdns.info but at a later date from previous "location": "United States", "owner": "A2 Hosting, Inc.", "lastseen": "2013-11-29". Tested viewdns.info range: 216.119.129.109 - 216.119.129.119
- 216.119.129.110: dommoejmechty.com.ua. Legit.
- 216.119.129.111: dailybeatz.com: Legit
- 216.119.129.113:
- audreygeneve.com
- reyzheng.com
- jacintorey.com
- 216.119.129.114: dailynewsandsports.com. hit.
- 216.119.129.115: afxchange.com legit/broken
- 216.119.129.116: danafunkfinancial.com: legit
- 208.73.33.194 on securitytrails.com
iranfootballsource.com:
- 34.98.99.30 Kansas City - United States Google LLC 2021-05-24
- 184.168.221.94 United States GoDaddy.com 2020-07-21
- 50.63.202.66 United States GoDaddy.com 2020-07-07
- 50.63.202.86 United States GoDaddy.com 2020-05-28
- 184.168.221.94 United States GoDaddy.com 2020-05-13
- 50.63.202.74 United States GoDaddy.com 2020-04-29
- 50.18.223.191 San Jose - United States Amazon.com 2015-03-23. Sources: 2013 DNS Census and viewdns.info
- no viewdns.info hits +- 10
- 85.13.200.108 United Kingdom Coreix Dedicated Customer Allocation 2013-06-30. Source: viewdns.info
- 85.13.200.108: 1000 hits, so unlikely to be the one
iraniangoalkicks.com:
- 68.178.232.100: treverse IP source: viewdns.info. see rastadirect.net.
- 208.71.138.130 2010-02-22 -> 2010-08-06, QWK.net Hosting, L.L.C.. source: dnshistory.org/historical-dns-records/a/iraniangoalkicks.com. Large shared hosting domain, no good nearby hits, several legit sites.
- securitytrails.com/domain/iraniangoalkicks.com/history/a says:
- 2011-03-31 68.178.232.100
- 2008-09-01 208.71.138.130
iraniangoals.com:
- 68.178.232.100: see rastadirect.net
- 69.65.33.21 - Flushing - United States - GigeNET - 2011-09-08. Also at: dnshistory.org/historical-dns-records/a/iraniangoals.com 2009-08-03 -> 2011-01-12 69.65.33.21 viewdns.info/reverseip/?t=1&host=69.65.33.21 80 virtual nothing pops to eye on quick read:
- 69.65.33.2: onemincustomerservice.com. web.archive.org/web/20091015044922/http://www.onemincustomerservice.com/. Doesn't feel like a hit. cqcounter.com/whois/www/onemincustomerservice.com.html error
- 69.65.33.5: 400+ domains
- 69.65.33.6: 4 domains but recent resolutions only
- similar status for everything else withing +-20. A couple of domains, no easy hits
- securitytrails.com/domain/iraniangoals.com/history/a same from 2008-09-17
football-enthusiast.com:
- 212.4.18.14: Tested viewdns.info range: 212.4.18.1 - 212.4.18.29. This is a curious case, rather close to 212.4.18.129 sightseeingnews.com, but not quite in the same range apparently. Viewdns.info also agrees on its history with only "212.4.18.14", "location" : "Milan - Italy", "owner" : "MCI Worldcom Italy Spa", "lastseen" : "2013-06-30" of interest.
cyhiraeth-intlnews.com:
news-latina.com: domainsbyproxy.com 2007-12-17
- dnshistory.org/historical-dns-records/a/news-latina.com 2010-03-11 -> 2010-08-16 64.92.111.3. this has several hits for the same IP on DNS Census 2013 which is unusual. Tested viewdns.info range: 64.92.111.1 - 64.92.111.13
- viewdns.info/iphistory/?domain=news-latina.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-08-11 virtual
- 64.92.111.3 United States MASSIVE-NETWORKS 2011-07-27 mdeium virtual viewdns.info/reverseip/?t=1&host=64.92.111.3
- web.archive.org/web/20110211133905/http://tipsypotpole.com/ off
- web.archive.org/web/20250000000000*/quantumhealing.com popular
- web.archive.org/web/20110202114353/http://outdoortradition.com/ redirecting. dawhois.com/www/outdoortradition.com.html not found.
- web.archive.org/web/20250000000000*/gtinvestigations.com popular
- web.archive.org/web/20250000000000*/dig-itmag.com big
europeannewsflash.com:
- viewdns.info/iphistory/?domain=europeannewsflash.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-10-09 virtual
- 216.131.66.209 San Francisco - United States STRTEC 2011-09-08. Tested viewdns.info range: 216.131.66.201 216.131.66.219
- dnshistory.org/historical-dns-records/a/europeannewsflash.com 2010-02-06 -> 2010-08-02 216.131.66.209. Tested.
outlooknewscast.com:
- dnshistory.org/historical-dns-records/a/outlooknewscast.com
- 2009-08-08 -> 2011-02-11 74.53.159.130. Tested viewdns.info range: 74.53.159.120 - 74.53.159.140
- 74.53.159.130: aeromedhistory.org 2014-11-29
- 74.53.159.130: mariposahorticultural.com 2022-11-28
- 74.53.159.130: thewritestuffresume.com 2011-04-04. Legit.
- 2009-08-08 -> 2011-02-11 74.53.159.130. Tested viewdns.info range: 74.53.159.120 - 74.53.159.140
- viewdns.info/iphistory/?domain=outlooknewscast.com
- 204.93.178.121 Chicago - United States SERVERCENTRAL 2011-09-08. Tested viewdns.info range: 204.93.178.111 - 204.93.178.131. Skimmed through, nothing of great interest.
- 74.53.159.130 United States SOFTLAYER 2011-04-04. Tested.
24hoursprimenews.com:
- dnshistory.org/historical-dns-records/a/24hoursprimenews.com 2009-12-14 -> 2011-10-04 216.9.68.24. Mid virtual: viewdns.info/reverseip/?t=1&host=216.9.68.24 had a quick look but no hits:
- viewdns.info/iphistory/?domain=24hoursprimenews.com 216.9.68.24 United States VONAGE-BUSINESS 2012-01-11. Tested.
- securitytrails.com/domain/24hoursprimenews.com/history/a same
farsi-newsandweather.com:
- dnshistory.org/historical-dns-records/a/farsi-newsandweather.com 2010-02-07 -> 2010-08-03 69.49.101.19. Tested viewdns.info range: 69.49.101.9 - 69.49.101.19
- viewdns.info/iphistory/?domain=farsi-newsandweather.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-01-11 virtual
- 69.49.101.19 Canada INFB-AS 2011-11-13. Tested.
global-view-news.com:
- dnshistory.org/historical-dns-records/a/global-view-news.com 2010-02-13 -> 2010-08-04 67.220.228.130. Tested viewdns.info range: 67.220.228.120 - 67.220.228.160:
- 67.220.228.150: investfromhome.co.uk 2011-09-05. No archives.
- viewdns.info/iphistory/?domain=global-view-news.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-01-11 virtual
- 69.90.161.195 Canada COGECO-PEER1 2011-09-08. Unknown. Tested viewdns.info range: 69.90.161.185 69.90.161.205. Some virtual misses. viewdns.info/reverseip/?t=1&host=69.90.161.195 medium virtual, canada.
health-men-today.com:
- dnshistory.org/historical-dns-records/a/health-men-today.com
- 2011-01-07 -> 2011-01-07 69.90.162.165. Tested viewdns.info range: 69.90.162.155 - 69.90.162.175. Virtuals.
- 2009-11-30 -> 2010-05-27 67.220.228.224. New range with global-view-news.com? Tested viewdns.info range: 67.220.228.214 67.220.228.234
- 2009-08-01 -> 2009-09-19 69.42.58.50. Tested viewdns.info range: 69.42.58.40 - 69.42.58.60. Virtuals, canada.
- viewdns.info/iphistory/?domain=health-men-today.com
- securitytrails.com/domain/health-men-today.com/history/a
- 69.42.58.50 Aptum Technologies 2008-09-01 (17 years) 2008-09-04 (17 years) 3 days
firstnewssource.com:
pars-technews.com:
- dnshistory.org/historical-dns-records/a/pars-technews.com 2009-08-08 -> 2011-02-13 74.220.219.104 Tested viewdns.info range: 74.220.219.94 74.220.219.114. viewdns.info/reverseip/?t=1&host=74.220.219.104 medium virtual haven't bothered much.
- viewdns.info/iphistory/?domain=pars-technews.com 74.220.219.104 United States UNIFIEDLAYER-AS-1 2012-11-12. Tested.
newdaynewsonline.com:
- dnshistory.org/historical-dns-records/a/newdaynewsonline.com 2010-03-10 -> 2010-08-15 76.163.54.16. Tested viewdns.info range: 76.163.54.6 76.163.54.26. viewdns.info/reverseip/?t=1&host=76.163.54.16 empty.
- 76.163.54.23: leewoodwork.com 2014-07-05
- viewdns.info/iphistory/?domain=newdaynewsonline.com
- 74.91.154.56 United States INTERNAP-BLOCK-4 2012-11-12 unknown range. Tested viewdns.info range: 74.91.154.46 74.91.154.66
- 74.91.154.61: benefitsla.com 2013-04-21. Legit.
- 76.163.54.16 United States WINDSTREAM 2011-09-08 unknown range. Tested.
- 74.91.154.56 United States INTERNAP-BLOCK-4 2012-11-12 unknown range. Tested viewdns.info range: 74.91.154.46 74.91.154.66
sportsnewsfinder.com:
- dnshistory.org/historical-dns-records/a/sportsnewsfinder.com 2009-08-11 -> 2011-02-24 66.113.196.128. Tested viewdns.info range: 66.113.196.118 66.113.196.138. viewdns.info/reverseip/?t=1&host=66.113.196.128 empty.
- viewdns.info/iphistory/?domain=sportsnewsfinder.com
- 50.63.202.58 United States AS-26496-GO-DADDY-COM-LLC 2013-03-23 some similar hits on other sites, possibly all flukes
- 207.150.219.159 United States AFFINITY-INTER 2013-03-02
- 66.113.196.128 United States NETNATION 2012-01-11. Tested.
newsworldsite.com:
- viewdns.info/iphistory/?domain=newsworldsite.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2013-05-20 big virtual
- 204.93.159.80 Chicago - United States SERVERCENTRAL 2013-04-21. Tested viewdns.info range: 204.93.159.70 204.93.159.90. viewdns.info/reverseip/?t=1&host=204.93.159.80 medium virtual.
- 204.93.159.84: team-merk.com 2011-08-11. No archives.
todaysnewsreports.net:
- viewdns.info/iphistory/?domain=todaysnewsreports.net
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-07-01
- 205.178.189.129 United States NETWORK-SOLUTIONS-HOSTING 2013-05-20 likely virtual
- 173.255.131.72 Reno - United States UK-2 Limited 2012-08-27. Tested viewdns.info range: 173.255.131.62 173.255.131.82. Virtual and modern hits only.
- 67.213.211.232 United States UK-2 Limited 2011-09-07 unknown. Tested viewdns.info range: 67.213.211.222 67.213.211.242. viewdns.info/reverseip/?t=1&host=67.213.211.232 empty.
- 67.213.211.236: icf-finan.com 2015-01-20
- 67.213.211.237: playinside.me 2016-02-04. Nice domain hack, but no.
- 67.213.211.239: reality-sexxx.com 2011-09-08
hassannews.net:
- viewdns.info/iphistory/?domain=hassannews.net
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-07-08
- 205.178.189.131 United States NETWORK-SOLUTIONS-HOSTING 2013-07-01. Likely virtual.
todayoutdoors.com:
- dnshistory.org/historical-dns-records/a/todayoutdoors.com
- 2009-08-11 -> 2010-07-07 174.133.44.90. Tested viewdns.info range: 174.133.44.80 174.133.44.100. Virtual and modern. viewdns.info/reverseip/?t=1&host=174.133.44.90 two modern domains.
- 2011-03-01 -> 2011-03-01 174.123.172.82 unknown. Tested viewdns.info range: 174.123.172.72 174.123.172.92. Virtuals.
- viewdns.info/iphistory/?domain=todayoutdoors.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-07-02 virtual
- 174.123.172.82 United States SOFTLAYER 2011-04-04. Tested.
globaltourist.net:
- dnshistory.org/historical-dns-records/a/ 2009-07-30 -> 2011-01-01 69.59.20.215 unknown. Tested viewdns.info range: 69.59.20.205 69.59.20.225. Virtuals.
- viewdns.info/iphistory/?domain=globaltourist.net
- 216.172.170.14 United States NETWORK-SOLUTIONS-HOSTING 2013-07-08
- 216.21.239.197 United States NETWORK-SOLUTIONS-HOSTING 2012-06-25
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-04-09 big virtual
- 174.136.34.154 United States IHNET 2012-03-12 unknown. Tested viewdns.info range: 174.136.34.144 174.136.34.164
- 74.119.145.101 Frankfurt am Main - Germany PERFORMIVE 2011-09-07. Tested viewdns.info range: 74.119.145.91 74.119.145.111. One virtual.
- 69.59.20.215 United States ATLRETAIL 2011-06-22. Tested viewdns.info/reverseip/?t=1&host=69.59.20.215
terrain-news.com:
- JAR
- viewdns.info/iphistory/?domain=terrain-news.com None in simple ranges.
- 204.11.56.25 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-11-08. Virtuals.
- 208.91.197.19 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-05-20. Virtual 167. viewdns.info/reverseip/?host=208.91.197.19&t=1 not very promising.
- eurotravelnyc.com legit web.archive.org/web/20110201195411/http://eurotravelnyc.com/
- 208.187.167.20 United States DATANOC 2012-01-11. Tested viewdns.info range: 208.187.167.10 208.187.167.30. Newer domains. viewdns.info/reverseip/?t=1&host=208.187.167.20 only has one conck.ooo. WTF.
- securitytrails.com/domain/terrain-news.com/history/a same:
intlnewsdaily.com
- dnshistory.org/historical-dns-records/a/intlnewsdaily.com 2010-02-21 -> 2010-08-06 75.126.136.179. unknown range. viewdns.info/reverseip/?t=1&host=75.126.136.179 empty checked 75.126.136.171 - 75.126.136.179
- viewdns.info/iphistory/?domain=intlnewsdaily.com
- 208.91.197.19 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-05-20. Virtual. Tested.
- 63.247.95.50 Austell - United States NTHL 2012-06-29 unknown. Tested viewdns.info range: 63.247.95.40 63.247.95.60
- 63.247.95.50: 2b-sports.com 2013-04-21
- 63.247.95.50: caldentalinsurance.com 2014-07-05
- 63.247.95.50: cameronbal-photography.com 2012-06-29
- 63.247.95.50: congbetham.com 2014-07-05
- 63.247.95.50: essentialintelligenceagency.com 2023-03-07
- 63.247.95.50: isabellavalentina.com 2014-07-05
- 63.247.95.50: jhraccounting.com.au 2021-05-03
- 63.247.95.50: missouribreaks294.com 2012-06-29
- 63.247.95.50: startorganize.com 2011-08-11
- 63.247.95.50: tifocus.net 2011-08-11
- 63.247.95.50: tifocus.org 2011-08-10
- 63.247.95.50: whitepartyorlando.com 2012-01-11
- 204.11.56.25 (ipinf.ru) viewdns.info/reverseip/?t=1&host=204.11.56.25 Virtual 2,999
- securitytrails.com/domain/intlnewsdaily.com/history/a empty on dates
opensourcenewstoday.com:
- viewdns.info/iphistory/?domain=opensourcenewstoday.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-11-13 virtual
- 64.16.193.48 Riyadh - Saudi Arabia Saudi Telecom Company JSC 2011-09-08. Tested viewdns.info range: 64.16.193.38 64.16.193.55. Ran out. viewdns.info/reverseip/?t=1&host=64.16.193.48 virtual 55, lots of porn
- securitytrails.com/domain/opensourcenewstoday.com/history/a
techwatchtoday.com:
- viewdns.info/iphistory/?domain=techwatchtoday.com
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-11-29 virtual
- 66.11.225.226 United States TNWEB-LEW-001 2012-01-11 unknown. Checked 66.11.225.220 - 66.11.225.233
- dnshistory.org/historical-dns-records/a/techwatchtoday.com 2009-08-11 -> 2011-02-26 66.11.225.226 big shared host
- securitytrails.com/domain/techwatchtoday.com/history/a same
Likely hits possible but whose archives is too broken to be easily certain. If:were to ever be found, these would be considered hits.
- nearby IP hits
- proper reverse engineering of their comms if any, or any other page fingerprints
- 216.97.231.56 nouvelles-d-aujourdhuis.com. 2011. Stylistically perfect, but no nearby IP hits. domainsbyproxy.com. Maybe looking into HTML would help confirm:But wrong IP? likely CGI comms variant under the signup page: web.archive.org/web/20090405045548/http://nouvelles-d-aujourdhuis.com/members.html.
rss-items
Tested viewdns.info range: 216.97.231.46 - 216.97.231.66. Not a single reverse IP hit in there.viewdns.info also assigns it 50.63.202.46, GoDaddy.com, LLC, 2013-11-08 in addition to 216.97.231.56, Canada, IPXO LLC, 2013-09-06. This is very near other iranfootballsource.com flukes, so likely useless.securitytrails.com also gives it one earlier IP 209.200.240.250 last seen 2008-09-20: securitytrails.com/domain/nouvelles-d-aujourdhuis.com/history/a Hydra Communications Ltd before 216.97.231.56 "ASU doctor" first seen 2008-09-20 (15 years)> Tested viewdns.info range: 209.200.240.240 - 209.200.240.260 empty at the time of interest.Marked copyright 2006, so mega early.
africainnews.com
- no archives of the HTML. dawhois.com/www/africainnews.com.html somewhat in-style but unclear.
- SWF. A reverse engineering of the SWF should be able to confirm.
- web.archive.org/web/20111007194814/http://africainnews.com/robots.txt
- dnshistory.org/historical-dns-records/a/africainnews.com
- 2009-12-29 -> 2010-07-28 72.167.232.43. Tested viewdns.info range: 72.167.232.33 - 72.167.232.53. Several virtual hosts there. viewdns.info/reverseip/?t=1&host=72.167.232.43 medium virtual haven't bothered to explore much
- 2011-10-14 -> 2011-10-14 68.178.232.100 virtual
- 2012-08-12 -> 2012-08-12 97.74.42.79. Tested viewdns.info range: 97.74.42.69 - 97.74.42.89
- 97.74.42.74: landtex.net 2023-03-22
- 97.74.42.76: solidasshonky.com 2023-03-07
- 97.74.42.77: solidasshonky.com 2023-03-07
- 97.74.42.78: blakebrothers.co 2018-05-05
- 97.74.42.78: learningjbe.com 2023-02-02
- 97.74.42.78: solidasshonky.com 2023-03-07
- 97.74.42.78: sourceuae.com 2023-03-07
- 97.74.42.78: superiorfoodservicesales.com 2017-09-10
- 97.74.42.79: large virtual
- 97.74.42.80: waiasialtd.com 2016-10-17
- viewdns.info/iphistory/?domain=africainnews.com
- 50.63.202.92 United States AS-26496-GO-DADDY-COM-LLC 2013-06-30. Likely large virtual.
- 97.74.42.79 United States AS-26496-GO-DADDY-COM-LLC 2013-05-20. tested.
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-06-29 virtual
- 68.178.232.99 United States AS-26496-GO-DADDY-COM-LLC 2011-11-13
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-10-09 virtual
- 72.167.232.43 United States GO-DADDY-COM-LLC 2011-09-08. Tested.
globalsentinelsite.com. dawhois.com/www/globalsentinelsite.com.html empty. Copyright 2011 on top and 2008 on bottom. Unusually wide, has a few sections, but somewhat shallow. Copyright 2008. JAR JAR. a.rss-item
- dnshistory.org/historical-dns-records/a/globalsentinelsite.com 2010-02-13 -> 2010-08-04 74.124.210.249 unknown
- viewdns.info/iphistory/?domain=globalsentinelsite.com
- 74.124.210.249 United States INMOTION 2011-11-13 unknown viewdns.info/reverseip/?host=74.124.210.249&t=1 has 347 hits
- JAR file structure:with:
./META-INF/MANIFEST.MF ./META-INF/WORLD.DSA ./META-INF/WORLD.SF ./global ./global/applet ./global/applet/A.class ./global/applet/Aa.class ./resource/resources.binManifest-Version: 1.0 Created-By: 1.4.2_15-b02 (Sun Microsystems Inc.) Ant-Version: Apache Ant 1.6.5 Name: global/applet/Bs.class SHA1-Digest: R1qrWUT6kYTLKa6TSmyWbBhLQSw= Name: global/applet/Ay.class SHA1-Digest: L0xOVdhBzEcmW8czjERAVH+tNyI=
todaysolar.com. This might just be legit, but keeping it around just in case.
- 2011
- JAR
- dnshistory.org/historical-dns-records/a/todaysolar.com 2009-08-11 -> 2011-03-01 74.208.62.112 unknown
- viewdns.info/iphistory/?domain=todaysolar.com 74.208.62.112 United States PROFITBRICKS-USA 2012-11-12
62.22.60.49: telecom-headlines.com. UUNET in Spain. Found with: visual inspection of full 2013 DNS Census virtual host cleanup list just before worldnewsnetworking.com. Tested viewdns.info range: 62.22.60.34 - 62.22.60.66
- 62.22.60.33: newsperk.com. Almost certainly a hit. Stylistically perfect, rss-item. But no comms not found. Ennerving! 2011. English. Egypt. news. Later legitimately reused.
- 62.22.60.34: freeslideshow.net. Legit? Attempting to open any HTML archives leads to an infinite page load loop, e.g. 2010. A subpage however exists: web.archive.org/web/20101230001640/http://freeslideshow.net/index_files/a.htm and appears legit.
- 62.22.60.40: travel-passage.com. Hit.
- 62.22.60.42: newsupdatesite.com. Hit.
- 62.22.60.46: flyingtimeline.com. Hit.
- 62.22.60.47: globalemergenceadvisorsbkserver.com. Legit.
- 62.22.60.48: currentcommunique.com. Hit.
- 62.22.60.49: telecom-headlines.com. Hit.
- 62.22.60.52: collectedmedias.com. Hit.
- 62.22.60.54: romulusactualites.com. Hit.
- 62.22.60.55: thefilmcentre.com. Hit.
- 62.22.60.56: traveltimenews.com. Hit.
62.22.61.206 worldnewsnetworking.com. UUNET in Spain. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 62.22.61.188 - 62.22.61.224
- 62.22.61.193: awfaoi.org. Hit.
- 62.22.61.197: rc5sports.com. Hit.
- 62.22.61.198: inside-vc.com. Hit.
- 62.22.61.200: zerosandonesnews.com. Hit.
- 62.22.61.202: bailsnboots.com. Hit.
- 62.22.61.203: the-cricketer-online.com. Hit.
- 62.22.61.204: hollywoodscreen.net. Hit.
- 62.22.61.206: worldnewsnetworking.com. Hit.
- 62.22.61.212: nuestrasfinanzas.com. Hit.
- 62.22.61.213: sandstormnews.com. Hit.
- 62.22.61.215: the-tech-mind.com. Hit.
- 62.22.61.217: court-masters.com. Hit.
- 62.22.61.219: allworldstatistics.com. Hit.
- 62.22.61.220: newsjaka.com. Hit.
- 62.22.61.221: biochemresource.com. Archive broken/empty. One archive: contains an epically long URL that might shed light into something: web.archive.org/web/20120529121245/http://www.biochemresource.com/?fp=iboHtuxnjLG66y52DkK1xCFuZDBnVC8wovQepLt2Tk%2Bo1JIgIdVb6WL8kv6sSOEtxwcq4EbiJ0GxFY9N6HSWlg%3D%3D&prvtof=97vgfKVqt1Sd68qgNDPXB0o7Rwo%2FO3GKiiMG7fane6A%3D&poru=Zd9DHFaHFZ6ZrRLm8SW3egagqvdpzHhWb%2FoulRGeEYIUSVATB5gwTIDhluetONjG7xovtb%2FrvDStoqiAF1O8wA%3D%3D&. Asked at: stackoverflow.com/questions/47310661/any-idea-what-are-fp-prvtof-poru-in-a-url but no reply so far. One day my friend, one day. cqcounter.com/whois/www/biochemresource.com.html not found.
- 62.22.61.222: www.news-blitz-ar.com (ipinf.ru). No archives. Perfect domain name theme match. cqcounter.com/whois/www/news-blitz-ar.com.html not found.
65.218.91.17 alljohnny.com. UUNET in United States. One of the Reuters websites.
- 208.91.197.132: rdns source: viewdns.info. Big virtual.
- 65.218.91.17: rdns source? : viewdns.info. Tested viewdns.info range: 65.218.91.13 - 65.218.91. 17
- 65.218.91.9: welcometonyc.net. Hit. rdns source: ipinf.ru. Later also at 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-10-21 by viewdns.info
- rolling-in-rapids.com. Hit.
- 65.218.91.17
- international-smallbusiness.com. Stylitsic match, but some uncommon features like the country seelctor dropdown.
- Archives:Also a potential unarchived CGI comms: web.archive.org/web/20110202031627/https://ssl.international-smallbusiness.com/cgi-bin/starting.cgi Perhaps with some better HTML reversing we could confirm a hit. Same registrar as alljohnny "L. Glaze" fuck me.
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-10-19. Big virtual.
- 65.218.91.17 United States UUNET 2013-09-06
- Archives:
- international-smallbusiness.com. Stylitsic match, but some uncommon features like the country seelctor dropdown.
- 65.218.91.9: welcometonyc.net. Hit. rdns source: ipinf.ru. Later also at 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-10-21 by viewdns.info
- 216.168.229.50: whoisxmlapi 2008-09-01 (15 years) 2010-04-17. Checked viewdns.info range: 216.168.229.45 - 216.168.229.55. viewdns.info/reverseip/?t=1&host=216.168.229.50 3k domains.
63.131.229.12 cyberreportagenews.com. ADHOST in Coeur d'Alene - United States. Tested viewdns.info range: 63.131.228.248 - 63.131.229.30
- 63.131.229.2: fightskillsresource.com. Hit
- 63.131.229.4: unitedterritorynews.com. Hit
- 63.131.229.9: show-dustry.com. Hit
- 63.131.229.10: afghanpoetry.net. Hit. Also at 74.254.12.166 in another range.
- 63.131.229.11: mythriftytrip.com. Hit
- 63.131.229.12: cyberreportagenews.com. Hit.
- 63.131.229.13: sunrise-news.com. Hit.
- 63.131.229.15: cricketnewsforindia.com. Hit.
- 63.131.229.16:
- nutricion-saludable.info. No archives. cqcounter.com/whois/www/nutricion-saludable.info.html has the exact same screenshot at the .net one, so also hit.
- nutricion-saludable.net. Hit.
- 63.131.229.18: itnl-xchange.com. Hit.
- 63.131.229.20:
- fixashion.net. Hit.
- a few others
63.130.160.50 theglobalheadlines.com. CW Vodafone Group PLC in United States. Found with: 2013 DNS census secureserver.net MX records intersection 2013 DNS Census virtual host cleanup. Tested viewdns.info range: 63.130.160.35 - 63.130.160.75
- 63.130.160.50: theglobalheadlines.com. Hit.
- 63.130.160.51:
- hai-pow.com. Hit.
- secudenetworksecurity.com. No archives. cqcounter.com/whois/www/secudenetworksecurity.com.html blank image.
- 63.130.160.53: echessnews.com. Hit.
- 63.130.160.59: technologiewissen.com. No archives from the time. Would be Technology knowledge in German, so another likely German hit. Shame. cqcounter.com/whois/www/technologiewissen.com.html empty
- 63.130.160.60: boxingstop.net. Hit.
- 63.130.160.61: bookmarksthis.com. Hit.
- 63.130.160.62: azerinews.org. Hit.
64.16.204.55 holein1news.com. Saudi Telecom Company JSC in Saudi Arabia. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 64.16.204.50 - 64.16.204.63. With did Wayback Machine have so few archives here? TODO stopping viewdns.info exploration a bit short due to that.
- 64.16.204.35: ironcityfootball.com. web.archive.org/web/20080510230549/ironcityfootball.com Legit/broke. cqcounter.com/whois/www/ironcityfootball.com.html from 2011 could be in style though... "Iron City" is a historical nickname for Pittsburgh, Pennsylvania.
- 64.16.204.51: africannewsandsports.com. No archives. rdns source: viewdns.info. cqcounter.com/whois/www/africannewsandsports.com.html not found.
- 64.16.204.53: bosniakbusinessnews.com. Hit.
- 64.16.204.54: affairesdumonde.com. Hit.
- 64.16.204.55: holein1news.com. Hit.
- 64.16.204.56: fightorgohome.com. Uncertain. domainsbyproxy.com. Created: 2011-03-28. No archives. rdns source: viewdns.info cqcounter.com/whois/www/fightorgohome.com.html from 2011 not very typical but possible. Has a "Login" link visible for possible comms. The domain name is typical...
- 64.16.204.58: tech-topix.com. Hit.
- 64.16.204.60: pakpoldaily.com. No archives. rdns source: viewdns.info. TODO meaning? Might be Indonesian, maybe linked to police: www.facebook.com/watch/?v=880204266271955 cqcounter.com/whois/www/pakpoldaily.com.html not found.
65.61.127.163 capture-nature.com. ADHOST in Greenacres - United States. whois.arin.net/rest/net/NET-65-61-96-0-1/pft?s=65.61.127.163: Net Range: 65.61.96.0 - 65.61.127.255. Organization. Name: TierPoint, LLC. Tested viewdns.info range: 65.61.127.149 -
- 65.61.127.46: anahuacchamber.com 2012-12-22T14:59:01
- 65.61.127.117: medicaresupplementalinsurance.com, 2013-08-21T09:49:41. Legit.
- 65.61.127.121: counter-images.com 2013-08-22T11:14:44: web.archive.org/web/20110208173132/http://www.counter-images.com/ Empty.
- 65.61.127.125 zaphound.com 2013-08-21T02:25:40. Legit.
- 65.61.127.130: ambitions.org 2013-08-22T01:43:40. Legit.
- 65.61.127.161: european-footballer.com. Hit.
- 65.61.127.163: capture-nature.com. Hit.
- 65.61.127.164: futbolistico.net. 2012-02-20T03:25:33. Legit. web.archive.org/web/20130509004058/http://futbolistico.net/
- 65.61.127.165: travelconnectionsonline.com. Ciro initially though this might be a hit. But upon Googling it, there's now a mirror at: travelconn.tripod.com/. Combined with the lack of a standard communications mechanism and the 2001 copyright, maybe it isn't a hit after all
- 65.61.127.166: globalnewsbulletin.com: Hit.
- 65.61.127.167: internationalwhiskylounge.com. Hit.
- 65.61.127.168: the-golden-rule.info 2013-09-20T02:13:52. Hit.
- 65.61.127.169: crossovernews.net. Hit.
- 65.61.127.170: newsidori.com. Hit.
- 65.61.127.171: nrgconsultingandnews.com. Hit. 2013-08-13T18:45:05
- 65.61.127.172: premierstriker.com. Hit. 2012-01-11
- 65.61.127.174: dedrickonline.com. Hit.
- 65.61.127.175: altworldnews.com. Hit.
- 65.61.127.176: american-historyonline.com. Hit. 2011-09-08
- 65.61.127.177: material-science.org. Hit.
- 65.61.127.178: tee-shot.net. Hit.
- 65.61.127.180: screencentral.info. Hit.
- 65.61.127.181: worldnewsandtravel.com. Hit. 2011-11-13
- 65.61.127.182: pangawana.com. Hit.
- 65.61.127.183: cutabovenews.com. Hit.
- 65.61.127.184: worldwildlifeadventure.com. Hit.
- 65.61.127.186: explorealtmeds.com. Hit.
- 65.61.127.194: 16 domains, so unclear.
- about-video-games.com: web.archive.org/web/20121013013710/http://about-video-games.com/ off
- aboutfaceonline.com: web.archive.org/web/20120701000000*/aboutfaceonline.com off
- 65.61.127.200: cdl-link.com (ipinf.ru). Legit.
- 65.61.127.222: asianwhitecoffee.com 2012-07-16T09:21:05 web.archive.org/web/20110903080036/http://asianwhitecoffee.com/. Could be legit.
66.45.179.205 noticiasporjanua.com. ADHOST in Edmonds - United States. Found with: 2013 DNS Census virtual host cleanup. Tested viewdns.info range: 66.45.179.187 - 66.45.179.223
- 66.45.179.187: mail03.gatesfoundation.org. Legit.
- 66.45.179.192: thegraceofislam.com. Hit.
- 66.45.179.193: arabicnewsunfiltered.com. Hit.
- 66.45.179.194: raulsonsglobalnews.com. Hit.
- 66.45.179.195: aryannews.net. Hit.
- 66.45.179.199: attivitaestremi.com. Hit.
- 66.45.179.200: foodwineandsuch.com. Hit.
- 66.45.179.201: hitthepavementnow.com. Hit.
- 66.45.179.203: noticiascontinental.com. Hit.
- 66.45.179.205: noticiasporjanua.com. Hit.
- 66.45.179.206: podisticamondiale.com. Hit.
- 66.45.179.207: reflectordenoticias.com. Hit.
- 66.45.179.208: havenofgamerz.com. Hit.
- 66.45.179.209: vejaaeuropa.com. Hit.
- 66.45.179.210: sa-michigan.com. Hit.
- 66.45.179.211: absolutebearing.net. Hit.
- 66.45.179.212: grandretirement.net. No archives. cqcounter.com/whois/www/grandretirement.net.html blank image.
- 66.45.179.213: myportaltonews.com. Hit.
- 66.45.179.214: investmentintellect.com. Hit.
- 66.45.179.215: nigeriastar.net 2012-03-12. Hit.
66.104.169.184 bcenews.com. XO-AS15 in United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 66.104.169.158 - 66.104.169.189
- 66.104.169.162: bestsportsnews.net. Archive broken. cqcounter.com/whois/www/bestsportsnews.net.html error not found.
- 66.104.169.163: doctorsoncallsite.com. Hit. domainsbyproxy.com
- 66.104.169.164: lightandshadowonline.com. Hit. domainsbyproxy.com. Created: 2007-11-27. Updated: 2012-06-06.
- 66.104.169.168: plugged-into-news.net. Hit. Network Solutions, LLC. Registrant: Godfrey Hubbard.
- 66.104.169.169: worldsportsite.com. Hit. domainsbyproxy.com. Created: 2009-05-20.
- 66.104.169.171: golf-on-holiday.com. Hit. Network Solutions, LLC. Registrant: Tammy Pulley.
- 66.104.169.172: perspectiva-noticias.com. Hit. domainsbyproxy.com. Created: 2009-04-28.
- 66.104.169.175: aquaswimming.com. Hit. domainsbyproxy.com
- 66.104.169.177: dojo-temple.com. Hit. domainsbyproxy.com
- 66.104.169.179: neighbour-news.com. Hit. domainsbyproxy.com
- 66.104.169.180: medicatechinfo.com. Hit. Network Solutions, LLC. Registrant: Jason Noll.
- 205.178.189.131: securitytrails.com 2009-06-25 - 2009-07-02 Network Solutions, LLC., "ip_count": 726755. Moved to new one 2009-07-02 - 2010-11-03
- 66.104.169.181: brickmanfinancialnews.com. Hit. domainsbyproxy.com
- 66.104.169.182: casanewsnow.com. Hit. domainsbyproxy.com
- 66.104.169.183: aworldofnews.com. No archives. cqcounter.com/whois/www/aworldofnews.com.html blank image
- 66.104.169.184: bcenews.com. Hit.
- 66.104.169.197: teamshula.com. Legit.
66.104.173.186 myworldlymusic.com. XO-AS15 in United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 66.104.173.158 - 66.104.173.194
- 66.104.173.161: fanatic-pc-gamers.com. domainsbyproxy.com. 2013: Welcome to the US Petabox. cqcounter.com/whois/www/fanatic-pc-gamers.com.html somewhat in-style with large "Login to our Members Forum" message and copyright 2005.
- 66.104.173.163: runakonews.com. Hit.
- 66.104.173.164: shoppingadventure.net. Hit.
- 66.104.173.165: entertaining-ly.com. Hit. Network Solutions, LLC for Matthew Sorrell. tools.whoisxmlapi.com/reverse-whois-search hits:
- premier-fishing-tips.com. Legit with photos and mention of Matthew Sorrell: web.archive.org/web/20110129024453/http://www.premier-fishing-tips.com/ Still live as of 2025.
Sincerely,
Matthew Sorrell
Webmaster, Premier-Fishing-Tips.com
- entertaining-ly.com
- 66.104.173.166: zubeenews.com. Hit. domainsbyproxy.com
- 66.104.173.169: smart-financeology.com. Hit. domainsbyproxy.com
- 66.104.173.173: remarkably has two potential hits, both shown in viewdns.info, and one of them was also in the 2013 DNS Census.
- worldfeedstoday.com. Hit. Network Solutions, LLC + Perfect Privacy LLC.
- world-newsfeeds.com. No archives. cqcounter.com/whois/www/world-newsfeeds.com.html blank image.
- 66.104.173.175: media-coverage-now.com. Hit. domainsbyproxy.com
- 66.104.173.176: jbc-online-news.com. Hit. domainsbyproxy.com
- 66.104.173.177: webscooper.com. Hit.
- 66.104.173.178: dk-dcinvestment.com. Hit. domainsbyproxy.com
- 66.104.173.179: newsforthetech.com. Hit. domainsbyproxy.com
- 66.104.173.180: stara-turistick.com. Hit. domainsbyproxy.com
- 66.104.173.181: playbackpolitics.com. Hit. domainsbyproxy.com
- 66.104.173.182: snapnewsfront.net. Hit. domainsbyproxy.com
- 66.104.173.183: ingenuitytrendz.com. Hit. domainsbyproxy.com
- 66.104.173.184: armashoy.com. Hit. domainsbyproxy.com
- 66.104.173.185: baocontact.com. Hit. Godaddy for a "Denise Welch":tools.whoisxmlapi.com/reverse-whois-search has 151 results, some inspections:
"name": "Denise Welch", "organization": null, "street": "Box 288", "city": "Macdona", "state": "Texas", "postalCode": "78054", "country": "UNITED STATES",Reducing a bit searching for Macdona as city gives only 19 hits:- web.archive.org/web/20160610031345/http://socialmediamagazine.biz/ legit Denise Welch, President
- web.archive.org/web/20211126033925/http://allofmywishes.com/ no relevant archives
- web.archive.org/web/20110208070523/pet-a-bration.com no archives
- web.archive.org/web/20111126163259/http://tamilupgraded.com/ 19 Archives broken. cqcounter.com/whois/www/tamilupgraded.com.html off style.
- web.archive.org/web/20080115063123/http://www.zirnitrasports.com/ suspicious but quite broken. Arabic. Split images. Comms not found. cqcounter.com/whois/www/zirnitrasports.com.html in-style. viewdns.info/iphistory/?domain=zirnitrasports.com. Members/register at top linking to web.archive.org/web/20080115220218/http://www.zirnitrasports.com/reg.html
- 216.180.224.58 British Virgin Islands NTHL 2012-01-11. viewdns.info/reverseip/?t=1&host=216.180.224.58 small virtual. Also searched 216.180.224.50 - 216.180.224.65
- dare2wearts.com 2012-06-29 No archives.
- keralaaicuf.com 2012-09-21. No archives.
- kids-ireland.com 2011-11-13 web.archive.org/web/20110128075525/http://kids-ireland.com/ off
- makeupbyjadab.com 2012-11-12. Off
- socalfitnessbootcamp.com 2012-06-29. Off
- unitedwelfareservices.com 2012-11-12. No archives.
- zirnitrasports.com 2012-01-11
- 216.180.224.58 British Virgin Islands NTHL 2012-01-11. viewdns.info/reverseip/?t=1&host=216.180.224.58 small virtual. Also searched 216.180.224.50 - 216.180.224.65
- bontonphoto.com web.archive.org/web/20100605033030/http://www.bontonphoto.com/ suspicious with members linking to web.archive.org/web/20130826142257/https://bonto001.secure.omnis.com/cgi-bin/main.cgi www.omnis.com/ is a hosting service.
- web.archive.org/web/20130528074647/http://bontonphoto.com/ better screenshot has a news link.. cqcounter.com/whois/www/bontonphoto.com.html empty
- olqhchurch.com web.archive.org/web/20110201182208/http://olqhchurch.com/ dead, cqcounter.com/whois/www/olqhchurch.com.html not found
- 66.104.173.186: myworldlymusic.com. Hit.
- 66.104.173.189: hitpoint-gaming.com. Hit. Network Solutions, LLC + perfect privacy.
66.104.175.40 beyondnetworknews.com. XO-AS15 in United States. whois.arin.net/rest/net/NET-66-104-0-0-1/pft?s=66.104.175.40. Net Range:66.104.0.0 - 66.107.255.255. 2012 Internet Census puts most/all hits in this range under ip66-104-175-34.z175-104-66.customer.algx.net,
algx.net redirects to verizon.com as of 2023. Related: superuser.com/questions/956568/why-are-my-pings-going-to-customer-algx-net. Tested viewdns.info range: 66.104.175.24 - unknown- 66.104.175.34: itwebtoday.com. Hit. domainsbyproxy.com
- 66.104.175.35: drglobalnews.com. Hit.
- 66.104.175.36: adilnews.net. Hit.
- 66.104.175.37: technewstogo.com. web.archive.org/web/20110201205946/http://technewstogo.com/ "UNDER CONSTRUCTION" cqcounter.com/whois/www/technewstogo.com.html same.
- 66.104.175.40: beyondnetworknews.com. Hit.
- 66.104.175.41: grubbersworldrugbynews.com. Hit. domainsbyproxy.com
- 66.104.175.42: news-and-sports.com. Hit.
- 66.104.175.44: yourtripfinder.net. Hit. domainsbyproxy.com
- 66.104.175.45: rollinsnetwork.com. Hit. domainsbyproxy.com
- 66.104.175.46: infosharenews.com. Hit.
- 66.104.175.47: southasiaheadlines.com. Hit.
- 66.104.175.48: worlddispatch.net. Hit.
- 66.104.175.49: webworldsports.com. Hit.
- 66.104.175.50: fly-bybirdies.com. Hit.
- 66.104.175.51: businessexchangetoday.com. Hit.
- 66.104.175.52: mensajeradenoticias.com. Hit. domainsbyproxy.com
- 66.104.175.53: info-ology.net. Hit.
- 66.104.175.54: marketflows.net. Hit. domainsbyproxy.com
- 66.104.175.57: metanewsdaily.com. Hit.
- 66.104.175.218: remote.taxconsultantsgroup.com. No archives. cqcounter.com/whois/www/taxconsultantsgroup.com.html commercial so unlikely
66.175.106.148 activegaminginfo.com. UUNET in United States. whois.arin.net/rest/net/NET-66-175-106-128-1/pft?s=66.175.106.148: Net Range: 66.175.106.128 - 66.175.106.159. Customer Name: DIAMOND-COLESON. Tested viewdns.info range: 66.175.106.131 - 66.175.106.178
- 66.175.106.10: nationalchecktrust.com. Legit?
- 66.175.106.134: paddlescoop.com. Hit.
- 66.175.106.137: kessingerssportsnews.com. Hit. Network Solutions: Latimer, Daniel12 hits for name but nothing else looks promissing:
"name": "Latimer, Daniel|ATTN KESSINGERSSPORTSNEWS.COM|care of Network Solutions", "organization": null, "street": "PO Box 459", "city": "PA", "state": "US", "postalCode": "18222", "country": "UNITED STATES",- element42.au
- refugeministryoils.com
- element42.com.au
- refugeloveministry.net
- refugeloveministry.com
- boysofrockingham.com
- daniellatimer.net
- thejourneytoyourheart.com. web.archive.org/web/20130925191623/http://thejourneytoyourheart.com/ empty cqcounter.com/whois/www/thejourneytoyourheart.com.html not found
- latimerstudio.com
- latimerstudios.com
- danlatimer.com
- kessingerssportsnews.com
- 66.175.106.138: factorforcenews.com. Hit. domainsbyproxy.com
- 66.175.106.140: aroundthemiddleeast.com. No Wayback Machine hits. Last resolved: 2012-06-29. cqcounter.com/whois/www/aroundthemiddleeast.com.html not found.
- 66.175.106.142: kanata-news.com. Hit. domainsbyproxy.com
- 66.175.106.143: thecricketfan.com. Hit.
- 66.175.106.146: inews-today.com. Initially found with 2013 DNS Census virtual host cleanup heuristic keyword searches which gave IP address 193.203.49.212. But that has no nearby hits. 66.175.106.146 was later found on viewdns.info, and slotted into this other existing IP range.
- 193.203.49.211 datingso.com: legit? Russian dating website
- 193.203.49.212 inews-today.com. Hit.
- 193.203.49.223 zatysi.net: legit
- 193.203.49.226 kinotopik.com: legit? Russian
- 193.203.49.229 rotor-volgograd.com. Legit.
- 193.203.49.233 ordercytotec.com. Broken. cqcounter.com/whois/www/ordercytotec.com.html not found.
- 66.175.106.147: starwarsweb.net. Hit.
- 66.175.106.148: activegaminginfo.com. Hit. Network Solutions, LLC for Elizabeth Corral. tools.whoisxmlapi.com/reverse-whois-search reverse search "Corral, Elizabeth" only has that hit
- 66.175.106.149: feedsdemexicoyelmundo.com. Hit.
- 66.175.106.150: noticiasmusica.net. Hit. Network Solutions, LLC for Megan See. tools.whoisxmlapi.com/reverse-whois-search only this hit.
- 66.175.106.155: atomworldnews.com. Hit. domainsbyproxy.com
- 66.175.106.158: nouvellesetdesrapports.com. Hit.
- 66.175.106.166: exchange.katzbarron.com. Legit. Reverse IP source: 2012 Internet Census
- 66.175.106.183: mail.lfdatacenter.com. No archives.
66.237.236.247 comunidaddenoticias.com. XO-AS15 in United States. Tested viewdns.info range: 66.237.236.222 - 66.237.236.254
- 66.237.236.227: newsandmusicminute.com. Hit. Network Solutions, LLC for:tools.whoisxmlapi.com/reverse-whois-search search for "Alger, Jennifer" has four domain:
"name": "Alger, Jennifer", "organization": null, "street": "PO Box 459", "city": "Drums", "state": "PA", "postalCode": "18222", "country": "UNITED STATES",but more interestingly this address is the same as other hits: activegameinfo.com and noticiasmusica.net! "PO Box 459" anywhere search has 10k+ domains and so does Drums so not helping.- preparedtoact.com: parked domain girl web.archive.org/web/20130831091701/http://www.preparedtoact.com/
- prepared2act.com
- newsandmusicminute.com
- jennisdish.com web.archive.org/web/20110207105346/http://jennisdish.com/ godaddy
- 66.237.236.229: pearls-playlist.com 2011-11-13. Hit. domainsbyproxy.com
- 66.237.236.230: beyondthefringe.info 2013-01-02. Hit. GoDaddy.com forno hits for that name of reversed.
"registrantContact": { "name": "Nathan Stock", "organization": null, "street": "PO Box 61654", "city": "Savannah", "state": "Georgia", "postalCode": "31420", "country": "UNITED STATES", "email": "nathanstock@earthlink.net", "telephone": "19129206355", - 66.237.236.231: primetimemovies.net 2011-06-22. Hit. No whois records.
- 66.237.236.235: persephneintl.com. Hit. domainsbyproxy.com
- 66.237.236.236: directoalgrano.net 2012-01-23. Hit.
- 66.237.236.240: actualizaciondebeisbol.com. Hit. domainsbyproxy.com
- 66.237.236.243: mygadgettech.com. Hit.
- 66.237.236.247: comunidaddenoticias.com. Hit. domainsbyproxy.com
- 66.237.236.249: sumerjaseahora.com. Hit. domainsbyproxy.com
69.84.156.90 stickshiftnews.com. COLOSPACE in Methuen - United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 69.84.156.64 - 69.84.156.95
- 69.84.156.69: al-ashak-news-me.com. Hit.
- 69.84.156.70: theventurenews.info. Hit.
- 69.84.156.71: worldfinancetoday.net. Hit.
- 69.84.156.72: autonewsarabia.com. Hit.
- 69.84.156.74: blue-moon-news.com. Hit.
- 69.84.156.75: theoutergreen.com. No archives. Might have been another golf hit. cqcounter.com/whois/www/theoutergreen.com.html not found.
- 69.84.156.76: tnc-urdu.com. Hit.
- 69.84.156.79: jassimnews.com. No archives/broken. cqcounter.com/whois/www/jassimnews.com.html blank.
- 69.84.156.80: noticiasdenuestromundo.com. Hit.
- 69.84.156.82: arabicnewsonline.com. Hit.
- 69.84.156.83: unganadormundial.com. Hit.
- 69.84.156.84: focusonbokeh.com. Hit. Network Solutions, LLC.
- 69.84.156.85: classic-rocktopia.com. Hit. domainsbyproxy.com.
- 69.84.156.87: i7diver.com. Hit.
- 69.84.156.88: diariodeelmundo.com. Hit.
- 69.84.156.89: todaysarabnews.com. Hit.
- 69.84.156.90: stickshiftnews.com. Hit.
- 69.84.156.91: theinternationalgoal.com. Hit.
72.34.53.174 technologytodayandtomorrow.com. IHNET in United States. This IP is special. This IP is somehow closely linked to the "Mass Deface III" pastebin as it seems to have been hosted by Condor hosting. They also have many old sites, and links to Russia which is apparently where this was hosted.
- viewdns.info/iphistory/?domain=technologytodayandtomorrow.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-11-13 virtual
- 72.34.53.174 United States IHNET 2011-09-08. Tested viewdns.info range: 72.34.53.164 72.34.53.184 viewdns.info/reverseip/?t=1&host=72.34.53.174 went through all of them;
- hits
- electronictechreviews.com 2011-09-08 domainsbyproxy.com
- recursosdenoticias.com 2012-06-29 domainsbyproxy.com
- todaysnewsandweather-ru.com 2012-01-11 domainsbyproxy.com
- myonlinegamesource.com 2012-01-11 Godaddy:has two domains:
"name": "Brandon Stiltner", "organization": null, "street": "1200 Brookstone Centre Pkwy", "city": "Columbus", "state": "Georgia", "postalCode": "31904", "country": "UNITED STATES",- sandshomerepairs.com. web.archive.org/web/20110207105346/sandshomerepairs.com no archives, cqcounter.com/whois/www/sandshomerepairs.com.html not found
- myonlinegamesource.com
- mytravelopian.com 2011-04-04 domainsbyproxy.com
- possible hits
* intloil.org 2012-04-27. 2011, Possible hit, a bit off style, but possibly because too broken. rss-item. Copyright 2005. Present at pastebin.com/CTXnhjeSp (now lost without archives I'm an idiot). cqcounter.com/whois/www/intloil.org.html from 2011 somewhat in style but interestingly also similarly broken. The "Login" button leads to another domain: "condorsecure.com": web.archive.org/web/20110721052801/https://condorsecure.com/~intloilo/alternativefuels.html which is megaweird and is what is mentioned in the "Mass Deface III" pastebin. domainsbyproxy.com. A similar thing happens in europeantravelcafe.com but to another domain.
* islamicnewsonline.com 2013-03-23. No archives in date range. cqcounter.com/whois/www/islamicnewsonline.com.html not found, sad - not hits
- businesscardprinternyc.info 2012-04-18. Legit web.archive.org/web/20110925172844/http://businesscardprinternyc.info/
- dermozamsoe106.com 2011-07-02
- glialcells2009paris.com 2012-11-12
- hysfreedom.net 2013-07-08. Legit. web.archive.org/web/20111014185727/http://hysfreedom.net/
- integrativetherapiesec.com 2013-06-30. Parked domain girl. cqcounter.com/whois/www/integrativetherapiesec.com.html not found
- larumbaknox.com 2012-01-11. Parked domain girl
- theebizguy.com 2022-12-26 web.archive.org/web/20250000000000*/theebizguy.com many archives
- nofatchics.com 2012-01-11
- bjellaagency.com 2023-03-07
- hits
- securitytrails.com/domain/technologytodayandtomorrow.com/history/a same
74.116.72.236 techtopnews.com. OPTIMUM-WIFI2 in Brooklyn - United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 74.116.72.215 - 74.116.72.254
- 74.116.72.199: newsungraphics.com. Legit.
- 74.116.72.209: newsung.com. Legit/broken. cqcounter.com/whois/www/newsung.com.html not found
- 74.116.72.214: ofinancialinc.com. Legit.
- 74.116.72.219: stockpromoters.com. Legit.
- 74.116.72.227: dayenews.com. Hit.
- 74.116.72.229: guide-daventure.com. Hit.
- 74.116.72.230: spaceage-exchange.com. No archives. cqcounter.com/whois/www/spaceage-exchange.com.html blank image.
- 74.116.72.231: bleachersfootballnews.com. Hit.
- 74.116.72.232: indirectfreekick.com. Hit.
- 74.116.72.233: wwiichronicles.net. Hit.
- 74.116.72.234: petroleumagenews.com. Hit.
- 74.116.72.235: the-open-book-online.com. Hit.
- 74.116.72.236: techtopnews.com. Hit.
- 74.116.72.237: noticiasdiariasdedeportes.com. No archives. Sad, another potential Brazil hit. cqcounter.com/whois/www/noticiasdiariasdedeportes.com.html not found.
- 74.116.72.238: pohandakhbar.com. Hit. domainsbyproxy.com.
- 74.116.72.239: crickettoday.info. Hit.
- 74.116.72.240: zafernews.com. Hit.
- 74.116.72.241: itechnewstoday.com. Hit. domainsbyproxy.com.
- 74.116.72.242: gdgtsource.com. Hit.
- 74.116.72.243: waronfilmonline.com. Hit.
- 74.116.72.244: arborstribune.org. Hit. arborstribune.org. Godaddy without domainsbyproxy.com. Registrant: Ryan Binder, email rkbinder@copper.net Reverse hits for name:
- arborstribune.org
- phaseintl.us
- rblab.us
- bindersynthetics.com
- ryanbinder.com
- finalmarch.com. No archives. cqcounter.com/whois/www/finalmarch.com.html not found.
- finalmarch.info.
- mydrunknews.com. Godaddy parked: web.archive.org/web/20110207181833/http://mydrunknews.com/. cqcounter.com/whois/www/mydrunknews.com.html not found.
- 74.116.72.245: wineenthusiastonline.com. Welcome to the US Petabox. cqcounter.com/whois/www/wineenthusiastonline.com.html not found.
- 74.116.72.246: vuvuzelanews.com. Hit.
- 74.116.72.247: ballbatstumpsandbails.com. Hit.
- 74.116.72.248: kioni-sailing.com. Hit.
- 74.116.72.249: round-trip-travel.com. Hit.
- 74.116.72.250: arabicnewsource.com. Hit.
74.254.12.168 non-stop-news.net. BELLSOUTH-NET-BLK in Atlantic Beach - United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 74.254.12.158 - 74.254.12.195. This domain exceptionally also has a second IP also with multihits: 207.239.196.230. The fact that the range has rdns sources with hits from both 2013 DNS Census and viewdns.info suggests this range is correct.
- 74.254.12.163: half-court.net. Hit.
- 74.254.12.163: dailywellnessnews.com. Hit.
- 74.254.12.165: dylandon.net. Hit. rdns source: viewdns.info.
- 74.254.12.166: afghanpoetry.net. Hit.
- 74.254.12.168: non-stop-news.net. Hit.
- 74.254.12.169: soldiersofsouthasia.com. Hit.
- 74.254.12.170: greek-news.info. Hit.
- 74.254.12.171: autism-news.org. Hit.
- 74.254.12.172: thesportsguidebook.com. rdns source: 2013 DNS Census. Only has archive of one subpage: 2009. English. sports. cqcounter.com/whois/www/thesportsguidebook.com.html not found.
- 74.254.12.173: thefreshnews.com. Hit.
- 74.254.12.174: reliefline.info. web.archive.org/web/20090416064302/http://www.reliefline.info:80/ Archive too broken. cqcounter.com/whois/www/reliefline.info.html broken.
- 74.254.12.176: pakcricketgrd.com. Hit.
- 74.254.12.177: networkofnews.com. Hit.
- 74.254.12.179: wineconnaisseur.net. Hit.
- 74.254.12.180: helpinghandssite.com. Hit.
- 74.254.12.185: newskwest.com. No archives. cqcounter.com/whois/www/newskwest.com.html broken.
- 74.254.12.187: efiinvestment.com. Hit.
- 74.254.12.188: first-tee-golf.com. Hit.
- 74.254.12.189: fabu-foto.com. Hit.
- 74.254.12.190: viptravelabroad.com. Hit.
173.208.81.2 LEASEWEB-USA-CHI in Lombard - United States:
- weblognewsinfo.com:
- dnshistory.org/historical-dns-records/a/weblognewsinfo.com 2010-05-10 -> 2010-10-07 64.120.20.234 viewdns.info/reverseip/?t=1&host=64.120.20.234 small virtual:
- web.archive.org/web/20101229135149/http://knightsofx.net/ off
- marvel-mail.com/ no archives, dawhois.com/site/marvel-mail.com.html no results
- viewdns.info/iphistory/?domain=weblognewsinfo.com
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-09-26 virtual
- 173.208.81.2 Lombard - United States LEASEWEB-USA-CHI 2013-06-30 virtual with newsincirculation.com viewdns.info/reverseip/?t=1&host=173.208.81.2
- dnshistory.org/historical-dns-records/a/weblognewsinfo.com 2010-05-10 -> 2010-10-07 64.120.20.234 viewdns.info/reverseip/?t=1&host=64.120.20.234 small virtual:
- newsincirculation.com
- dnshistory.org/historical-dns-records/a/newsincirculation.com
- 2010-03-10 -> 2010-08-15 64.120.20.234 virtual with weblognewsinfo.com
- 2013-11-26 -> 2013-11-26 70.32.43.226
- viewdns.info/iphistory/?domain=newsincirculation.com
- 70.32.43.226 Lombard - United States LEASEWEB-USA-CHI 2014-01-31
- 50.63.202.77 United States AS-26496-GO-DADDY-COM-LLC 2013-10-19. virutal?
- 70.32.43.226 Lombard - United States LEASEWEB-USA-CHI 2013-09-26 virtual?
- 69.147.228.5 Chicago - United States LEASEWEB-USA-CHI 2012-11-12 unknown. Tested viewdns.info range: 69.147.228.1 69.147.228.15. Nope.
- 173.208.81.2 Lombard - United States LEASEWEB-USA-CHI 2011-04-04 virtual
- dnshistory.org/historical-dns-records/a/newsincirculation.com
199.19.110.7 theworldnewsfeeds.com. Los Angeles - United States FIBER-LOGIC.
- dnshistory.org/historical-dns-records/a/theworldnewsfeeds.com no hits
- viewdns.info/iphistory/?domain=theworldnewsfeeds.com
- 199.19.110.7 2012-01-11 unknown range viewdns.info/reverseip/?t=1&host=199.19.110.7 small virtual:
- Hits
- classymotors.net
- russiansportsworld.com
- urbestbod.com
- Not hits:
- angelesmesapc.org: web.archive.org/web/20110623222054/http://angelesmesapc.org/ seems legit.
- web.archive.org/web/20110701070546/http://www.gralnickandsale.com/ broken
- web.archive.org/web/20110208064143/http://magnoliahousephotography.com/ commercial
- web.archive.org/web/20101229224456/http://rdns13.net/ cgi bin
- Hits
- 74.200.252.212 United States RACKSPACE 2011-11-13 unknown range. viewdns.info/reverseip/?t=1&host=74.200.252.212 small virtual fully explored:
- 199.19.110.7 2012-01-11 unknown range viewdns.info/reverseip/?t=1&host=199.19.110.7 small virtual:
199.85.212.118 just-kidding-news.com. ATT-INTERNET4 in United States.
- 199.85.212.118 rdns source: 2013 DNS Census virtual host cleanup heuristic keyword searches, dnshistory.org (2009-09-23 -> 2011-01-25) and viewdns.info: "location": "United States", "owner": "VIMRO, LLC", "lastseen": "2012-01-11". Tested viewdns.info range: 199.85.212.95 - 199.85.212.128. Not sure worth it given the many 2013 DNS Census misses surrounding.
- 199.85.212.98: colorsxpress.com. Legit
- 199.85.212.104:
- jobindons.com 2013-10-19.
- piogroup.org 2012-12-29.
- 199.85.212.105: mide-news.com. Hit.
- 199.85.212.109: game2be.com. Infinite load loop: web.archive.org/web/20080102074404/http://www.game2be.com/ cqcounter.com/whois/www/game2be.com.html error not found.
- 199.85.212.111:
- newsandsportscentral.com. Hit.
- and many many others, not bothering with it
- 199.85.212.115: veryperi.com. Legit? 2011. Style is similar.
- 199.85.212.116: approselect.com. Legit?
- 199.85.212.117: innovative-software-solutions.com. broken/legit cqcounter.com/whois/www/innovative-software-solutions.com.html broken.
- 199.85.212.118: just-kidding-news.com. Hit.
- 199.85.212.119: invisus.com. Legit
- 199.85.212.120: allurebyjustine.com. Legit?
- 199.85.212.121: stockprouniversity.com cqcounter.com/whois/www/stockprouniversity.com.html legit?
- 199.85.212.122: stjosephswoodshop.com Legit?
- 199.85.212.125: time-spacer.net. Welcome to the US Petabox. cqcounter.com/whois/www/time-spacer.net.html service unavailable
- 199.85.212.132: qualitytrans.net. Legit?
- 199.85.212.134: mywellnessminder.com. Legit?
- 199.85.212.138: crystalglassinc.com
- 199.85.212.140: davistech-llc.com
- 68.178.232.100: see rastadirect.net. rdns source: viewdns.info: "location": "United States", "owner": "GoDaddy.com, LLC", "lastseen": "2012-06-29"
- 209.85.45.84. Tested viewdns.info range: 209.85.45.74 - 209.85.45.94.
- 209.85.45.2: dz8.dailyrazor.com
- 209.85.45.2: jr4consulting.com
- 209.85.45.41: guitarzza.com. No archives of time.
- 209.85.45.46: evergraindecking.com. No archives of time.
- 209.85.45.114: mauritiuspropertyconsultant.com. Legit/ broken.
- 209.85.45.160: bieltvedt.net. No archives of time.
- 209.85.45.160: golfstats.dk. No archives.
- 209.85.45.225: infokus.ca
- 209.85.45.225: mail.tomlatham.net
- 209.85.45.225: mail.tomlatham.org
- 209.85.45.239: flavacationcenter.com
204.176.38.143 noticiassofisticadas.com. UUNET in United States. Found with: 2013 DNS Census virtual host cleanup. Tested viewdns.info range: 204.176.38.125 - 204.176.38.154
- 204.176.38.130: i-pressnews.com. Hit.
- 204.176.38.132: turkishnewslinks.com. Hit.
- 204.176.38.134: photographyarecord.com. Hit.
- 204.176.38.135: breakingthewicket.com. Hit.
- 204.176.38.136: politicalworldtoday.com. Hit.
- 204.176.38.137: hi-tech-today.com. Hit.
- 204.176.38.138: continental-business-news.com. TODO. rss-item, split images. 2011. Cannot find comms. Also header and footer are not limited width which is unusual. Further HTML similarity reversing would be needed.
- 204.176.38.139: bigscreenbattles.com. Hit.
- 204.176.38.141: rakotafootball.com. Hit.
- 204.176.38.142: senderosdemontana.com. Hit.
- 204.176.38.143: noticiassofisticadas.com. Hit.
- 204.176.38.144: techno-today.com. Hit.
- 204.176.38.145: tickettonews.com. Hit.
- 204.176.38.146: dps-digitalphotosharing.com. Hit.
- 204.176.38.147: theputtingreen.com. Hit.
- 204.176.38.149: sportsnewstodayar.com. Hit.
- 204.176.38.150: kairuafricanews.com. Hit.
204.176.39.115 globalprovincesnews.com. UUNET in United States. Tested viewdns.info range: 204.176.39.93 - 204.176.39.124
- 204.176.39.97: beamingnews.com. Hit.
- 204.176.39.98: cubriendonoticias.com. Hit.
- 204.176.39.100: rowleyworldpost.com. Hit.
- 204.176.39.101: noticiastopicas.com. No archives. cqcounter.com/whois/www/noticiastopicas.com.html not found.
- 204.176.39.103: economicnewsbuzz.com. Hit.
- 204.176.39.104: spectranewsonline.com. Hit.
- 204.176.39.105: entertainmentnewscompany.com. Hit.
- 204.176.39.107: guidetoelectronics.net. Uncertain. 2010. English. tech, electronics. Split images, rss-items. Comms not found, likely CGI comms variant on unarchived login page:. web.archive.org/web/20101230025246/http://guidetoelectronics.net/login.html
- 204.176.39.110: arabnewsatdawn.com. Hit.
- 204.176.39.114: messengergalaxy.com. Uncertain. 2011. Would be the first example of something more commercial/service offering we've seen so far. Possible CGI comms variant.
- 204.176.39.115: globalprovincesnews.com. Hit.
- 204.176.39.116: mahparah-news.com. Hit.
- 204.176.39.119: commercialspacedesign.com. Hit.
207.150.191.68 technologypresstoday.com. Saudi Telecom Company JSC in Saudi Arabia.
- technologypresstoday.com. Hit. 2011. JAR. Farsi. RSS, split images.
- viewdns.info/iphistory/?domain=technologypresstoday.com says 72.13.93.206 Santa Clara - United States EGIHOSTING 2012-01-11. viewdns.info/reverseip/?host=72.13.93.206&t=1 says large virtual.
- dnshistory.org/dns-records/technologypresstoday.com says empty
- securitytrails.com/domain/technologypresstoday.com/history/a
- 72.13.93.203 EGIHosting 2009-07-20 (16 years) 2009-07-27 (16 years) 7 days
- 64.13.159.156 Wave Broadband 2009-05-30 (16 years) 2009-07-16 (16 years) 2 months. viewdns.info/reverseip/?t=1&host=64.13.159.156 empty.
- 207.150.191.68 Saudi Telecom Company JSC 2009-01-21 (16 years) 2009-05-22 (16 years) 4 months
- 68.178.232.100 GoDaddy.com, LLC 2009-01-14 (16 years) 2009-01-20 (16 years) 6 days
- worldofonlinenews.com. Hit.
- dnshistory.org/historical-dns-records/a/worldofonlinenews.com 2015-12-15 -> 2016-04-21 108.167.161.90 presumably from the legit era
- viewdns.info/iphistory/?domain=worldofonlinenews.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-07-02 virtual
- 207.150.191.68 Saudi Arabia Saudi Telecom Company JSC 2011-04-04 virtual
- mywebofnews.com. Hit.
- dnshistory.org/historical-dns-records/a/mywebofnews.com 2010-03-09 -> 2010-08-14 207.150.191.68 But this has several hits for the same IP on DNS Census 2013 which is unusual:
viewdns.info/reverseip/?host=207.150.191.68&t=1 is medium virtual:3xhunter.com|2012-04-12T07:53:24|207.150.191.68 dreamersoul.net|2012-04-11T22:06:18|207.150.191.68 exdump.com|2012-02-03T11:42:44|207.150.191.68- world-high.info: cqcounter.com/whois/www/world-high.info.html legit wordpress
- viewdns.info/iphistory/?domain=mywebofnews.com no hits
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-07-27 virtual
- 207.150.191.68 Saudi kkkArabia Saudi Telecom Company JSC 2011-06-22 virtual
- viewdns.info/reverseip/?host=207.150.191.68&t=1
- kickofffootballnews.com. Hit. viewdns.info/iphistory/?domain=kickofffootballnews.com to that IP alone
- ithaiproperty.com. Legit. web.archive.org/web/20111001231548/http://www.ithaiproperty.com/
- themaconnightlife.com: no archives: web.archive.org/web/20250000000000*/themaconnightlife.com. cqcounter.com/whois/www/themaconnightlife.com.html sems legit.
- web.archive.org/web/20110202093639/http://theadvancompany.com/ cgi-bin directory
- web.archive.org/web/20091212001404/http://www.toddlerbedrailshop.com/ off
- cqcounter.com/whois/www/texasdavisfive.com.html off
- web.archive.org/web/20250000000000*/geldherrin-lady-estefania.com no archives.
207.210.250.132 aeronet-news.com. AS17378 in United States. This is the Autonomous System Number for TierPoint, LLC. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 207.210.250.126 - 207.210.250.157
- 207.210.250.131: starrynightnews.com. Hit.
- 207.210.250.132: aeronet-news.com. Hit.
- 207.210.250.133: bakaribulletin.com. Hit.
- 207.210.250.134: deprensaenlarevisiondehoy.com. Hit.
- 207.210.250.135: icwb-news.com. Hit.
- 207.210.250.136: sportsreelhighlights.com. Hit.
- 207.210.250.137: fashionforward.info. No archives. cqcounter.com/whois/www/fashionforward.info.html innovative but has a "Member" section. Stock lady visible somwhere at westlahairgrowth.com/?page_id=12158 according to Google images but I couldn't find it easily in the page.
- 207.210.250.138: inquiry-human-past.com. Hit.
- 207.210.250.139: thefairwaysaregreen.com. Hit.
- 207.210.250.142: russiaupdate.com. Hit.
- 207.210.250.143: archaeologyreview.net. Hit.
- 207.210.250.144: highspeed-news.com. No archives. cqcounter.com/whois/www/highspeed-news.com.html not found.
- 207.210.250.146: noticias-caracas.com. Hit.
- 207.210.250.147: bailandstump.com. Hit.
- 207.210.250.148: classicalmusic4arab.com. Hit.
- 207.210.250.149: globalventurestat.com. Hit.
- 207.210.250.152: al-rashidrealestate.com. Hit.
- 207.210.250.153: newsintheworld-ru.com. Hit.
- 207.210.250.154: news-unlimited.info. Hit.
208.93.112.105 fastnews-online.com. TULIP-SYSTEMS in United States. Checked viewdns.info range: 208.93.112.90 - 208.93.112.155
- 208.93.112.101: cketnews.com: web.archive.org/web/20070612034201/http://cketnews.com/. Archives from 2007 and off style. cqcounter.com/whois/www/cketnews.com.html not found.
- 208.93.112.105: fastnews-online.com. Hit.
- 208.93.112.106: travelxtreme.net. Hit.
- 208.93.112.108: nbanewsroundup.com. Hit.
- 208.93.112.110: luxuryfive.net. Hit.
- 208.93.112.111: topfootballnewsonline.com. Hit.
- 208.93.112.112: todaysportscores.com. Hit.
- 208.93.112.113: mostefficientself.com. Uncertain. cqcounter.com/whois/www/mostefficientself.com.html hard to tell. One is reminded of fightorgohome.com.
- 208.93.112.114: dynamicworldnews.com. Hit.
- 208.93.112.116: gazingvoyage.com. Hit.
- 208.93.112.123: garundipost.com. Hit.
- 208.93.112.125: theradioamateurs.com: no archives. cqcounter.com/whois/www/theradioamateurs.com.html not found.
208.254.38.39 todaysengineering.com. COLO-PREM-VZB in United States.
- Tested viewdns.info range: 208.254.38.9 - 208.254.38.86. Weirdly empty, doesn't even show the domain iteslf!
- 208.254.38.39: todaysengineering.com. Hit. rdns source: both viewdns.info and 2013 DNS Census
- 208.254.38.56: nejadnews.com. Hit.
- 68.178.232.100: source: securitytrails.com. 2009-11-24 - 2009-12-11, GoDaddy.com, LLC
208.254.40.117 worldnewsandent.com. COLO-PREM-VZB in United States. whois.arin.net/rest/net/NET-208-192-0-0-1/pft?s=208.254.40.117: Net Range 208.192.0.0 - 208.255.255.255. Tested viewdns.info range: 208.254.40.92 - 208.254.40.135
- 208.254.40.96: sixty2media.com. Hit.
- 208.254.40.99: newspoliticssource.com. Hit.
- 208.254.40.110 musical-fortune.net. Hit.
- 208.254.40.113: ashoka-gemstones.com. Hit.
- 208.254.40.117: worldnewsandent.com. Hit.
- 208.254.40.124: riskandrewardnews.com. Hit.
- 208.254.40.129: mailb.casella.com. Legit.
208.254.42.205 driversinternationalgolf.com. COLO-PREM-VZB in United States. Tested viewdns.info range: 208.254.42.178 - 208.254.42.233.
- 208.254.42.35: mystorytimefriends.com. Broken/legit.
- 208.254.42.194: it-proonline.com. Hit.
- 208.254.42.200: riccs.mwcog.org. Legit. Reverse IP source: 2012 Internet Census, 2012-05-14.
- 208.254.42.205: driversinternationalgolf.com. Hit.
- 208.254.42.209: mardelsurnoticias.com. Hit. Reverse IP source: viewdns.info
- 208.254.42.215: nowfreshfinances.com. Hit.
- 208.254.42.216: circulatingnews.net. Hit.
- 208.254.42.219: westingtonpassnews.com. Hit. Reverse IP source: 2013 DNS Census
- 208.254.44.155: brandimpact.com. Legit/broken: web.archive.org/web/20070801000000*/brandimpact.com
- 208.254.45.105: operatorenum.com. Legit/broken: web.archive.org/web/20100301000000*/operatorenum.com
209.162.192.49 rastadirect.net. DF-PTL2-3 in Gresham - United States. Source: securitytrails.com and cqcounter.com/site/rastadirect.net.html. Tested viewdns.info: 209.162.192.30 209.162.192.70
* 209.162.192.44: thejewelofsouthamerica.com. Hit.
* 209.162.192.49: rastadirect.net. Hit.
* 209.162.192.51: yellow-chair-report.com. Hit.
* 209.162.192.54: tutkulu-turu.com. Possible hit. domainsbyproxy.com 2008-03-04. Weird style made up exclusively of cut up images, including the text itself where links would normally be. Turkish. Archive a bit weird with images on top of text. 2011 Copyright 2006. Unarchived link to web.archive.org/web/20110129065840/http://tutkulu-turu.com/login.html with title "Kullanıcı adı" (Username). Headline "Online seyahat etmek acenta" translates to "Online travel agency".
* 209.162.192.57: globalnewsreports.net. Hit.
* 209.162.192.59: easytravelsite.net. Hit.
* 209.162.192.70: phrio.com. Off date. viewdns.info/reverseip/?t=1&host=209.162.192.70
* 209.162.192.44: thejewelofsouthamerica.com. Hit.
* 209.162.192.49: rastadirect.net. Hit.
* 209.162.192.51: yellow-chair-report.com. Hit.
* 209.162.192.54: tutkulu-turu.com. Possible hit. domainsbyproxy.com 2008-03-04. Weird style made up exclusively of cut up images, including the text itself where links would normally be. Turkish. Archive a bit weird with images on top of text. 2011 Copyright 2006. Unarchived link to web.archive.org/web/20110129065840/http://tutkulu-turu.com/login.html with title "Kullanıcı adı" (Username). Headline "Online seyahat etmek acenta" translates to "Online travel agency".
* 209.162.192.57: globalnewsreports.net. Hit.
* 209.162.192.59: easytravelsite.net. Hit.
* 209.162.192.70: phrio.com. Off date. viewdns.info/reverseip/?t=1&host=209.162.192.70
- 68.178.232.100 - United States - GoDaddy.com - 2011-05-02. Reverse IP source: viewdns.infoThere are actualy talk pages about this IP
- +-20 range: several domains on each IP, but can't find any hits easily
210.80.75.55 philippinenewsonline.net. UUNET in Australia. Tested viewdns.info range: 210.80.75.30 - 210.80.75.67
- 210.80.75.35: aroundtheworldnews.net. No archives. ipinf.ru/domains/210.80.75.33/ disagrees and places it at .33.
- 210.80.75.36: e-commodities.net. Hit.
- 210.80.75.37: trekkingtoday.com. Hit.
- 210.80.75.41: multinews-33.com. Hit.
- 210.80.75.42: movimientodenticias.com. No archives. cqcounter.com/whois/www/movimientodenticias.com.html blank.
- 210.80.75.43: gulfandmiddleeastnews.com. Hit.
- 210.80.75.44: whirlybirdinflight.com. Hit.
- 210.80.75.45: kings-game.net. Hit.
- 210.80.75.46: topglobalnewsdaily.com. Hit.
- 210.80.75.49: recipe-dujour.com. Hit.
- 210.80.75.53: sportsman-elite.com. Hit.
- 210.80.75.55: philippinenewsonline.net. Hit.
- 210.80.75.56: technewsforme.com. Hit.
- 210.80.75.59: goldeportesnoticias.com. Hit.
- 210.80.75.68: gigabyte-usa.com. Legit.
212.4.16.232 mynewscheck.com. UUNET in Cassano d'Adda - Italy. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 212.4.16.214 - 212.4.17.198. ipinf.ru/domains/?search=212.4.17.125&cust=1 says they are /19, so .16 and .17 are both the same range from a registration perspective::
- 212.4.16.224: lanoticiasdehoyelinforme.com. Hit.
- 212.4.16.232: mynewscheck.com. Hit.
- 212.4.16.239: saktimarsgolf.com 2012-06-29. Broken/legit/no archives of relevant date: web.archive.org/web/20081031060207/http://saktimarsgolf.com/. cqcounter.com/whois/www/saktimarsgolf.com.html blank.
- 212.4.16.245: financial-crisis-news.com. Hit.
- 212.4.16.252: minutosdenoticias.com. Hit. web.archive.org/web/20100517151612/http://minutosdenoticias.com/
212.4.17.38 fightwithoutrules.com. UUNET in Cassano d'Adda - Italy. whois.arin.net/rest/net/NET-208-192-0-0-1/pft?s=208.254.40.117. Net Range: 208.192.0.0 - 208.255.255.255. Organization: Name: Verizon Business. Tested viewdns.info range: see 212.4.16.* aboveThere were also some other reverse IP hits for fightwithoutrules.com, but no CIA websites there:
- 212.4.17.38: fightwithoutrules.com. Hit.
- 212.4.17.41: newtechfrontier.com. Hit.
- 212.4.17.43: smart-travel-consultant.com. Hit.
- 212.4.17.46: atentlaloc.com. Hit.
- 212.4.17.53: newsresolution.net. Hit.
- 212.4.17.56: lesummumdelafinance.com. Hit.
- 212.4.17.56: thepinnacleoffinance.com. No Wayback machine archives. cqcounter.com/whois/www/thepinnacleoffinance.com.html blank.
- 212.4.17.61: tech-stop.org. Archive: 2011. Feels likely. No commons found. .org hit? Has subdomain "gear.tech-stop.org" according to 2013 DNS Census, which suggests CGI comms, but no links to it
- 212.4.17.98: topbillingsite.com. Hit.
- 212.4.17.122: b2bworldglobal.com. Hit.
- 212.4.17.125: worldaroundyunnan.com. Hit.
- 212.4.17.160: localtoglobalnews.com. Hit.
Other hits:
- 208.91.197.132. rdns source: viewdns.info: "location" : "British Virgin Islands", "owner" : "Confluence Networks Inc", "lastseen" : "2013-09-26". So this is after the previous one, unlikely to be correct.
- 205.178.189.131. source: securitytrails.com
212.4.18.129 sightseeingnews.com. UUNET in Cassano d'Adda - Italy. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 212.4.18.115 - 212.4.18.148. TODO expand. Interesting wide/sparse range? Or perhaps it's two separate ranges?
212.209.74.105 globalbaseballnews.com. UUNET in Sweden. Tested viewdns.info range: 212.209.74.100 - 212.209.74.132. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches
- 212.209.74.105: globalbaseballnews.com. Hit.
- 212.209.74.106: football-de-luxe.com. Hit.
- 212.209.74.111: worldconcerns.info. No archives. cqcounter.com/whois/www/worldconcerns.info.html empty.
- 212.209.74.112: developmental-league.com. Unclear. CGI comms variant? 2010. English. CGI. American football.
- 212.209.74.115: mediocampodefutbol.com. Hit.
- 212.209.74.117: myengineeringaffinity.com. Hit.
- 212.209.74.122: atthemovies.biz. Hit.
- 212.209.74.123: worldfinancialexchangenews.com. Hit.
- 212.209.74.124: urouttahere.com. Hit.
- 212.209.74.125: avoilurefixe.com. Hit. Domains By Proxy, LLC.[ref]
- 212.209.74.126: headlines2day.com. Hit.
- 118.139.174.11. Reverse IP source: viewdns.info
- 118.139.174.11: 712 domain hits on it
- 118.139.174.21: theargentineanwineco.com 2013-09-26. No Wayback machine archive. cqcounter.com/whois/www/theargentineanwineco.com.html not found.
- nothing else on the +-20 range
- 184.168.221.91. Reverse IP source: 2013 DNS Census
- 184.168.221.91: 40k hits on 2013 DNS Census
- 118.139.174.11. Reverse IP source: viewdns.info
- 212.209.74.127: construction-zones.com. Unclear. CGI comms variant? 2009. No known comms found. English. construction. Has a login page: web.archive.org/web/20091130144158/http://construction-zones.com/login.html so maybe CGI comms variant
212.209.79.40 hydradraco.com. UUNET in Sweden. Found with: visual inspection of full 2013 DNS Census virtual host cleanup list just after globalbaseballnews.com. Tested viewdns.info range: 212.209.79.35 - 212.209.79.63
- 212.209.79.34: fgnl.net. Hit. securitytrails.com provides IP history:both under MCI Communications Services, Inc. d/b/a Verizon Business.
- 212.209.79.37: fitness-sources.com. Hit.
- 212.209.79.40: hydradraco.com. Hit.
- 212.209.79.41: noticiasdelmundolatino.com. Hit.
- 212.209.79.42: suparakuvi.com. Hit.
- 212.209.79.44: myigadgets.net. Unclear. 2010. tech. Contains some helpers to: iGoogle. This page is very interesting. and quite different from the others, as it contains highly specialized functionality. No known comms found. The choice of homepage languages is also very suspicious: Arabic, Farsi, French, Chinese and Spanish.
- 212.209.79.46: cetusdelph.com. Hit.
- 212.209.79.47: willtoworship.com. Hit. domainsbyproxy.com
- 212.209.79.48: themvconnection.com. Hit.
- 212.209.79.51: pi-resources.net. Hit.
- 212.209.79.52: newel-adserver.com. Redirects to newel.com which is legit. cqcounter.com/whois/www/newel-adserver.com.html blank.
- 212.209.79.53: ourscubaworld.com. Hit.
- 212.209.79.58: tech-love-home.com. Hit.
- 212.209.79.60: first-solo-aviation.com. Hit.
- 212.209.79.61: china-destinations.org. Hit.
212.209.90.84 thenewseditor.com. UUNET in Sweden. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 212.209.90.64 - 212.209.90.99
- 212.209.90.69: worldedgenews.com. Hit.
- 212.209.90.72: talkingpointnews.info. Hit.
- 212.209.90.74: globalinvestmentnews.net. Hit.
- 212.209.90.75: prebitinvestment.com. Hit.
- 212.209.90.77: energy-bulb.com 2011. English. energy. Comms not found, but has unarchived link to: web.archive.org/web/20110128182345/https://webmail.energy-bulb.com/login.html. CGI comms variant?
- 212.209.90.79: freeblink.com. No archives for timerange, then legit. cqcounter.com/whois/www/freeblink.com.html off-style
- 212.209.90.80: nsmovies.net. Hit.
- 212.209.90.82: middleeastjournal.net. Hit.
- 212.209.90.84: thenewseditor.com. Hit.
- 212.209.90.87: newsandweathersource.com. Hit.
- 212.209.90.89: pakisports.com. Hit.
- 212.209.90.90: vriha-aesthetics.com. Hit.
- 212.209.90.92: amishkanews.com. Hit.
- 212.209.90.93: theentertainbiz.com. Hit.
- 212.209.90.94: eurosportssummary.com. Hit.
- 212.209.91.14: teracom.net. Legit
216.93.248.194 esmundonoticias.com. TWDX in Chelmsford - United States.
- dnshistory.org/historical-dns-records/a/esmundonoticias.com 2010-02-05 -> 2010-08-02 216.93.248.194. Tested viewdns.info range: 216.93.248.184 216.93.248.204. viewdns.info/reverseip/?host=216.93.248.194&t=1 gives:
- hits:
- esmundonoticias.com 2012-01-11
- kukrinews.com 2011-06-22
- dnshistory.org/historical-dns-records/a/kukrinews.com 2010-02-26 -> 2010-08-07 216.93.248.194
- viewdns.info/iphistory/?domain=kukrinews.com 216.93.248.194 Malden - United States TWDX 2011-06-22
- lasthournews.com 2010-02-27 -> 2010-08-07
- tech-geek-news.com 2012-01-11
- not hits;
- 216.93.248.194: coxsackielive.com 2012-06-29. No archives. dawhois.com/www/coxsackielive.com.html off.
- 216.93.248.194: datapakassociates.org 2012-04-27. No rachives. dawhois.com/www/datapakassociates.org.html off.
- 216.93.248.194: easywebworld.net 2012-02-27. Broken: web.archive.org/web/20101229051406/http://easywebworld.net/ "This Site Is Under Construction. Come Back Soon!" so seems legit. dawhois.com/www/easywebworld.net.html same.
- 216.93.248.194: librarianhelper.com 2013-06-30. Parked domain girl. dawhois.com/www/librarianhelper.com.html not found.
- 216.93.248.194: ualbanycornerstone.org 2012-04-13. Legit.
- hits:
- viewdns.info/iphistory/?domain=esmundonoticias.com 216.93.248.194 Malden - United States TWDX 2012-01-11. Tested. viewdns.info/reverseip/?t=1&host=216.93.248.194 small virtual.
216.104.38.114 all-sport-headlines.com. SINGLEHOP-LLC in United States.
- viewdns.info/iphistory/?domain=all-sport-headlines.com
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-11-12 virtual
- 216.104.38.114 United States SINGLEHOP-LLC 2012-09-21. Tested viewdns.info range: 216.104.38.104 216.104.38.124
- viewdns.info/reverseip/?t=1&host=216.104.38.114
- hits:
* wahidfutbol.com
* wildbirds-seasia.com - not hits:
- web.archive.org/web/0/oaksathighlandlakes.com no archives
- web.archive.org/web/20110208080756/http://www.weathersbyhoa.com/cgi-bin/index.pl?action=main
- web.archive.org/web/20110202205540/http://www.themeadowssubdivisionhoa.com/cgi-bin/index.pl?action=main
- web.archive.org/web/20110208074306/http://bsheroics.com/ humm off there is a chance. They have actual twitter: x.com/bsheroics nevermind. And: www.facebook.com/profile.php?id=100078200499209
- afterawhilecrocodile.info 2011-07-26. Legit.
- hits:
- viewdns.info/reverseip/?t=1&host=216.104.38.114
- securitytrails.com/domain/all-sport-headlines.com/history/a adds
- 66.246.218.219 Cologix, Inc 2008-09-01 (17 years) 2008-11-25 (16 years) 3 months. viewdns.info/reverseip/?t=1&host=66.246.218.219 empty.
216.105.98.152: modernarabicnews.com. SAVVY-NET in United States. Found with: 2013 DNS Census virtual host cleanup heuristic keyword searches. Tested viewdns.info range: 216.105.98.125 - 216.105.98.167
- 216.105.98.118:
- estudashboard.com: broken cqcounter.com/whois/www/estudashboard.com.html not found
- fintrade.us: legit
- 216.105.98.132: europeantravelcafe.com. Hit.
- 216.105.98.134: fuenteneta.com. Hit.
- 216.105.98.135: ilat-news.com. Hit.
- 216.105.98.136: etherealinspirations.net. Hit.
- 216.105.98.137: the-news-zone.com. Hit.
- 216.105.98.138: photozoomnews.com. No archives. cqcounter.com/whois/www/photozoomnews.com.html empty
- 216.105.98.139: cultura-digital.net. Hit.
- 216.105.98.140: uaeshoppingspree.com. Hit.
- 216.105.98.141: jabarifootball.com. No archives. "Jabari" is a Swahili/Arabic name[ref]. cqcounter.com/whois/www/jabarifootball.com.html not found.
- 216.105.98.142: globalreview-ar.com. No archives. Shame, could have been our first Argentinian site. cqcounter.com/whois/www/globalreview-ar.com.html empty.
- 216.105.98.144: garanziadellasicurezza.com. Hit.
- 216.105.98.145: montanismoaventura.com. Hit.
- 216.105.98.146: large-format-news.com. Hit.
- 216.105.98.147: nepalnewsbrief.com. Hit. dnshistory.org marks it as having IP 2010-03-10 -> 2010-08-15 216.169.148.94 [ref]. This range does feel a bit different from the others, too many broken archives, and relatively early ones too. Explored viewdns.info range: 216.169.148.84 - 216.169.148.104, empty for period. domainsbyproxy.com.
- 216.105.98.148: teclafinance.com. Hit.
- 216.105.98.149: entreman.com. Hit.
- 216.105.98.152: modernarabicnews.com. Hit.
- 216.105.98.153: global-headlines.com. Hit.
- 216.105.98.154: everythingcricket.org. Hit.
- 216.105.98.156: familyhealthonline.net. Hit.
- 216.105.98.157: delacorne.com. Hit.
- 216.105.98.158: econfutures.com. Hit.
- 216.105.98.161: kstcloud.com. No archives. cqcounter.com/whois/www/kstcloud.com.html not found
219.90.61.123 journeystravelled.com. UUNET in Taiwan. Tested viewdns.info range: 219.90.61.100 - 219.90.61.133
- 219.90.61.100: pressstory.com: "Under construction". web.archive.org/web/20110128124548/http://pressstory.com/. cqcounter.com/whois/www/pressstory.com.html same
- 219.90.61.103: bet2plays.com. "Under construction". Unlikely thematic, too spicy. cqcounter.com/whois/www/bet2plays.com.html same
- 219.90.61.110: surya-brahma.com. Hit
- 219.90.61.111: classicalmusicboxonline.com. Hit.
- 219.90.61.116: athletepro.net. Hit.
- 219.90.61.117: lajornadanow.com. Hit.
- 219.90.61.119: aviation-navigation.com. Hit.
- 219.90.61.120: theinternationalworld.com. Hit.
- 219.90.61.121: thepyramidnews.com. Hit.
- 219.90.61.122: iran-newslink-today.com. Hit.
- 219.90.61.123: journeystravelled.com. Hit.
219.90.62.243 fitness-dawg.com. UUNET in Taiwan. whois.arin.net/rest/net/NET-219-0-0-0-1/pft?s=219.90.62.243. Net Type: Allocated to APNIC. Tested viewdns.info range: unknown - 219.90.62.255
- 219.90.62.173:
- dominatingduos.com: 2013-08-12T17:53:09. No archive. cqcounter.com/whois/www/dominatingduos.com.html empty
- has other domains
- 219.90.62.193: centralnewsreleasers.com. Only a 2018 of the robots.txt: web.archive.org/web/*/http://centralnewsreleasers.com/* so likely not a hit. cqcounter.com/whois/www/centralnewsreleasers.com.html not found.
- 219.90.62.209: penniesbythemillions.com. No archives. cqcounter.com/whois/www/penniesbythemillions.com.html not found.
- 219.90.62.229: information-junky.com. Hit.
- 219.90.62.231: todosperuahora.com. Hit.
- 219.90.62.232: race26point2.com. Hit. No archives, but has subdomain: secure.race26point2.com, so likely CGI comms. cqcounter.com/whois/www/race26point2.com.html somewaht in-style and also a "members" link, presumably linking to secure.race26point2.com. The "26" and "2" are not very clear, but tagline clarifies "leading the race on the latest running news and events" so it's a running news website
- 219.90.62.233: theworld-news.net. Hit.
- 219.90.62.234: recuerdosdeviajeonline.com. Hit
- 219.90.62.235: ordenpolicial.com. Hit.
- 219.90.62.240: cityworldnewsnow.com. Hit. No archives but has subdomain: secure.cityworldnewsnow.com so likely CGI comms. cqcounter.com/whois/www/cityworldnewsnow.com.html in-style, arab world mentions.
- 219.90.62.237: elcorreodenoticias.com. Hit.
- 219.90.62.238: freshtechonline.com. Hit.
- 219.90.62.240: cityworldnewsnow.com. Hit.
- 219.90.62.241: newscentertoday.com. Hit.
- 219.90.62.242: ride-captain.com. Hit.
- 219.90.62.244: easytraveleurope.com. Hit.
- 219.90.62.245: world-news-now.net. Hit.
- 219.90.62.246: negativeaperture.com. Hit.
- 219.90.62.247: conquermstoday.com. Hit
- 219.90.62.249: forensic-exchange.com. 2013 archive: web.archive.org/web/20130714094026/http://forensic-exchange.com/. Appears to be a buggy Wayback Machine archive somehow, so inconclusive. cqcounter.com/whois/www/forensic-exchange.com.html in-style, clarifies focus on computer.
It is because there was nothing there, or just because we don't have a good enough reverse IP database?
It is possible that DomainTools could help with a more complete database, but its access is extremely expensive and out of reach at the moment.
Putting 140 USD into WhoisXMLAPI to get all whois histories of interest for possible reverse searches would also be of interest.
It can't be HTML crawl because presumably there wouldn't have been links to those websites? Presumably this is why Common Crawl doesn't seem to have any hits.
The same question also applies to the 2013 DNS Census. It has less hits, but still has many.
Whatever they did, we are so so glad that they did!
.com and .net are very dominant. Here we list other choices made:
.info: has a few hits:Did a full Wayback Machine CDX scanning on .info after:That makes about 10k domains, so it's about the right size.grep -e news -e noticias -e nouvelles -e world -e global.org: has a least one hit, see: Are there .org hits?.biz:- unarchived comms:
- atthemovies.biz
- unarchived comms:
Previously it was unclear if there were any .org hits, until we found the first one with clear comms: web.archive.org/web/20110624203548/http://awfaoi.org/hand.jar
Later on, two more clear ones were found with expired domain trackers:further settling their existence. Later on newimages.org also came to light.
Others that had been previously found in IP ranges but without clear comms:
.org is very rare, and has been excluded from some of our search heuristics. That was a shame, but likely not much was missed.
This is a dark art, and many of the sources are shady as fuck! We often have no idea of their methodology. Also no source is fully complete. We just piece up as best we can.
- www.zone-h.org/archive/ip=208.76.80.93/page=11?hz=1 mentions
newsupdatesite.comand mentions "defacement", the "Mass Deface III" pastebin comes to mind. No other nearby hits on quick inspection.
This is our primary data source, the first article that pointed out a few specific CIA websites which then served as the basis for all of our research.
We take the truth of this article as an axiom. And then all we claim is that all other websites found were made by the same people due to strong shared design principles of the such websites.
D'oh.
But to be serious. The Wayback Machine contains a very large proportion of all sites. It does happen sometime that a Wayback Machine archive is missing or broken and cqcounter has the screenshot. But the Wayback Machine is still the most complete database we have found so far. Some archives are very broken. But those are rare.
The only problem with the Wayback Machine is that there is no known efficient way to query its archives across domains. You have to have a domain in hand for CDX queries: Wayback Machine CDX scanning.
The Common Crawl project attempts in part to address this lack of querriability, but we haven't managed to extract any hits from it.
CDX + 2013 DNS Census + heuristics however has been fruitful however.
We have dumped all Wayback Machine archives of known websites to: github.com/cirosantilli/cia-2010-websites-dump using ../cia-2010-covert-communication-websites/download-websites.sh. This allows for better grepping and serves as a backup in case they ever go down.
The Wayback Machine has an endpoint to query cralwed pages called the CDX server. It is documented at: github.com/internetarchive/wayback/blob/master/wayback-cdx-server/README.md.
This allows to filter down 10 thousands of possible domains in a few hours. But 100s of thousands would be too much. This is because you have to query exactly one URL at a time, and they possibly rate limit IPs. But no IP blacklisting so far after several hours, so it's not that bad.
Once you have a heuristic to narrow down some domains, you can use this helper: ../cia-2010-covert-communication-websites/cdx.sh to drill them down from 10s of thousands down to hundreds or thousands.
We then post process the results of cdx.sh with ../cia-2010-covert-communication-websites/cdx-post.sh to drill them down from from thousands to dozens, and manually inspect everything.
From then on, you can just manually inspect for hist on your browser.
Dire times require dire methods: ../cia-2010-covert-communication-websites/cdx-tor.sh.
First we must start the tor servers with the and then use it on a newline separated domain name list to check;This creates a directory
tor-army command from: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983tor-army 100./cdx-tor.sh infile.txtinfile.txt.cdx/ containing:infile.txt.cdx/out00,out01, etc.: the suspected CDX lines from domains from each tor instance based on the simple criteria that the CDX can handle directly. We split the input domains into 100 piles, and give one selected pile per tor instance.infile.txt.cdx/out: the final combined CDX output ofout00,out01, ...infile.txt.cdx/out.post: the final output containing only domain names that match further CLI criteria that cannot be easily encoded on the CDX query. This is the cleanest domain name list you should look into at the end basically.
Since archive is so abysmal in its data access, e.g. a Google BigQuery would solve our issues in seconds, we have to come up with creative ways of getting around their IP throttling.
Distilled into an answer at: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983
This should allow a full sweep of the 4.5M records in 2013 DNS Census virtual host cleanup in a reasonable amount of time. After JAR/SWF/CGI filtering we obtained 5.8k domains, so a reduction factor of about 1 million with likely very few losses. Not bad.
5.8k is still a bit annoying to fully go over however, so we can also try to count CDX hits to the domains and remove anything with too many hits, since the CIA websites basically have very few archives:This gives us something like:sorted by increasing hit counts, so we can go down as far as patience allows for!
cd 2013-dns-census-a-novirt-domains.txt.cdx
./cdx-tor.sh -d out.post domain-list.txt
cd out.post.cdx
cut -d' ' -f1 out | uniq -c | sort -k1 -n | awk 'match($2, /([^,]+),([^)]+)/, a) {printf("%s.%s %d\n", a[2], a[1], $1)}' > out.count12654montana.com 1
aeronet-news.com 1
atohms.com 1
av3net.com 1
beechstreetas400.com 1New results from a full CDX scan of 2013-dns-census-a-novirt.csv:
- 219.90.61.123 journeystravelled.com
JAR, SWF and CGI-bin scanning by path only is fine, since there are relatively few of those. But .js scanning by path only is too broad.
One option would be to filter out by size, an information that is contained on the CDX. Let's check typical ones:Ignoring some obvious unrelated non-comms files visually we get a range of about 2732 to 3632:This ignores the obviously atypical JavaScript with SHAs from iranfootballsource, and the particularly small old menu.js from cutabovenews.com, which we embed into ../cia-2010-covert-communication-websites/cdx-post-js.sh.
grep -f <(jq -r '.[]|select(select(.comms)|.comms|test("\\.js"))|.host' ../media/cia-2010-covert-communication-websites/hits.json) out | out.jshits.cdx
sort -n -k7 out.jshits.cdxnet,hollywoodscreen)/current.js 20110106082232 http://hollywoodscreen.net/current.js text/javascript 200 XY5NHVW7UMFS3WSKPXLOQ5DJA34POXMV 2732
com,amishkanews)/amishkanewss.js 20110208032713 http://amishkanews.com/amishkanewss.js text/javascript 200 S5ZWJ53JFSLUSJVXBBA3NBJXNYLNCI4E 3632The size helps a bit, but it's not insanely good unfortunately, only about 3x, these are some common JS sizes right there!
Many hits appear to happen on the same days, and per-day data does exist: archive.org/details/widecrawl but apparently cannot be publicly downloaded unfortunately. But maybe there's another way? TODO select candidates.
Their historic DNS and reverse DNS info was very valuable, and served as Ciro's the initial entry point to finding hits in the IP ranges given by Reuters.
Generic information about the website not specific on this project will be stored at: Section "viewdns.info".
Since this source is so scarce and valuable, we have been quite careful to note down all the domain and IP ranges that have been explored.
At news.ycombinator.com/item?id=38496244, the creator of the viewdns.info, "Hughesey", also stated that he'd able to give some free credits for public research projects such as this one. This would have saved up going to quite a few Cafes to get those sweet extra IPs! But it was more fun in hardmode, no doubt.
We do API access to IP ranges with this simple helper: ../cia-2010-covert-communication-websites/viewdns-info.sh, usage:e.g.:
./viewdns-info.sh <apikey> <start-ipv-address> <end-ipv-address>./viewdns-info.sh 8b890b00b17ed2d66bbed878d51200b58d43d014 66.45.179.187 66.45.179.210For domain to IP queries from the API you should use "iphistory" viewdns.info/api/docs/ip-history.php:
curl 'https://api.viewdns.info/iphistory/?domain=todaysengineering.com&apikey=$APIKEY&output=json'Just beware of the viewdns.info reverse IP bug, that really sucks and led to us missing a ton of domains.
DomainTools might contain one of the most complete historic revese DNA databases in existence, possibly via their 2021 acquisition of Farsight DNSDB, but we were unable to verify it because it is incredibly expensive: DomainTools historical reverse IP
Main article: DNS Census 2013.
This data source was very valuable, and led to many hits, and to finding the first non Reuters ranges with Section "secure subdomain search on 2013 DNS Census".
Hit overlap:Domain hit count when we were at 279 hits: 142 hits, so about half of the hits were present.
jq -r '.[].host' ../media/cia-2010-covert-communication-websites/hits.json ) | xargs -I{} sqlite3 aiddcu.sqlite "select * from t where d = '{}'"The timing of the database is perfect for this project, it is as if the CIA had planted it themselves!
We've noticed that often when there is a hit range:and that this does not seem to be that common. Let's see if that is a reasonable fingerprint or not.
- there is only one IP for each domain
- there is a range of about 20-30 of those
Note that although this is the most common case, we have found multiple hits that viewdns.info maps to the same IP.
First we create a table The
u (unique) that only have domains which are the only domain for an IP, let's see by how much that lowers the 191 M total unique domains:time sqlite3 u.sqlite 'create table t (d text, i text)'
time sqlite3 av.sqlite -cmd "attach 'u.sqlite' as u" "insert into u.t select min(d) as d, min(i) as i from t where d not like '%.%.%' group by i having count(distinct d) = 1"not like '%.%.%' removes subdomains from the counts so that CGI comms are still included, and distinct in count(distinct is because we have multiple entries at different timestamps for some of the hits.Let's start with the 208 subset to see how it goes:OK, after we fixed bugs with the above we are down to 4 million lines with unique domain/IP pairs and which contains all of the original hits! Almost certainly more are to be found!
time sqlite3 av.sqlite -cmd "attach 'u.sqlite' as u" "insert into u.t select min(d) as d, min(i) as i from t where i glob '208.*' and d not like '%.%.%' and (d like '%.com' or d like '%.net') group by i having count(distinct d) = 1"This data is so valuable that we've decided to upload it to: archive.org/details/2013-dns-census-a-novirt.csv Format:The numbers of the first column are the IPs as a 32-bit integer representation, which is more useful to search for ranges in.
8,chrisjmcgregor.com
11,80end.com
28,fine5.net
38,bestarabictv.com
49,xy005.com
50,cmsasoccer.com
80,museemontpellier.net
100,newtiger.com
108,lps-promptservice.com
111,bridesmaiddressesshow.comTo make a histogram with the distribution of the single hostname IPs:Which gives the following useless noise, there is basically no pattern:
#!/usr/bin/env bash
bin=$((2**24))
sqlite3 2013-dns-census-a-novirt.sqlite -cmd '.mode csv' >2013-dns-census-a-novirt-hist.csv <<EOF
select i, sum(cnt) from (
select floor(i/${bin}) as i,
count(*) as cnt
from t
group by 1
union
select *, 0 as cnt from generate_series(0, 255)
)
group by i
EOF
gnuplot \
-e 'set terminal svg size 1200, 800' \
-e 'set output "2013-dns-census-a-novirt-hist.svg"' \
-e 'set datafile separator ","' \
-e 'set tics scale 0' \
-e 'unset key' \
-e 'set xrange[0:255]' \
-e 'set title "Counts of IPs with a single hostname"' \
-e 'set xlabel "IPv4 first byte"' \
-e 'set ylabel "count"' \
-e 'plot "2013-dns-census-a-novirt-hist.csv" using 1:2:1 with labels' \
;There are two keywords that are killers: "news" and "world" and their translations or closely related words. Everything else is hard. So a good start is:
grep -e news -e noticias -e nouvelles -e world -e globaliran + football:
- iranfootballsource.com: the third hit for this area after the two given by Reuters! Epic.
3 easy hits with "noticias" (news in Portuguese or Spanish"), uncovering two brand new ip ranges:
- 66.45.179.205 noticiasporjanua.com
- 66.237.236.247 comunidaddenoticias.com
- 204.176.38.143 noticiassofisticadas.com
Let's see some French "nouvelles/actualites" for those tumultuous Maghrebis:
- 216.97.231.56 nouvelles-d-aujourdhuis.com
news + global:
- 204.176.39.115 globalprovincesnews.com
- 212.209.74.105 globalbaseballnews.com
- 212.209.79.40: hydradraco.com
OK, I've decided to do a complete Wayback Machine CDX scanning of
news... Searching for .JAR or https.*cgi-bin.*\.cgi are killers, particularly the .jar hits, here's what came out:- 62.22.60.49 telecom-headlines.com
- 62.22.61.206 worldnewsnetworking.com
- 64.16.204.55 holein1news.com
- 66.104.169.184 bcenews.com
- 69.84.156.90 stickshiftnews.com
- 74.116.72.236 techtopnews.com
- 74.254.12.168 non-stop-news.net
- 193.203.49.212 inews-today.com
- 199.85.212.118 just-kidding-news.com
- 207.210.250.132 aeronet-news.com
- 212.4.18.129 sightseeingnews.com
- 212.209.90.84 thenewseditor.com
- 216.105.98.152 modernarabicnews.com
"headline": only 140 matches in 2013-dns-census-a-novirt.csv and 3 hits out of 269 hits. Full inspection without CDX led to no new hits.
"today": only 3.5k matches in 2013-dns-census-a-novirt.csv and 12 hits out of 269 hits, TODO how many on those on 2013-dns-census-a-novirt? No new hits.
"world", "global", "international", and spanish/portuguese/French versions like "mondo", "mundo", "mondi": 15k matches in 2013-dns-census-a-novirt.csv. No new hits.
Let' see if there's anything in records/mx.xz.
mx.csv is 21GB.
They do have
" in the files to escape commas so:mx.pyWould have been better with csvkit: stackoverflow.com/questions/36287982/bash-parse-csv-with-quotes-commas-and-newlines
import csv
import sys
writer = csv.writer(sys.stdout)
with open('mx.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
writer.writerow([row[0], row[3]])then:
# uniq not amazing as there are often two or three slightly different records repeated on multiple timestamps, but down to 11 GB
python3 mx.py | uniq > mx-uniq.csv
sqlite3 mx.sqlite 'create table t(d text, m text)'
# 13 GB
time sqlite3 mx.sqlite ".import --csv --skip 1 'mx-uniq.csv' t"
# 41 GB
time sqlite3 mx.sqlite 'create index td on t(d)'
time sqlite3 mx.sqlite 'create index tm on t(m)'
time sqlite3 mx.sqlite 'create index tdm on t(d, m)'
# Remove dupes.
# Rows: 150m
time sqlite3 mx.sqlite <<EOF
delete from t
where rowid not in (
select min(rowid)
from t
group by d, m
)
EOF
# 15 GB
time sqlite3 mx.sqlite vacuumLet's see what the hits use:
awk -F, 'NR>1{ print $2 }' ../media/cia-2010-covert-communication-websites/hits.csv | xargs -I{} sqlite3 mx.sqlite "select distinct * from t where d = '{}'"At around 267 total hits, only 84 have MX records, and from those that do, almost all of them have exactly:with only three exceptions:We need to count out of the totals!which gives, ~18M, so nope, it is too much by itself...
smtp.secureserver.net
mailstore1.secureserver.netdailynewsandsports.com|dailynewsandsports.com
inews-today.com|mail.inews-today.com
just-kidding-news.com|just-kidding-news.comsqlite3 mx.sqlite "select count(*) from t where m = 'mailstore1.secureserver.net'"Let's try to use that to reduce where
av.sqlite from 2013 DNS Census virtual host cleanup a bit further:time sqlite3 mx.sqlite '.mode csv' "attach 'aiddcu.sqlite' as 'av'" '.load ./ip' "select ipi2s(av.t.i), av.t.d from av.t inner join t as mx on av.t.d = mx.d and mx.m = 'mailstore1.secureserver.net' order by av.t.i asc" > avm.csvavm stands for av with mx pruning. This leaves us with only ~500k entries left. With one more figerprint we could do a Wayback Machine CDX scanning scan.Let's check that we still have most our hits in there:At 267 hits we got 81, so all are still present.
grep -f <(awk -F, 'NR>1{print $2}' /home/ciro/bak/git/media/cia-2010-covert-communication-websites/hits.csv) avm.csvsecureserver is a hosting provider, we can see their blank page e.g. at: web.archive.org/web/20110128152204/http://emmano.com/. security.stackexchange.com/questions/12610/why-did-secureserver-net-godaddy-access-my-gmail-account/12616#12616 comments:
secureserver.net is the name GoDaddy use as the reverse DNS for IP addresses used for dedicated/virtual server hosting
We intersect 2013 DNS Census virtual host cleanup with 2013 DNS census MX records and that leaves 460k hits. We did lose a third on the the MX records as of 260 hits since secureserver.net is only used in 1/3 of sites, but we also concentrate 9x, so it may be worth it.
We did a full Wayback Machine CDX scanning for JAR, SWF and cgi-bin in those, but only found a single new hit:
- 63.130.160.50 theglobalheadlines.com. Just barely missed with our 2013 DNS Census virtual host cleanup heuristic keyword searches as we did think of both "global" and "headlines" in the "news" themes!
We can also cut down the data a lot with stackoverflow.com/questions/1915636/is-there-a-way-to-uniq-by-column/76605540#76605540 and tld filtering:This brings us down to a much more manageable 3.0 GB, 83 M rows.
awk -F, 'BEGIN{OFS=","} { if ($1 != last) { print $1, $3; last = $1; } }' ns.csv | grep -E '\.(com|net|info|org|biz),' > nsu.csvLet's just scan it once real quick to start with, since likely nothing will come of this venue:As of 267 hits we get:so yeah, most of those are likely going to be humongous just by looking at the names.
grep -f <(awk -F, 'NR>1{print $2}' ../media/cia-2010-covert-communication-websites/hits.csv) nsu.csv | tee nsu-hits.csv
cat nsu-hits.csv | csvcut -c 2 | sort | awk -F. '{OFS="."; print $(NF-1), $(NF)}' | sort | uniq -c | sort -k1 -n 1 a2hosting.com
1 amerinoc.com
1 ayns.net
1 dailyrazor.com
1 domainingdepot.com
1 easydns.com
1 frienddns.ru
1 hostgator.com
1 kolmic.com
1 name-services.com
1 namecity.com
1 netnames.net
1 tonsmovies.net
1 webmailer.de
2 cashparking.com
55 worldnic.com
86 domaincontrol.comThe smallest ones by far from the total are: frienddns.ru with only 487 hits, all others quite large or fake hits due to CSV. Did a quick Wayback Machine CDX scanning there but no luck alas.
Let's check the smaller ones:Doubt anything will come out of this.
inews-today.com,2013-08-12T03:14:01,ns1.frienddns.ru
source-commodities.net,2012-12-13T20:58:28,ns1.namecity.com -> fake hit due to grep e-commodities.net
dailynewsandsports.com,2013-08-13T08:36:28,ns3.a2hosting.com
just-kidding-news.com,2012-02-04T07:40:50,jns3.dailyrazor.com
fightwithoutrules.com,2012-11-09T01:17:40,sk.s2.ns1.ns92.kolmic.com
fightwithoutrules.com,2013-07-01T22:46:23,ns1625.ztomy.com
half-court.net,2012-09-10T09:49:15,sk.s2.ns1.ns92.kolmic.com
half-court.net,2013-07-07T00:31:12,ns1621.ztomy.comLet's do a bit of counting out of the total:gives ~20M domain using so it accounts for 1/4 of the total.
grep domaincontrol.com ns.csv | awk -F, '{print $1}' | uniq | wcdomaincontrol. Let's see how many domains are in the first place:awk -F, '{print $1}' ns.csv | uniq | wcSame as 2013 DNS census NS records basically, nothing came out.
dnshistory.org contains historical domain -> mappings.
We have not managed to extract much from this source, they don't have as much data on the range of interest.
But they do have some unique data at least, perhaps we should try them a bit more often, e.g. they were the only source we've seen so far that made the association: headlines2day.com -> 212.209.74.126 which places it in the more plausible globalbaseballnews.com IP range.
TODO can it do IP to domain? Or just domain to IP? Asked on their Discord: discord.com/channels/698151879166918727/968586102493552731/1124254204257632377. Their banner suggests that yes:
With our new look website you can now find other domains hosted on the same IP address, your website neighbours and more even quicker than before.
Owner replied, you can't:
At the moment you can only do this for current not historical records
In principle, we could obtain this data from search engines, but Google doesn't track that entire website well, e.g. no hits for
site:dnshistory.org "62.22.60.48" presumably due to heavy IP throttling.Homepage dnshistory.org/ gives date starting in 2009:and it is true that they do have some hits from that useful era.
Here at DNS History we have been crawling DNS records since 2009, our database currently contains over 1 billion domains and over 12 billion DNS records.
Any data that we have the patience of extracting from this we will dump under github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/hits.json.
They appear to piece together data from various sources. This is the most complete historical domain -> IP database we have so far. They don't have hugely more data than viewdns.info, but many times do offer something new. It feels like the key difference is that their data goes further back in the critical time period a bit.
TODO do they have historical reverse IP? The fact that they don't seem to have it suggests that they are just making historical reverse IP requests to a third party via some API?
E.g. searching
thefilmcentre.com under historical data at securitytrails.com/domain/thefilmcentre.com/history/al gives the correct IP 62.22.60.55.Account creation blacklists common email providers such as gmail to force users to use a "corporate" email address. But using random domains like
ciro@cirosantilli.com works fine.Their data seems to date back to 2008 for our searches.
So far, no new domains have been found with Common Crawl, nor have any existing known domains been found to be present in Common Crawl. Our working theory is that Common Crawl never reached the domains How did Alexa find the domains?
Let's try and do something with Common Crawl.
Unfortunately there's no IP data apparently: github.com/commoncrawl/cc-index-table/issues/30, so let's focus on the URLs.
Using their Common Crawl Athena method: commoncrawl.org/2018/03/index-to-warc-files-and-urls-in-columnar-format/
Sample first output line:So
# 2
url_surtkey org,whwheelers)/robots.txt
url https://whwheelers.org/robots.txt
url_host_name whwheelers.org
url_host_tld org
url_host_2nd_last_part whwheelers
url_host_3rd_last_part
url_host_4th_last_part
url_host_5th_last_part
url_host_registry_suffix org
url_host_registered_domain whwheelers.org
url_host_private_suffix org
url_host_private_domain whwheelers.org
url_host_name_reversed
url_protocol https
url_port
url_path /robots.txt
url_query
fetch_time 2021-06-22 16:36:50.000
fetch_status 301
fetch_redirect https://www.whwheelers.org/robots.txt
content_digest 3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ
content_mime_type text/html
content_mime_detected text/html
content_charset
content_languages
content_truncated
warc_filename crawl-data/CC-MAIN-2021-25/segments/1623488519183.85/robotstxt/CC-MAIN-20210622155328-20210622185328-00312.warc.gz
warc_record_offset 1854030
warc_record_length 639
warc_segment 1623488519183.85
crawl CC-MAIN-2021-25
subset robotstxturl_host_3rd_last_part might be a winner for CGI comms fingerprinting!Naive one for one index:have no results... data scanned: 5.73 GB
select * from "ccindex"."ccindex" where url_host_registered_domain = 'conquermstoday.com' limit 100;Let's see if they have any of the domain hits. Let's also restrict by date to try and reduce the data scanned:Humm, data scanned: 60.59 GB and no hits... weird.
select * from "ccindex"."ccindex" where
fetch_time < TIMESTAMP '2014-01-01 00:00:00' AND
url_host_registered_domain IN (
'activegaminginfo.com',
'altworldnews.com',
...
'topbillingsite.com',
'worldwildlifeadventure.com'
)Sanity check:has a bunch of hits of course. Data scanned: 212.88 MB,
select * from "ccindex"."ccindex" WHERE
crawl = 'CC-MAIN-2013-20' AND
subset = 'warc' AND
url_host_registered_domain IN (
'google.com',
'amazon.com'
)WHERE crawl and subset are a must! Should have read the article first.Let's widen a bit more:Still nothing found... they don't seem to have any of the URLs of interest?
select * from "ccindex"."ccindex" WHERE
crawl IN (
'CC-MAIN-2013-20',
'CC-MAIN-2013-48',
'CC-MAIN-2014-10'
) AND
subset = 'warc' AND
url_host_registered_domain IN (
'activegaminginfo.com',
'altworldnews.com',
...
'worldnewsandent.com',
'worldwildlifeadventure.com'
)Does not appear to have any reverse IP hits unfortunately: opendata.stackexchange.com/questions/1951/dataset-of-domain-names/21077#21077. Likely only has domains that were explicitly advertised.
We could not find anything useful in it so far, but there is great potential to use this tool to find new IP ranges based on properties of existing IP ranges. Part of the problem is that the dataset is huge, and is split by top 256 bytes. But it would be reasonable to at least explore ranges with pre-existing known hits...
We have started looking for patterns on
66.* and 208.*, both selected as two relatively far away ranges that have a number of pre-existing hits. 208 should likely have been 212 considering later finds that put several ranges in 212.tcpip_fp:
- 66.104.
- 66.104.175.41: grubbersworldrugbynews.com: 1346397300 SCAN(V=6.01%E=4%D=1/12%OT=22%CT=443%CU=%PV=N%G=N%TM=387CAB9E%P=mipsel-openwrt-linux-gnu),ECN(R=N),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=N),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.48: worlddispatch.net: 1346816700 SCAN(V=6.01%E=4%D=1/2%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=1D5EA%P=mipsel-openwrt-linux-gnu),SEQ(SP=F8%GCD=3%ISR=109%TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.49: webworldsports.com: 1346692500 SCAN(V=6.01%E=4%D=9/3%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=5044E96E%P=mipsel-openwrt-linux-gnu),SEQ(SP=105%GCD=1%ISR=108%TI=Z%TS=A),OPS(O1=M550ST11NW6%O2=M550ST11NW6%O3=M550NNT11NW6%O4=M550ST11NW6%O5=M550ST11NW6%O6=M550ST11),WIN(W1=1510%W2=1510%W3=1510%W4=1510%W5=1510%W6=1510),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.50: fly-bybirdies.com: 1346822100 SCAN(V=6.01%E=4%D=1/1%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=14655%P=mipsel-openwrt-linux-gnu),SEQ(TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.53: info-ology.net: 1346712300 SCAN(V=6.01%E=4%D=9/4%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=50453230%P=mipsel-openwrt-linux-gnu),SEQ(SP=FB%GCD=1%ISR=FF%TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.175.106
- 66.175.106.150: noticiasmusica.net: 1340077500 SCAN(V=5.51%D=1/3%OT=22%CT=443%CU=%PV=N%G=N%TM=38707542%P=mipsel-openwrt-linux-gnu),ECN(R=N),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.175.106.155: atomworldnews.com: 1345562100 SCAN(V=5.51%D=8/21%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=5033A5F2%P=mips-openwrt-linux-gnu),SEQ(SP=FB%GCD=1%ISR=FC%TI=Z%TS=A),ECN(R=Y%DF=Y%TG=40%W=1540%O=M550NNSNW6%CC=N%Q=),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
Hostprobes quick look on two ranges:
208.254.40:
... similar down
208.254.40.95 1334668500 down no-response
208.254.40.95 1338270300 down no-response
208.254.40.95 1338839100 down no-response
208.254.40.95 1339361100 down no-response
208.254.40.95 1346391900 down no-response
208.254.40.96 1335806100 up unknown
208.254.40.96 1336979700 up unknown
208.254.40.96 1338840900 up unknown
208.254.40.96 1339454700 up unknown
208.254.40.96 1346778900 up echo-reply (0.34s latency).
208.254.40.96 1346838300 up echo-reply (0.30s latency).
208.254.40.97 1335840300 up unknown
208.254.40.97 1338446700 up unknown
208.254.40.97 1339334100 up unknown
208.254.40.97 1346658300 up echo-reply (0.26s latency).
... similar up
208.254.40.126 1335708900 up unknown
208.254.40.126 1338446700 up unknown
208.254.40.126 1339330500 up unknown
208.254.40.126 1346494500 up echo-reply (0.24s latency).
208.254.40.127 1335840300 up unknown
208.254.40.127 1337793300 up unknown
208.254.40.127 1338853500 up unknown
208.254.40.127 1346454900 up echo-reply (0.23s latency).
208.254.40.128 1335856500 up unknown
208.254.40.128 1338200100 down no-response
208.254.40.128 1338749100 down no-response
208.254.40.128 1339334100 down no-response
208.254.40.128 1346607900 down net-unreach
208.254.40.129 1335699900 up unknown
... similar downSuggests exactly 127 - 96 + 1 = 31 IPs.
208.254.42:
... similar down
208.254.42.191 1334522700 down no-response
208.254.42.191 1335276900 down no-response
208.254.42.191 1335784500 down no-response
208.254.42.191 1337845500 down no-response
208.254.42.191 1338752700 down no-response
208.254.42.191 1339332300 down no-response
208.254.42.191 1346499900 down net-unreach
208.254.42.192 1334668500 up unknown
208.254.42.192 1336808700 up unknown
208.254.42.192 1339334100 up unknown
208.254.42.192 1346766300 up echo-reply (0.40s latency).
208.254.42.193 1335770100 up unknown
208.254.42.193 1338444900 up unknown
208.254.42.193 1339334100 up unknown
... similar up
208.254.42.221 1346517900 up echo-reply (0.19s latency).
208.254.42.222 1335708900 up unknown
208.254.42.222 1335708900 up unknown
208.254.42.222 1338066900 up unknown
208.254.42.222 1338747300 up unknown
208.254.42.222 1346872500 up echo-reply (0.27s latency).
208.254.42.223 1335773700 up unknown
208.254.42.223 1336949100 up unknown
208.254.42.223 1338750900 up unknown
208.254.42.223 1339334100 up unknown
208.254.42.223 1346854500 up echo-reply (0.13s latency).
208.254.42.224 1335665700 down no-response
208.254.42.224 1336567500 down no-response
208.254.42.224 1338840900 down no-response
208.254.42.224 1339425900 down no-response
208.254.42.224 1346494500 down time-exceeded
... similar downSuggests exactly 223 - 192 + 1 = 31 IPs.
It does appears that long sequences of ranges are a sort of fingerprint. The question is how unique it would be.
First:This reduces us to 2 million IP rows from the total possible 16 million IPs.
n=208
time awk '$3=="up"{ print $1 }' $n | uniq -c | sed -r 's/^ +//;s/ /,/' | tee $n-up-uniq
t=$n-up-uniq.sqlite
rm -f $t
time sqlite3 $t 'create table tmp(cnt text, i text)'
time sqlite3 $t ".import --csv $n-up-uniq tmp"
time sqlite3 $t 'create table t (i integer)'
time sqlite3 $t '.load ./ip' 'insert into t select str2ipv4(i) from tmp'
time sqlite3 $t 'drop table tmp'
time sqlite3 $t 'create index ti on t(i)'OK now just counting hits on fixed windows has way too many results:
sqlite3 208-up-uniq.sqlite "\
SELECT * FROM (
SELECT min(i), COUNT(*) OVER (
ORDER BY i RANGE BETWEEN 15 PRECEDING AND 15 FOLLOWING
) as c FROM t
) WHERE c > 20 and c < 30
"Let's try instead consecutive ranges of length exactly 31 instead then:271. Hmm. A bit more than we'd like...
sqlite3 208-up-uniq.sqlite <<EOF
SELECT f, t - f as c FROM (
SELECT min(i) as f, max(i) as t
FROM (SELECT i, ROW_NUMBER() OVER (ORDER BY i) - i as grp FROM t)
GROUP BY grp
ORDER BY i
) where c = 31
EOFAnother route is to also count the ups:
n=208
time awk '$3=="up"{ print $1 }' $n | uniq -c | sed -r 's/^ +//;s/ /,/' | tee $n-up-uniq-cnt
t=$n-up-uniq-cnt.sqlite
rm -f $t
time sqlite3 $t 'create table tmp(cnt text, i text)'
time sqlite3 $t ".import --csv $n-up-uniq-cnt tmp"
time sqlite3 $t 'create table t (cnt integer, i integer)'
time sqlite3 $t '.load ./ip' 'insert into t select cnt as integer, str2ipv4(i) from tmp'
time sqlite3 $t 'drop table tmp'
time sqlite3 $t 'create index ti on t(i)'Let's see how many consecutives with counts:
sqlite3 208-up-uniq-cnt.sqlite <<EOF
SELECT f, t - f as c FROM (
SELECT min(i) as f, max(i) as t
FROM (SELECT i, ROW_NUMBER() OVER (ORDER BY i) - i as grp FROM t WHERE cnt >= 3)
GROUP BY grp
ORDER BY i
) where c > 28 and c < 32
EOFLet's check on 66:not representative at all... e.g. several convfirmed hits are down:
grep -e '66.45.179' -e '66.45.179' 6666.45.179.215 1335305700 down no-response
66.45.179.215 1337579100 down no-response
66.45.179.215 1338765300 down no-response
66.45.179.215 1340271900 down no-response
66.45.179.215 1346813100 down no-responseLet's check relevancy of known hits:Output:
grep -e '208.254.40' -e '208.254.42' 208 | tee 208hits208.254.40.95 1355564700 unreachable
208.254.40.95 1355622300 unreachable
208.254.40.96 1334537100 alive, 36342
208.254.40.96 1335269700 alive, 17586
..
208.254.40.127 1355562900 alive, 35023
208.254.40.127 1355593500 alive, 59866
208.254.40.128 1334609100 unreachable
208.254.40.128 1334708100 alive from 208.254.32.214, 43358
208.254.40.128 1336596300 unreachableThe rest of 208 is mostly unreachable.
208.254.42.191 1335294900 unreachable
...
208.254.42.191 1344737700 unreachable
208.254.42.191 1345574700 Icmp Error: 0,ICMP Network Unreachable, from 63.111.123.26
208.254.42.191 1346166900 unreachable
...
208.254.42.191 1355665500 unreachable
208.254.42.192 1334625300 alive, 6672
...
208.254.42.192 1355658300 alive, 57412
208.254.42.193 1334677500 alive, 28985
208.254.42.193 1336524300 unreachable
208.254.42.193 1344447900 alive, 8934
208.254.42.193 1344613500 alive, 24037
208.254.42.193 1344806100 alive, 20410
208.254.42.193 1345162500 alive, 10177
...
208.254.42.223 1336590900 alive, 23284
...
208.254.42.223 1355555700 alive, 58841
208.254.42.224 1334607300 Icmp Type: 11,ICMP Time Exceeded, from 65.214.56.142
208.254.42.224 1334681100 Icmp Type: 11,ICMP Time Exceeded, from 65.214.56.142
208.254.42.224 1336563900 Icmp Type: 11,ICMP Time Exceeded, from 65.214.56.142
208.254.42.224 1344451500 Icmp Type: 11,ICMP Time Exceeded, from 65.214.56.138
208.254.42.224 1344566700 unreachable
208.254.42.224 1344762900 unreachablen=66
time awk '$3~/^alive,/ { print $1 }' $n | uniq -c | sed -r 's/^ +//;s/ /,/' | tee $n-up-uniq-cOK down to 45 MB, now we can work.
grep -e '66.45.179' -e '66.104.169' -e '66.104.173' -e '66.104.175' -e '66.175.106' '66-alive-uniq-c' | tee 66hitsNah, it's full of holes:won't be able to find new ranges here.
4,66.45.179.187
12,66.45.179.188
2,66.45.179.197
1,66.45.179.202
2,66.45.179.205
2,66.45.179.206
1,66.45.179.207Domain list only, no IPs and no dates. We haven't been able to extract anything of interest from this source so far.
Domain hit count when we were at 69 hits: only 9, some of which had been since reused. Likely their data collection did not cover the dates of interest.
When you Google most of the hit domains, many of them show up on "expired domain trackers", and above all Chinese expired domain trackers for some reason, notably e.g.:This suggests that scraping these lists might be a good starting point to obtaining "all expired domains ever".
- hupo.com: e.g. static.hupo.com/expdomain_myadmin/2012-03-06(国际域名).txt. Heavily IP throttled. Tor hindered more than helped.Scraping script: ../cia-2010-covert-communication-websites/hupo.sh. Scraping does about 1 day every 5 minutes relatively reliably, so about 36 hours / year. Not bad.Results are stored under
tmp/humo/<day>.Check for hit overlap:The hits are very well distributed amongst days and months, at least they did a good job hiding these potential timing fingerprints. This feels very deliberately designed.grep -Fx -f <( jq -r '.[].host' ../media/cia-2010-covert-communication-websites/hits.json ) cia-2010-covert-communication-websites/tmp/hupo/*There are lots of hits. The data set is very inclusive. Also we understand that it must have been obtains through means other than Web crawling, since it contains so many of the hits.Some of their files are simply missing however unfortunately, e.g. neither of the following exist:webmasterhome.cn did contain that one however: domain.webmasterhome.cn/com/2012-07-01.asp. Hmm. we might have better luck over there then?2018-11-19 is corrupt in a new and wonderful way, with a bunch of trailing zeros:ends in:wget -O hupo-2018-11-19 'http://static.hupo.com/expdomain_myadmin/2018-11-19%EF%BC%88%E5%9B%BD%E9%99%85%E5%9F%9F%E5%90%8D%EF%BC%89.txt hd hupo-2018-11-19000ffff0 74 75 64 69 65 73 2e 63 6f 6d 0d 0a 70 31 63 6f |tudies.com..p1co| 00100000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 0018a5e0 00 00 00 00 00 00 00 00 00 |.........|More generally, several files contain invalid domain names with non-ASCII characters, e.g. 2013-01-02 contains365<D3>л<FA><C2><CC>.com. Domain names can only contain ASCII charters: stackoverflow.com/questions/1133424/what-are-the-valid-characters-that-can-show-up-in-a-url-host Maybe we should get rid of any such lines as noise.Some files around 2011-09-06 start with an empty line. 2014-01-15 starts with about twenty empty lines. Oh and that last one also has some trash bytes the end<B7><B5><BB><D8>. Beauty. - webmasterhome.cn: e.g. domain.webmasterhome.cn/com/2012-03-06.asp. Appears to contain the exact same data as "static.hupo.com"Also has some randomly missing dates like hupo.com, though different missing ones from hupo, so they complement each other nicely.Some of the URLs are broken and don't inform that with HTTP status code, they just replace the results with some Chinese text 无法找到该页 (The requested page could not be found):Several URLs just return length 0 content, e.g.:It is not fully clear if this is a throttling mechanism, or if the data is just missing entirely.
curl -vvv http://domain.webmasterhome.cn/com/2015-10-31.asp * Trying 125.90.93.11:80... * Connected to domain.webmasterhome.cn (125.90.93.11) port 80 (#0) > GET /com/2015-10-31.asp HTTP/1.1 > Host: domain.webmasterhome.cn > User-Agent: curl/7.88.1 > Accept: */* > < HTTP/1.1 200 OK < Date: Sat, 21 Oct 2023 15:12:23 GMT < Server: Microsoft-IIS/6.0 < X-Powered-By: ASP.NET < Content-Length: 0 < Content-Type: text/html < Set-Cookie: ASPSESSIONIDCSTTTBAD=BGGPAONBOFKMMFIPMOGGHLMJ; path=/ < Cache-control: private < * Connection #0 to host domain.webmasterhome.cn left intactStarting around 2018, the IP limiting became very intense, 30 mins / 1 hour per URL, so we just gave up. Therefore, data from 2018 onwards does not contain webmasterhome.cn data.Starting from2013-05-10the format changes randomly. This also shows us that they just have all the HTML pages as static files on their server. E.g. with:we see:grep -a '<pre' * | s2013-05-09:<pre style='font-family:Verdana, Arial, Helvetica, sans-serif; '><strong>2013<C4><EA>05<D4><C2>09<C8>յ<BD><C6>ڹ<FA><BC><CA><D3><F2><C3><FB></strong><br>0-3y.com 2013-05-10:<pre><strong>2013<C4><EA>05<D4><C2>10<C8>յ<BD><C6>ڹ<FA><BC><CA><D3><F2><C3><FB></strong> - justdropped.com: e.g. www.justdropped.com/drops/010112com.html. First known working day:
2006-01-01. Unthrottled. - yoid.com: e.g.: yoid.com/bydate.php?d=2016-06-03&a=a. First known workding day:
2016-06-01.
Data comparison:
- 2012-01-01Looking only at the
.com:The lists are quite similar however.- webmastercn has just about ten extra ones than justdropped, the rest is exactly the same
- justdropped has some extra and some missing from hupo
We've made the following pipelines for hupo.com + webmasterhome.cn merging:
./hupo.sh &
./webmastercn.sh &
./justdropped.sh &
wait
./justdropped-post.sh
./hupo-merge.sh
# Export as small Google indexable files in a Git repository.
./hupo-repo.sh
# Export as per year zips for Internet Archive.
./hupo-zip.sh
# Obtain count statistics:
./hupo-wc.shCount unique domains in the repos:
( echo */*/*/* | xargs cat ) | sort -u | wcThe extracted data is present at:Soon after uploading, these repos started getting some interesting traffic, presumably started by security trackers going "bling bling" on certain malicious domain names in their databases:
- archive.org/details/expired-domain-names-by-day
- github.com/cirosantilli/expired-domain-names-by-day-* repos:
- github.com/cirosantilli/expired-domain-names-by-day-2006
- github.com/cirosantilli/expired-domain-names-by-day-2007
- github.com/cirosantilli/expired-domain-names-by-day-2008
- github.com/cirosantilli/expired-domain-names-by-day-2009
- github.com/cirosantilli/expired-domain-names-by-day-2010
- github.com/cirosantilli/expired-domain-names-by-day-2011 (~11M)
- github.com/cirosantilli/expired-domain-names-by-day-2012 (~18M)
- github.com/cirosantilli/expired-domain-names-by-day-2013 (~28M)
- github.com/cirosantilli/expired-domain-names-by-day-2014 (~29M)
- github.com/cirosantilli/expired-domain-names-by-day-2015 (~28M)
- github.com/cirosantilli/expired-domain-names-by-day-2016
- github.com/cirosantilli/expired-domain-names-by-day-2017
- github.com/cirosantilli/expired-domain-names-by-day-2018
- github.com/cirosantilli/expired-domain-names-by-day-2019
- github.com/cirosantilli/expired-domain-names-by-day-2020
- github.com/cirosantilli/expired-domain-names-by-day-2021
- github.com/cirosantilli/expired-domain-names-by-day-2022
- github.com/cirosantilli/expired-domain-names-by-day-2023
- github.com/cirosantilli/expired-domain-names-by-day-2024
- GitHub trackers:
- admin-monitor.shiyue.com
- anquan.didichuxing.com
- app.cloudsek.com
- app.flare.io
- app.rainforest.tech
- app.shadowmap.com
- bo.serenety.xmco.fr 8 1
- bts.linecorp.com
- burn2give.vercel.app
- cbs.ctm360.com 17 2
- code6.d1m.cn
- code6-ops.juzifenqi.com
- codefend.devops.cndatacom.com
- dlp-code.airudder.com
- easm.atrust.sangfor.com
- ec2-34-248-93-242.eu-west-1.compute.amazonaws.com
- ecall.beygoo.me 2 1
- eos.vip.vip.com 1 1
- foradar.baimaohui.net 2 1
- fty.beygoo.me
- hive.telefonica.com.br 2 1
- hulrud.tistory.com
- kartos.enthec.com
- soc.futuoa.com
- lullar-com-3.appspot.com
- penetration.houtai.io 2 1
- platform.sec.corp.qihoo.net
- plus.k8s.onemt.co 4 1
- pmp.beygoo.me 2 1
- portal.protectorg.com
- qa-boss.amh-group.com
- saicmotor.saas.cubesec.cn
- scan.huoban.com
- sec.welab-inc.com
- security.ctrip.com 10 3
- siem-gs.int.black-unique.com 2 1
- soc-github.daojia-inc.com
- spigotmc.org 2 1
- tcallzgroup.blueliv.com
- tcthreatcompass05.blueliv.com 4 1
- tix.testsite.woa.com 2 1
- toucan.belcy.com 1 1
- turbo.gwmdevops.com 18 2
- urlscan.watcherlab.com
- zelenka.guru. Looks like a Russian hacker forum.
- LinkedIn profile views:
- "Information Security Specialist at Forcepoint"
Check for overlap of the merge:
grep -Fx -f <( jq -r '.[].host' ../media/cia-2010-covert-communication-websites/hits.json ) cia-2010-covert-communication-websites/tmp/merge/*Next, we can start searching by keyword with Wayback Machine CDX scanning with Tor parallelization with out helper ../cia-2010-covert-communication-websites/hupo-cdx-tor.sh, e.g. to check domains that contain the term "news":produces per-year results for the regex term OK lets:
./hupo-cdx-tor.sh mydir 'news|global' 2011 2019news|global between the years under:tmp/hupo-cdx-tor/mydir/2011
tmp/hupo-cdx-tor/mydir/2012./hupo-cdx-tor.sh out 'news|headline|internationali|mondo|mundo|mondi|iran|today'Other searches that are not dense enough for our patience:
world|global|[^.]infoOMG and a few more. It's amazing.
news search might be producing some golden, golden new hits!!! Going full into this. Hits:- thepyramidnews.com
- echessnews.com
- tickettonews.com
- airuafricanews.com
- vuvuzelanews.com
- dayenews.com
- newsupdatesite.com
- arabicnewsonline.com
- arabicnewsunfiltered.com
- newsandsportscentral.com
- networkofnews.com
- trekkingtoday.com
- financial-crisis-news.com
Related:
TODO what does this Chinese forum track? New registrations? Their focus seems to be domain name speculation
Some of the threads contain domain dumps. We haven't yet seen a scrapable URL pattern, but their data goes way back and did have various hits. The forum seems to have started in 2006: club.domain.cn/forum.php?mod=forumdisplay&fid=41&page=10127
club.domain.cn/forum.php?mod=viewthread&tid=241704 "【国际域名拟删除列表】2007年06月16日" is the earliest list we could find. It is an expired domain list.
Some hits:
- club.domain.cn/forum.php?mod=viewthread&tid=709388 contains
alljohnny.comThe thread title is "2009.5.04". The post date 2009-04-30Breadcrumb nav: 域名论坛 > 域名增值交易区 > 国际域名专栏 (domain name forum > area for domain names increasing in value > international domais)
pastebin.com/CTXnhjeS dated mega early on Sep 30th, 2012 by CYBERTAZIEX.
This source was found by Oleg Shakirov.
This pastebin contained a few new hits, in addition to some pre-existing ones. Most of the hits them seem to be linked to the IP 72.34.53.174, which presumably is a major part of the fingerprint found by CYBERTAZIEX, though unsurprisingly methodology is unclear. As documented, the domains appear to be linked to a "Condor hosting" provider, but it is hard to find any information about it online.
From the title, it would seem that someone hacked into Condor and defaced all of its sites, including unknowingly some CIA ones which is LOL.
Ciro Santilli checked every single non-subdomain domain in the list.
Other files under the same account: pastebin.com/u/cybertaziex did not seem of interest.
The author's real name appears to be Deni Suwandi: twitter.com/denz_999 from Indonesia, but all accounts appear to be inactive, otherwise we'd ping him to ask for more info about the list.
www.zone-h.com lists some of the domains. They also seem to have intended to have snapshots of the defaces but we can't see them which is sad:
- www.zone-h.com/mirror/id/18994983 Inspecting the source we see an image zonehmirrors.org/defaced/2013/01/14/vypconsulting.com//tmp/sejeal.jpg "Sejeal" "Memorial of Gaza Martyrs". Sejeal defacements are mentioned e.g. at:
- www.zone-h.com/mirror/id/18410811 inspecting source we find: zonehmirrors.org/defaced/2012/09/30/ambrisbooks.com/ which lists the team:
{kind=link}
alljohnny.com had a hit: ipinf.ru/domains/alljohnny.com/, and so Ciro started looking around... and a good number of other things have hits.Not all of them, definitely less data than viewdns.info.
But they do reverse IP, and they show which nearby reverse IPs have hits on the same page, for free, which is great!
Shame their ordering is purely alphabetical, doesn't properly order the IPs so it is a bit of a pain, but we can handle it.
OMG, Russians!!!
The data here had a little bit of non-overlap from other sources. 4 new confirmed hits were found, plus 4 possible others that were left as candidates.
cqcounter.com has an exceptionally complete database containing:
- domains
- IP of the domain in the past e.g. cqcounter.com/whois/site/activegaminginfo.com.html which actually contains the IP 66.175.106.148!
- 727 x 545 screenshots from the past e.g. at: cqcounter.com/whois/www/activegaminginfo.com.html. These were also presumably meant to show as a thumbnail on the main page: cqcounter.com/whois/www/activegaminginfo.com.html but don't because it's buggy. It's not as good as the HTML from Wayback machine as we can't confirm comms like that, but still this can d help to verify if known in-range domains that the wayback machine didn't archive well (because it is buggy as hell?) have correct style and if they have anything fun in them. We are storing:
- a backup of the screenshots at: github.com/cirosantilli/media/tree/master/cia-2010-covert-communication-websites/screenshots/cqcounter
- a list of their source URLs at: github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/cqcounter-images.txt This should be merged into hits.json but we are lazy.
And perhaps due to having lots of CAPTCHAs, Google doesn't seem to index that website very well... it even has a tiny screenshot! And it also shows some more metadata beyond IP, e.g. HTTP response headers, which notably contain stuff like
Server: Apache-Coyote/1.1.They seem to have an exceptionally complete database.
Both cqcounter.com/whois/www/teclafinance.com.html and cqcounter.com/whois/site/activegaminginfo.com.html both are broken, so it appears that their screenshot mechanism at the time did nor support Chinese characters well.
They also have some random localized versions:These can be useful if your IP gets blacklisted on the main site because you were checking too many sites.
In this section we document the outcomes of more detailed inspection of both the communication mechanisms (JavaScript, JAR, swf) and HTML that might help to better fingerprint the websites.
There are four main types of communication mechanisms found:These have short single word names with some meaning linked to their website.
- There is also one known instance where a .zip extension was used! web.archive.org/web/20131101104829*/http://plugged-into-news.net/weatherbug.zip as:
<applet codebase="/web/20101229222144oe_/http://plugged-into-news.net/" archive="/web/20101229222144oe_/http://plugged-into-news.net/weatherbug.zip"JAR is the most common comms, and one of the most distinctive, making it a great fingerprint. - JavaScript file. There are two subtypes:
- JavaScript with SHAs. Rare. Likely older. Way more fingerprintable.
- JavaScript without SHAs. They have all been obfuscated slightly different and compressed. But the file sizes are all very similar from 8kB to 10kB, and they all look similar, so visually it is very easy to detect a match with good likelyhood.
- Adobe Flash swf file. In all instances found so far, the name of the SWF matches the name of the second level domain exactly, e.g.:While this is somewhat of a fingerprint, it is worth noting that is was a relatively commonly used pattern. But it is also the rarest of the mechanisms. This is a at a dissonance with the rest of the web, which circa 2010 already had way more SWF than JAR apparently.
http://tee-shot.net/tee-shot.swfSome of the SWF websites have archives for empty/servletpages:which makes us think that it is a part of the SWF system../bailsnboots.com/20110201234509/servlet/teammate/index.html ./currentcommunique.com/20110130162713/servlet/summer/index.html ./mynepalnews.com/20110204095758/servlet/SnoopServlet/index.html ./mynepalnews.com/20110204095403/servlet/release/index.html ./www.hassannews.net/20101230175421/servlet/jordan/index.html ./zerosandonesnews.com/20110209084339/servlet/technews/index.html - CGI comms
Because the communication mechanisms are so crucial, they tend to be less varied, and serve as very good fingerprints. It is not ludicrous, e.g. identical files, but one look at a few and you will know the others.
We've come across a few shallow and stylistically similar websites on suspicious ranges with this pattern.
No JS/JAR/SWF comms, but rather a subdomain, and an HTTPS page with .cgi extension that leads to a login page. Some names seen for this subdomain:
The question is, is this part of some legitimate tooling that created such patterns? And if so which? Or are they actual hits with a new comms mechanism not previously seen?
The fact that:suggests to Ciro that they are an actual hit.
- hits of this type are so dense in the suspicious ranges
- they are so stylistically similar between on another
- citizenlabs specifically mentioned a "CGI" comms method
In particular, the
secure and ssl ones are overused, and together with some heuristics allowed us to find our first two non Reuters ranges! Section "secure subdomain search on 2013 DNS Census"Some currently known URLsIf we could do a crawl search for
- backstage.musical-fortune.net/cgi-bin/backstage.cgi
- clients.smart-travel-consultant.com/cgi-bin/clients.cgi
- members.it-proonline.com/cgi-bin/members.cgi
- members.metanewsdaily.com/cgi-bin/ABC.cgi
- miembros.todosperuahora.com/cgi-bin/business.cgi
- secure.altworldnews.com/cgi-bin/desk.cgi
- secure.driversinternationalgolf.com/cgi-bin/drivers.cgi
- secure.freshtechonline.com/cgi-bin/tech.cgi
- secure.globalnewsbulletin.com/cgi-bin/index.cgi
- secure.negativeaperture.com/cgi-bin/canon.cgi
- secure.riskandrewardnews.com/cgi-bin/worldwide.cgi
- secure.theworld-news.net/cgi-bin/news.cgi
- secure.topbillingsite.com/cgi-bin/main.cgi
- secure.worldnewsandent.com/cgi-bin/news.cgi
- ssl.beyondnetworknews.com/cgi-bin/local.cgi
- ssl.newtechfrontier.com/cgi-bin/tech.cgi
- www.businessexchangetoday.com/cgi-bin/business.cgi
- heal.conquermstoday.com (path unknown)
secure.*com/cgi-bin/*.cgi that might be a good enough fingerprint, maybe even *.*com/cgi-bin/*.cgi. Edit: it is not perfect, but we kind of did it: Section "secure subdomain search on 2013 DNS Census".Later on, we've also come across some stylistic hits in IP ranges with apparent slight variations of the CGI comms pattern:
Since these are so rare, it is still a bit hard to classify them for sure, but they are of great interest no doubt, as as we start to notice these patterns more tend to come if it is a thing.
The CGI comms websites contain the only occurrence of HTTPS, so it might open up the door for a certificate fingerprint as proposed by user joelcollinsdc at: news.ycombinator.com/item?id=36280801!
crt.sh appears to be a good way to look into this:They all appear to use either of:
- backstage.musical-fortune.net:
- clients.smart-travel-consultant.com
- members.it-proonline.com
- members.metanewsdaily.com
- miembros.todosperuahora.com
- secure.altworldnews.com
- secure.driversinternationalgolf.com
- secure.freshtechonline.com
- secure.globalnewsbulletin.com
- secure.negativeaperture.com
- secure.riskandrewardnews.com
- secure.theworld-news.net
- secure.topbillingsite.com
- secure.worldnewsandent.com
- ssl.beyondnetworknews.com
- ssl.newtechfrontier.com
- www.businessexchangetoday.com
- heal.conquermstoday.com
- Go Daddy
- Thawte DV SSL CA
- Starfield Technologies, Inc.
crt.sh/?q=globalnewsbulletin.com has a hit to: crt.sh/?id=774803. With login we can see: search.censys.io/certificates/5078bce356a8f8590205ae45350b27f58f4ac04478ed47a389a55b539065cee8. Issued by www.thawte.com/repository/index.html. No hits for certificates with same public key: search.censys.io/search?resource=certificates&q=parsed.subject_key_info.fingerprint_sha256%3A+714b4a3e8b2f555d230a92c943ced4f34b709b39ed590a6a230e520c273705af or any other "same" queries though.
Let's try another one for secure.altworldnews.com: search.censys.io/certificates/e88f8db87414401fd00728db39a7698d874dbe1ae9d88b01c675105fabf69b94. Nope, no direct mega hits here either.
TODO it would be cool to have a look at the JARs and see if they have anything in common that makes for a good fringerprint. Would not help find new ones, but would help to confirm possible hits.
The most advanced reverse engineering effort so far has been by GitHub user quat1024, an undergratuate student at Ohio State University, Minecraft modding extraordinaire and furry afficionado. Minecraft is written in Java, which may partly explains his Java skills.He managed to deobfuscate the strings present inthe JARs using Enigma, possibly github.com/FabricMC/Enigma, a Java reverse engineering tool. Cool findings on web.archive.org/web/20110208072027/http://newsupdatesite.com/update.jar include:
.
./c
./c/b
./c/b/b.class
./c/b/c.class
./c/b/d.class
./c/b/a
./c/b/a/a.class
./c/b/a/b.class
./c/b/a/c.class
./c/b/a/d.class
./c/a
./c/a/a.class
./c/a/b.class
./c/a/c.class
./b
./b/a
./b/a/a
./b/a/a/e.class
./b/a/a/f.class
./b/a/a/a.class
./b/a/a/b.class
./b/a/a/g.class
./b/a/a/c.class
./b/a/a/d.class
./META-INF
./META-INF/MANIFEST.MF
./a
./a/cre
./a/a
./a/a/b
./a/a/b/a.class
./a/a/a
./a/a/a/e.class
./a/a/a/applet.configs
./a/a/a/b
./a/a/a/b/e.class
./a/a/a/b/f.class
./a/a/a/b/b.class
./a/a/a/b/g.class
./a/a/a/b/c.class
./a/a/a/b/d.class
./a/a/a/b/a
./a/a/a/b/a/a.class
./a/a/a/b/a/b.class
./a/a/a/b/a/c.class
./a/a/a/c.class
./a/a/a/d.class
./a/a/a/a
./a/a/a/a/a.class./META-INF/MANIFEST.MFManifest-Version: 1.0
Ant-Version: Apache Ant 1.7.1
Created-By: 1.5.0_17-b04 (Sun Microsystems Inc.)web.archive.org/web/20110207204640/http://flyingtimeline.com/aircraft.jar is very similar looking.
META-INF/MANIFEST.MF is identical:Manifest-Version: 1.0
Ant-Version: Apache Ant 1.7.1
Created-By: 1.5.0_17-b04 (Sun Microsystems Inc.)web.archive.org/web/20110202185659/http://differentviewtoday.com/bwm.jar is a bit different with tree:and:
META-INF/MANIFEST.MF
a/a.class
b/a/a/a.class
b/a/a/b.class
b/a/a/c.class
b/a/b/a.class
b/a/b/b.class
b/a/b/c.class
b/a/b/d.class
b/a/b/e.class
b/a/bw.properties
b/a/c.class
c/a/a/a.class
c/a/a/b.class
c/a/a/c.class
c/a/a/d.class
c/a/b.class
c/a/c.class
c/a/d.class
c/a/e.class
c/b/a.class
c/b/b.class
c/b/c.classMETA-INF/MANIFEST.MF
Manifest-Version: 1.0
Ant-Version: Apache Ant 1.6.5
Created-By: 1.5.0_12-b04 (Sun Microsystems Inc.)There are two types of JavaScript found so far. The ones with SHA and the ones without. There are only 2 examples of JS with SHA:Both files start with precisely the same string:
- iraniangoals.com: web.archive.org/web/20110202091909/http://iraniangoals.com/journal.js Commented at: iraniangoals.com JavaScript reverse engineering
- iranfootballsource.com: web.archive.org/web/20110202091901/http://iranfootballsource.com/futbol.js
- kukrinews.com: web.archive.org/web/20100513094909/http://kukrinews.com/news.js
- todaysnewsandweather-ru.com: web.archive.org/web/20110207094735/http://todaysnewsandweather-ru.com/blacksea.js
var ms="\u062F\u0631\u064A\u0627\u0641\u062A\u06CC",lc="\u062A\u0647\u064A\u0647 \u0645\u062A\u0646",mn="\u0628\u0631\u062F\u0627\u0632\u0634 \u062F\u0631 \u062C\u0631\u064A\u0627\u0646 \u0627\u0633\u062A...\u0644\u0637\u0641\u0627 \u0635\u0628\u0631 \u0643\u0646\u064A\u062F",lt="\u062A\u0647\u064A\u0647 \u0645\u062A\u0646",ne="\u067E\u0627\u0633\u062E",kf="\u062E\u0631\u0648\u062C",mb="\u062D\u0630\u0641",mv="\u062F\u0631\u064A\u0627\u0641\u062A\u06CC",nt="\u0627\u0631\u0633\u0627\u0644",ig="\u062B\u0628\u062A \u063A\u0644\u0637. \u062C\u0647\u062A \u062A\u062C\u062F\u064A\u062F \u062B\u0628\u062A \u0635\u0641\u062D\u0647 \u0631\u0627 \u0628\u0627\u0632\u0622\u0648\u0631\u06CC \u06A9\u0646\u064A\u062F",hs="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",ji="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",ie="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",gc="\u0633\u0648\u0627\u0631 \u06A9\u0631\u062F\u0646 \u062A\u06A9\u0645\u064A\u0644 \u0634\u062F",gz="\u0645\u0637\u0645\u0626\u0646\u064A\u062F \u06A9\u0647 \u0645\u064A\u062E\u0648\u0627\u0647\u064A\u062F \u067E\u064A\u0627\u0645 \u0631\u0627 \u062D\u0630\u0641 \u06A9\u0646\u064A\u062F\u061F"Good fingerprint present in all of them:
throw new Error("B64 D.1");};if(at[1]==-1){throw new Error("B64 D.2");};if(at[2]==-1){if(f<ay.length){throw new Error("B64 D.3");};dg=2;}else if(at[3]==-1){if(f<ay.length){throw new Error("B64 D.4")Some reverse engineering was done at: twitter.com/hackerfantastic/status/1575505438111571969?lang=en.
Notably, the password is hardcoded and its hash is stored in the JavaScript itself. The result is then submitted back via a POST request to
/cgi-bin/goal.cgi.TODO: how is the SHA calculated? Appears to be manual.
The JavaScript of each website appears to be quite small and similarly sized. They are all minimized, but have reordered things around a bit.
For example consider: web.archive.org/web/20110202190932/http://feedsdemexicoyelmundo.com/mundo.js
First we have to know that the Wayback Machine adds some stuff before and after the original code. The actual code there starts at:and ends in:
ap={fg:['MSXML2.XMLHTTPck++;};return fu;};Further analysis would be needed.
Googling most domains gives only very few results, and most of them are just useless lists of expired domains. Skipping those for now.
Googling
"dedrickonline.com" has a git at www.webwiki.de/dedrickonline.com# Furthermore, it also contains the IP address "65.61.127.174" under the "Technik" tab!Unfortunately that website appears to be split by language? E.g. the English version does not contain it: www.webwiki.com/dedrickonline.com, which would make searching a bit harder, but still doable.
IP search did work! www.webwiki.de/65.61.127.174
But doesn't often/ever work unfortunately for others.
Searching on github.com: github.com/DrWhax/cia-website-comms by Jurre van Bergen from September 2022 contains some of the links to some of the ones reported by Reuters including some of their JARs, presumably for reversing purposees. Pinged him at: github.com/DrWhax/cia-website-comms/issues/1
Some less-trivial breakthroughs:
- finding 2013 DNS Census
- CGI comms characterization
- secure subdomain search on 2013 DNS Census let to a few hits
- 2013 DNS Census virtual host cleanup heuristic keyword searches was massive and led to many new ranges
Grepping the 2013 DNS Census first by overused CGI comms subdomains
secure. and ssl. leaves 200k lines. Grepping for the overused "news" led to hits:- secure.worldnewsandent.com,2012-02-13T21:28:15,208.254.40.117
- ssl.beyondnetworknews.com,2012-02-13T20:10:13,66.104.175.40
Also tried but failed:
sports:- secure.motorsportdealers.com,2012-04-10T20:19:09,64.73.117.38 web.archive.org/web/20110501000000*/motorsportdealers.com
OK, after the initial successes in New results: only one...
secure., we went a bit more data intensive:- took all
secure.*ssl.*URLs in the 2013 DNS Census, 70k entries - cleaned up a bit, e.g. only
.comor.net. this left only, 30k entries only - lopped over all of them in archive CDX: Wayback Machine CDX scanning, searching for those that also end in
.cgiweb.archive.org/cdx/search/cdx?url=$domain&matchType=domain&filter=urlkey:.*.cgi&to=20140101000000. Took an afternoon, but no rate limit block. - this leaves about 1000, so we loop over all of them manually on web archive with a script, and opened any that had the pattern of very vew hits between 2010 and 2013 only, and on those check for visual/thematic style match. Careful not to make more than 15 requests per minute or else 5 min blacklist!
- 208.254.42.205 secure.driversinternationalgolf.com,2012-02-13T10:42:20,
After 2013 DNS Census virtual host cleanup heuristic keyword searches we later understood why there were so few hits here: the 2013 DNS Census didn't capture the
secure. subdomains of many domains it had for some reason. Shame, because if it had, this method would have yielded many more results.Starting at twitter.com/shakirov2036/status/1746729471778988499, Russian expat Oleg Shakirov comments "Let me know if you are still looking for the Carson website".
He then proceeded to give Carson and 5 other domains in private communication. His name is given here with his consent. His advances besides not being blind were Yandexing for some of the known hits which led to pages that contained other hits:
- moyistochnikonlaynovykhigr.com contains a copy of myonlinegamesource.com, and both are present at www.seomastering.com/audit/pefl.ru/, an SEO tracker, because both have backlinks to
pefl.ru, which is apparently a niche fantasy football website - 4 previously unknown hits from: "Mass Deface III" pastebin. He missed one which Ciro then found after inspecting all URLs on Wayback Machine, so leading to a total of 5 new hits from that source.
Unfortunately, these methods are not very generalizable, and didn't lead to a large number of other hits. But every domain counts!
Edit: Carson was found Oleg Shakirov's findingsby Oleg Shakirov:
alljohnny.com, communicated at: twitter.com/shakirov2036/status/1746729471778988499, earliest archive from 2004 (!): web.archive.org/web/20040113025122/http://alljohnny.com/, The domain was hidden in plain sight, it was present in a not very visible watermark visible in the Reuters article screenshot! The watermark was added to the CIA to the background image, it is actually present on the website. In retrospect, it was actually present at on the expired domain trackers dataset, but the mega discrete all second word made Ciro Santilli miss it: github.com/cirosantilli/expired-domain-names-by-day-2015/blob/9d504f3b85364a64f7db93311e70011344cff788/07/05/02#L1572
2004 Wayback Machine archive of alljohnny.com
. What follows is the previous
The fact that the Reuters article has a screenshot of it, and therefore a Wayback Machine link, plus the specificity of the website topic, will likely keep Ciro awake at night for a while until someone finds that domain.
Some text visible on the Reuters screenshot:It is unclear however if this text is plaintext or part of a an image.
Johnny Carson and The Tonight Show
Your Favorite Host and Comedic Genius
Submit Your Favorite Carson Moment
Heeere's Johnny!
Holy crap, the "Here's Johnny" line from The Shining (1980) is a reference to Johnny Carson: www.youtube.com/watch?v=WDpipB4yehk, www.youtube.com/watch?v=aYnyPAkgyvc, Ciro never knew that... but every American would have understood it at the time.
Some failed attempts, either dry guesses or from DNS grepping dataset searches:
- johnnycarson.com: official
- johnnycarson.net: fan site: web.archive.org/web/20010501225614/http://johnnycarson.net/
- johnnycarsontonight.com
- carson-johnny.com: legit
- johnnycarsonshow.com: web.archive.org/web/20110208005558/http://johnnycarsonshow.com/captcha/index.php?d=johnnycarsonshow.com your IP has been blocked
- tributetojohnnycarson.com: only one archive web.archive.org/web/20180805132430/http://tributetojohnnycarson.com/
- bestofjohnnycarson.com: web.archive.org/web/20130525035938/http://bestofjohnnycarson.com/ Lived past 2013.
- bestofjohnny.com/: web.archive.org/web/20130506011824/http://bestofjohnny.com/ empty
- johnnycarsonvideo.com: dead early 2000s web.archive.org/web/20130605152818/http://johnnycarsonvideo.com/
- johnnycarsontv.com: web.archive.org/web/20230000000000*/johnnycarsontv.com
- thejohnnycarsonshow.com: web.archive.org/web/20230000000000*/thejohnnycarsonshow.com
- carsonsbest.com: web.archive.org/web/20230000000000*/carsonsbest.com
- johnnycarsonfans.com: web.archive.org/web/20230000000000*/johnnycarsonfans.com
- web.archive.org/web/20230000000000*/carsonified.com
- night:
- amazing:
- johnnyamazing.com: broken archives: web.archive.org/web/*/http://johnnyamazing.com/*
- carson
- johnneycarson.com: no archives
- johnnycarson.co: no archives
- johnnycarsons.info
- johnnycarsons.com
- johnnycarson.org
- johnnycarsonsdesk.com
- johnny-carson-video.com
- johnnycarsondvd.org
- johnnycarsondvds.org
- johnnycarsondvd.net
- johnnycarsondvd.tv
- johnnycarsondvds.net
- johnnycarsondvds.tv
- johnnycarson.tv
- johnnyguitarcarson.com
- johnnycarsonmovie.com
- hookedonjohnnycarson.com
- johnnycarsonbook.com
- licensingjohnnycarson.com
- johnnnycarson.com
- johnnycarson360.com
- koalajohnnycarson.com
- johnny-carson.com
- johnnycarsonbirthplace.com
- johnnycarsonbirthplace.net
- johnny:
- heres:
- heresjohnnyfilm.com: web.archive.org/web/20131011115733/http://www.heresjohnnyfilm.com/ legit
- hereisjohnny.net: no archives
- heresjohnnyradioshow.com: web.archive.org/web/20130509042107/http://heresjohnnyradioshow.com/, Legit most likely: web.archive.org/web/20140517103512/http://heresjohnnyradioshow.com/
- wherejohnnylives.net: broken archives
- heresjohnny.com: squat web.archive.org/web/20130607145841/http://heresjohnny.com/ Many other TlD like .net, .co.uk
- heeeeresjohnny.com: web.archive.org/web/20130612211448/http://heeeeresjohnny.com/: legit
- night:
- johnnylatenight.com: web.archive.org/web/20150801132622/http://johnnylatenight.com/ Legit broken
- web.archive.org/web/20110208161513/http://www.johnnysnight.com/
- heres:
- johnnycarson.org: squatted past 2013, nothing before
- carsonshow.com: squat: web.archive.org/web/20110224211714/http://carsonshow.com/
- tonightshow247.net: web.archive.org/web/20101226190209/http://tonightshow247.net/: squat
- tonightshow.tv: web.archive.org/web/20141221222442/http://www.tonightshow.tv/: legit
Searching the Wayback Machine proved fruitless. There is no full text search: Wayback Machine full text search, and a heuristic web.archive.org/web/20230000000000*/Johnny%20Carson search has relevant hits but not the one we want.
Another attempt was to search for "carson" on webmasterhome.cn which lists expired domains in bulk by expiration day, and it search engine friendly. It contains most of the domains we've found so far. Google either doesn't support partial word search or requires you to be a God to find it
so we settle for DuckDuckGo which supports it: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22&t=h_&ia=web Adding years also helps: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22+2011&ia=web with this we might be getting all possible results. Ciro went through all in 2011, 2012 and 2013 but no luck. Also fuck en.wikipedia.org/wiki/Carson_City,_Nevada and en.wikipedia.org/wiki/Carson,_California :-)
Let's search tools.whoisxmlapi.com/reverse-whois-search for "carson" contained in any historic domain name. 10,001 lines. Grepping those, no good Wayback machine hits for those that also contain "johnny" or "show". Data at: raw.githubusercontent.com/cirosantilli/media/master/cia-2010-covert-communication-websites/tools.whoisxmlapi.com_reverse-whois-search_carson.csv in case anyone want to try and dig...
Scrapped justdropped data, patched:and then:
+++ b/cia-2010-covert-communication-websites/cdx-post.sh
@@ -1,7 +1,7 @@
#!/usr/bin/env bash
# Post process the output of cdx.sh to enrich IDs even further, and reconstruct easier to Web Archive inspect domain names.
-grep -P -e '([^,)]+)\)\/\1\.swf|\)/[^/]+.jar|([^,)]+),([^,)]+),([^,)]+)\)/cgi-bin/[^/]+\.cgi' "$1" |
- sed -r 's/\).*//' | awk -F, '{ printf("%s.%s\n", $2, $1) }' | uniq -c | awk '$1 == 1{ print $2 }' | tee $1.post
+grep -P -e '([^,)]+)\)\/\1\.swf|\)/[^/]+.jar|([^,)]+),([^,)]+),([^,)]+)\)/cgi-bin/[^/]+\.cgi' "$1"|
+ sed -r 's/\).*//' | awk -F, '{ printf("%s.%s\n", $2, $1) }' | uniq -c | awk '{ print $2 }' | tee $1.post./hupo-cdx-tor.sh out 'news|headline|internationali|mondo|mundo|mondi|iran|today' 2006 2022web.archive.org/web/20110203041325/http://financecentraltoday.com/
- viewdns.info/iphistory/?domain=financecentraltoday.com
- 208.91.197.27 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-11-08
- 69.90.163.85 Canada COGECO-PEER1 2013-09-26
- 69.90.160.75 Canada COGECO-PEER1 2011-06-22 viewdns.info/reverseip/?t=1&host=69.90.160.75 says small virtual. Checked all but no hits.
- securitytrails.com/domain/financecentraltoday.com/history/a
- 69.90.160.75 Aptum Technologies 2010-04-04 (15 years) 2010-04-27 (15 years) 23 days
- 69.42.58.70 Aptum Technologies 2009-01-07 (16 years) 2009-01-28 (16 years) 21 days. Near health-men-today.com.
web.archive.org/web/20110202221328/http://thenewsofpakistan.com/
- viewdns.info/iphistory/?domain=thenewsofpakistan.com
- 50.22.27.227 Dallas - United States SOFTLAYER 2013-06-30
- 174.133.70.18 United States SOFTLAYER 2012-11-12. In range.
- securitytrails.com/domain/thenewsofpakistan.com/history/a
web.archive.org/web/20110201184753/http://shadesofnews.com/
- viewdns.info/iphistory/?domain=shadesofnews.com
- 64.6.225.2 United States WEBINT 2013-11-29 viewdns.info/reverseip/?t=1&host=64.6.225.2 mid virtual.
- securitytrails.com/domain/shadesofnews.com/history/a
web.archive.org/web/20050424123432/http://www.pokernewsweb.com/ likely legit in the intended emulated style
web.archive.org/web/20101226225311/http://world-news-online.net/ domainsbyproxy.com registered 2006-06-14T21
- viewdns.info/iphistory/?domain=world-news-online.net
- 199.187.208.12 Miami - United States PERFORMIVE 2013-12-02 viewdns.info/reverseip/?t=1&host=199.187.208.12 is small virtual, checked all in there and 199.187.208.5 - 199.187.208.15
- 63.247.81.241 United States NTHL 2011-09-07 viewdns.info/reverseip/?t=1&host=63.247.81.241 searching 63.247.81.249
- 63.247.81.241 web.archive.org/web/20110202210855/http://motornstyle.com/ off
- 63.247.81.244 web.archive.org/web/20110106222053/http://puzzlesgalore.net/ under construction
- 63.247.81.245 web.archive.org/web/20110202102921/http://chairyogavideo.com/ under construction
- 63.247.81.247 web.archive.org/web/20110207131727/http://pccubeservice.com/indexPage.jsp
- securitytrails.com/domain/world-news-online.net/history/a
web.archive.org/web/20100923090646/http://mideasttoday.net/
- viewdns.info/iphistory/?domain=mideasttoday.net says:
- 208.91.197.27 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-12-09
- 65.98.118.97 United States FORTRESSITX 2013-12-02
- 65.98.118.101 United States FORTRESSITX 2013-05-20. viewdns.info/reverseip/?t=1&host=65.98.118.101 empty
- securitytrails.com/domain/mideasttoday.net/history/a says:
web.archive.org/web/20110209045123/http://dryterrainnews.com/
- viewdns.info/iphistory/?domain=dryterrainnews.com says:
- 50.22.27.227 Dallas - United States SOFTLAYER 2013-11-29
- 174.133.70.18 United States SOFTLAYER 2012-11-12
- securitytrails.com/domain/dryterrainnews.com/history/a
web.archive.org/web/20100206221718/http://euronewsonline.net/
- viewdns.info/iphistory/?domain=euronewsonline.net says:
- 74.220.207.94 United States UNIFIEDLAYER-AS-1 2013-12-09
- 184.168.221.55 United States AS-26496-GO-DADDY-COM-LLC 2013-11-25
- 74.220.207.94 United States UNIFIEDLAYER-AS-1 2013-09-23. viewdns.info/reverseip/?t=1&host=74.220.207.94 says medium virtual.
- securitytrails.com/domain/euronewsonline.net/history/a also says
web.archive.org/web/20110208063146/http://news-and-sports.com/ Hit.
- viewdns.info/iphistory/?domain=news-and-sports.com says:
- 204.11.56.25 British Virgin Islands CONFLUENCE-NETWORK-INC 2014-07-05
- 208.91.197.19 British Virgin Islands CONFLUENCE-NETWORK-INC 2013-05-20
- 66.104.175.42 United States XO-AS15 2012-06-29 In range.
web.archive.org/web/20110202054628/http://intoworldnews.com/ hit.
- viewdns.info/iphistory/?domain=intoworldnews.com says:
- securitytrails:
web.archive.org/web/20110207171340/http://mydailynewsreport.com/ hit
- viewdns.info/iphistory/?domain=mydailynewsreport.com says
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2014-03-15
- 74.52.51.139 United States SOFTLAYER 2012-06-29 viewdns.info/reverseip/?t=1&host=74.52.51.139 says small virtual
On that same IP...- web.archive.org/web/20110208004005/http://networkconnectionsite.com/ Hit. viewdns.info/iphistory/?domain=networkconnectionsite.com says only at that IP.
- web.archive.org/web/20110207103008/http://soccerguidesite.com/ Korean site, would be unusual given a splash page. Has a JAR at: web.archive.org/web/20110207103045/http://soccerguidesite.com/tools.jar but everything else unarchived. JAR is atypical.
Around checked 74.52.51.133 - 74.52.51.149- viewdns.info/reverseip/?t=1&host=74.52.51.136 large virtual
- securitytrails.com/domain/mydailynewsreport.com/history/a says
- 74.52.51.139 SoftLayer Technologies Inc. 2011-03-06 (14 years) 2011-03-21 (14 years) 15 days
- 174.123.39.202 SoftLayer Technologies Inc. 2010-12-08 (14 years) 2011-03-05 (14 years) 3 months
- 75.125.247.170 SoftLayer Technologies Inc. 2010-02-20 (15 years) 2010-05-22 (15 years) 3 months
- 205.178.189.129 Network Solutions, LLC 2010-02-10 (15 years) 2010-02-20 (15 years) 10 days. viewdns.info/reverseip/?t=1&host=205.178.189.129 is large virtual.
web.archive.org/web/20050508220858/http://www.asianewsupdate.com/ this looks like the exact format of legitimate site the CIA was emulating. Copyright 2005, a CGI link to as: www.asianewsupdate.com:80/cgi-sys/FormMail.cgi There's a phone there 01 647-0910 so seems less likely?
2010. JAR unarchived. rss, split image
- viewdns.info/iphistory/?domain=newsdelivered.net says:
- 192.96.218.41 United States 123NET 2013-06-10
- 196.40.84.210 Costa Rica RADIOGRAFICA COSTARRICENSE 2013-05-20
- 50.63.202.40 United States AS-26496-GO-DADDY-COM-LLC 2013-04-08
- 74.220.207.158 United States UNIFIEDLAYER-AS-1 2013-03-11. viewdns.info/reverseip/?host=74.220.207.158&t=1 says large virtual.
- securitytrails:
2010. JAR. Split header.
- viewdns.info/iphistory/?domain=latinamericanewsbeat.com says:
- 184.168.221.34 United States AS-26496-GO-DADDY-COM-LLC 2013-03-23
- 74.91.172.195 United States INTERNAP-BLOCK-4 2012-11-12
- 76.162.90.179 United States WINDSTREAM 2011-09-08. viewdns.info/reverseip/?host=76.162.90.179&t=1 says small virtual? Explored 76.162.90.174 - 76.162.90.183.
- securitytrails.com/domain/latinamericanewsbeat.com/history/a
2011. JAR unarchived. Split header.
- viewdns.info/iphistory/?domain=inkfreenews.com says:
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-09-21
- 128.121.9.46 United States NTT-LTD-2914 2012-06-29. Reverse empty. Checked: 128.121.9.43 - 128.121.9.53
- securitytrails.com/domain/inkfreenews.com/history/a
2011. JAR. a.newslink, a.newslinkalt.
- viewdns.info/iphistory/?domain=profile-news.com says:
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2012-06-29
- 199.204.248.105 United States WEBINT 2012-01-11. viewdns.info/reverseip/?host=199.204.248.105&t=1 says large virtual.
- 205.214.86.38 United States DATABANK-LATISYS 2011-08-11. viewdns.info/reverseip/?host=205.214.86.38&t=1 says small virtual.
- securitytrails.com/domain/profile-news.com/history/a
2011. Arabic. RSS.
- viewdns.info/iphistory/?domain=nejadnews.com says: 208.254.38.56 United States COLO-PREM-VZB 2012-06-29.
- viewdns.info/reverseip/?host=208.254.38.56&t=1 says single domain and we see that todaysengineering.com was not too far confirming a new range
web.archive.org/web/20110129115400/http://kmirano.com/ shallow but off style? Has a kmirano.sfw... viewdns.info/iphistory/?domain=kmirano.com says 211.1.224.71 Japan NTT SmartConnect Corporation 2012-01-11
2011. JAR. Copyright 2008. Split header and other images. They are obsessed about CDMA (2G).
- viewdns.info/iphistory/?domain=wiredworldnews.com says:
- 69.89.237.152 United States RINGSQUARED 2012-01-11. Empty.
- 67.213.209.10 Atlanta - United States UK-2 Limited 2011-04-04. Virtual.
- securitytrails.com/domain/wiredworldnews.com/history/a
- 69.89.237.152 RingSquared 2011-06-25 (14 years) 2011-07-30 (14 years) 1 month
- 69.89.237.152 RingSquared 2011-06-14 (14 years) 2011-06-24 (14 years) 10 days
- 67.213.209.10 UK-2 Limited 2008-12-03 (16 years) 2009-02-10 (16 years) 2 months
- 69.4.225.2 SoftLayer Technologies Inc. 2008-09-01 (17 years) 2008-09-09 (17 years) 8 days. viewdns.info/reverseip/?t=1&host=69.4.225.2 empty.
2011. JAR. split header, RSS.
- viewdns.info/iphistory/?domain=the-news-scene.com says 74.81.69.194 United States NTHL 2012-01-11. viewdns.info/reverseip/?host=74.81.69.194&t=1 says virtual.
- securitytrails.com/domain/the-news-scene.com/history/a says
- 74.81.69.194 NETWORK TRANSIT HOLDINGS LLC 2009-12-24 (15 years) 2010-03-23 (15 years) 3 months
- 209.51.136.178 QuickMeg Inc 2008-09-01 (17 years) 2009-12-24 (15 years) 1 year. viewdns.info/reverseip/?t=1&host=209.51.136.178 says small virtual and in there we obtain:Explored viewdns.info 209.51.136.170 - 209.51.136.185 empty.
2010. Suspicious. But no clear fingrenprint. Also not as shallow as others. Also Joomla based which would be novel.
- viewdns.info/iphistory/?domain=eqranews.com says:
- 69.64.147.243 United States RIGHTSIDE 2012-03-03
- 67.228.81.180 Seattle - United States SOFTLAYER 2011-04-04. viewdns.info/reverseip/?t=1&host=67.228.81.180 says virtual.
- securitytrails.com/domain/eqranews.com/history/a says
- 69.64.147.243 Amazon.com, Inc. 2011-04-28 (14 years) 2012-01-19 (13 years) 9 months
- 67.228.81.180 SoftLayer Technologies Inc. 2011-04-18 (14 years) 2011-04-28 (14 years) 10 days
- 174.37.172.68 SoftLayer Technologies Inc. 2011-04-13 (14 years) 2011-04-18 (14 years) 5 days
- 67.228.81.180 SoftLayer Technologies Inc. 2011-03-19 (14 years) 2011-04-13 (14 years) 25 days
- 74.220.215.62 Unified Layer 2010-03-18 (15 years) 2011-03-19 (14 years) 1 year
2010. JAR.
- viewdns.info/iphistory/?domain=magneticfieldnews.com says 173.205.124.151 United States IMH-IAD 2012-01-11. viewdns.info/reverseip/?host=173.205.124.151&t=1 says large-ish virtual.
- dnshistory.org/dns-records/magneticfieldnews.com empty
- securitytrails.com/domain/magneticfieldnews.com/history/a
2011. JAR. RSS, Split header images.
- viewdns.info/iphistory/?domain=segomonews.com 204.13.11.6 United States KATTARE 2012-01-11. viewdns.info/reverseip/?host=204.13.11.6&t=1 says virtual.
- dnshistory.org/historical-dns-records/a/segomonews.com same
- securitytrails.com/domain/segomonews.com/history/a same
newspapergateway.com/ web.archive.org/web/20110208070309/http://newspapergateway.com/ hard to tell but generally off. Has both JAR and SWF.
- viewdns.info/iphistory/?domain=newspapergateway.com says:
- 63.251.171.80 United States INTERNAP-BLOCK-4 2011-11-13
- 66.115.138.101 United States PERFORMIVE 2011-09-08
2011 Farsi. JAR. RSS.
- dnshistory.org/dns-records/pondernews.net nothing
- viewdns.info/iphistory/?domain=pondernews.net. privatesystems.net.
- 68.178.232.100 United States AS-26496-GO-DADDY-COM-LLC 2011-11-28
- 67.222.6.108 Atlanta - United States PRIVATESYSTEMS 2011-10-31. Virtual. Also here on very quick look at promising names:
- web.archive.org/web/20100517070603/http://middle-east-newstoday.com/ Only at that IP. JS.
- securitytrails.com/domain/pondernews.net/history/a
2011. English. Split header, RSS.
- viewdns.info/iphistory/?domain=internationalnewsworthiness.com says 216.86.153.116 United States STEADFAST 2011-04-04. Checking 216.86.153.106 - 216.86.153.125
- viewdns.info/reverseip/?host=216.86.153.114&t=1 big virtual
- viewdns.info/reverseip/?host=216.86.153.116&t=1 says it became a medium virtual
- dnshistory.org/dns-records/internationalnewsworthiness.com empty
- securitytrails.com/domain/internationalnewsworthiness.com/history/a
sandstormnews.com 2011, SWF Arabic.
ul.rss-items > li.rss-item, split header- viewdns.info/iphistory/?domain=sandstormnews.com
- 68.178.232.99 United States AS-26496-GO-DADDY-COM-LLC 2011-04-04. viewdns.info/reverseip/?t=1&host=68.178.232.99 says big virtual.
- securitytrails.com/domain/sandstormnews.com/history/a
zerosandonesnews.com 2011. SWF Split header,
ul.rss-items > li.rss-item- viewdns.info/iphistory/?domain=zerosandonesnews.com empty
- dnshistory.org/dns-records/zerosandonesnews.com empty
- securitytrails.com/domain/zerosandonesnews.com/history/a says 62.22.61.200 which is in range
differentviewtoday.com: web.archive.org/web/20110202185635/http://differentviewtoday.com/ split header images JAR archived at: web.archive.org/web/20110202185659/http://differentviewtoday.com/bwm.jar
lasthournews.com web.archive.org/web/20100513182623/http://lasthournews.com/. Urdu. JAR at: web.archive.org/web/20100513182724/http://lasthournews.com/recent.jar. Split header images.
- viewdns.info/iphistory/?domain=lasthournews.com no relevant IPs
- dnshistory.org/historical-dns-records/a/lasthournews.com mentions 2010-02-27 -> 2010-08-07 216.93.248.194
- securitytrails.com/domain/lasthournews.com/history/a says
mynepalnews.com, split header images,
ul.rss-items > li.rss-item, Unarchived jar:- viewdns.info/iphistory/?domain=mynepalnews.com
- 5.9.240.230 Falkenstein - Germany Hetzner Online GmbH 2014-01-31
- 142.4.222.67 Canada OVH SAS 2013-12-20
- 72.9.137.7 Nepal WorldLink Communications Pvt Ltd 2013-06-30. Big virtual.
- 64.71.179.79 United States HURRICANE 2012-11-12. Nothing else on 64.71.179.71 - 64.71.179.89.This IP address also shows up on web.archive.org/web/20110204095753/http://mynepalnews.com/cgi-bin/check.cgi/
SERVER_ADDR = 64.71.179.79There we also see:which appears to be the crawler's IP: github.com/duy13/vDDoS-Protection/issues/29REMOTE_ADDR = 204.236.235.245
- securitytrails.com/domain/mynepalnews.com/history/a
- 5.9.219.166 Hetzner Online GmbH 2013-12-31 (11 years) 2014-01-08 (11 years) 8 days
- 142.4.222.67 OVH SAS 2013-12-02 (11 years) 2013-12-31 (11 years) 29 days
- 72.9.137.7 WorldLink Communications Pvt Ltd 2013-01-24 (12 years) 2013-04-02 (12 years) 2 months
- 64.71.179.79 Hurricane Electric LLC 2008-09-01 (17 years) 2008-10-21 (16 years) 2 months
- web.archive.org/web/20111008211517/http://elgintoday.com/ wordpress so unlikely
- 50.63.202.88 United States AS-26496-GO-DADDY-COM-LLC 2014-02-21
- 97.74.249.128 United States AS-26496-GO-DADDY-COM-LLC 2014-01-11 big virtual
Summary: this is just a red herring. Wakatime owner likely registered the domains just after this article was published as a publicity stunt. Fair play though.
As raised at: news.ycombinator.com/item?id=36280666, many, but not all, of the domains currently redirect to wakatime.com/ as of 2023, and apparently they were taken up in 2013 (TODO how to confirm that). TODO what is the explanation for that? Some examples that do:But some failed resolution examples:Even more suspiciously, according to his LinkedIn: www.linkedin.com/in/alanhamlett/, the owner of Wakatime, Alan Hamlett, worked at WhiteHat Security, Inc from Aug 2011 - Sep 2013. The company was then acquired by Synopsys in 2022. Holy crap!!! As shown at: web.archive.org/web/20131013193406/https://www.whitehatsec.com/ that company made website security tools. Did that dude use the tools to find the vulnerabilty and then just gobble up all the domains??? What a fucking legend if he did!!!
Let's try:
Running e.g.gives:so we see that he must have setup redirection with Namecheap as mentioned at: www.namecheap.com/support/knowledgebase/article.aspx/385/2237/how-to-redirect-a-url-for-a-domain/
curl -vvv dedrickonline.com* Trying 162.255.119.197:80...
* Connected to dedrickonline.com (162.255.119.197) port 80 (#0)
> GET / HTTP/1.1
> Host: dedrickonline.com
> User-Agent: curl/7.88.1
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
< Date: Mon, 12 Jun 2023 20:30:19 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 55
< Connection: keep-alive
< Location: https://wakatime.com
< X-Served-By: Namecheap URL Forward
< Server: namecheap-nginx
<
<a href='https://wakatime.com'>Moved Permanently</a>.
* Connection #0 to host dedrickonline.com left intactLet's also try DNS history
- whoisrequest.com/history/:
- tools.whoisxmlapi.com/whois-history-search
- dedrickonline.com:
- CIA (registrar: Godaddy, registrant name: domainsbyproxy.com)
- Created Date: October 27, 2010 00:00:00 UTC
- Updated Date: October 28, 2013 00:00:00 UTC
- Expires Date: October 27, 2014 00:00:00 UTC
- Alan (namecheap):
- CIA (registrar: Godaddy, registrant name: domainsbyproxy.com)
- activegaminginfo.com:
- CIA (Network Solutions, registrant name: LLC. Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions)
- Created Date: January 26, 2010 00:00:00 UTC
- Updated Date: November 27, 2010 00:00:00 UTC
- Expires Date: January 26, 2012 00:00:00 UTC
- Alan:
- CIA (Network Solutions, registrant name: LLC. Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions)
- iraniangoalkicks.com:
- iraniangoals.com:
- CIA (registrar: Godaddy, registrant name: domainsbyproxy.com):
- Reuters:
- Created Date: September 29, 2022 11:16:09 UTC
- Updated Date: September 29, 2022 11:16:09 UTC
- Expires Date: September 29, 2023 11:16:09 UTC
- dedrickonline.com:
So these suggest Alan might have just come along in 2023 way after the 2022 Reuters article and did the same basic IP range search that Ciro is doing now, so possibly no new tech. Let's ask... twitter.com/cirosantilli/status/1668369786865164289
Searching tools.whoisxmlapi.com/reverse-whois-search with term "Corral, Elizabeth" gave no results unfortunately.
Basic search under tools.whoisxmlapi.com/reverse-whois-search for "Corral" also empty. They can't see their own data? Ah, need advanced. Marked "Historic" and selected "Corral, Elizabeth", ony one hit, activegaminginfo.com.
Sources of whois history include:
- whois-history.whoisxmlapi.com/ from whoisXMLAPI. Notably they also have historical reverse WHOIS... tools.whoisxmlapi.com/reverse-whois-search but it needs credits. TODO we need to squeeze this a but further at some point.
When that data comes in JSON format as from whoisXMLAPI, we are going to just dump it in github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/whois.json
The vast majority of domains seem to be registered either via domainsbyproxy.com which likely intgrates with Godaddy and is widely used, and seems to give zero infromation at all about the registrar.
A much smaller number however uses other methods, some of which sometimes leak a little bit of data:Big question: webmasters.stackexchange.com/questions/13237/how-do-you-view-domain-whois-history DomainTools also has it.
- Network Solutions, LLC. These sometimes give a tiny bit of information: one name. Other times they are hidden behind Perfect Privacy, LLC. Examples>Pulley, Tammy
- alljohnny.net: L. Glaze. tools.whoisxmlapi.com/reverse-whois-search "Glaze, L." has
- webstorageforme.com. web.archive.org/web/20130917230604/http://webstorageforme.com/ broken, cqcounter.com/whois/www/webstorageforme.com.html blank
- welcometonyc.net. Hit!
- international-smallbusiness.com. Same IP as alljohnny.net and quite possibly hit..
- alljohnny.com. Hit!
- locateontheweb.com. cqcounter.com/whois/www/locateontheweb.com.html broken/test page
- rolling-in-rapids.com. web.archive.org/web/20111101080224/rolling-in-rapids.com no archives but cqcounter.com/whois/www/rolling-in-rapids.com.html hit style! viewdns.info/iphistory/?domain=rolling-in-rapids.com puts it at:
- 208.91.197.132 British Virgin Islands CONFLUENCE-NETWORK-INC 2014-01-31
- 65.218.91.9 United States UUNET 2013-12-20 so matchwith welcometonyc.com but not listed at viewdns.info/reverseip/?t=1&host=65.218.91.9 because of the viewdns.info reverse IP bug!
- differentviewtoday.com: tools.whoisxmlapi.com/whois-history-search kind of empty no name
but presumably these are the names of employees of the company? We are yet to see two identical names however, which also suggests fake names. Network Solutions appears to offer both hosting and domain registration, and the CIA seems to have used this service combo a lot.- golf-on-holiday.com: Pulley, Tammy. No tools.whoisxmlapi.com/whois-history-search reverse hits.
- intoworldnews.com: Benjamin McGrew. Only that hit for reverse name at tools.whoisxmlapi.com/reverse-whois-search
- magneticfieldnews.com: Sarah Lowell tools.whoisxmlapi.com/reverse-whois-search has 9 domains
- sarahlowell.com: web.archive.org/web/20110208130657/http://sarahlowell.com/ Yoga instructor.
- puppychallengesacademy.com
- sarahlowelldogtraining.com
- puppychallenges.com. web.archive.org/web/20130517151924/http://puppychallenges.com/ wordpress.
- puppychallenges.net
- realwomensduathlon.com. No archives of era: web.archive.org/web/20180808101430/http://realwomensduathlon.com/
- magneticfieldnews.com. Hit.
- highflyingagility.com. Legit? Service offer.
- ropies.com. web.archive.org/web/20111101080224/http://ropies.com/
- medicatechinfo.com: Jason Noll. Has the following hits at tools.whoisxmlapi.com/reverse-whois-search
- dreamschemedesigns.com. Legit
- dreamschemedesigns.net
- aviationturbinesinternational.com. No relevant archives.
- garysluhan.com. Seems legit.
- cjlogic.com: registrar Godaddy (not Network Services!) and contact:This image is his Gmail's current profile image as of 2025: openclipart.org/detail/19437/high-wing-airplane
Noll, Jason noll.jason@gmail.com 104 Southridge Ct. Marthasville, Missouri 63357 United States (660) 441-0780 Fax -- - medicatechinfo.com. Hit.
- health-men-today.com. Hit. Holy fuck it has two hits out of 7!!!
- mydailynewsreport.com: Rebecca Melancon on tools.whoisxmlapi.com/reverse-whois-search:
- rebecca-melancon.com. web.archive.org/web/20180808172531/http://rebecca-melancon.com/ pilates teacher
- swlabuyahome.net
- swlalistmyhome.net
- rebeccaworking4yousite.com
- mylakecharlescityguide.com
- swlalistmyhome.com
- rebeccaworking4you.com
- swlabuyahome.com
- calcasieuhouses.com web.archive.org/web/20111013212502/http://calcasieuhouses.com/. Wordpress. Copyright Rebecca Melancon, Equal Housing Opportunity.
Message from Rebecca
Welcome to Calcasieu Houses! Here you will find not only information about Real Estate in Calcasieu Parish & the Lake Charles area, but also information about the area itself. I am constantly adding content so please check back often. I can help you with relocation, buying, selling, as well as looking for a great restaurant or a new activity to do! There will be information on Lake Charles, Sulphur, Westlake, & Moss Bluff. If you have something you would like to see added to the website, please feel free to contact me!
- mydailynewsreport.com. Hit.
- plugged-into-news.net: Godfrey Hubbard. Searching tools.whoisxmlapi.com/reverse-whois-search for two terms "Godfrey" "Hubbard" gives a small list of 20 domains including plugged-into-news.net. They all appear to have both words in them. Searching just "Hubbard, Godfrey" has only 3 hits:so it seems to match the strings exactly!
- hubbardgodfrey.online
- plugged-into-news.net
- hubbardgodfrey.com
- alljohnny.net: L. Glaze. tools.whoisxmlapi.com/reverse-whois-search "Glaze, L." has
- godaddy without domainsbyproxy.com: a few of the websites are registered in Godaddy without domainsbyproxy. These might be the ones that gives out the most information:
- baocontact.com
How on Earth did did Citizen Labs find what seems to be a DNS fingerprint??? Are there simply some very rare badly registered domains? What did they see!
whoisxmlapi WHOIS history April 11, 2011:Folowed by reuters registration in 2022.
- Created Date: March 6, 2008 00:00:00 UTC
- Updated Date: March 7, 2011 00:00:00 UTC
- Expires Date: March 6, 2014 00:00:00 UTC
- Registrant Name: domainsbyproxy.com.
- Registrant Organization: Domains by Proxy, Inc.
- Registrant Street: 15111 N. Hayden Rd., Ste 160,
- Registrant City: Scottsdale
- Registrant State/Province: Arizona
- Registrant Postal Code: 85260
- Registrant Country: UNITED STATES
- Name servers: NS29.WORLDNIC.COM|NS30.WORLDNIC.COM
whoisrequest.com/history/ mentions:
- 1 Apr, 2008: Domain created*, nameservers added. Nameservers:
- ns1.webhostingpad.com
- ns2.webhostingpad.com
whoisxmlapi WHOIS history March 23, 2011:
whoisrequest.com/history/ mentions:
1 May, 2007: Domain created*, nameservers added. Nameservers:
1 May, 2007: Domain created*, nameservers added. Nameservers:
- ns1.qwknetllc.com
- ns2.qwknetllc.com
whoisxmlapi WHOIS history March 22, 2011:
- Registrar Name: NETWORK SOLUTIONS, LLC.
- Created Date: January 26, 2010 00:00:00 UTC
- Updated Date: November 27, 2010 00:00:00 UTC
- Expires Date: January 26, 2012 00:00:00 UTC
- Registrant Name: Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions
- Registrant Street: PO Box 459
- Registrant City: PA
- Registrant State/Province: US
- Registrant Postal Code: 18222
- Registrant Country: UNITED STATES
- Administrative Name: Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions
- Administrative Street: PO Box 459
- Administrative City: Drums
- Administrative State/Province: PA
- Administrative Postal Code: 18222
- Administrative Country: UNITED STATES
- Administrative Email: xc2mv7ur8cw@networksolutionsprivateregistration.com
- Administrative Phone: 5707088780
- Name servers: NS23.DOMAINCONTROL.COM|NS24.DOMAINCONTROL.COM
whoisxmlapi WHOIS record on April 28, 2011
whoisxmlapi WHOIS record on September 13, 2011
- Registrar Name: NETWORK SOLUTIONS, LLC
- Created Date: February 17, 2010 00:00:00 UTC
- Updated Date: February 17, 2010 00:00:00 UTC
- Expires Date: February 17, 2015 00:00:00 UTC
- Registrant Name: See, Megan|ATTN NOTICIASMUSICA.NET|care of Network Solutions
- Registrant Street: PO Box 459
- Registrant City: PA
- Registrant State/Province: US
- Registrant Postal Code: 18222
- Registrant Country: UNITED STATES
- Administrative Contact
- Administrative Name: See, Megan|ATTN NOTICIASMUSICA.NET|care of Network Solutions
- Administrative Street: PO Box 459
- Administrative City: Drums
- Administrative State/Province: PA
- Administrative Postal Code: 18222
- Administrative Country: UNITED STATES
- Administrative Email: hf3eg77c4nn@networksolutionsprivateregistration.com
- Administrative Phone: 5707088780
- Name Servers: NS45.WORLDNIC.COM|NS46.WORLDNIC.COM
2012:
- Registrant Country: PANAMA
whoisxmlapi WHOIS record on April 17, 2011
Articles were limited to the first 100 out of 120 total. Click here to view all children of Espionage.
Articles by others on the same topic
There are currently no matching articles.