
Mary Lou Jepsen is a prominent American entrepreneur, engineer, and inventor known for her work in the fields of display technology and neuroscience. She has co-founded and held leadership roles in multiple technology firms, and she is particularly recognized for her work with low-cost, high-resolution display technology, which she developed as part of her involvement with One Laptop per Child (OLPC), where she served as the engineering lead for the OLPC project.
In this section we will use the file nodejs/bench_mem.js, tests are run on Node.js v16.14.2 from NVM, Ubuntu 21.10, on Lenovo ThinkPad P51 (2017) which has 32 GB RAM.
Related answer: stackoverflow.com/questions/12023359/what-do-the-return-values-of-node-js-process-memoryusage-stand-for/72043884#72043884
First using
topp from stackoverflow.com/questions/1221555/retrieve-cpu-usage-and-memory-usage-of-a-single-process-on-linux/40576129#40576129 let's observe the memory usage of some baseline cases.For a Node.js infinite loop nodejs/infinite_loop.jsThis gives approximately:
topp infinite_loop.js- RSS: 20 MB
- VSZ: 230 MB
Adding a single hello world to it as in nodejs/infinite_hello.js and running:leads to:We understand that Node.js preallocates VSZ wildly. No big deal, but it does mean that VSZ is a useless measure for Node.js.
topp infinite_hello.js- RSS: 26 MB
- VSZ: 580 MB
Forcing garbage collection as in nodejs/infinite_hello.js brings it down to 20 MB however:
topp node --expose-gc infinite_hello_gc.jsFinally let's see a baseline for which gives initially:but after a few seconds randomly jumps to:so we understand that
process.memoryUsage nodejs/infinite_memoryusage.js:node --expose-gc infinite_memoryusage.js{
rss: 23851008,
heapTotal: 6987776,
heapUsed: 3674696,
external: 285296,
arrayBuffers: 10422
}{
rss: 26005504,
heapTotal: 9084928,
heapUsed: 3761240,
external: 285296,
arrayBuffers: 10422
}First a baseline case with an array of length 1:This gives the same results as with:
node --expose-gc bench_mem.js n 1node --expose-gc infinite_memoryusage.js. The same result is obtained by doing:a = undefinednode --expose-gc bench_mem.js deallocIf we use we see that the memory is now, unsurprisingly, accounted for under Results for different N:We see therefore that typed arrays are much closer to what they advertise (4 bytes per element), even for smaller element counts, as expected.
Int32Array typed array buffers instead of a simple Array:node --expose-gc bench_mem.js array-buffer n NarrayBuffers, e.g. for N 1 million:{
rss: 31776768,
heapTotal: 6463488,
heapUsed: 3674520,
external: 4285296,
arrayBuffers: 4010422
}|| N
|| `arrayBuffers`
|| `rss`
|| `rss` per elem
| 1 M
| 4 MB
| 31 MB
| 5
| 10 M
| 40 MB
| 67 MB
| 4.6
| 100 M
| 40 MB
| 427 MB
| 4Now let's try one million objects of type gives:Disaster! Memory usage is up to 70 MB! Why?? We were expecting only about 24, 4 baseline + 2 * 10 for each million int?!
{ a: 1, b: -1 }:node --expose-gc bench_mem.js obj{
rss: 138969088,
heapTotal: 105246720,
heapUsed: 70103896,
external: 285296,
arrayBuffers: 10422
}And now an equivalent version using gives the same result.
class:node --expose-gc bench_mem.js classLet's try Array:is even worse at 78 MB!! OMG why.
node --expose-gc bench_mem.js arr{
rss: 164597760,
heapTotal: 129363968,
heapUsed: 78117008,
external: 285296,
arrayBuffers: 10422
}How Plate Tectonics was Discovered (1970)
Source. Produced by Simon Campbell-JonesThe inaugural that predicted the Josephson effect.
Published on Physics Letters, then a new journal, before they split into Physics Letters A and Physics Letters B. True Genius: The Life and Science of John Bardeen mentions that this choice was made rather than the more prestigious Physical Review Letters because they were not yet so confident about the results.
It is called "AC effect" because when we apply a DC voltage, it produces an alternating current on the device.
By looking at the Josephson equations, we see that a positive constant, then just increases linearly without bound.
Wikipedia mentions that this frequency is , so it is very very high, so we are not able to view individual points of the sine curve separately with our instruments.
Also it is likely not going to be very useful for many practical applications in this mode.
An I-V curve can also be seen at: Figure "Electron microscope image of a Josephson junction its I-V curve".
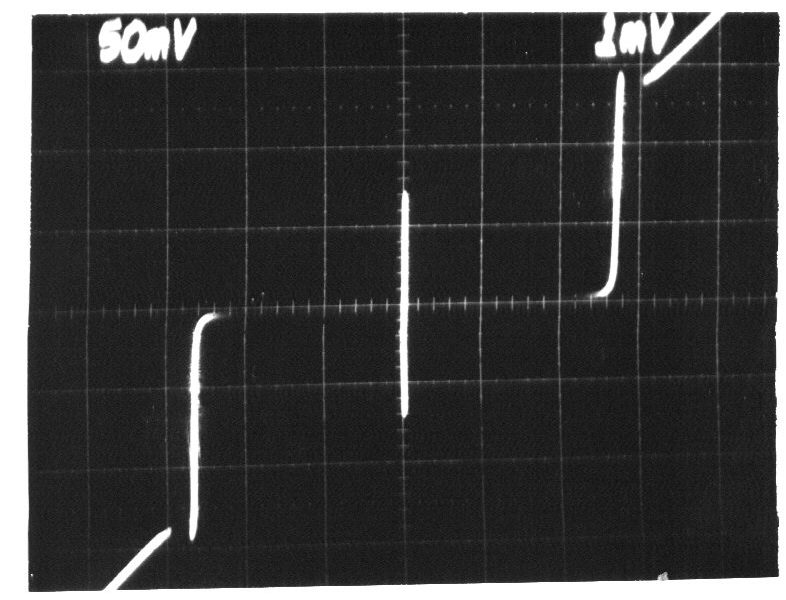
I-V curve of the AC Josephson effect
. Source. Voltage is horizontal, current vertical. The vertical bar in the middle is the effect of interest: the current is going up and down very quickly between , the Josephson current of the device. Because it is too quick for the oscilloscope, we just see a solid vertical bar.
Superconducting Transition of Josephson junction by Christina Wicker (2016)
Source. Amazing video that presumably shows the screen of a digital oscilloscope doing a voltage sweep as temperature is reduced and superconductivity is reached.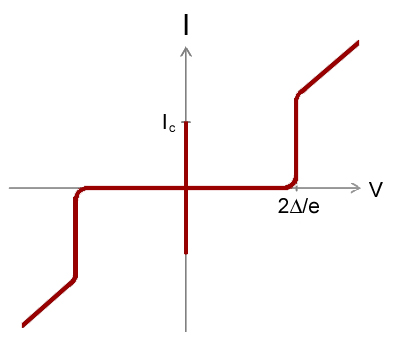
To run examples on a specific database:All examples can be tested on all databases with:
./index.jsor./index.js l: SQLite./index.js p: PostgreSQL. You must manually create a database calledtmpand ensure that peer authentication works for it
cd sequelize
./testOverview of the examples:
- nodejs/sequelize/index.js: a bunch of basic examples
- nodejs/sequelize/update.js: This file is also where we are storing our expression-foo for now, e.g. how to do stuff like
col1 + col2. Such knowledge can however be used basically anywhere else however, e.g. inASorWHEREclauses, not just inUPDATE. - nodejs/sequelize/count.js: a simplified single-table count example. In practice, this will be usually done together with JOIN queries across multiple tables. Answers: stackoverflow.com/questions/22627258/how-does-group-by-works-in-sequelize/69896449#69896449
- nodejs/sequelize/date.js: automatic date typecasts
- nodejs/sequelize/like.js: LIKE
- nodejs/sequelize/camel_case.js: trying to get everything in the database camel cased, columns starting with lowercase, and tables starting with uppercase. The defaults documented on getting started documentation do uppercase foreign keys, and lowercase non-foreign keys. It's a mess.
- nodejs/sequelize/ignore_duplicates.js: ignore query on unique violation with
ignoreDuplicates: truewhich does SQLiteINSERT OR IGNORE INTOor PostgreSQLON CONFLICT DO NOTHING. Closely related Upsert versions:- Upsert
- nodejs/sequelize/upsert.js:
.upsertselects the conflict column automatically by unique columns. Both SQLite and PostgreSQL doINSERT INTO ON CONFLICT. PostgreSQL usesRETURNING, which was added too recently to SQLite: www.sqlite.org/lang_returning.html - nodejs/sequelize/update_on_duplicate.js:
.bulkCreate({}, { updateOnDuplicate: ['col1', col2'] }. Produces queries analogous to.upsert. This method is cool because it can upsert multiple columns at once. But it is annoying that you have to specify all fields to be updated one by one manually. - stackoverflow.com/questions/29063232/how-to-get-the-id-of-an-inserted-or-updated-record-in-sequelize-upsert/72092277#72092277
- stackoverflow.com/questions/55531860/sequelize-bulkcreate-updateonduplicate-for-postgresql
- Upsert
- nodejs/sequelize/inc.js: demonstrate the
incrementmethod. In SQLite, it produces a statement of type:UPDATE `IntegerNames` SET `value`=`value`+ 1,`updatedAt`='2021-11-03 10:23:45.409 +00:00' WHERE `id` = 3 - nodejs/sequelize/sync_alter.js: illustrates
Model.sync({alter: true})to modify a table definition, answers: stackoverflow.com/questions/54898994/bulkupdate-in-sequelize-orm/69044138#69044138 - nodejs/sequelize/truncate_key.js
- nodejs/sequelize/validation.js: is handled by a third-party library: github.com/validatorjs/validator.js. They then add a few extra validators on top of that.The
args: truething is explained at: stackoverflow.com/questions/58522387/unhandled-rejection-sequelizevalidationerror-validation-error-cannot-create-pr/70263032#70263032 - nodejs/sequelize/composite_index.js: stackoverflow.com/questions/34664853/sequelize-composite-unique-constraint
- nodejs/sequelize/indent_log.js: stackoverflow.com/questions/34664853/sequelize-composite-unique-constraint
- association examples:
- nodejs/sequelize/one_to_many.js: basic one-to-many examples.
- nodejs/sequelize/many_to_many.js: basic many-to-many examples, each user can like multiple posts. Answers: stackoverflow.com/questions/22958683/how-to-implement-many-to-many-association-in-sequelize/67973948#67973948
- ORDER BY include:
- nodejs/sequelize/many_to_many_custom_table.js: many-to-many example, but where we craft our own table which can hold extra data. In our case, users can like posts, but likes have a integer weight associated with them. Related threads:
- nodejs/sequelize/many_to_many_same_model.js: association between a model and itself: users can follow other users. Related:
- nodejs/sequelize/many_to_many_same_model_super.js
- nodejs/sequelize/many_to_many_super.js: "Super many to many": sequelize.org/master/manual/advanced-many-to-many.html This should not exist and shows how bad this library is for associations, you need all that boilerplate in order to expose certain relationships that aren't otherwise exposed by a direct
hasManywith implicit join table.
- nested includes to produce queries with multiple JOIN:
- nodejs/sequelize/nested_include.js: find all posts by users that a given user follows. Answers: stackoverflow.com/questions/42632943/sequelize-multiple-where-clause/68018083#68018083
- nodejs/sequelize/nested_include_super.js: like nodejs/sequelize/nested_include.js but with a super many to many. We should move this to nodejs/sequelize/many_to_many_super.js.
- two relationships between two specific tables: we need to use
as:to disambiguate them- nodejs/sequelize/many_to_many_double.js: users can both follow and like posts
- nodejs/sequelize/one_to_many_double.js: posts have the author and a mandatory reviewer
- hooks
- internals:
- nodejs/sequelize/common.js: common utilities used across examples, most notably:
- to easily setup different DBRM
- nodejs/sequelize/min_nocommon.js: to copy paste to Stack Overflow
- nodejs/sequelize/min.js: template for new exapmles in the folder
- nodejs/sequelize/common.js: common utilities used across examples, most notably:
Pinned article: Introduction to the OurBigBook Project
Welcome to the OurBigBook Project! Our goal is to create the perfect publishing platform for STEM subjects, and get university-level students to write the best free STEM tutorials ever.
Everyone is welcome to create an account and play with the site: ourbigbook.com/go/register. We belive that students themselves can write amazing tutorials, but teachers are welcome too. You can write about anything you want, it doesn't have to be STEM or even educational. Silly test content is very welcome and you won't be penalized in any way. Just keep it legal!
Intro to OurBigBook
. Source. We have two killer features:
- topics: topics group articles by different users with the same title, e.g. here is the topic for the "Fundamental Theorem of Calculus" ourbigbook.com/go/topic/fundamental-theorem-of-calculusArticles of different users are sorted by upvote within each article page. This feature is a bit like:
- a Wikipedia where each user can have their own version of each article
- a Q&A website like Stack Overflow, where multiple people can give their views on a given topic, and the best ones are sorted by upvote. Except you don't need to wait for someone to ask first, and any topic goes, no matter how narrow or broad
This feature makes it possible for readers to find better explanations of any topic created by other writers. And it allows writers to create an explanation in a place that readers might actually find it.
Figure 1. Screenshot of the "Derivative" topic page. View it live at: ourbigbook.com/go/topic/derivativeVideo 2. OurBigBook Web topics demo. Source. - local editing: you can store all your personal knowledge base content locally in a plaintext markup format that can be edited locally and published either:This way you can be sure that even if OurBigBook.com were to go down one day (which we have no plans to do as it is quite cheap to host!), your content will still be perfectly readable as a static site.
- to OurBigBook.com to get awesome multi-user features like topics and likes
- as HTML files to a static website, which you can host yourself for free on many external providers like GitHub Pages, and remain in full control

Figure 3. Visual Studio Code extension installation.
Figure 4. Visual Studio Code extension tree navigation.
Figure 5. Web editor. You can also edit articles on the Web editor without installing anything locally.Video 3. Edit locally and publish demo. Source. This shows editing OurBigBook Markup and publishing it using the Visual Studio Code extension.Video 4. OurBigBook Visual Studio Code extension editing and navigation demo. Source. 
- Infinitely deep tables of contents:


{kind=link}
{kind=link}
All our software is open source and hosted at: github.com/ourbigbook/ourbigbook
Further documentation can be found at: docs.ourbigbook.com
Feel free to reach our to us for any help or suggestions: docs.ourbigbook.com/#contact