
abcmidi Updated 2025-07-16
ABC notation Updated 2025-07-16
Standard from 2011: abcnotation.com/wiki/abc:standard:v2.1
No bend/vibratto/slides :-(
Multitrack volatile: abcnotation.com/wiki/abc:standard:v2.1#multiple_voices
Abelian an non abelian anyons Updated 2025-07-16
Abelian anyon Updated 2025-07-16
Key physical experiment: fractional quantum Hall effect.
Abelian group Updated 2025-07-16
Abel-Ruffini theorem Updated 2025-07-16
Aberration (astronomy) Updated 2025-07-16
Abhidhamma Pitaka Updated 2025-07-16
Abing Updated 2025-07-16
Once Ciro Santilli played Suwu herding sheep while his mother in law was around, and she quickly pointed out:He's very popular!
Suwu by Abing!

Abrahamic religion Updated 2025-07-16
It is just mind blowing that Christians, Muslims and Jews can have so many conflicts considering that their religions are basically the same. Uncanny valley comes to mind. See also remarks at: cirosantilli.com/china-dictatorship/zhong-gong
The transfiguration of Jesus is a notable example where Jesus/the Church tries to divert older religions into him. And then Muhammad does the same during isra and Mi'raj, and meets up with Jesus, John the Baptist and Abraham. The Kaaba was also clearly an earlier place of worship of local religions before Muhammad. But of course, Abraham was one of the builders of the Kaaba, so all good.
Abraham Pais Updated 2025-07-16
This due is a beast, he knows both the physics and the history of physics, and has the patience to teach it. What a blessing: Section "How to teach and learn physics".
Abraham Pais Prize for History of Physics Updated 2025-07-16
Absorbing Markov chain Updated 2025-07-16
Absorption (electromagnetic radiation) Updated 2025-07-16
Absorption, spontaneous and stimulated emission Updated 2025-07-16
Abstract algebra Updated 2025-07-16
Abstract syntax tree Updated 2025-07-16
AC adapter Updated 2025-07-16


{kind=link}
{kind=link}
{kind=link}
Academia Updated 2025-07-16
Academia is broken Updated 2025-07-16
Sometimes Ciro Santilli regrets not having done a PhD. But this section makes him feel better about himself. To be fair, part of the merit is on him, part of the reason he didn't move on was the strong odour of bullshit oozing down to Masters level. A good PhH might have opened interesting job opportunities however, given that you don't really learn anything useful before that point in your education.
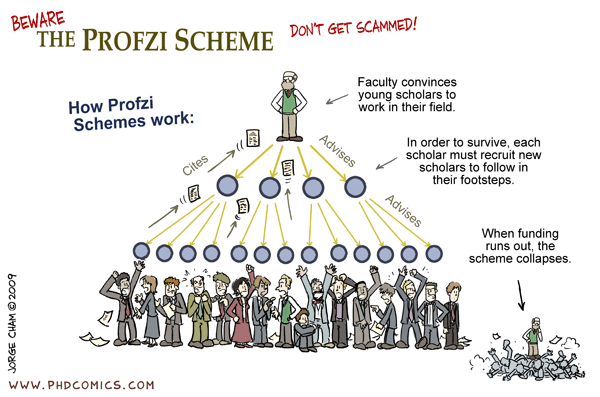
Profzi scheme by PhD Comics
. A Ponzi scheme that trains people in new skills is not necessarily a terrible thing. It is a somewhat more useful version than standard exam based education.
Perhaps the problem is "forcing" 35 year olds to go down that path when they might also want to have boring stuff like families and security.
If people could get to the PhD level much, much sooner, it wouldn't be as obscene: Section "Students must be allowed to progress as fast as they want".
There are unlisted articles, also show them or only show them.