
Incoming links: Wayback Machine
This is an update to the article: Section "CIA 2010 covert communication websites"
Most websites were boring as usual, but one was slightly cooler: webofcheer.com is a comedy fansite featuring Johnny Carson, Charles Chaplin, Rowan Atkins (of Mr. Bean fame), The Three Stooges and some other Americans no one knows about anymore. There must have been a massive Johnny Carson amongst the contractors at that time, given that we previously also knew about
alljohnny.com, a site dedicated fully to him! Both of these sites also serve as some of the earliest examples we've got so far, dating back to 2004 and 2005.
2011 Wayback Machine archive of webofcheer.com
. Source. 
2011 Wayback Machine archive of webofcheer.com scrolled to show Johnny Carson
. Source. 
2004 Wayback Machine archive of alljohnny.com
. Source. This one was a previously known website featuring Johnny Carson.Another cool discovery is that I found the Getty Images source of the Jedi boy on their Star Wars themed site starwarsweb.net: web.archive.org/web/20101230033220/http://starwarsweb.net/ The photo can still be licensed today as of 2025: www.gettyimages.co.uk/detail/photo/little-jedi-royalty-free-image/172984439. I found it by searching for "jedi boy" on gettyimages.co.uk. The photo is credited to username
madisonwi, presumably an alias of a photographer from Madison, Wisconsin. Inspired by this I reverse image searched and found the source of many other stock images from other websites, and I pinged their authors whenever I could locate them e.g. x.com/cirosantilli/status/1899750172260806711.
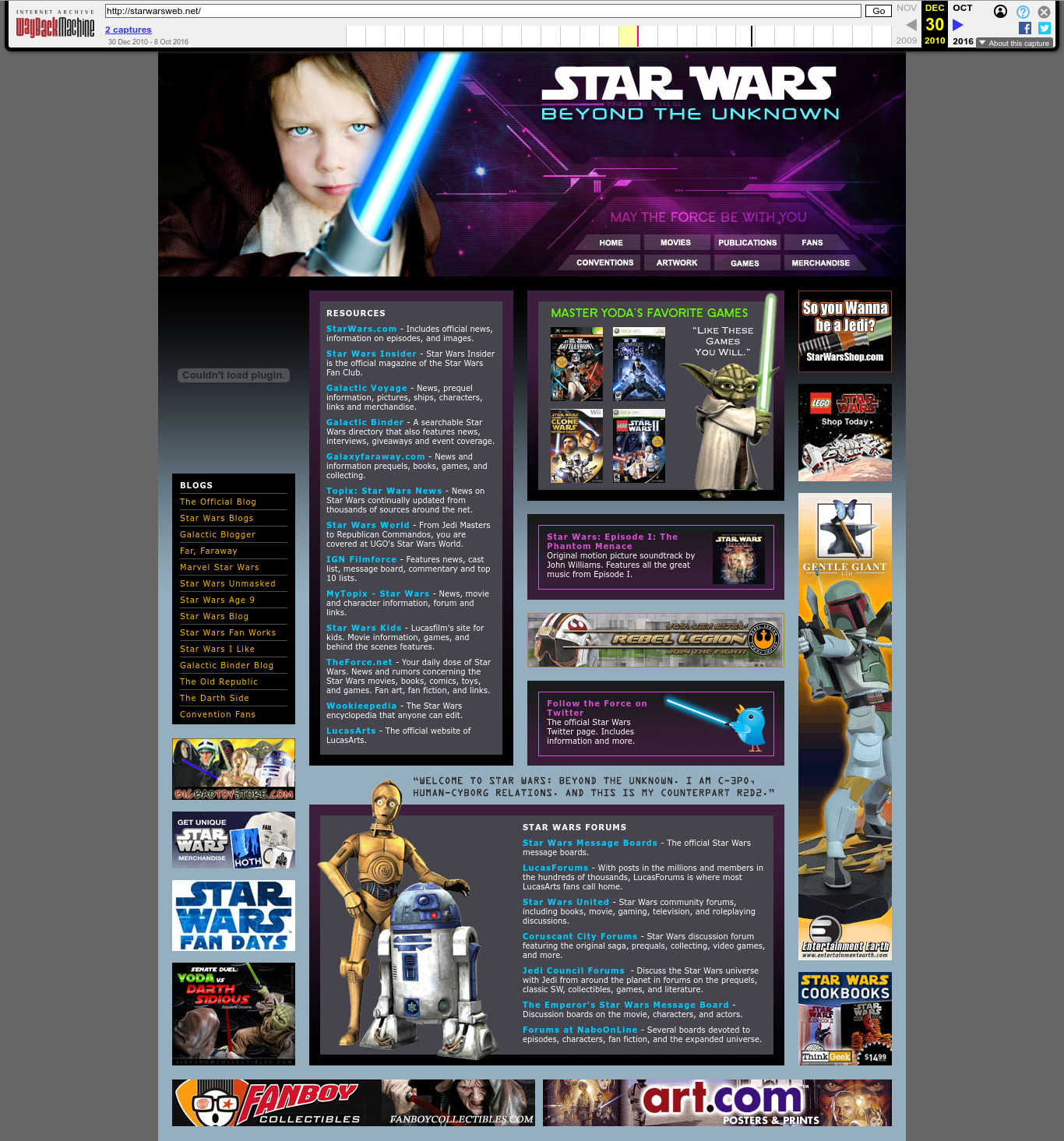
2010 Wayback Machine archive of starwarsweb.net
. There were two small advances that led to the discovery of new domains:
- while looking for a way to procrastinate I decided to scrape justdropped.com/drops/ for fun. That website lists expired domain names and see if it would yield any new results.I had already scrapped other expired domain websites before and used that data, and I hoped that this one would provide some new domain hits, even though it had very large overlap with the other websites I had scraped domains from previously.Such domain name lists tend to contain all SCAM domains in existence, since those inevitably expire once the scammers are caught.
- even more importantly, I noticed by chance that I was being too strict on a small part of my fingerprinting which was excluding a few good domains, by removing any hits that had multiple archives of the Communication mechanism
With those two new developments, I then kicked off my pre-existing search pipelines searching for domain names with the word
news on them, an amazingly efficient heuristic because many of the websites were disguised as news aggregators, and after a few hours theses new hits emerged. A few of those also led to the discovery of new IPs which then led to new domains.One entirely new IP range was found around fastnews-online.com from 208.93.112.105 to 208.93.112.125. There were many domain names with very promising names in the range, but unfortunately for some reason most didn't have Wayback Machine Archives so I didn't count them as hits as per my guidelines.

2009 Wayback Machine archive of fastnews-online.com
. Also the newly found todaysengineering.com at 208.254.38.39 appears to form an IP range with the previously known nejadnews.com at 208.254.38.56, but I couldn't find any other domains in the region with our current data sources.

2011 Wayback Machine archive of todaysengineering.com
. All other domains either slot into previously known IP ranges, or more commonly don't currently have a known IP, though they would likely just slot in existing ranges if we had better data.
Thanks to Jack Rhysider from the Darknet Diaries podcast for pointing me to the existing of the 2022 Reuters article that kickstarted my research on the subject!
One outcome of this update is that I've increased my jq level to better automate the maintenance of the hits.json file were I store all the known websites in JSON format. I love that tool so much, I managed to merge two JSONs with it removing duplicates and then sort the JSON as desired. Beauty.
The full list of newly found websites is:
- cellar-notes.com
- dailywellnessnews.com
- differentviewtoday.com
- dryterrainnews.com
- euronewsonline.net
- fastnews-online.com
- financecentraltoday.com
- globalcitizennews.net
- globalinvestmentnews.net
- inkfreenews.com
- internationalnewsworthiness.com
- intoworldnews.com
- lasthournews.com
- latinamericanewsbeat.com
- localtoglobalnews.com
- magneticfieldnews.com
- middle-east-newstoday.com
- mideasttoday.net
- mydailynewsreport.com
- mynepalnews.com
- nbanewsroundup.com
- nejadnews.com
- networkconnectionsite.com
- news-and-sports.com
- newsdelivered.net
- pondernews.net
- profile-news.com
- purlicue-news.com
- sandstormnews.com
- segomonews.com
- shadesofnews.com
- technologypresstoday.com/
- the-news-scene.com
- thefootball-life.com
- thefreshnews.com
- thenewsofpakistan.com
- totallynewsnow.com
- travelxtreme.net
- webofcheer.com
- wiredworldnews.com
- world-news-online.net
- worldaroundyunnan.com
- worldofonlinenews.com
Announced at:
- mastodon.social/@cirosantilli/114156495883418926
- x.com/cirosantilli/status/1900249928653271334
- www.facebook.com/cirosantilli/posts/pfbid02LbrfezGmFik582d6H7ZEoCf9bwpU73vyivdGLVbbzWjejWLS5Rv9EjGNXBPQppUBl
- www.linkedin.com/posts/cirosantilli_httpslnkdineyu8qwc-i-found-44-new-covert-activity-7306015949374058496-X5zl/
Updates 60 new CIA website screenshots discovered on CQ Counter New IP ranges established Created 2025-04-15 Updated 2025-07-16
I have come to realize that a few of the websites do seem to use virtual hosting, i.e. multiple domains per IP, and I put a bit more manual effort into looking at known possible IPs that had a relatively small number of domains in them.
This led either to finding a few new domains, or placing existing domains in the same IP as another domains.
From now on I'll consider any IP with more than two hits to be an "IP range".
The new finds around other pre-existing domains are:
- 199.19.110.7 (theworldnewsfeeds.com):
- 207.150.191.68 (technologypresstoday.com)
- 216.93.248.194 (esmundonoticias.com)
- 216.104.38.110 (all-sport-headlines.com)
Furthermore, I now found new hits on nearby IPs of 209.162.192.49 rastadirect.net which was given by Reuters, thus establishing a new IP range there. Apparently I had simply failed to check IPs around one of the possible reverse IPs for it. The new finds are:
- 209.162.192.44 thejewelofsouthamerica.com
- 209.162.192.51 yellow-chair-report.com
- 209.162.192.57 globalnewsreports.net
- 209.162.192.59 easytravelsite.net

2010 Wayback Machine archive of thejewelofsouthamerica.com
. Source. Updates 60 new CIA website screenshots discovered on CQ Counter Possible cute internal information leaks on a few sites Created 2025-04-15 Updated 2025-07-16
216.105.98.132 europeantravelcafe.com is a very likely hit that:This suggests that this was an internal site management link for the site operators which was later noticed and removed across versions, leaking the management method in the process.
- had a "Plan Your Trip" link in 2010: web.archive.org/web/20100724024623/http://www.europeantravelcafe.com/ linking to an external website: secure-cert.net/~etc/transport.html
- and had the link removed in 2011: web.archive.org/web/20110201192245/http://europeantravelcafe.com/
2010 Wayback Machine archive of www.europeantravelcafe.com
. Source. The suspicious "Plan Your Trip" link that was later removed is highlighted with an arrow made by us.199.187.208.12 webofcheer.com has an exceedingly weird HTML page title:which feels like it could be a leak of an internal identifier for this website, or perhaps even worse, for the CIA program itself.
pg1c
Updates Backing up CIA website archives for research and posterity Created 2025-05-23 Updated 2025-10-27
I've downloaded and uploaded copies of the archives of the CIA websites as follows:
- all cqcounter screenshots where cqcounter was the best source to: github.com/cirosantilli/media/tree/master/cia-2010-covert-communication-websites/screenshots/cqcounter. That commercial website does not inspire much trust, e.g. now the main pages like cqcounter.com/site/internationalwhiskylounge.com.html were giving an error:so I'm glad to have saved their precious screenshots at a safer place.
[1114: The table 'access' is full] ( 1114 : The table 'access' is full ) - all Wayback Machine archives to: github.com/cirosantilli/cia-2010-websites-dump. The exports were done with github.com/StrawberryMaster/wayback-machine-downloader by Felipe x.com/opapeldetrouxa which is an up-to-date fork of github.com/hartator/wayback-machine-downloader and the tool seemed to work very well. I've also edited that better working fork at the top answer of: superuser.com/questions/828907/how-to-download-a-website-from-the-archive-org-wayback-machine/957298#957298
The cqcounter screenshots don't offer too much information, but having the wayback machine ones could actually reveal new fingerprints and other website information leaks.
Starting December 2004, the "Submit your favored carlson quote" of alljohnny.com was mind blowingly switched to point to https://washington.serversecured.net/~alljohnn/cgi-bin/memlog.cgi thus likely leaking the control site URL. Beauty. It previously pointed to web.archive.org/web/20040901162621/https://secure.alljohnny.com/cgi-bin/memlog.cgi
mynepalnews.com actually has several archives for a /stats path which contains HTML reports generated by Webalizer, an analytic tracker that tracks the source of incoming traffic!!! It is hard to believe that the CIA would have left that there. Particularly ridiculous is the presence of
inurl:cgi server_software at web.archive.org/web/20110204095809/http://mynepalnews.com:80/stats/usage_200805.html which is almost certainly a Google dork search, which we know is something that the Iranians used to find the websites. That search hits under /cgi-bin/check.cgi. That page is itself os some interest containing SERVER_ADMIN = mmadev@mmadev.com. web.archive.org/web/20110204095815/http://mynepalnews.com:80/stats/usage_200806.html also reveals several request IPs. Even if this is not a CIA website, there's a chance we could find the IP of the Iranian counter-intelligence in these IP list, it's mind blowing. There's lots of referrer spam too as well. Further HTML inspection however seems to show close relationship to that HTML and other confirmed hits.globaltourist.net, if is actually a hit, likely has a a 2003 archive, which would be our earliest hit archive so far.
A fun fact is that looking at the source code of: web.archive.org/web/20130828122833/http://euronewsonline.net/euro_bus.php we noticed an interesting comment:which clarifies that the CIA likely used Adobe ImageReady to cut up the images for Split header images:We also understand that the tool likely outputs the layout to HTML directly, and leaks the adobe projects filenames (.pds files) in the process.
<!-- ImageReady Slices (enewsweather.psd) -->Adobe ImageReady was a bitmap graphics editor that was shipped with Adobe Photoshop for six years. It was available for Windows, Classic Mac OS and Mac OS X from 1998 to 2007. ImageReady was designed for web development and closely interacted with Photoshop
Updates Link to CIA website autism-news.org found on Wikipedia from back in 2011 Created 2026-06-14 Updated 2026-06-14 2026-06-14
Imagine that it is 2011 and you are editing the linked to it back in 2011 in a Talk of the "Causes of autism" Wikipedia page. You are researching about the far fetched theory that it was Neanderthal mixture with earlier humans which led to the appearance of autism. You Google it up and list some links. One of them happens to be
autism-news.org. This is how it would have looked like at the time according to archive.org. You mark it as "non-legitimate" and move on.And imagine that, unknown to you however, this page was actually created by CIA employees as of of many to allow their agents to communicate information back to the CIA! These pages would later be discovered by the target countries such as China and Iran, leading to the imprisonment and execution of many agents!
Well, this is exactly what happened to Wikipedia user Slartibartfastibast!
After the revelations of CIA 2010 covert communication websites, security researcher Ellie intentionally registered the domain autism-news.org, and she found out that Wikipedia Slartibartfastibast had linked to it back in 2011 in a Talk of the "Causes of autism" page discussing the legitimacy of the "Neanderthal Admixture Hypothesis".
Ellie created a Accidentally found a CIA covert communications website badge for them which his exceedingly cute.
Attempts to reach Slartibartfastibast to ask how he found the website failed, x.com/Slartibartfas12 is a possible account, and there is also a known similar Gmail address from a data leak which might match.
It is almost certain that they just happened to find the website while Googling for it, since we know that the websites were Googleable because it has been reported that the Iranians used Google dorking to find some of them.[ref] This is presumably because Google had access to zone files, which are big dumps of registered domains that some registrars make available to some organizations.
Ciro Santilli subsequently searched for any more hits of the Websites on the Wikipedia dumps by grepping gives a few dozen hits, all legit. The next step would be to try and download full Wikipedia history for the period, but that would require more patience and would likely not yield anything of much interest either.
enwiki-latest-externallinks.sql which contains all live external links outgoing from Wikipedia. The only two hits were autism-news.org itself and inkfreenews.com which became a legitimate local news website for Northern Indiana as early as 2013. Inspection of:grep -Po "inkfreenews.*?'.*?'.*?'" enwiki-latest-externallinks.sqlIt is understandable why
autism-news.org is would be one of the few websites most prone to being randomly Googled: unlike most websites which are quite generic news aggregator websites, this one contains a surprising amount of text. Much like the Star Wars website starwarsweb.net, we would like to think that the contractor who made this one up actually put their hearts into it, and might have had a real personal interest in the matter. The quotes about Neanderthal Admixture Hypothesis are in the Causes subpage:The Neanderthal Theory is that autism and other psychiatric conditions evolved from interbreeding between Homo Sapiens and Neanderthals. This interbreeding is believed to have caused genetic material from the Neanderthals to enter the Homo Sapiens genome. Whether such interbreeding ever actually occurred is controversial, and this theory is extremely speculative.
The username "Slartibartfastibast" seems to be a variation of Slartibartfast, a character from The Hitchhiker's Guide to the Galaxy who according to Gemini is a:So it's probably an autistic dude from the UK. Their Wiki homepage says simply however:and as of writing their latest contribution was from 2014 and they are typical STEM nerd based on their edits.
venerable "planetary designer" from the planet Magrathea, most famously known for his award-winning work designing coastlines and his deep, personal passion for creating fjords

2011 Wayback Machine archive of autism-news.org
. Source. vistomail.com Updated 2025-07-16
2023-11-17 bitcointalk.org/index.php?topic=5478677.0 "I Bought vistomail.com. Now What?" Restricted topic, but Google caught it: archive.ph/wip/dDxqi The message:
I am dedicating the next few months, and perhaps even years, to researching Satoshi Nakamoto and the intricacies of blockchain technology. About four weeks ago, I came across vistomail.com for sale on afternic.com and decided to purchase it. I added vistomail.com to my proton.me account and configured it to catch all emails. As a result, numerous emails started flowing in. Subsequently, I connected satoshi@vistomail.com and discovered significant information that I am excited to share with you in the coming months.To be clear, I want to emphasize that I am not Satoshi Nakamoto. My interest lies in understanding the future plans for Bitcoin and its impact on the world. I invite you to join me on this journey, contributing your knowledge to the collective understanding. I believe there is a possibility of uncovering the ultimate treasure, and I am eager to share it with all of you.twitter @alexelbanna
2023-11-17, 06:46:25 PM. bitcointalk.org/index.php?topic=5474482.0 vistomail.com for sale, Restricted topic, but Google caught it: archive.ph/wip/GARBy The message:
Email address: satoshi@vistomail.com$50,000 obo for vistomail.com. Buy Now: www.afternic.com/listings/778206How it would be of value:You would open a proton.me account add domain vistomail.com. Then you create an address such as: satoshi@vistomail.com and the you can set the domain to a catch all address. All satoshi@vistomail.com emails will come into your inbox. All emails from @vistomail.com going to vistomail.com will now be in your inbox.BUY NOW: www.afternic.com/listings/778206See other domains Satoshi Nakamoto owned here: www.afternic.com/listings/778206Michael Weber
Domain Registrar
mweber@dosidos.net
They updated the page to a more scammy one as of 2024: web.archive.org/web/20240310205138/https://www.vistomail.com/ mentioning x1coin.org. But still Alex no doubt: twitter.com/AlexElbanna/status/1763575552538001530 | github.com/bLeYeNk
As of 2024-04-10, it was now a Ghost blogging intance still by Alex: www.vistomail.com/articles-coming-soon/ He added Ciro Santilli as a collaborator, but Ciro could only draft articles which Alex could then review. He allowed a cheeky link to OurBigBook.com in: archive.ph/8l6az epic. Let's see if it gives traffic!
www.vistomail.com/non-profits/ claims they were giving out grants via satoshin@nt-medic.com and provided address 1BCwUg3PsLK9wJK815RkmzSMdAnALNHu64

Wayback Machine archive of www.vistomail.com/Default.aspx on 2013-12-09
. Source.