
Incoming links: Wayback Machine
Home Updated 2026-05-30
Check out: OurBigBook.com, the best way to publish your scientific knowledge. It's an open source note taking system that can publish from lightweight markup files in your computer both to a multi-user mind melding dynamic website, or as a static website. It's like Wikipedia + GitHub + Stack Overflow + Obsidian mashed up. Source code: github.com/ourbigbook/ourbigbook.
Sponsor me to work on this project. For 1M USD I will quit my job and work on OurBigBook full time for three more years to try and kickstart The Higher Education Revolution. Status: ~44k / 400k USD. At 4M USD I retire/tenure and work on open STEM forever. How to donate: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
I first quit my job 1st June 2024 to work on the project for 1 year after I reached my initial 100k goal mostly via a 1000 Monero donation.
Mission: to live in a world where you can learn university-level mathematics, physics, chemistry, biology and engineering from perfect free open source books that anyone can write to get famous. More rationale: Section "OurBigBook.com"
Explaining things is my superpower, e.g. I was top user #39 on Stack Overflow in 2023[ref][ref] and I have a few 1k+ star educational GitHub repositories[ref][ref][ref][ref]. Now I want to bring that level of awesomeness to masters level Mathematics and Physics. But I can't do it alone! So I created OurBigBook.com to allow everyone to work together towards the perfect book of everything.
My life's goal is to bring hardcore university-level STEM open educational content to all ages. Sponsor me at github.com/sponsors/cirosantilli starting from 1$/month so I can work full time on it. Further information: Section "Sponsor Ciro Santilli's work on OurBigBook.com". Achieving what I call "free gifted education" is my Nirvana.
This website is written in OurBigBook Markup, and it is published on both cirosantilli.com (static website) and outbigbook.om/cirosantilli (multi-user OurBigBook Web instance). Its source code is located at: github.com/cirosantilli/cirosantilli.github.io and also at
cirosantilli.com/_dir and it is licensed under CC BY-SA 4.0 unless otherwise noted.To contact Ciro, see: Section "How to contact Ciro Santilli". He likes to talk with random people of the Internet.
GitHub | Stack Overflow | LinkedIn | YouTube | Twitter | Wikipedia | Zhihu 知乎 | Weibo 微博 | Other accounts

Besides that, I'm also a freedom of speech slacktivist and recreational cyclist. I like Chinese traditional music and classic Brazilian pop. Opinions are my own, but they could be yours too. Tax the rich.
Let's create an educational system with:
- no distinction between university and high school, students just go as fast as they can to what they really want without stupid university entry exams
- fully open source learning material
- on-demand examinations that anyone can easily take without prerequisites
- granular entry selection only for space in specific laboratories or participation in specific novel research projects
I offer:
- online private tutoring for:
- any STEM university course
- passionate younger STEM students (any age) who want to learn university level material and beyond. Can your kid be the next Fields Medalist or Nobel Prize winner? I'm here to help, especially if you are filthy rich! I focus moving students forward as fast as they want on and on producing useful novel tutorials and results
Let your child be my Emile, and me be their Adolfo Amidei, and let's see how far they can go! I will help take your child:and achieve their ambitious STEM goals!- into the best universities
- into the best PhD programs
- educational consulting for institutions looking to improve their STEM courses
- do you know that course or teacher that consistently gets bad reviews every year? I'll work with the teacher to turn the problem around!
- are you looking to create a consistent open educational resources offering to increase your institutions internationally visibility? I can help with that too.
My approach is to:For minors, parents are welcome to join video calls, and all interactions with the student will be recorded and made available to parents.
- propose interesting research projects. The starting point is always deciding the end goal: Section "Backward design"
- learn what is needed to do the project together with the student(s)
- publish any novel results or tutorials/tools produced freely licensed online, and encourage the student to do the same (Section "Let students learn by teaching", digital garden)
I have a proven track of explaining complex concepts in an interesting and useful way. I work for the learner. Teaching statement at: Section "How to teach". Pricing to be discussed. Contact details at: Section "How to contact Ciro Santilli".
I am particularly excited about pointing people to the potential next big things, my top picks these days are:I am also generally interested in:
- quantum computing
- AGI research, in particular AI code generation, automated theorem proving and robotics
- assorted molecular biology technologies
- 20th century physics, notably AMO and condensed matter
- the history of science, and in particular trying to look at seminal papers of a field

The problem with education by Ciro Santilli
. Source. In this video Ciro Santilli exposes his fundamental philosophy regarding why Education is broken. This philosophy was the key motivation behind the failed OurBigBook Project.Introduction to the OurBigBook Project
. Source. OurBigBook Web topics demo
. Source. The OurBigBook topic feature allows users to "merge their minds" in a "sort by upvote"-stack overflow-like manner for each subject. This is the killer feature of OurBigBook Web. More information at: docs.ourbigbook.com/ourbigbook-web-topics.OurBigBook dynamic article tree demo
. Source. The OurBigBook dynamic tree feature allows any of your headers to be the toplevel h1 header of a page, while still displaying its descendants. SEO loves this, and it also allows users to always get their content on the correct granularity. More information at: docs.ourbigbook.com/ourbigbook-web-dynamic-article-tree.OurBigBook local editing and publishing demo
. Source. With OurBigBook you can store your content as plaintext files in a Lightweight markup, and then publish that to either OurBigBook.com to get awesome multi-user features, or as a static website where you are in full control. More information at: docs.ourbigbook.com/publish-your-content.Top Down 2D continuous game with Urho3D C++ SDL and Box2D for Reinforcement learning by Ciro Santilli (2018)
Source. More information: Section "Ciro's 2D reinforcement learning games". This is Ciro's underwhelming stab at the fundamental question: Can AGI be trained in simulations?. This project could be taken much further.
-------------------------------------
| Force of Will 3 U U |
| --------------------------------- |
| | //////////// | |
| | ////() ()\////\ | |
| | ///_\ (--) \///\ | |
| | ) //// \_____///\\ | |
| | ) \ / / / / | |
| | ) / \ | | / _/ | |
| | ) \ ( ( / / / / \ | |
| | / ) ( ) / ( )/( ) \ | |
| | \(_)/(_)/ /UUUU \ \\\/ | | |
| .---------------------------------. |
| Interrupt |
| ,---------------------------------, |
| | You may pay 1 life and remove a | |
| | blue card in your hand from the | |
| | game instead of paying Force of | |
| | Will's casting cost. Effects | |
| | that prevent or redirect damage | |
| | cannot be used to counter this | |
| | loss of life. | |
| | Counter target spell. | |
| `---------------------------------` |
| l
| Illus. Terese Nelsen |
-------------------------------------Code 1. .
Artist unknown, uploaded December 2014. Part of Section "Cool data embedded in the Bitcoin blockchain" where Ciro Santilli maintains a curated list of such interesting inscriptions.
This was a small project done by Ciro for artistic purposes that received some attention due to the incredible hype surrounding cryptocurrencies at the time. Ciro Santilli's views on cryptocurrencies are summarized at: Section "Are cryptocurrencies useful?".

YellowRobot.jpgJPG image fully embedded in the Bitcoin blockchain depicting some kind of cut material art depicting a yellow robot, inscribed on January 29, 2017.
Ciro Santilli found this image and others during his research for Section "Cool data embedded in the Bitcoin blockchain" by searching for image fingerprints on every transaction payload of the blockchain with a script.
The image was uploaded by EMBII, co-creator of the AtomSea & EMBII upload mechanism, which was responsible for a large part of the image inscriptions in the Bitcoin blockchain.
The associated message reads:This is one of Ciro Santilli's favorite AtomSea & EMBII uploads, as it perfectly encapsules the "medium as an art form" approach to blockchain art, where even non-novel works can be recontextualized into something interesting, here depicting an opposition between the ephemeral and the immutable.
Chiharu [EMBII's Japanese wife] and I found this little yellow robot while exploring Chicago. It will be covered by tar or eventually removed but this tribute will remain. N 41.880778 E -87.629210
2010 Wayback Machine archive of starwarsweb.net
. This website was used as one of the CIA 2010 covert communication websites, a covert system the CIA used to communicate with its assets. More details at: Section "CIA 2010 covert communication websites".
Ciro Santilli had some naughty OSINT fun finding some of the websites of this defunct network in 2023 after he heard about the 2022 Reuters report on the matter, which for the first time gave away 7 concrete websites out of a claimed 885 total found. As of November 2023, Ciro had found about 350 of them.

2010 Wayback Machine archive of noticiasmusica.net
. This is another website that was used as one of the CIA 2010 covert communication websites. This website is written in Brazilian Portuguese, and therefore suggests that the CIA had assets in Brazil at the time, and thus was spying on a "fellow democracy".
Although Snowden's revelations made it extremely obvious to the world that the USA spies upon everyone outside of the Five Eyes, including fellow democracies, it is rare to have such a direct a concrete proof of it visible live right on the Wayback Machine. Other targeted democracies include France, Germany, Italy and Spain. More details at: USA spying on its own allies.
This investigative report by Ciro Santilli was featured on the Daily Mail after 404 Media reported on it in 2025.

Diagram of the fundamental theorem on homomorphisms by Ciro Santilli (2020)
Shows the relationship between group homomorphisms and normal subgroups.
Used in the Stack Exchange answer to What is the intuition behind normal subgroups? One of Section "The best articles by Ciro Santilli".

Spacetime diagram illustrating how faster-than-light travel implies time travel by Ciro Santilli (2021)
Used in the Stack Exchange answer to Does faster than light travel imply travelling back in time?. One of Section "The best articles by Ciro Santilli".
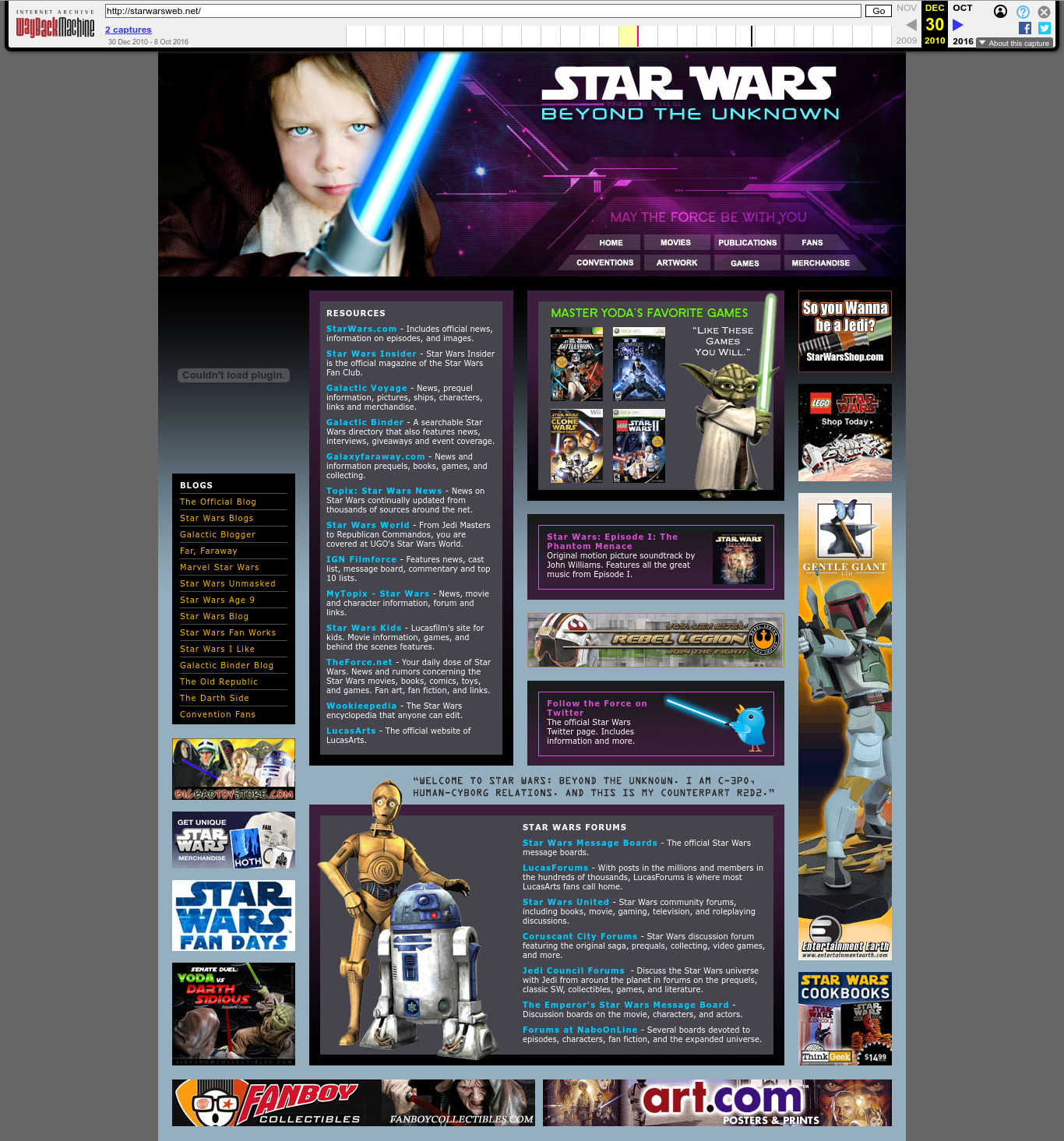
Average insertion time into heaps, binary search tree and hash maps of the C++ standard library by Ciro Santilli (2015)
Source. Used in the Stack Overflow answer to Heap vs Binary Search Tree (BST). One of Section "The best articles by Ciro Santilli".
Top view of an open Oxford Nanopore MinION
. Source. This is Ciro Santilli's hand on the Wikipedia article: en.wikipedia.org/wiki/Oxford_Nanopore_Technologies. He put it there after working a bit on Section "How to use an Oxford Nanopore MinION to extract DNA from river water and determine which bacteria live in it" :-) And he would love to document more experiments like that one Section "Videos of all key physics experiments", but opportunities are extremely rare.A quick 2D continuous AI game prototype for reinforcement learning written in Matter.js, you can view it on a separate page at cirosantilli.com/_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport. This is a for-fun-only prototype for Ciro's 2D reinforcement learning games, C++ or maybe Python (for the deep learning ecosystem) seems inevitable for a serious version of such a project. But it is cute how much you can do with a few lines of Matter.js!
HTML snippet:
<iframe src="_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport" width="1000" height="850"></iframe> Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects Brazil Created 2024-09-06 Updated 2025-07-16
2010 Wayback Machine archive of noticiasmusica.net
. The Brazilian one. Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects France Created 2024-09-06 Updated 2025-07-16
2010 Wayback Machine archive of lesummumdelafinance.com
. A French one. Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects Germany Created 2024-09-06 Updated 2025-07-16

2010 Wayback Machine archive of dedrickonline.com
. The German one. Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects Italy Created 2024-09-06 Updated 2025-07-16

2011 Wayback Machine archive of attivitaestremi.com
. An Italian one about extreme sports. Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects The Star Wars website Created 2024-09-06 Updated 2025-07-16
2010 Wayback Machine archive of starwarsweb.net
. The Star Wars one. Carl Victor Page Updated 2025-07-16
Larry Page's father.
Carl is mentioned in The Google Story Chapter 2 "When Larry Met Sergey".
He divorced from Larry's mother Gloria in 1980 or 1981, "when he [Page] was eight years old" according to The Google Story. He then moved on to Joyce Wildenthal, another MSU professor. Larry had a good relation with both Gloria and Joyce:
Larry came to feel that he was showered with love and wisdom from two mothers: his real mom, and Joyce Wildenthal, a Michigan State professor who had a long-term relationship with his dad.
His obituary on the website of the Michigan State University, where he taught most of his life: www.cse.msu.edu/Alumni_Friends/Alumni/PageMemorial.php:
Page served as CSE’s [MSU Department of Computer Science and Engineering] first graduate director and had a critical role in promoting the department’s research mission. In 1967, when he joined MSU, the computer science program consisted of only undergraduate courses. Just three years later, the department offered eighteen graduate courses in computer science.[...]Page taught courses in Automata and Formal language theory and Artificial intelligence. He was a beloved teacher and mentor to innumerable students until his death in 1996.

Carl Victor Page's obituary by Matt Collar
. Source. Found by Googling into his Wikidata entry: www.wikidata.org/wiki/Q15791098 which cites this random German Wikipedia page: de.wikipedia.org/wiki/Carl_Victor_Page which cites the obituary from this WordPress blog: tao221.wordpress.com/ TODO find the page of the blog that uses that image.

Carl Victor Page Memorial World Wide Web Page
. Source. Another useful hit from tao221.wordpress.com found by... Googling! Contains the best photo of Carl we've found so far. The screenshot seems to be a Ctrl + P of some website, if only the author knew about Wayback Machine! The links on that screenshot would be of interest. The screenshot also mentions other family members:
- Carl B. Page, with a cpsr.org/ email. A brother maybe? www.legacy.com/us/obituaries/detroitnews/name/carl-page-obituary?pid=182235576%26utm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3Dobitsharebeta mentions a Carl B. Page from Michigan who died in 2010.
- Joyce Wildenthal, Carl's partner, with a pilot.msu.edu email. TODO what is
pilot?
Caroline Ulbricht is the wife of Ross Ulbricht, founder of the Silk Road website which allowed users to buy and sell illegal drugs online.
Caroline's maiden name is Caroline Debrion. She is French, and they met soon after Ross was put into jail. The couple married in 2024, one year before Ross' pardon in 2025. Ordinary this girl is not.
Other interesting quotes from the article related to Caroline:
“I dated so many jerks in L.A., and Ross was just very real and just super kind,” she said in 2021, according to a recording of a conversation with an associate obtained by The Times. “Ross is very, very romantic.”Their relationship caused friction in the family. Ms. Ulbricht and Ms. Debrion sometimes butted heads, two people familiar with the women said. Against the wishes of Ms. Ulbricht, who had shielded her son from the media, Ms. Debrion helped persuade Mr. Ulbricht to participate in a Silk Road documentary, a last-ditch effort to sway public opinion.
Ciro Santilli had deduced caroline's maiden name "Caroline Debrion" before the New York Times article by stalking of her online accounts below. Also, her middle name might start with an L giving "Caroline L. Debrion", but this is less certain.
Likely accounts, all of which were live after Ross left prison, but were since taken down tested as of July 2025, including any Wayback Machine archives which are now marked "This URL has been excluded from the Wayback Machine":
- www.linkedin.com/in/carolineld/. Named "Caroline Ulbricht" as of February 2025. Her last employement was as a remote Senior Tech Project Manager / Scrum Master at SiriusXM, a podcast technology company where she was until June 2024. From her feed www.linkedin.com/in/carolineld/recent-activity/all/ she seems to have an interest in computer programming and deeptech which is kind of cool. Many of her LinkedIn posts link to x.com/CrlneD. The "ld" from the LinkedIn username could be her middle name starting with L plus Debrion. Either that or she is a massive fan of the GNU ld linker for some reaso.
- x.com/CrlneD is linked from LinkedIn several times, but is currently suspended. This profile has a 3 archives from 2014 e.g. web.archive.org/web/20140408111206/https://twitter.com/CrlneD under name "Caroline Debrion". This archive was up when this article was originally writen but as of July 2025 is markedso it is possible that they read this article and requested the takedown. Searching Twitter for ther username has many hits on now deleted discdussions related to Ross: x.com/search?q=%22CrlneD%22&src=typed_query. She shas a bit of French stuff going on, maybe she actually has cultural links to France as indicated by her name.
This URL has been excluded from the Wayback Machine.
- www.quora.com/profile/Caroline-Debrion. The archive: archive.ph/VEMHR has a better matching profile image. This is further confirmed by this mispost under the wrong Twitter account: x.com/ClemencyForRoss/status/471408997082603520, linking to one of her Quora answers.
Googling "Caroline Debrion" previously found a: cryptonews.com/fr/exclusives/saga-ross-ulbricht-et-silk-road-scandales-derriere-la-peine-3271/ (archive from January 2025) specificlly describing her in French as "voluntary and projct manager for the website FreeRoss", so that is almost certainly be her maiden name. As of July 2025, her family name "Debrion" had been removed from the article, which is marked "Last updated: June 18, 2025", so they presumably found that article after either reading this article or Googling her and requested the change. She is also quoted in French in that article, but before The spectacular comeback tour of Ross Ulbricht it was unclear if she actually spoke in French or if this was just translated from English. Translation of one of her quotes:
Possibly related profiles but uncertain:
- www.tiktok.com/@carolinel.debrion has an account of a Caroline L. Debrion, with the likely L. middle name.
- github.com/0xbzho/onename/blob/6bb8799767967236a7815b8ee469466639d60b48/c/a/caro.json#L14 a OneName account, a Bitcoin-based identity system linking to her twitter "crlned"
- jira.atlassian.com/secure/ViewProfile.jspa?name=1eba64e21192
- fr.pinterest.com/brahms42/
- www.facebook.com/caroline.ulbricht.3/
Ciro Santilli first found her name mentioned without source at: en.m.wikipedia.org/wiki/File:Ross_Ulbricht_Released_from_Prison_(cropped).jpg. Her first name "Caroline" was given by Ross at: x.com/RealRossU/status/1888299042146578925 on February 8th 2025.
As of 2025 most Google hits currently give "Rebecca Caroline Ulbricht Ferreira" however, an unrelated Brazilian molecular biology researcher from UNICAMP. So a good Google search is
"caroline ulbricht" -Rebecca to remove the overlap. This leads to www.linkedin.com/in/carolineld/ hits.x.com/pete_rizzo_/status/1882489065167356024 has a photo of them hugging at the jail parking lot just after he was released in 2025.


Ross Ulbricht with his wife soon after he was released from jail in 2025 on the road
. Source. 


CIA 2010 covert communication websites Wayback Machine Updated 2025-07-16
D'oh.
But to be serious. The Wayback Machine contains a very large proportion of all sites. It does happen sometime that a Wayback Machine archive is missing or broken and cqcounter has the screenshot. But the Wayback Machine is still the most complete database we have found so far. Some archives are very broken. But those are rare.
The only problem with the Wayback Machine is that there is no known efficient way to query its archives across domains. You have to have a domain in hand for CDX queries: Wayback Machine CDX scanning.
The Common Crawl project attempts in part to address this lack of querriability, but we haven't managed to extract any hits from it.
CDX + 2013 DNS Census + heuristics however has been fruitful however.
We have dumped all Wayback Machine archives of known websites to: github.com/cirosantilli/cia-2010-websites-dump using ../cia-2010-covert-communication-websites/download-websites.sh. This allows for better grepping and serves as a backup in case they ever go down.
Common Crawl Updated 2025-07-16
Amazing project, that basically makes a more searchable Wayback Machine.
A bit hard to use their data though, partly due to size, but also lack of free to use querrying mechanisms, and how obtuse Amazon S3 is to use.
Notably, aws-cli with an account is the only reliable way, everything else is way too broken, e.g. trying the to check the an index index.commoncrawl.org/CC-MAIN-2023-06/ very often 500s.
But still, their projct is amazing.
The only out-of-the-box search they seem to have is: urlsearch.commoncrawl.org/ for domains/URLs. It is good, but there could be so much more... notably IPs.
Sample sizes can be found at: commoncrawl.org/2023/04/mar-apr-2023-crawl-archive-now-available/
To explore the data, after login:
aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2013-20/Copy the toplevel directory only:
aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/ . --recursive --exclude "*/*"Copy some wet/wat files:
aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wat.gz .
aws s3 sync s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz .Directory structrure:
- cc-index.paths.gz (1K)
- cc-index-table.paths.gz (1K)
- segment.paths.gz (1.7K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/ crawl-data/CC-MAIN-2013-20/segments/1368696381630/ - index.html (2.3K)
- wat.paths.gz (98K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wat.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.wat.gz - wet.paths.gz (98K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.wet.gz - warc.paths.gz (99K)
crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.gz - segments: directgory with actual data
- 1368696381249: one of many segments, any meaning of name?
- CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz (142M, 334M unzipped)A tiny bit of metadata, and then plaintext content from the website, e.g. the second one:No IP unfortunately.
WARC/1.0 WARC-Type: conversion WARC-Target-URI: http://004eeb5.netsolhost.com/stephensilver.htm WARC-Date: 2013-05-18T08:11:02Z WARC-Record-ID: <urn:uuid:773b31ba-ddc6-47a5-ae24-d08141b9944d> WARC-Refers-To: <urn:uuid:4b1bdbff-4926-4ced-86f6-072f5bb3837a> WARC-Block-Digest: sha1:LQFSCR2LIJQYMPTXRHWU7HAPQTVSYS3A Content-Type: text/plain Content-Length: 12046 Stephen Silver is a journalist and editor who specializes in the areas of politics, pop culture, film and sports. He works as an editor with the North American Publishing Co. and as a film critic with The Trend, a local newspaper in the Philadelphia area. - A lot of JSON metadata and no contents as desired. Contains IP! Some entries however are humongous with a ton of useless data, that's what bloats these so much:Let's beautify one of them to see it better:
WARC/1.0 WARC-Type: metadata WARC-Target-URI: CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz WARC-Date: 2013-11-22T14:51:12Z WARC-Record-ID: <urn:uuid:ec54e493-8965-41be-b344-07596cc30b3a> WARC-Refers-To: <urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1> Content-Type: application/json Content-Length: 1180 {"Envelope":{"Format":"WARC","WARC-Header-Length":"274","Block-Digest":"sha1:JCZOI4V3UOTXGIRLFMPLW4J2WPLAKGVR","Actual-Content-Length":"372","WARC-Header-Metadata":{"WARC-Type":"warcinfo","WARC-Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz","WARC-Date":"2013-11-22T14:51:12Z","Content-Length":"372","WARC-Record-ID":"<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>","Content-Type":"application/warc-fields"},"Payload-Metadata":{"Trailing-Slop-Length":"0","Actual-Content-Type":"application/warc-fields","Actual-Content-Length":"372","Headers-Corrupt":true,"WARC-Info-Metadata":{"robots":"classic","software":"Nutch 1.6 (CC)/CC WarcExport 1.0","description":"Wide crawl of the web with URLs provided by Blekko for Spring 2013","hostname":"ip-10-60-113-184.ec2.internal","format":"WARC File Format 1.0","isPartOf":"CC-MAIN-2013-20","operator":"CommonCrawl Admin","publisher":"CommonCrawl"}}},"Container":{"Compressed":true,"Gzip-Metadata":{"Footer-Length":"8","Deflate-Length":"453","Header-Length":"10","Inflated-CRC":"866052549","Inflated-Length":"650"},"Offset":"0","Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz"}} WARC/1.0 WARC-Type: metadata WARC-Target-URI: http://%20jwashington@ap.org/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions WARC-Date: 2013-05-18T05:48:54Z WARC-Record-ID: <urn:uuid:d519658f-7a63-46c1-849b-4cd92332ddb8> WARC-Refers-To: <urn:uuid:cefd363b-1fec-4590-8305-4c6fab2e095f> Content-Type: application/json Content-Length: 1501 {"Envelope":{"Format":"WARC","WARC-Header-Length":"433","Block-Digest":"sha1:B2B6JDSGWCUQIIUGV54SXEE25RX4SANS","Actual-Content-Length":"302","WARC-Header-Metadata":{"WARC-Type":"request","WARC-Date":"2013-05-18T05:48:54Z","WARC-Warcinfo-ID":"<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>","Content-Length":"302","WARC-Record-ID":"<urn:uuid:cefd363b-1fec-4590-8305-4c6fab2e095f>","WARC-Target-URI":"http://%20jwashington@ap.org/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions","WARC-IP-Address":"165.1.125.44","Content-Type":"application/http; msgtype=request"},"Payload-Metadata":{"Trailing-Slop-Length":"4","HTTP-Request-Metadata":{"Headers":{"Accept-Language":"en-us,en-gb,en;q=0.7,*;q=0.3","Host":"ap.org","Accept-Encoding":"x-gzip, gzip, deflate","User-Agent":"CCBot/2.0","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"},"Headers-Length":"300","Entity-Length":"0","Entity-Trailing-Slop-Bytes":"0","Request-Message":{"Method":"GET","Version":"HTTP/1.0","Path":"/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions"},"Entity-Digest":"sha1:3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ"},"Actual-Content-Type":"application/http; msgtype=request"}},"Container":{"Compressed":true,"Gzip-Metadata":{"Footer-Length":"8","Deflate-Length":"455","Header-Length":"10","Inflated-CRC":"453539965","Inflated-Length":"739"},"Offset":"453","Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz"}}Fuck no IP addresses either. But other entries do have it, why not this one?{ "Envelope": { "Format": "WARC", "WARC-Header-Length": "274", "Block-Digest": "sha1:JCZOI4V3UOTXGIRLFMPLW4J2WPLAKGVR", "Actual-Content-Length": "372", "WARC-Header-Metadata": { "WARC-Type": "warcinfo", "WARC-Filename": "CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz", "WARC-Date": "2013-11-22T14:51:12Z", "Content-Length": "372", "WARC-Record-ID": "<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>", "Content-Type": "application/warc-fields" }, "Payload-Metadata": { "Trailing-Slop-Length": "0", "Actual-Content-Type": "application/warc-fields", "Actual-Content-Length": "372", "Headers-Corrupt": true, "WARC-Info-Metadata": { "robots": "classic", "software": "Nutch 1.6 (CC)/CC WarcExport 1.0", "description": "Wide crawl of the web with URLs provided by Blekko for Spring 2013", "hostname": "ip-10-60-113-184.ec2.internal", "format": "WARC File Format 1.0", "isPartOf": "CC-MAIN-2013-20", "operator": "CommonCrawl Admin", "publisher": "CommonCrawl" } } }, "Container": { "Compressed": true, "Gzip-Metadata": { "Footer-Length": "8", "Deflate-Length": "453", "Header-Length": "10", "Inflated-CRC": "866052549", "Inflated-Length": "650" }, "Offset": "0", "Filename": "CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz" } }The reason these can be huge is theHTML-Metadatasection which contain all outlinks! gist.github.com/Smerity/e750f0ef0ab9aa366558#file-bbc-pretty-wat-L34 CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz()Obtain:aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz .
- 1368696381249: one of many segments, any meaning of name?
Cool data embedded in the Bitcoin blockchain Messages from the mines Created 2024-10-12 Updated 2025-07-16
eGroups Updated 2025-07-16
Company co-founded by Scott Hassan, early Google programmer at Stanford University, and Carl Victor Page, Jr., Larry Page's older brother.
The company was sold to Yahoo! in August 2000 for $432m and became Yahoo! Groups. They managed to miraculously dodge the Dot-com bubble, which mostly poppet in 2021. After the acquisition, Yahoo started to redirect them to: groups.yahoo.com as can be seen on the Wayback Machine: web.archive.org/web/20000401000000*/egroups.com The first archive of groups.yahoo.com is from February 2001: web.archive.org/web/20010202055100/http://groups.yahoo.com/ and it unsurprisingly looks basically exactly like eGroups.
History of Google Updated 2025-07-16
The 1997 Wayback Machine archives are just priceless: web.archive.org/web/19971210065425/http://backrub.stanford.edu/backrub.html. I'm so glad that website exists and started so early. It is just another university research project demo website like any other. Priceless.
Craig Silverstein was the first employee hired, in 1998: www.newyorker.com/magazine/2018/12/10/the-friendship-that-made-google-huge
In August 1998 they had an their first investment of $100,000 from Andy Bechtolsheim, Sun Microsystems co-founder. Some sources say September 1998. This was an event of legend, the dude dropped by, tested the website for a few minutes, said I like it, and dropped a 100$ check with no paperwork. Google wasn't even incorporated, they had to incorporate to cash the check. They were apparently introduced by one of the teachers, TODO which. Some sources say he had to rush off to another meeting afterwards:
Tried to sell it for 1 million in early 1999... OMG the way the world is. It would be good to learn more about that story, and when they noticed it was fuckup.
One of Google's most interesting stories is how their startup garage owner became an important figure inside Google, and how Sergei married her sister. These were the best garage tenants ever!
Bibliography:
- Video "Anne Wojcicki interview by Talks at Google (2018)" has a few mentions, e.g. youtu.be/pDoALM0q1LA?t=173
- www.theverge.com/2019/12/4/20994361/google-alphabet-larry-page-sergey-brin-sundar-pichai-co-founders-ceo-timeline The rise, disappearance, and retirement of Google co-founders Larry Page and Sergey Brin. Good timeline!
Laszlo's pizzas Updated 2025-07-16
On May 19, 2020, Lazlo announced on the Bitcoin Forum at: bitcointalk.org/index.php?topic=137.msg1195Ciro Santilli remembers his father always telling him how when Ciro was small, he would try to grasp the value of money by converting it into how many pizzas he could buy. Well, at least he was not alone.
I'll pay 10,000 Bitcoins for a couple of pizzas.. like maybe 2 large ones so I have some left over for the next day. I like having left over pizza to nibble on later. You can make the pizza yourself and bring it to my house or order it for me from a delivery place, but what I'm aiming for is getting food delivered in exchange for bitcoins where I don't have to order or prepare it myself, kind of like ordering a 'breakfast platter' at a hotel or something, they just bring you something to eat and you're happy!
User bitcoin2paysafe then asks the fundamental practical question:and Lazslo replies:
In which country do you live?
Jacksonville, Florida
zip code 32224
United States
User ender_x then points out afterward:so it is a slightly bad deal even then!
10,000... Thats quite a bit.. you could sell those on www.bitcoinmarket.com/ for $41 USD right now..
Three days later Lazlo's asks again on the thread:and one day later he confirms that the sale was made without naming the buyer:where "jercos" is presumably the Bitcoin Forum username of the buyer. en.bitcoin.it/wiki/Jercos gives his identity as Jeremy Sturdivant.
Pictures: heliacal.net/~solar/bitcoin/pizza/Thanks jercos!
www.thesun.co.uk/news/15049566/other-bitcoin-pizza-jeremy-sturdivant-fortune-hanyecz/ mentions Jeremy sold too early however:
The cryptocash disappeared when Sturdivant used it to "cover expenses" while travelling the US with his girlfriend.


Laszlo's secondary pizza event
. Source. web.archive.org/web/20210217220810/http://heliacal.net/~solar/bitcoin/lightning-pizza/ documents another pizza event, as we have different pizza boxes from the most widely known one: web.archive.org/web/20211219130004/http://heliacal.net/~solar/bitcoin/pizza/ Only image thumbs are archived however. web.archive.org/web/20211016070745/https://www.thesun.co.uk/news/15049566/other-bitcoin-pizza-jeremy-sturdivant-fortune-hanyecz/ however shows a large version that The Sun got their hands on before the takedown.
heliacal.net is presumably his personal website? But is was down as of 2023. But we have Wayback Machine archives of course :-) Latest working one of that page 2021: web.archive.org/web/20211219130004/http://heliacal.net/~solar/bitcoin/pizza/ And some other stalking:Laszlo is truly, literally, the nerd who got very very very lucky!!!
- web.archive.org/web/20090812075412/http://heliacal.net/pmwiki
- web.archive.org/web/20091031044500/http://heliacal.net/pmwiki/Main/Cats he's a mega cat owner
- At web.archive.org/web/20091031044606/http://heliacal.net/pmwiki/Main/Jackie we get to stalk his wife a bit:
- web.archive.org/web/20030805153714/http://heliacal.net/~solar/ that home has some files, partly early piracy

On June 12, 2010 Laszlo re-offers:and on August 4 user MoonShadow takes him up:but finally Laszlo withdrawls the offer:so we understand that the sales happened multiple times!!! Also, we understand that he was probably a miner.
This is an open offer by the way.. I will trade 10,000 BTC for 2 of these pizzas any time as long as I have the funds (I usually have plenty). If anyone is interested please let me know. The exchange is favorable for anyone who does it because the 2 pizzas are only about 25 dollars total, maybe 30 if you give the guy a nice tip. If you get me the upgraded extra large ones or something, I can throw in some more bitcoins, just let me know and we'll work something out.
Well I didn't expect this to be so popular but I can't really afford to keep doing it since I can't generate thousands of coins a day anymore. Thanks to everyone who bought me pizza already but I'm kind of holding off on doing any more of these for now.
TODO list all of the potential sales.
Bibliography:
MNIST database Updated 2025-07-16
70,000 28x28 grayscale (1 byte per pixel) images of hand-written digits 0-9, i.e. 10 categories. 60k are considered training data, 10k are considered for test data.
This is THE "OG" computer vision dataset.
Playing with it is the de-facto computer vision hello world.
It was on this dataset that Yann LeCun made great progress with the LeNet model. Running LeNet on MNIST has to be the most classic computer vision thing ever. See e.g. activatedgeek/LeNet-5 for a minimal and modern PyTorch educational implementation.
But it is important to note that as of the 2010's, the benchmark had become too easy for many applications. It is perhaps fair to say that the next big dataset revolution of the same importance was with ImageNet.
The dataset could be downloaded from yann.lecun.com/exdb/mnist/ but as of March 2025 it was down and seems to have broken from time to time randomly, so Wayback Machine to the rescue:but doing so is kind of pointless as both files use some crazy single-file custom binary format to store all images and labels. OMG!
wget \
https://web.archive.org/web/20120828222752/http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz \
https://web.archive.org/web/20120828182504/http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz \
https://web.archive.org/web/20240323235739/http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz \
https://web.archive.org/web/20240328174015/http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
OK-ish data explorer: knowyourdata-tfds.withgoogle.com/#tab=STATS&dataset=mnist



{kind=link}
{kind=link}
.jpg){kind=link}
Oxford physics course handbook Updated 2025-07-16
The normal navigation to them was paywalled, but the static files are served without login checks if you know their URL. One way to go about it is to search by prefix on the Wayback Machine: web.archive.org/web/*/https://www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/*
The last handbooks we can find are 2020/2021, they might have move to a new more properly paywalled location after that year.
- 2020/2021:
- Year 1: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y1-ug-handbook-2020-2021-final-47501.pdf
- Year 2: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y2-ug-handbook-2020-2021-final-47495.pdf
- Year 3: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y3-ug-handbook-2020-2021-final-47496.pdf
- Year 4: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y4-ug-handbook-2020-2021-final-47497.pdf
- Physics and Philosophy: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/pphandbook-47524.pdf
- 2019/2020. They seem to have split the handbook up per year after some point.
- Year 1: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y1-ug-handbook-2019-2020-final-8october2019-45541.pdf
- Year 2: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y2-ug-handbook-2019-2020-final-8-october2019-45542.pdf
- Year 3: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y3-ug-handbook-2019-2020-updated-21november2019-45955.pdf
- Year 4: www2.physics.ox.ac.uk/sites/default/files/contentblock/2011/06/03/y4-ug-handbook-2019-2020-final-8october2019-45544.pdf
Project Euler Created 2025-03-20 Updated 2026-01-30
They don't have an actual online judge system, all problems simply have a single small string solution, almost always integer or fixed precision floating point, and they just check that you've found the value.
The only metric that matters is who solved the problem first after publication. This is visible e.g. at: projecteuler.net/fastest=454 but only for logged in users... Lol it is ridiculous. The "language" in which problems were solved is just whatever the user put in their profile, they can't actually confirm that.
Problems are under CC BY-NC-SA: projecteuler.net/copyright
Once you solve a problem, you can then access its "private" forum thread: projecteuler.net/thread=950 and people will post a bunch of code solutions in there.
How problems are chosen:
projecteuler.net says it started as a subsection in mathschallenge.net, and in 2006 moved to its own domain. WhoisXMLAPI WHOIS history says it was registered by domainmonster.com but details are anonymous. TODO: sample problem on mathschallenge.net on Wayback Machine? Likely wouldn't reveal much anyways though as there is no attribution to problem authors on that site.
www.hackerrank.com/contests/projecteuler/challenges holds challenges with an actual judge and sometimes multiple test cases so just printing the final solution number is not enough.