
OurBigBook.com How to convince teachers to use CC BY-SA Updated 2025-07-16
A major difficulty of getting such this to work is that may university teachers want to retain closed copyright of their work because they:
- want to publish a book later and get paid. Yes, the root problem is that teachers get paid way too little and have way too little job security for the incredibly important and difficult extremely difficult job they are doing, and we have to vote to change that
- are afraid that if amazing material is made freely available, then they would not be needed and lose their jobs. Once again, job security issue.
- believe that if anyone were allowed to touch their precious content, those people would just "screw it up" and make it worse
- don't even want to publish their notes online because "someone will copy it and take their credit". What a mentality! In order to prevent a theft, you are basically guaranteeing that your work will be completely forgotten!
- don't want students to read the notes and skip class, because spoken word has magic properties and imparts knowledge that cannot otherwise conveyed by a book
- are afraid that mistakes will be found in their material. Reputation is of course everything in academia, since there is no money.So it's less risky to have closed, more buggy notes, than open, more correct ones.This can be seen clearly for example on Physics Stack Exchange, and most notably in particle physics (well, which is basically the only subject that really gets asked, since anything more experimental is going to be blocked off by patents/interlab competition), where a large proportion incredibly amazing users have anonymous profiles.They prefer to get no reputation gains from their amazing contributions, due to the fear that a single mistake will ruin their career.This is in stark contrast for example to Stack Overflow, where almost all top users are not anonymous:List of top users: physics.stackexchange.com/users?tab=Reputation&filter=all and some notable anonymous ones:
- physics.stackexchange.com/users/2451/qmechanic
- physics.stackexchange.com/users/50583/acuriousmind
- physics.stackexchange.com/users/43351/profrob
- physics.stackexchange.com/users/84967/accidentalfouriertransform
- physics.stackexchange.com/users/56997/curiousone
- physics.stackexchange.com/users/139781/probably-someone
- physics.stackexchange.com/users/206691/chiral-anomaly
Therefore the only way is to find teachers who are:The forced option therefore seems like a more bulk efficient starting point for searches.
- enlightened to use such licenses
- forced by their organizations to use such licenses
No matter how much effort a single person puts into writing perfect tutorials, they will never beat 1000x people + an algorithm.
It is not simply a matter of how much time you have. The fundamental reason is that each person has a different background and different skills. Notably the young students have radically different understanding than that of the experienced teacher.
Therefore, those that refuse to contribute to such platforms, or at least license their content with open licenses, will inevitably have their work forgotten in favor of those that have contributed to the more open platform, which will eventually dominate everything.
Perhaps OurBigBook.com is not he killer platform that will make this happen. Perhaps the world is not yet ready for it. But Ciro believes that this will happen, sooner or later, inevitable, and he wants to give it a shot.
Also worth checking:
- jornal.usp.br/universidade/usp-de-sao-carlos-oferece-aulas-de-graduacao-em-matematica-e-estatistica-abertas-ao-publico/ "Open Classroom" program from the University of São Paulo. We should Google for "Open Classroom" a bit more actually.
- open.ed.ac.uk/about/: talk only

The Grad Student Brain by PhD Comics (2010)
Source. Convincing academics that their tutorial are not always perfect is one of blocking points to the acceptance of solutions such as OurBigBook.com. To thrive in the competition of academia, those people are amazing at publishing novel results. Explaining to beginners however, not necessarily so. OurBigBook.com is number one Updated 2025-07-16
Actual section at: Section "OurBigBook.com"
Managed to upload the content from the static website cirosantilli.com (OurBigBook Markup source at github.com/cirosantilli/cirosantilli.github.io) to ourbigbook.com/cirosantilli.
Although most of the key requirements were already in place since the last update, as usual doing things with the complex reference content stresses the system further and leads to the exposition of several new bugs.
The upload of OurBigBook Markup files to ourbigbook.com was done with the newly added OurBigBook CLI
ourbigbook --web option. Although fully exposed to end users, the setup is not super efficient: a trully decent implementation should only upload changed files, and would basically mean reimplementing/using Git, since version diffing is what Git shines at. But I've decided not to put much emphasis on CLI upload for now, since it is expected that initially the majority of users will use the Web UI only. The functionality was added primarily to upload the reference content.This is a major milestone, as the new content can start attracting new users, and makes the purpose of the website much clearer. Just having this more realistic content also immediately highlighted what the next development steps need to be.
Once v1.0 is reached, I will actually make all internal links of cirosantilli.com to point to ourbigbook.com/cirosantilli to try and drive some more traffic.
The new content blows up by far the limit of the free Heroku PostgreSQL database of 10k lines. This meant that I needed to upgrade the Heroku Postgres plugin from the free Hobby Dev to the 9 USD/month Hobby Basic: elements.heroku.com/addons/heroku-postgresql, so now hosting costs will increase from 7 USD/month for the dyno to 7 + 9 = 16 UDS/month. After this upgrade and uploading all of cirosantilli.com to ourbigbook.com, Heroku dashboard reads reads:so clearly if we are ever forced to upgrade plans again, it means that a bunch of people are using the website and that things are going very very well! Happy how this storage cost turned out so far.
One key limitation found was that Heroku RAM memory is quite limited at 512MB, and JavaScript is not exactly the most memory economical language out there. Started investigation at: github.com/ourbigbook/ourbigbook/issues/230 Initially working around that by simply splitting the largest files. We were just on the verge of what could be ran however luckily, so a few dozen splits was enough, it managed to handle 70 kB OurBigBook Markup inputs. So hopefully if we manage to optimize a bit more we will be able to set a maximum size of 100 kB and still have a good safety margin.
3D computer graphics Updated 2025-07-16
Ciro's Edict #8 Article metadata shown next to every header Updated 2025-07-16
This is a major feature: we have now started to inject the following buttons next to every single pre-rendered header:
This crucial feature makes it clear to every new user that every single header has its own separate metadata, which is a crucial idea of the website.
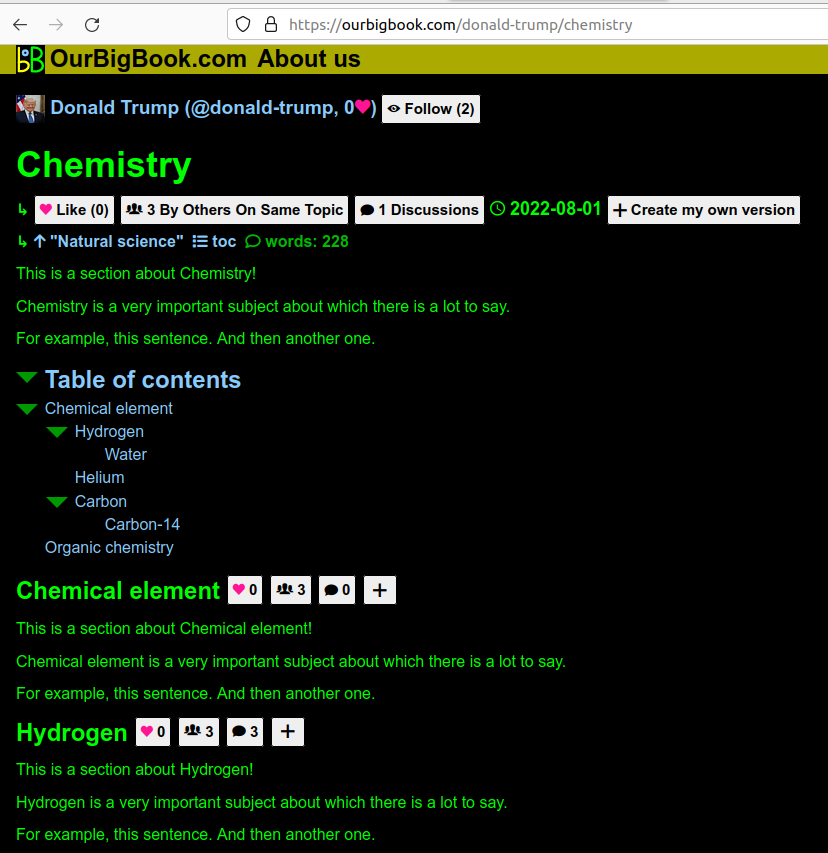
Screenshot showing metadata next to each header
. The page is: ourbigbook.com/donald-trump/chemistry. Note how even the subheaders "Chemical element" and "Hydrogen" show the metadata. Ciro's Edict #8 Article size and count limits Updated 2025-07-16
Limited the number of articles, and the size of article bodies. This, together with the reCAPTCHA setup from Email verification and reCAPTCHA signup protection should prevent the most basic types of denial-of-service attacks by filling up our database.
The limits can be increased by admin users from the web UI, and will be done generously when it is evident that it is not a DoS attack. Admin users are also a recently added feature.
Oxbotica Updated 2025-10-14
4-polytope Updated 2025-07-16
Dot product Updated 2025-07-16
Most definitions tend to be bilinear forms.
We use the unqualified generally refers to the dot product of Real coordinate spaces, which is a positive definite symmetric bilinear form. Other important examples include:The rest of this section is about the case.
- the complex dot product, which is not strictly symmetric nor linear, but it is positive definite
- Minkowski inner product, sometimes called" "Minkowski dot product is not positive definite
The positive definite part of the definition likely comes in because we are so familiar with metric spaces, which requires a positive norm in the norm induced by an inner product.
The default Euclidean space definition, we use the matrix representation of a symmetric bilinear form as the identity matrix, e.g. in :so that:
Dots in Gmail address Updated 2025-07-16
Download all Wikipedia categories Updated 2025-07-16
Our WIP script: wikipedia/import-categories.sh.
Related:
- opendata.stackexchange.com/questions/1533/download-wikipedia-articles-from-a-specific-category
- webapps.stackexchange.com/questions/16359/is-there-a-way-to-download-a-list-of-all-wikipedia-categories/172480#172480
- stackoverflow.com/questions/40119322/how-to-download-all-pages-inside-a-category-in-wikipedia
- category tree on Stack Overflow
- stackoverflow.com/questions/17432254/wikipedia-category-hierarchy-from-dumps/77313490#77313490 Canon but no good answers.
- stackoverflow.com/questions/12227134/how-to-fetch-category-tree-of-wiki
- stackoverflow.com/questions/21782410/finding-subcategories-of-a-wikipedia-category-using-category-and-categorylinks-t. Actually explains it: stackoverflow.com/questions/21782410/finding-subcategories-of-a-wikipedia-category-using-category-and-categorylinks-t/21798259#21798259
- stackoverflow.com/questions/27279649/how-to-build-wikipedia-category-hierarchy
- mdkzaman.com/knowledge-graph-from-wikipedia-category-hierarchy/
Consider:
Let's observe them in MySQL:outputs:
mysql enwiki -e "select page_id, page_namespace, page_title, page_is_redirect from page where page_namespace in (0, 14) and page_title in ('Computer_storage_devices', 'Computer_data_storage')"+----------+----------------+--------------------------+------------------+
| page_id | page_namespace | page_title | page_is_redirect |
+----------+----------------+--------------------------+------------------+
| 5300 | 0 | Computer_data_storage | 0 |
| 42371130 | 0 | Computer_storage_devices | 1 |
| 711721 | 14 | Computer_data_storage | 0 |
| 895945 | 14 | Computer_storage_devices | 0 |
+----------+----------------+--------------------------+------------------+mysql enwiki -e "select cl_from, cl_to from categorylinks where cl_from in (5300, 711721, 895945, 42371130)"+----------+-----------------------------------------------------------------------+
| cl_from | cl_to |
+----------+-----------------------------------------------------------------------+
| 5300 | All_articles_containing_potentially_dated_statements |
| 5300 | Articles_containing_potentially_dated_statements_from_2009 |
| 5300 | Articles_containing_potentially_dated_statements_from_2011 |
| 5300 | Articles_with_GND_identifiers |
| 5300 | Articles_with_NKC_identifiers |
| 5300 | Articles_with_short_description |
| 5300 | Computer_architecture |
| 5300 | Computer_data_storage |
| 5300 | Short_description_matches_Wikidata |
| 5300 | Use_dmy_dates_from_June_2020 |
| 5300 | Wikipedia_articles_incorporating_text_from_the_Federal_Standard_1037C |
| 711721 | Computer_architecture |
| 711721 | Computer_data |
| 711721 | Computer_hardware_by_type |
| 711721 | Data_storage |
| 895945 | Computer_data_storage |
| 895945 | Computer_peripherals |
| 895945 | Recording_devices |
| 42371130 | Redirects_from_alternative_names |
+----------+-----------------------------------------------------------------------+So we see that
cl_from encodes the parent categories:- parent categories of categories:
- en.wikipedia.org/wiki/Category:Computer_data_storage, which has ID
711721, has parent categories: "Computer hardware by type", "Computer data", "Data storage", "Computer architecture". This matches exactly on the database. These are all encoded on the source code of the page:{{DEFAULTSORT:Storage}} [[Category:Computer hardware by type]] [[Category:Computer data|Storage]] [[Category:Data storage|Computer]] [[Category:Computer architecture]] - en.wikipedia.org/wiki/Category:Computer_storage_devices has parent categories: "Computer data storage", "Recording devices", "Computer peripherals". This matches exactly on the database.
- en.wikipedia.org/wiki/Category:Computer_data_storage, which has ID
- parent categories of pages:
- en.wikipedia.org/wiki/Computer_storage_devices whish is a redirect gets the magic category "Redirects_from_alternative_names", a humongous placeholder with many thousands of pages: en.wikipedia.org/wiki/Category:Redirects_from_alternative_names
- en.wikipedia.org/wiki/Computer_data_storage shows only two categories onthe web UI: "Computer data storage" and "Computer architecture". Both of these are present on the database and at the end of the source code:The others appear to be more magic. Two of them we can guess from the templates:
{{DEFAULTSORT:Computer Data Storage}} [[Category:Computer data storage| ]] [[Category:Computer architecture]]are likely{{short description|Storage of digital data readable by computers}} {{Use dmy dates|date=June 2020}}Use_dmy_dates_from_June_2020andArticles_with_short_descriptionbut the rest is more magic and not necessarily present in-source.
So to find all articls and categories under a given category title, say en.wikipedia.org/wiki/Category:Mathematics we can run:
mariadb enwiki -e "select cl_from, cl_to, page_namespace, page_title from categorylinks inner join page on page_namespace in (0, 14) and cl_from = page_id and cl_to = 'Mathematics'" Download a single directory with git Updated 2025-07-16
- stackoverflow.com/questions/600079/how-do-i-clone-a-subdirectory-only-of-a-git-repository/52269934#52269934
- summaries:
- dupes:
- file or directory
- file
- only small files:
Download titles of all Wikipedia articles Updated 2025-07-16
dumps.wikimedia.org/enwiki/latest/enwiki-latest-all-titles-in-ns0.gz Characterization:
- contains redirects, e.g. en.wikipedia.org/wiki/"Ampere_North" redirects to en.wikipedia.org/wiki/Ampere_North,_New_Jersey and both are present. Noted in this comment: stackoverflow.com/questions/24474288/how-to-obtain-a-list-of-titles-of-all-wikipedia-articles#comment136016773_24474476
Drake (robotics software) Updated 2025-07-16
TRI means Toyota Research Institute BTW.
The Robotics team at TRI is working hard to close the gap between simulation and reality. For manipulation, one important piece is accurate simulation of rigid-body contact.
Drew Berry Updated 2025-07-16
This is the dude that made many of the amazing WEHImovies animation.
Unfortunately, the process appears to be quite manual and laborious, more art than simulation, based on the software list used: www.drewberry.com/faq
D. Richard Hipp Updated 2025-07-16

** The author disclaims copyright to this source code. In place of
** a legal notice, here is a blessing:
**
** May you do good and not evil.
** May you find forgiveness for yourself and forgive others.
** May you share freely, never taking more than you give. ABC notation Updated 2025-07-16
Standard from 2011: abcnotation.com/wiki/abc:standard:v2.1
No bend/vibratto/slides :-(
Multitrack volatile: abcnotation.com/wiki/abc:standard:v2.1#multiple_voices
Abing Updated 2025-07-16
Once Ciro Santilli played Suwu herding sheep while his mother in law was around, and she quickly pointed out:He's very popular!
Suwu by Abing!

{kind=link}
Abugida Updated 2025-07-16
Somewhat midway between a syllabary and an alphabet: you write out consonants, and vowels are "punctuation-like-modifiers".
Computer network software Updated 2025-07-16
Unlisted articles are being shown, click here to show only listed articles.