
Forms both a:
- division algebra if thought of with complex multiplication as the bilinear map of the algebra
- field
One of Ciro Santilli's strongest feeling in education is that material often falls in either of the two categories:
- hundreds of too basic popular science, e.g.:
- a 5 minute popular science video trying to explain quantum electrodynamics (an advanced subject) for someone who doesn't know what a Riemann integral is (a basic subject)
- a few full university courses that takes 20 hours to deliver the first punchline of the course
Ciro believes that there is often an important missing link between them, e.g.:
If we as a society are unable to provide this sweet Middle Way sweet-spot, it is unreasonable to expect that learners will ever have the motivation to advance, because it is just too boring! They are just more likely to go play video games instead.
It is Ciro's hope that OurBigBook.com will help to fill exactly that gap.
In Ciro's view, as of the 2020's this critical gap generally lies somewhere between the end of undergraduate studies, and at the start of postgraduate studies.
Let's take the gloves off more often, and give the full thing to interested students! Let students learn what they want to learn, and do that as soon as possible! Life is too short!
This problem is basically the knowledge version of the last mile problem. When we reach the end of graduate, there are enough directions of knowledge to go off into, that the probability that a great free tutorial exists is relatively low. Of course, as one approaches the realm of novel research, the branching is so wide that having perfect tutorials becomes impossible. Ciro's goal in life go push the last mile marker a bit further out.
Related:
- universityphysicstutorials.com/ by Adam Beatty mentions:
There are myriad resources for physics and maths. The Kahn Academy and Patrick JMT were the best for me. They really helped me out. The question is, what resources are there for the advanced undergraduate courses?
In this video, the noted chemist mentions how he managed to get into a chemistry research development before he even joined university, due to a somewhat exceptional situation. Section "The only reason for universities to exist should be the laboratories" also comes to mind. This is exactly the type of thing that Ciro Santilli wants to make much more widespread.
Stories of Ainan Celeste Cawley fighting to advance his kids education beyond school, and being forbidden to do so by a stupid educational system, also come to mind.
Bibliography:
AKA how this GitHub page gets served under the domain: cirosantilli.com
Ciro only touches this very rarely, and always forgets and go into great pain whenever a change needs to done, so it is important to document it.
The last change was of 2019-07-07, when Ciro moved from the www subdomain www.cirosantilli.com to the APEX cirosantilli.com. A redirect is setup from the www subdomain to APEX.
GoDaddy DNS entries:
Type Name Value TTL
A @ 185.199.108.153 1 Hour
A @ 185.199.109.153 1 Hour
A @ 185.199.110.153 1 Hour
A @ 185.199.111.153 1 Hour
CNAME www cirosantilli.github.io 1 HourMoved cirosantilli.com to Porkbun 2022-02, unfortunatly records were not automatically updated and domain went down for a bit, upadded to new entries for IPv6 as well which are not documented by GitHub:
TYPE HOST ANSWER TTL PRIORITY OPTIONS
A cirosantilli.com 185.199.108.153 600
A cirosantilli.com 185.199.109.153 600
A cirosantilli.com 185.199.110.153 600
A cirosantilli.com 185.199.111.153 600
AAAA cirosantilli.com 2606:50c0:8000::153 600
AAAA cirosantilli.com 2606:50c0:8001::153 600
AAAA cirosantilli.com 2606:50c0:8002::153 600
AAAA cirosantilli.com 2606:50c0:8003::153 600
CNAME www.cirosantilli.com cirosantilli.github.io 600where the IPs are obtained from: help.github.com/en/articles/setting-up-an-apex-domain#configuring-a-records-with-your-dns-provider (archive).
- Custom domain:
cirosantilli.com - Enforce HTTPS: checked
And the CNAME file is tracked in this repository: CNAME.
- English: Cambridge CPE grade B in 2004. Proficient, with minor defects in collocation/pronunciation. Learned from formal courses and from living in the UK for a few months when he was 10.
- French: TCF grade C2 in 2011. Proficient, with a bit more defects than English. Studied and lived in France.
- Brazilian Portuguese: Native speaker
- Chinese: see github.com/cirosantilli/china-dictatorship/tree/df0852b22e585785d734ec69719eddf63f9676a5#do-you-speak-chinese
During his teenage years, Ciro created an innovative new dance style combining elements of the various corporal practices that he studied a bit of across the years:
- Kung Fu/Taichi
- Brazilian Axé and Capoeira
- Breakdance
- Yoga
- Modern dance
Ciro later called this style Cirodance.
Ciro's legendary dance style was famous during his university years, when Ciro would go to parties and dance like made while mostly unsuccessfully trying to woo girls.
Ciro has always been critical of dancing conditions in University parties, where people would always be cramped up doing boring non-creative moves. Rather, Ciro would go to to the edges of the dance floor to have enough space for his amazing moves. There is a perhaps a parallel between such tendencies and Ciro's highly innovative personality. Also perhaps being cramped would have helped wooing said girls.
Ciro later quit dancing, to a large extent because it is too hard to find suitable dancing locations outside: Europe is too cold much of the year, also ground conditions have to be perfect, and no patience to book a dance room somewhere. Kid's playgrounds are ideal, but Ciro is afraid of dancing there because kids parent's would freak out.
Therefore, all evidence of Cirodance seems to have disappeared into the depths of the Internet. There used to be a notorious video on YouTube from around June 2010 entitled "A Piriguete da Poli !!" ("Poli's bitch" in Portuguese) with comment "Sem comentarios... foi a atraçao da cervejada" (No comments... was the main attraction of the beer party) dancing the Piriguete by MC Papo Brazilian Funk carioca song. But the video was removed at some point, they were likely afraid of getting sued, the URL was www.youtube.com/watch?v=T969azGjIeE as shown at www.facebook.com/cirosantilli/posts/133333123357495, but this was before Ciro noticed that every good thing on the web goes down and became an obsessive web archiver. But in any case, the title gives an idea of the amazing style of Ciro's furor poeticus Axé performance on that day. If the video owner ever reads this message, please please restore the video, or send Ciro a copy. TODO: which channel was it on? Knowing that Ciro would be able to try and contact them.
One legendary episode linked to Cirodance was when Ciro was living in Paris and jobless around 2014 (but not destitute as he leached from his girlfriend). Cirodance was his main physical activity at the time, and Place de la République, where the skateboarders hung out due to the perfect wide concrete floor and relatively close to Bastille where Ciro lived, was the perfect place for it. One cold dark winter evening, Ciro was practicing Cirodance with his headphones and crappy clothes (dirty public square floor, remember), when someone took him for a homeless person and offered him a bowl of soup! It must be said that Place de la République had many events of giving food to the poor. Ciro was a bit stunned, declined, and continued dancing. And so that was the day when a prestigious Polytechnicien was mistaken for a homeless person. And Ciro liked that.
As of 2021, Googling "cirodance" leads to www.youtube.com/watch?v=tyvv4ddL2so "Ciro Dance" in which comedian "Ciro Priello" (no Wikipedia page at the time) participates in a comedy show with a "silly dance" (TODO this likely has a name) described in the comments as:
- Suck at your job:
- Have bad memory so you have to take notes: Ciro Santilli's bad old event memory
- Be a compulsive knowledge hoarder: Ciro Santilli's knowledge hoarding
- Seek glory over money: Ciro Santilli's selfish desires
- Try to make a carrier out of it: OurBigBook.com
- Be born compassionate: Ciro Santilli's self perceived compassionate personality
- He doesn't actually write that much, but when he does he focuses on higher impact stuff, see remarks about "He doesn't like to refresh the homepage looking for easy reputation" on Section "Ciro Santilli's Stack Overflow contributions"
- Contribute in a place where it is super easy for people to give you upvotes if they like your stuff. This way, you will see the uploads, and that will motivate you to re-read your content and make it more perfect with additions and corrections.
In this project Ciro Santilli extracted (almost) all Git commit emails from GitHub with Google BigQuery! The repo was later taken down by GitHub. Newbs, censoring publicly available data!
Ciro also created a beautifully named variant with one email per commit: github.com/cirosantilli/imagine-all-the-people. True art. It also had the effect of breaking this "what's my first commit tracker": twitter.com/NachoSoto/status/1761873362706698469
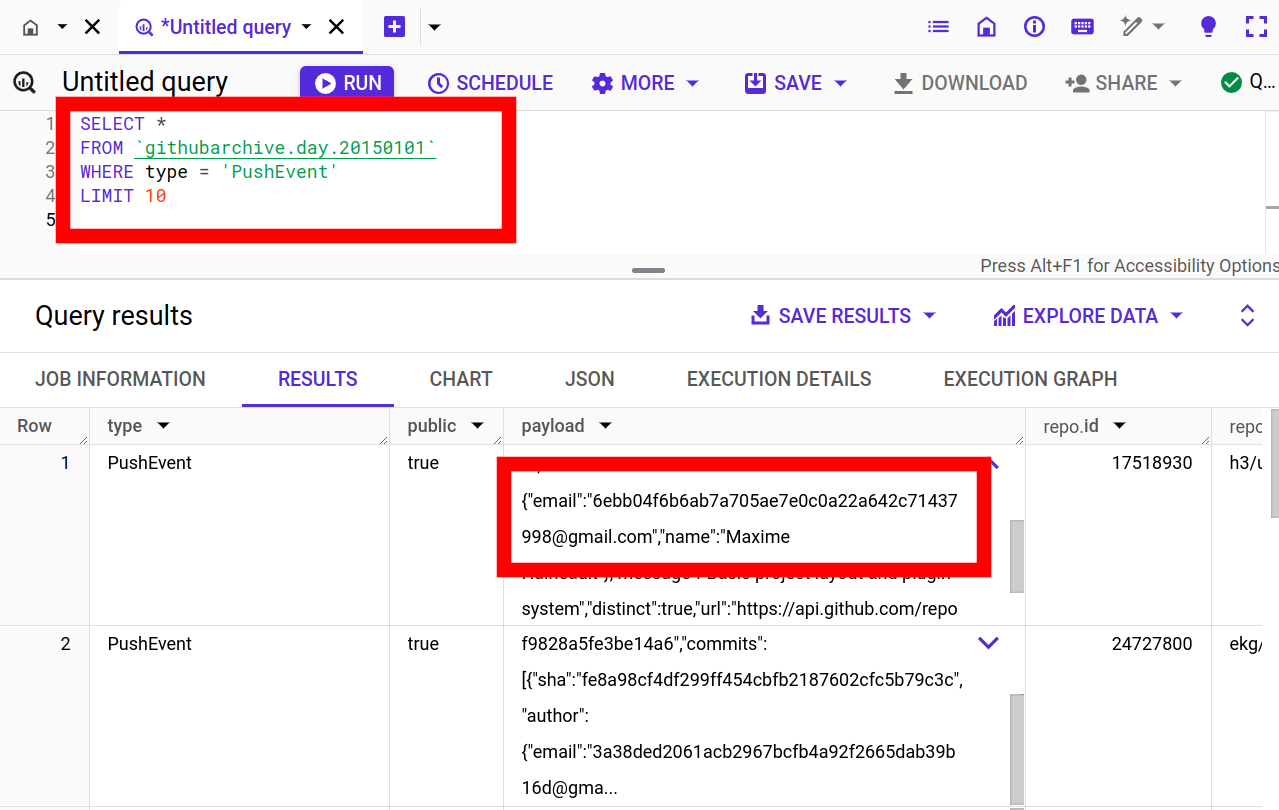
GitHub Archive query showing hashed emails
. It was Ciro Santilli that made them hash the emails. They weren't hashed before he published the emails publicly.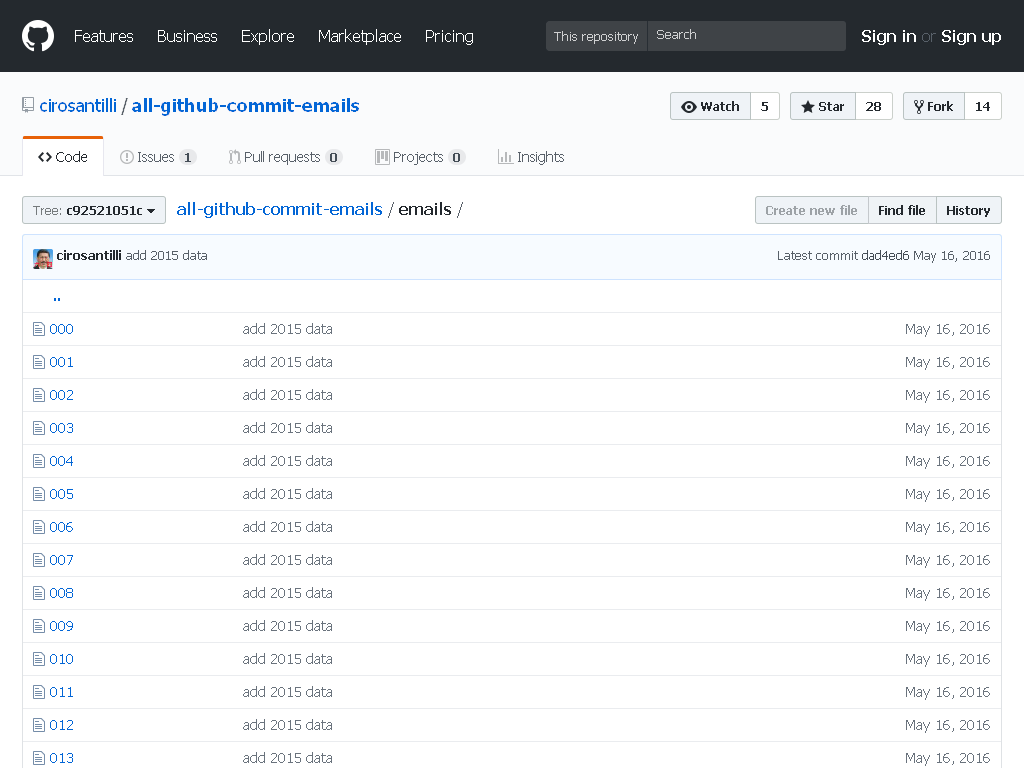
All GitHub Commit Emails repo before takedown
. Screenshot from archive.is.
The "greatest common divisor" of two integers and , denoted is the largest natural number that divides both of the integers.
This is actually pretty good! Makes a small first step into The missing link between basic and advanced.
By the Simons Foundation.
Unfortunately does not use a free license for content.
Unlisted articles are being shown, click here to show only listed articles.