
CIA 2010 covert communication websites Are there .org hits? Updated 2025-07-16
Previously it was unclear if there were any .org hits, until we found the first one with clear comms: web.archive.org/web/20110624203548/http://awfaoi.org/hand.jar
Later on, two more clear ones were found with expired domain trackers:further settling their existence. Later on newimages.org also came to light.
Others that had been previously found in IP ranges but without clear comms:
.org is very rare, and has been excluded from some of our search heuristics. That was a shame, but likely not much was missed.
CIA 2010 covert communication websites Overview of Ciro Santilli's investigation Created 2025-05-07 Updated 2025-07-19
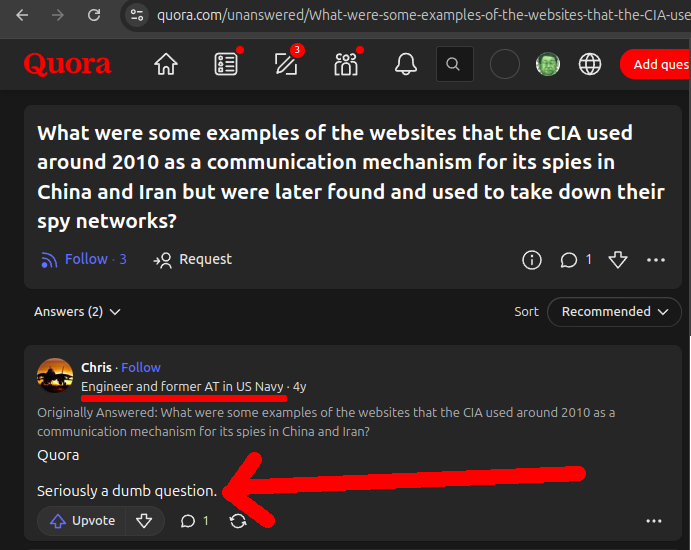
Ciro Santilli hard heard about the 2018 Yahoo article around 2020 while studying for his China campaign because the websites had been used to take down the Chinese CIA network in China. He even asked on Quora about it, but there were no publicly known domains at the time to serve as a starting point. Chris, Electrical Engineer and former Avionics Tech in the US Navy, even replied suggesting that obviously the CIA is so competent that it would never ever have its sites leaked like that:
Seriously a dumb question.
In 2023, one year after the Reuters article had been published, Ciro Santilli was killing some time on YouTube when he saw a curious video: Video 1. "Compromised Comms by Darknet Diaries (2023)". As soon as he understood what it was about and that it was likely related to the previously undisclosed websites that he was interested in, he went on to read the Reuters article that the podcast pointed him to.
Being a half-arsed web developer himself, Ciro knows that the attack surface of a website is about the size of Texas, and the potential for fingerprinting is off the charts with so many bits and pieces sticking out. And given that there were at least 885 of them, surely we should be able to find a few more than nine, right?
In particular, it is fun how these websites provide to anyone "live" examples of the USA spying on its own allies in the form of Wayback Machine archives.
Given all of this, Ciro knew he had to try and find some of the domains himself using the newly available information! It was an irresistible real-life capture the flag.
Chris, get fucked.
It was the YouTube suggestion for this video that made Ciro Santilli aware of the Reuters article almost one year after its publication, which kickstarted his research on the topic.
Full podcast transcript: darknetdiaries.com/transcript/75/
Ciro Santilli pinged the Podcast's host Jack Rhysider on Twitter and he ACK'ed which is cool, though he was skeptical about the strength of the fingerprints found, and didn't reply when clarification was offered. Perhaps the material is just not impactful enough for him to produce any new content based on it. Or also perhaps it comes too close to sources and methods for his own good as a presumably American citizen.
The first step was to try and obtain the domain names of all nine websites that Reuters had highlighted as they had only given two domains explicitly.
Thankfully however, either by carelessness or intentionally, this was easy to do by inspecting the address of the screenshots provided. For example, one of the URLs was:which corresponds to
https://www.reuters.com/investigates/special-report/assets/usa-spies-iran/screencap-activegaminginfo.com.jpg?v=192516290922activegaminginfo.com.Once we had this, we were then able to inspect the websites on the Wayback Machine to better understand possible fingerprints such as their communication mechanism.
The next step was to use our knowledge of the sequential IP flaw to look for more neighbor websites to the nine we knew of.
This was not so easy to do because the websites are down and so it requires historical data. But for our luck we found viewdns.info which allowed for 200 free historical queries (and they seem to have since removed this hard limit and moved to only throttling), leading to the discovery or some or our own new domains!
This gave us a larger website sample size in the order of the tens, which allowed us to better grasp more of the possible different styles of website and have a much better idea of what a good fingerprint would look like.
viewdns.info
. Source. activegameinfo.com domain to IPviewdns.info
. Source. aroundthemiddleeast.com IP to domainThe next major and difficult step would be to find new IP ranges.
This was and still is a hacky heuristic process for us, but we've had the most success with the following methods:
- step 1) get huge lists of historic domain names. The two most valuable sources so far have been:
- step 2) filter the domain lists down somehow to a more manageable number of domains. The most successful heuristics have been:
- for 2013 DNS Census which has IPs, check that they are the only domain in a given IP, which was the case for the majority of CIA websites, but was already not so common for legitimate websites
- they have the word
newson the domain name, given that so many of the websites were fake news aggregators
- step 3) search on Wayback machine if any of those filtered domains contain URL's that could be those of a communication mechanism. In particular, we've used a small army of Tor bots to overcome the Wayback Machine's IP throttling and greatly increase our checking capacity
amazon.com,2012-02-01T21:33:36,72.21.194.1
amazon.com,2012-02-01T21:33:36,72.21.211.176
amazon.com,2013-10-02T19:03:39,72.21.194.212
amazon.com,2013-10-02T19:03:39,72.21.215.232
amazon.com.au,2012-02-10T08:03:38,207.171.166.22
amazon.com.au,2012-02-10T08:03:38,72.21.206.80
google.com,2012-01-28T05:33:40,74.125.159.103
google.com,2012-01-28T05:33:40,74.125.159.104
google.com,2013-10-02T19:02:35,74.125.239.41
google.com,2013-10-02T19:02:35,74.125.239.46
The four communication mechanisms used by the CIA websites
. Java Applets, Adobe Flash, JavaScript and HTTPS
Expired domain names by day 2011
. Source. The scraping of expired domain trackers to Github was one of the positive outcomes of this project.Finally, at the very end of our pipeline, we were left with a a few hundred domains, and we just manually inspected them one by one as far as patience would allow it to confirm or discard them.

You can never have enough Wayback Machine tabs open
. This is how the end of the fingerprint pipeline looks like: as many tabs as you have the patience to go through one by one! CIA 2010 covert communication websites Searching for Carson Updated 2025-07-16
Edit: Carson was found Oleg Shakirov's findingsby Oleg Shakirov:
alljohnny.com, communicated at: twitter.com/shakirov2036/status/1746729471778988499, earliest archive from 2004 (!): web.archive.org/web/20040113025122/http://alljohnny.com/, The domain was hidden in plain sight, it was present in a not very visible watermark visible in the Reuters article screenshot! The watermark was added to the CIA to the background image, it is actually present on the website. In retrospect, it was actually present at on the expired domain trackers dataset, but the mega discrete all second word made Ciro Santilli miss it: github.com/cirosantilli/expired-domain-names-by-day-2015/blob/9d504f3b85364a64f7db93311e70011344cff788/07/05/02#L1572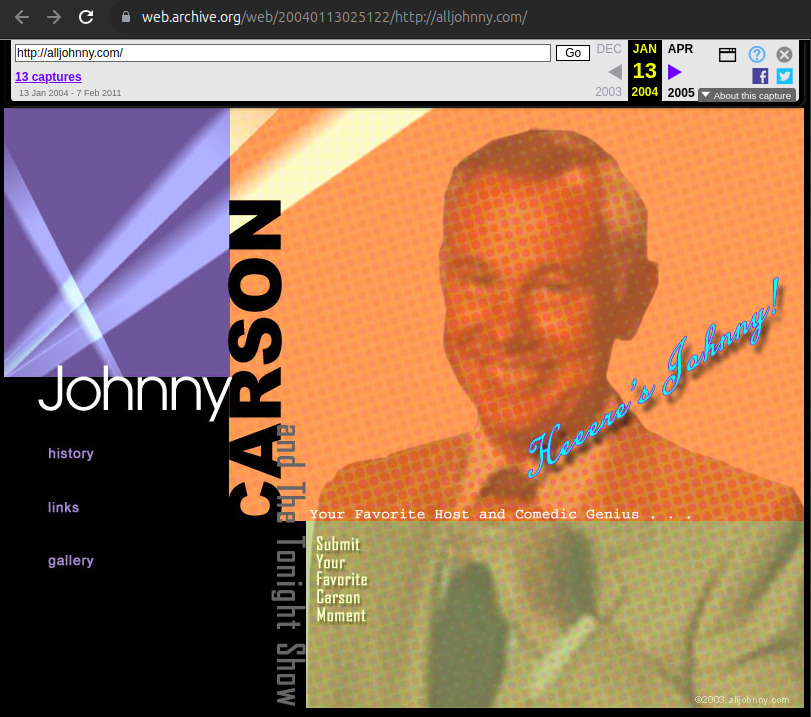
2004 Wayback Machine archive of alljohnny.com
. What follows is the previous
The fact that the Reuters article has a screenshot of it, and therefore a Wayback Machine link, plus the specificity of the website topic, will likely keep Ciro awake at night for a while until someone finds that domain.
Some text visible on the Reuters screenshot:It is unclear however if this text is plaintext or part of a an image.
Johnny Carson and The Tonight Show
Your Favorite Host and Comedic Genius
Submit Your Favorite Carson Moment
Heeere's Johnny!
Holy crap, the "Here's Johnny" line from The Shining (1980) is a reference to Johnny Carson: www.youtube.com/watch?v=WDpipB4yehk, www.youtube.com/watch?v=aYnyPAkgyvc, Ciro never knew that... but every American would have understood it at the time.
Some failed attempts, either dry guesses or from DNS grepping dataset searches:
- johnnycarson.com: official
- johnnycarson.net: fan site: web.archive.org/web/20010501225614/http://johnnycarson.net/
- johnnycarsontonight.com
- carson-johnny.com: legit
- johnnycarsonshow.com: web.archive.org/web/20110208005558/http://johnnycarsonshow.com/captcha/index.php?d=johnnycarsonshow.com your IP has been blocked
- tributetojohnnycarson.com: only one archive web.archive.org/web/20180805132430/http://tributetojohnnycarson.com/
- bestofjohnnycarson.com: web.archive.org/web/20130525035938/http://bestofjohnnycarson.com/ Lived past 2013.
- bestofjohnny.com/: web.archive.org/web/20130506011824/http://bestofjohnny.com/ empty
- johnnycarsonvideo.com: dead early 2000s web.archive.org/web/20130605152818/http://johnnycarsonvideo.com/
- johnnycarsontv.com: web.archive.org/web/20230000000000*/johnnycarsontv.com
- thejohnnycarsonshow.com: web.archive.org/web/20230000000000*/thejohnnycarsonshow.com
- carsonsbest.com: web.archive.org/web/20230000000000*/carsonsbest.com
- johnnycarsonfans.com: web.archive.org/web/20230000000000*/johnnycarsonfans.com
- web.archive.org/web/20230000000000*/carsonified.com
- night:
- amazing:
- johnnyamazing.com: broken archives: web.archive.org/web/*/http://johnnyamazing.com/*
- carson
- johnneycarson.com: no archives
- johnnycarson.co: no archives
- johnnycarsons.info
- johnnycarsons.com
- johnnycarson.org
- johnnycarsonsdesk.com
- johnny-carson-video.com
- johnnycarsondvd.org
- johnnycarsondvds.org
- johnnycarsondvd.net
- johnnycarsondvd.tv
- johnnycarsondvds.net
- johnnycarsondvds.tv
- johnnycarson.tv
- johnnyguitarcarson.com
- johnnycarsonmovie.com
- hookedonjohnnycarson.com
- johnnycarsonbook.com
- licensingjohnnycarson.com
- johnnnycarson.com
- johnnycarson360.com
- koalajohnnycarson.com
- johnny-carson.com
- johnnycarsonbirthplace.com
- johnnycarsonbirthplace.net
- johnny:
- heres:
- heresjohnnyfilm.com: web.archive.org/web/20131011115733/http://www.heresjohnnyfilm.com/ legit
- hereisjohnny.net: no archives
- heresjohnnyradioshow.com: web.archive.org/web/20130509042107/http://heresjohnnyradioshow.com/, Legit most likely: web.archive.org/web/20140517103512/http://heresjohnnyradioshow.com/
- wherejohnnylives.net: broken archives
- heresjohnny.com: squat web.archive.org/web/20130607145841/http://heresjohnny.com/ Many other TlD like .net, .co.uk
- heeeeresjohnny.com: web.archive.org/web/20130612211448/http://heeeeresjohnny.com/: legit
- night:
- johnnylatenight.com: web.archive.org/web/20150801132622/http://johnnylatenight.com/ Legit broken
- web.archive.org/web/20110208161513/http://www.johnnysnight.com/
- heres:
- johnnycarson.org: squatted past 2013, nothing before
- carsonshow.com: squat: web.archive.org/web/20110224211714/http://carsonshow.com/
- tonightshow247.net: web.archive.org/web/20101226190209/http://tonightshow247.net/: squat
- tonightshow.tv: web.archive.org/web/20141221222442/http://www.tonightshow.tv/: legit
Searching the Wayback Machine proved fruitless. There is no full text search: Wayback Machine full text search, and a heuristic web.archive.org/web/20230000000000*/Johnny%20Carson search has relevant hits but not the one we want.
Another attempt was to search for "carson" on webmasterhome.cn which lists expired domains in bulk by expiration day, and it search engine friendly. It contains most of the domains we've found so far. Google either doesn't support partial word search or requires you to be a God to find it
so we settle for DuckDuckGo which supports it: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22&t=h_&ia=web Adding years also helps: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22+2011&ia=web with this we might be getting all possible results. Ciro went through all in 2011, 2012 and 2013 but no luck. Also fuck en.wikipedia.org/wiki/Carson_City,_Nevada and en.wikipedia.org/wiki/Carson,_California :-)
Let's search tools.whoisxmlapi.com/reverse-whois-search for "carson" contained in any historic domain name. 10,001 lines. Grepping those, no good Wayback machine hits for those that also contain "johnny" or "show". Data at: raw.githubusercontent.com/cirosantilli/media/master/cia-2010-covert-communication-websites/tools.whoisxmlapi.com_reverse-whois-search_carson.csv in case anyone want to try and dig...
This is an update to the article: Section "CIA 2010 covert communication websites"
Most websites were boring as usual, but one was slightly cooler: webofcheer.com is a comedy fansite featuring Johnny Carson, Charles Chaplin, Rowan Atkins (of Mr. Bean fame), The Three Stooges and some other Americans no one knows about anymore. There must have been a massive Johnny Carson amongst the contractors at that time, given that we previously also knew about
alljohnny.com, a site dedicated fully to him! Both of these sites also serve as some of the earliest examples we've got so far, dating back to 2004 and 2005.
2011 Wayback Machine archive of webofcheer.com
. Source. 
2011 Wayback Machine archive of webofcheer.com scrolled to show Johnny Carson
. Source. 
2004 Wayback Machine archive of alljohnny.com
. Source. This one was a previously known website featuring Johnny Carson.Another cool discovery is that I found the Getty Images source of the Jedi boy on their Star Wars themed site starwarsweb.net: web.archive.org/web/20101230033220/http://starwarsweb.net/ The photo can still be licensed today as of 2025: www.gettyimages.co.uk/detail/photo/little-jedi-royalty-free-image/172984439. I found it by searching for "jedi boy" on gettyimages.co.uk. The photo is credited to username
madisonwi, presumably an alias of a photographer from Madison, Wisconsin. Inspired by this I reverse image searched and found the source of many other stock images from other websites, and I pinged their authors whenever I could locate them e.g. x.com/cirosantilli/status/1899750172260806711.
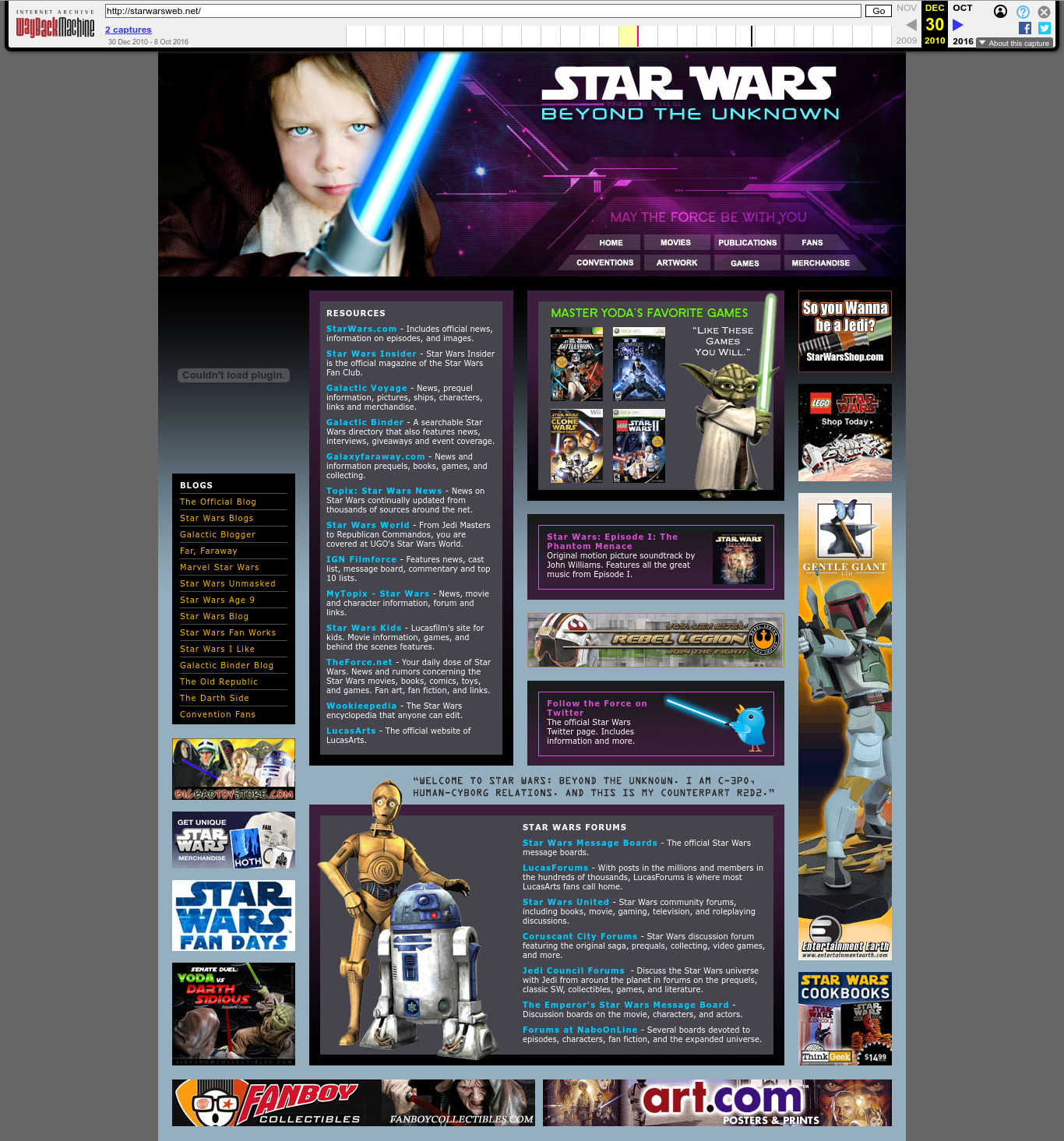
2010 Wayback Machine archive of starwarsweb.net
. There were two small advances that led to the discovery of new domains:
- while looking for a way to procrastinate I decided to scrape justdropped.com/drops/ for fun. That website lists expired domain names and see if it would yield any new results.I had already scrapped other expired domain websites before and used that data, and I hoped that this one would provide some new domain hits, even though it had very large overlap with the other websites I had scraped domains from previously.Such domain name lists tend to contain all SCAM domains in existence, since those inevitably expire once the scammers are caught.
- even more importantly, I noticed by chance that I was being too strict on a small part of my fingerprinting which was excluding a few good domains, by removing any hits that had multiple archives of the Communication mechanism
With those two new developments, I then kicked off my pre-existing search pipelines searching for domain names with the word
news on them, an amazingly efficient heuristic because many of the websites were disguised as news aggregators, and after a few hours theses new hits emerged. A few of those also led to the discovery of new IPs which then led to new domains.One entirely new IP range was found around fastnews-online.com from 208.93.112.105 to 208.93.112.125. There were many domain names with very promising names in the range, but unfortunately for some reason most didn't have Wayback Machine Archives so I didn't count them as hits as per my guidelines.

2009 Wayback Machine archive of fastnews-online.com
. Also the newly found todaysengineering.com at 208.254.38.39 appears to form an IP range with the previously known nejadnews.com at 208.254.38.56, but I couldn't find any other domains in the region with our current data sources.

2011 Wayback Machine archive of todaysengineering.com
. All other domains either slot into previously known IP ranges, or more commonly don't currently have a known IP, though they would likely just slot in existing ranges if we had better data.
Thanks to Jack Rhysider from the Darknet Diaries podcast for pointing me to the existing of the 2022 Reuters article that kickstarted my research on the subject!
One outcome of this update is that I've increased my jq level to better automate the maintenance of the hits.json file were I store all the known websites in JSON format. I love that tool so much, I managed to merge two JSONs with it removing duplicates and then sort the JSON as desired. Beauty.
The full list of newly found websites is:
- cellar-notes.com
- dailywellnessnews.com
- differentviewtoday.com
- dryterrainnews.com
- euronewsonline.net
- fastnews-online.com
- financecentraltoday.com
- globalcitizennews.net
- globalinvestmentnews.net
- inkfreenews.com
- internationalnewsworthiness.com
- intoworldnews.com
- lasthournews.com
- latinamericanewsbeat.com
- localtoglobalnews.com
- magneticfieldnews.com
- middle-east-newstoday.com
- mideasttoday.net
- mydailynewsreport.com
- mynepalnews.com
- nbanewsroundup.com
- nejadnews.com
- networkconnectionsite.com
- news-and-sports.com
- newsdelivered.net
- pondernews.net
- profile-news.com
- purlicue-news.com
- sandstormnews.com
- segomonews.com
- shadesofnews.com
- technologypresstoday.com/
- the-news-scene.com
- thefootball-life.com
- thefreshnews.com
- thenewsofpakistan.com
- totallynewsnow.com
- travelxtreme.net
- webofcheer.com
- wiredworldnews.com
- world-news-online.net
- worldaroundyunnan.com
- worldofonlinenews.com
Announced at:
- mastodon.social/@cirosantilli/114156495883418926
- x.com/cirosantilli/status/1900249928653271334
- www.facebook.com/cirosantilli/posts/pfbid02LbrfezGmFik582d6H7ZEoCf9bwpU73vyivdGLVbbzWjejWLS5Rv9EjGNXBPQppUBl
- www.linkedin.com/posts/cirosantilli_httpslnkdineyu8qwc-i-found-44-new-covert-activity-7306015949374058496-X5zl/