
Incoming links: Google Search
BackRub Updated 2025-07-16
This was the original name of Google Search.
One wonders if this name has some influence from the LGBT culture in San Francisco! The sexual innuendo is palpable.
"Back" is of course a reference to "backlinks", since Google Search relies on incoming links (AKA backlinks) to a webpage to determine its importance.
Ciro Santilli's Stack Overflow contributions Updated 2026-01-30

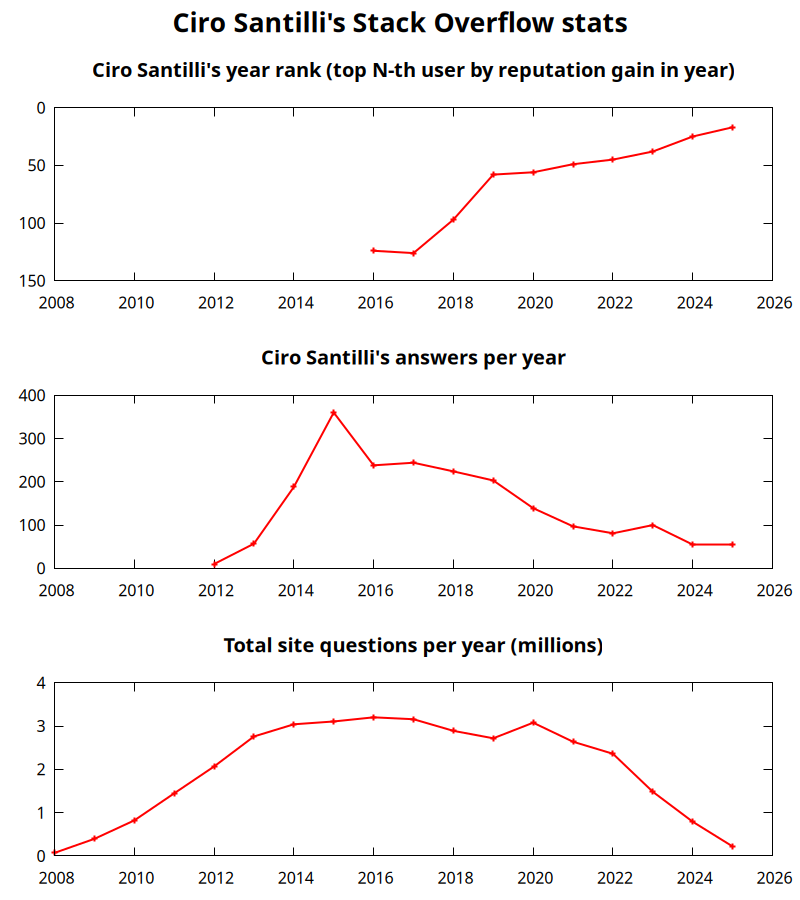
Data compiled for the plot: ciro-santilli-stack-overflow-stats.csv
- top obtained manually from pages such s=as: stackexchange.com/leagues/1/year/stackoverflow/2023-01-01
- answer count obtained with this Stack Exchange Data Explorer data.stackexchange.com/stackoverflow/query/433214/count-of-answers-by-user-over-time?UserId=895245
- total questions obtained with: data.stackexchange.com/stackoverflow/query/1926608/total-questions-asked-per-year-on-stack-overflow
Plot generated with gnuplot with ciro-santilli-stack-overflow-stats.gnuplot
Ciro Santilli's Stack Overflow contributions have, unsurprisingly, centered around the subjects he has worked with: systems programming and web development, and necessary tooling to get those done, such as Git, Python, Bash and Ubuntu.
His best answers are listed at: Section "The best articles by Ciro Santilli".
Stack Overflow has been the initial centerpiece of Ciro Santilli's campaign for freedom of speech in China, until Ciro noticed that GitHub might be potentially even more effective for it.
In Stack Overflow Ciro likes to:
- answer important questions found through Google which he needs to solve an actual problem he has right now, and for which none of the existing answers satisfied him, and close duplicates.
- monitor less known tags which very few people know a lot about and where the knowledge sharing desperately lacking, but in which Ciro specializes and therefore has some uncommon knowledge to share
In practice it also happens that Ciro:
- Googles for his own answers to remember some detail he wrote down but with slightly different terms that were closer to mind at the time, and find other similar questions for which he has the perfect answer.
- learns something new by chance, e.g. some new flashy feature of a new version of the C++ standard, thinks "this is awesome, there must be a Stack Overflow question for it", and then there is a question and he answers it
When he gets an upvote on one of his more obscure answers, Ciro often re-reads it, and often finds improvements to be made and makes them.
He doesn't like to refresh the homepage looking for easy reputation on widely known subjects. See also: online forums that lock threads after some time are evil.
The result is that Ciro ends up getting relatively a lot of reputation without much work! The term passive income, much beloved by fake investment gurus, comes to mind. But now it's "passive reputation"! And it is useless! Yay!
For this reason, Necromancer is Ciro's favorite badge (get 5 upvotes on a question older than 60 days), and as of July 2019, he became the #1 user with the most of this badge. Announcement on Twitter.
The number two at the time was VonC (see also: Section "Epic Stack Overflow users"), who had about 16 times more answers than Ciro in total! From this query: data.stackexchange.com/stackoverflow/query/1072396?&Date=2019-07-01&UserId=895245 it can be seen that as of July 2019, 1216 out of his 1329 answers were answered 60 days after the questions and constitute potential necromancers! Compare that to VonC's 1643 potential necromancers out of 21767 answers!
VonC eventually took back the lead in 2022, dude's a machine!!! twitter.com/cirosantilli/status/1546389532014247936
Someone at Ciro's work once said something along:and this does ring true in Stack Overflow as well. When you are answering stuff, it means that you either didn't know, or that the information wasn't well available, and so your specific application is progressing slowly because of that. Once the generic prerequisites are well solved and answered, you will spend much more time on your business specific things rather than anything else that can be factored out across projects, and so you will get more "directly useful work" done, and less Stack Overflow answers. Of course, without the prior research in place, you can't get the final product done either.
In terms of per year reputation ranks, Ciro was in the top 100 in of the 2018 ranking with 38,710 reputation gained in that year: stackexchange.com/leagues/1/year/stackoverflow/2018-01-01?sort=reputationchange&page=4 (archive). He reached top 50 in 2022. Note that daily reputation is mostly capped to 200 per day, leading to a maximum 73000 per year. It is possible to overcome this limit either with bounties or accepts, and Ciro finds it amazing that some people actually break the 73k limit by far with accepts, e.g. Gordon Linoff reached 135k in 2018 (archive)! However, this is something that Ciro will never do, because it implies answering thousands and thousands of useless semi duplicate questions as fast as possible to get the accept. Ciro's reputation comes purely from upvotes on important question, and is therefore sustainable without any extra effort once achieved. Interestingly, Ciro appeared on top of the quarter SE rankings around 2019-11: web.archive.org/web/20191112100606/https://stackexchange.com/leagues but it was just a bug ;-)
There is no joy like answering an old question, and watching your better answer go up little by little until it dominates all others.
Stack Overflow reputation is of course, in itself, meaningless. People who contribute to popular subjects like web development will always have infinitely more reputation than those that contribute to low level subjects.
What happens on the specialized topics though is that you end up getting to know all the 5 users who contribute 95% of the content pretty soon as you study those subjects.
Like everything that man does, the majority of Ciro's answers are more or less superficial subjects that many people know but few have the patience to explain well, or they are updates to important questions reflecting upstream developments. But as long as they save 15 minutes from someone's life, that's fine.
There is great beauty when you are involved in a programming problem, and you suddenly remember: wait, I answered something related a few years ago! And especially so when you can go back and improve your old answer with new insight. This has great value, because when you were more newbie, you would have typed different words into Google Search than you would now. So by updating posts from when you were a newbie, you are helping other newbies more, as they are more likely to be also searching for those keywords. It is also very nice to have some head start on the answer's upvote count and not have to bootstrap yet another answer from 0 upvotes and have to go through all the competition!
For example, Ciro's most upvoted answer as of July 2019 is stackoverflow.com/questions/18875674/whats-the-difference-between-dependencies-devdependencies-and-peerdependencies/22004559#22004559 was written when he spent his first week playing with NodeJS (he was having a look at Overleaf, later merged into Overleaf, for education), which he didn't touch again for several years, and still hasn't "mastered" as of 2019! This did teach a concrete life lesson to Ciro however: it is impossible to know what is the most useful thing you can do right now very precisely. The best bet is to follow your instincts and do as much awesome stuff as you can, and then, with some luck, some of those attempts will cover an use case.
Ciro tends to take most pride on his systems programming answers, which is a subject that truly relatively few people know about. He likes it when he goes insanely deep into a subject, way beyond what OP had in mind, exposing full root causes and broader causes, see e.g.:
- stackoverflow.com/questions/1778538/how-many-gcc-optimization-levels-are-there/30308151#30308151
- stackoverflow.com/questions/34519521/why-does-gcc-create-a-shared-object-instead-of-an-executable-binary-according-to/55704865#55704865
- stackoverflow.com/questions/8352535/how-does-kernel-get-an-executable-binary-file-running-under-linux/31394861#31394861
Ciro also derives great joy from his "media related answers" (3D graphics, audio, video), which are immensely fun to write, and sometimes borderline art, see answers such as those under "OpenGL" and "Media" under the best articles by Ciro Articles or even simpler answers such as:

There is something of greater value in perfectly presented technical knowledge, that goes beyond than simply getting something done. The pleasure of understanding and mastering something, and perhaps of the explanation itself. Sometimes when answering, Ciro feels like a tailor, where ASCII is his cloth. See also: Section "The art of programming", Section "Physics and the illusion of life".
Ciro's deep understanding of Stack Overflow mechanisms and its shortcomings also helped shape his ideas for: OurBigBook.com. So it is a bit funny to think that after all time Ciro spent on the website, he actually wants to destroy it and replace it with something better. There can be no innovation without some damage. It also led to Ciro's creation of Stack Overflow Vote Fraud Script.
After answering so many questions, he ended up converging to a more or less consistent style, which he formalized at:Like any other style guide, this answer style guide, once fully incorporated and memorized, allows Ciro to write answers faster, without thinking about formatting issues.
- meta.stackexchange.com/questions/18614/style-guide-for-questions-and-answers/326746#326746. Key self-quote:
- meta.stackexchange.com/questions/10647/how-do-i-write-a-good-title/311903#311903. Question title style only. After a few years later more people agreeing with that post which now had -12 votes: meta.stackoverflow.com/questions/422082/should-we-add-option-use-complete-sentences-to-first-answers-queue
Ciro also made a question title style guide: meta.stackexchange.com/questions/10647/how-do-i-write-a-good-title/311903#311903 but for some reason the Stack Overflow community prefers their semi-defined title meta-language to proper English. Go figure.
Ciro started contributing to Stack Overflow in 2012 when he was at École Polytechnique.
Like all things that end up shaping the course of one's life, Ciro started contributing without thinking too much about it.
His first answer was to the LaTeX question: Standalone diagrams with TikZ?, which reflects the fact that this happened while Ciro was reaching his Ciro Santilli's Open Source Enlightenment.
Ciro's first upvote was for his 2012 question: How to run a Python script portably without specifying its full path?
When he started contributing, Ciro was still a newbie. One early event he will never forget was when someone mentioned a "man page", and Ciro commented saying that there was a typo!
When Ciro reached 15 points and gained the ability to upvote, it felt like a major milestone, he even took a screenshot of the browser! 1k, 10k and 100k were also particularly exciting. When the 100k cup (archive) arrived in 2018, Ciro made a show-off Facebook post (archive). At some point though, your brain stops caring, and automatically filters out any upvotes you get except on the answers that you are really proud of and which don't yet have lots of upvotes. The last remaining useless gamed achievement that Ciro looked forward to was legendary (archive), and which he achieved on 2021-02-16.

From the start, Ciro's motivations for contributing to Stack Overflow have been a virtuous circle of:
- save the world through free education
- It feels especially amazing when people in the real world start taking note of you, and either close friends tell you straight out that you're a Stack Overflow God, or as you slowly and indirectly find out that less close know or came to you due to your amazing contributions.
It is also amazing when you start having a repertoire of answers, and as you are writing a new answer, you remember: "hey, the knowledge of that answer would be so welcome here", and so you link to the other answer as well at the perfect point. This somewhat achieves does what OurBigBook.com aims to do: for each small section of a tutorial, gather the best answers by multiple people.
Another one is Aaron Hall, who is also very high on the necromancer list, answers in Python which is a topic Ciro cares about, and states on his profile:so another necromancer.
Follow me on Twitter and tell me what canonical questions you would like me to respond to!
Way to go.
Ciro also asks some questions on a ratio of about 1 question per 10 answers. But Ciro's questions tend to be about extremely niche that no one knows/cares about, and a high percentage of them ends up getting self answered either at asking time or after later research.
Some fun reactions to Ciro's Stack Overflow activity:
- Eric B comments[ref] on Ciro's answer to the question "What does multicore assembly language look like?":
Holy shit, Ciro made it his masters degree to write OP an answer. What a long and detailed answer, thanks!
Scott Hassan Updated 2025-07-16
The guy who coded the initial version of BackRub, the first version of Google Search, but left before the company formed. TODO how did he meet Largey Brage? Why did he leave Google?
In 1997 he cofounded eGroups, a mailing list management website, together with the mysterious Carl Victor Page, Jr., Larry Page's older brother. eGroups was sold to Yahoo! in 2000 for $432m, just before the Dot-com bubble burst.
As of 2021 his net worth was of "only" $1b, even though his original Google shares would have been worth $13b. He must have sold too much too early to do other cool stuff. archive.ph/IgkMI:Did Largey give him this nice deal as a way to thank him for helping start the company, or was it just that they had no big hopes and $800 seemed right? youtu.be/pmXDtTD6vQY?t=146 suggests the stocks were part of his compensation for 3 months of coding work. Also mentioned at: nypost.com/2021/08/20/google-founder-created-revenge-site-against-estranged-wife
When Mr. Page and Mr. Brin founded Google in 1998, Mr. Hassan bought 160,000 shares for $800. When Google went public in 2004, the shares were worth more than $200 million. The shares, now in Google’s parent company, Alphabet, would be valued at more than $13 billion today [2021].

In 2001, Scott married a Vietnamese chick called Allison Huynh from university and they had three children.
In 2004 he tried strike a $20 million[ref] post-nuptial after Google went public, which she declined, so things were already crappy back then.
Then, during the divorce, Scott even created a revenge website for her as well. He's so petty! Down as of 2024 of course. There are only some weird redirect archives now: web.archive.org/web/20210915000000*/https://allisonhuynh.com redirecting to sites.google.com/view/allisonhuynhcom
The divorce is covered in several major outlets:
- www.dailymail.co.uk/news/article-9912929/Billionaire-investor-helped-launch-Google-accused-divorce-terrorism-bitter-break-up.html
- www.nytimes.com/2021/08/20/technology/Scott-Hassan-Allison-Huynh-divorce.html
- www.cnbctv18.com/technology/who-is-scott-hassan-the-google-founder-accused-of-divorce-terrorism-10543641.htm
- www.forbes.com/sites/jilliandonfro/2020/02/28/suitable-technologies-bankruptcy-filing-scott-hassan-allison-huynh/
To be fair, he did work on a lot of cool stuff after BackRub for which he deserves credit, not the least the company that created the Robot Operating System, which is a cool sounding open source project, which is awesome. But this divorce story is so damning! He should just own up to it, split the cash, and move on... The fact that the Google money came from an investment before marriage likely complicates things.
The fact that he does not have a Wikipedia page as of 2022 is mind blowing, especially after divorce details. Maybe Ciro Santilli will create it one day. Just no patience now. OK, done it June 2022: en.wikipedia.org/wiki/Scott_Hassan let's see if it lasts. The page lasted but ended up being Ciro Santilli's first edit war, how exciting:
- December 2022: an anonymous user with IP from California removed divorce details and google share ownership details, both of which had a New York Times source: www.nytimes.com/2021/08/20/technology/Scott-Hassan-Allison-Huynh-divorce.html. Discussion at: en.wikipedia.org/wiki/Talk:Scott_Hassan#Divorce_details_removed_as_%22poorly_sourced_material%22_by_anonymous_user_even_though_they_had_a_source_from_the_New_York_Times It feels exactly like the type of thing Scott would have done himself. And he possibly inadvertently exposed his real IP in doing so: 24.6.226.102. It is pingable, but Nmap analysis shows nothing of interest.
- June 2024: another partial revert removing the juicy divorce details by user named "ReversingWrongs". The username choice so incredibly cute and naive it makes Ciro wonder if this is from some woman that loves him (mother, child, new partner?) rather than just a Hassan sockpuppet. OK, perhaps with en.wikipedia.org/wiki/Wikipedia:Biographies_of_living_persons#People_who_are_relatively_unknown the divorce has to be left out? It's always impossible to decide with those wikipedia things. What you can say, is not necessarily what people want to read about, even when it is incredibly well source.
Looking a the history, he just kept revealing different IPs and continuously reverting, which other people put back in. Another of his IPs:There is also an interesting edit from 2600:1700:5470:5c50:7566:9580:1b60:ab41 which mentions without source the little known factso it could be Hassan adding some actually good and interesting information to the article. That one however also has an edit to en.wikipedia.org/wiki/Ernest_Nagel so maybe it's not him.
after working at Washington University's Medical Libraries Group (having been recruited out of SUNY Buffalo for the summer).


Screenshot of allisonhuynh.com by the Daily Mail
. Source. Updates Older updates Created 2024-08-10 Updated 2025-07-16
- en.wikipedia.org/wiki/Scott_Hassan I delved into a bit of Wikipedia drama on the page of Scott Hassan, initial coder of Google Search, which I created an am the main contributor.Originally I had added some details about this messy divorce which saw coverage in major publications such as the New York Times: www.nytimes.com/2021/08/20/technology/Scott-Hassan-Allison-Huynh-divorce.html and Scott used puppets to remove those at several points in time over the years.Those removals were then reverted by other editors, not myself, indicating that editors wanted the details there.While preparing to finally decide this through moderation, I ended up finding that the divorce details should likely have been left out according to Wikipedia rules, because Scott is "relatively unknown" and a "low profile individual":and so I ended up removing them myself.This is yet once again deletionism on Wikipedia weakening the site, and making @OurBigBook stronger :-) Here is the uncensored one: Scott Hassan
- unix.stackexchange.com/questions/256138/is-there-any-decent-speech-recognition-software-for-linux/613392#613392 cool to see that the Vosk open source speech recognition software by twitter.com/alphacep now has a convenient command line interface called vosk-transcriber!It allows you to just:
vosk-transcriber -m ~/var/lib/vosk/vosk-model-en-us-0.22 -i in.ogg -o out.srt -t srt - video.stackexchange.com/questions/33531/how-to-remove-background-from-video-without-green-screen-on-the-command-line/37392#37392 tested this AI video background remover github.com/nadermx/backgroundremover by @nadermx. It had a few glitches, but I had fun.
 unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093
unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093 Posted at:
Posted at: - Just found out that my Lenovo ThinkPad P14s has an infrared camera, and recorded a quick test video on Ubuntu 23.10 with:
fmpeg -y -f v4l2 -framerate 30 -video_size 640x360 -input_format gray -i /dev/video2 -c copy out.mkv- mastodon.social/@cirosantilli/112261675634568209
- twitter.com/cirosantilli/status/1778981935257116767
- www.facebook.com/cirosantilli/posts/pfbid027M3n2p8snE9otAWdHtJ3ig2AhrXoDGv4h68o1z8agHceQBbFHZpEoxg7KZbiWAgWl
- www.linkedin.com/feed/update/urn:li:activity:7184755892410576897/
- www.youtube.com/watch?v=o1ZeR6pmf6o
- commons.wikimedia.org/wiki/File:Infrared_video_of_Ciro_Santilli_waving_recorded_on_Lenovo_ThinkPad_P14s_with_FFmpeg_6.0_on_Ubuntu_23.10.webm

Figure 1. Ciro Santilli waving hello in infrared.