
Local symmetries of the Lagrangian imply conserved currents Updated 2025-07-16
More precisely, each generator of the corresponding Lie algebra leads to one separate conserved current, such that a single symmetry can lead to multiple conserved currents.
This is basically the local symmetry version of Noether's theorem.
Then to maintain charge conservation, we have to maintain local symmetry, which in turn means we have to add a gauge field as shown at Video "Deriving the qED Lagrangian by Dietterich Labs (2018)".
Bibliography:
- photonics101.com/relativistic-electrodynamics/gauge-invariance-action-charge-conservation#show-solution has a good explanation of the Gauge transformation. TODO how does that relate to symmetry?
- physics.stackexchange.com/questions/57901/noether-theorem-gauge-symmetry-and-conservation-of-charge
London Updated 2025-07-16
Yung Professional Move to London by Sans Beanstalk
. Source. The sad thing is that the same author also has another accurate video criticizing British suburbia, so there's no escape basically in the UK: www.youtube.com/watch?v=oIJuZbXLZeY.
Video "Being a Dickhead's Cool by Reuben Dangoor (2010)" also comes to mind.
Loop (topology) Updated 2025-07-16
Lord of the Rings character Updated 2025-07-16
Lorentz covariance Updated 2025-07-16
Same motivation as Galilean invariance, but relativistic version of that: we want the laws of physics to have the same form on all inertial frames, so we really want to write them in a way that is Lorentz covariant.
This is just the relativistic version of that which takes the Lorentz transformation into account instead of just the old Galilean transformation.
Lorentz gauge condition Updated 2025-07-16
E.g. thinking about the electric potential alone, you could set the zero anywhere, and everything would remain be the same.
The Lorentz gauge is just one such choice. It is however a very popular one, because it is also manifestly Lorentz invariant.
Poincaré group Updated 2025-07-16
Full set of all possible special relativity symmetries:
In simple and concrete terms. Suppose you observe N particles following different trajectories in Spacetime.
There are two observers traveling at constant speed relative to each other, and so they see different trajectories for those particles:Note that the first two types of transformation are exactly the non-relativistic Galilean transformations.
- space and time shifts, because their space origin and time origin (time they consider 0, i.e. when they started their timers) are not synchronized. This can be modelled with a 4-vector addition.
- their space axes are rotated relative to one another. This can be modelled with a 4x4 matrix multiplication.
- and they are moving relative to each other, which leads to the usual spacetime interactions of special relativity. Also modelled with a 4x4 matrix multiplication.
The Poincare group is the set of all matrices such that such a relationship like this exists between two frames of reference.
Poincaré sphere Updated 2025-07-16
In it, each of the six sides has a clear and simple to understand photon polarization state, either of:
The sphere clearly suggests for example that a rotational or diagonal polarizations are the combination of left/right with the correct phase. This is clearly explained at: Video "Quantum Mechanics 9b - Photon Spin and Schrodinger's Cat II by ViaScience (2013)".
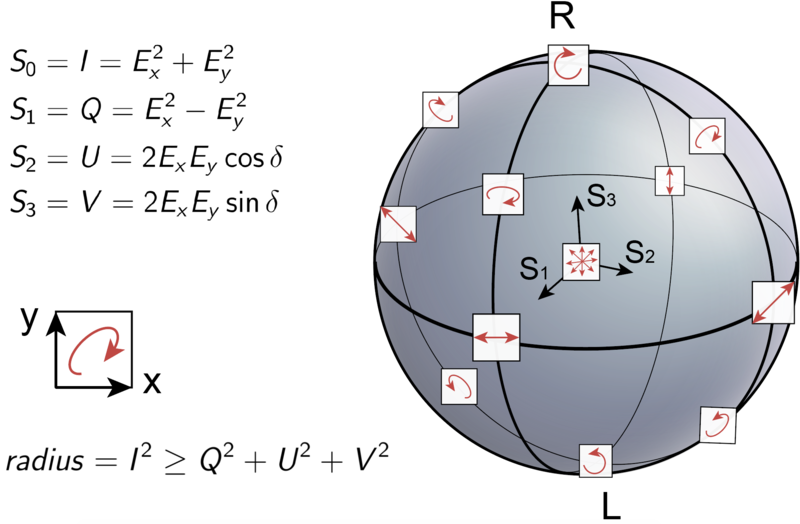
{kind=link}
Politics of Europe Updated 2025-07-16
Polymerase chain reaction Updated 2025-07-16
This is an extremely widely used technique as of 2020 and much earlier.
If allows you to amplify "any" sequence of choice (TODO length limitations) between a start and end sequences of interest which you synthesize.
If the sequence of interest is present, it gets amplified exponentially, and you end up with a bunch of DNA at the end.
You can then measure the DNA concentration based on simple light refraction methods to see if there is a lot of DNA or not in the post-processed sample.
Even Ciro Santilli had some contact with it at: Section "How to use an Oxford Nanopore MinION to extract DNA from river water and determine which bacteria live in it", see: PCR!
One common problem that happens with PCR if you don't design your primers right is: en.wikipedia.org/wiki/Primer_dimer
Sometime it fails: www.reddit.com/r/molecularbiology/comments/1kouomw/when_your_pcr_fails_again_and_you_start/and a comment:
Nothing humbles you faster than a bandless gel. One minute you’re a scientist, the next you’re just a pipette-wielding wizard casting spells that don’t work. Meanwhile, physicists are out there acting like gravity always behaves. Smash that upvote if your reagents have ever gaslit you.
PCR = Pray, Cry, Repeat
Freedom of speech Updated 2025-07-16
For Ciro Santilli's campaign for freedom of speech in China: Section "github.com/cirosantilli/china-dictatorship".
Ciro has the radical opinion that absolute freedom of speech must be guaranteed by law for anyone to talk about absolutely anything, anonymously if they wish, with the exception only of copyright-related infringement.
And Ciro believes that there should be no age restriction of access to any information.
People should be only be punished for actions that they actually do in the real world. Not even purportedly planning those actions must be punished. Access and ability to publish information must be completely and totally free.
If you don't like someone, you should just block them, or start your own campaign to prepare a counter for whatever it is that they are want to do.
This freedom does not need to apply to citizens and organizations of other countries, only to citizens of the country in question, since foreign governments can create influence campaigns to affect the rights of your citizens. More info at: cirosantilli.com/china-dictatorship/mark-government-controlled-social-media
Limiting foreign influence therefore requires some kind of nationality check, which could harm anonymity. But Ciro believes that almost certainly such checks can be carried out in anonymous blockchain consensus based mechanisms. Governments would issues nationality tokens, and tokens are used for anonymous confirmations of rights in a way that only the token owner, not even the government, can determine who used the token. E.g. something a bit like what Monero does. Rights could be checked on a once per account basis, or yearly basis, so transaction costs should not be a big issue. Maybe expensive proof-of-work systems can be completely bypassed to the existence of this central token authority?
Some people believe that freedom of speech means "freedom of speech that I agree with". Those people should move to China or some other dictatorship.
Frobenius theorem (real division algebras) Updated 2025-07-16
Notably, the octonions are not associative.
From first principles Updated 2025-07-16
Los Alamos From Below by Richard Feynman (1975) Updated 2025-07-16
Amazing talk by Richard Feynman that describes his experiences at Los Alamos National Laboratory while developing the first nuclear weapons.
Transcript: calteches.library.caltech.edu/34/3/FeynmanLosAlamos.htm Also included full text into Surely You're Joking, Mr. Feynman.
- www.youtube.com/watch?v=uY-u1qyRM5w&t=2881s describes the computing aspects. Particularly interesting is the quote about how they used the typist secretary pool to emulate the IBM machines and debug their programs before the machines had arrived. This is exactly analogous to what is done in 2020 in the semiconductor industry, where slower models are used to estimate how future algorithms will run in future hardware.
Polynomial over a field Updated 2025-07-16
However, a polynomial can be defined over any other field just as well, the most notable example being that of a polynomial over a finite field.
For example, given the finite field of order 9, and with elements , we can denote polynomials over that ring aswhere is the variable name.
For example, one such polynomial could be:and another one:Note how all the coefficients are members of the finite field we chose.
Polynomial over a ring Updated 2025-07-16
However, there is nothing in the immediate definition that prevents us from having a ring instead, i.e. a field but without the commutative property and inverse elements.
The only thing is that then we would need to differentiate between different orderings of the terms of multivariate polynomial, e.g. the following would all be potentially different terms:while for a field they would all go into a single term:so when considering a polynomial over a ring we end up with a lot more more possible terms.
If the ring is a commutative ring however, polynomials do look like proper polynomials: Section "Polynomial over a commutative ring".
Possible new effects in superconductive tunnelling Updated 2025-07-16
The inaugural that predicted the Josephson effect.
Published on Physics Letters, then a new journal, before they split into Physics Letters A and Physics Letters B. True Genius: The Life and Science of John Bardeen mentions that this choice was made rather than the more prestigious Physical Review Letters because they were not yet so confident about the results.
Git design rationale Updated 2025-07-16
The fundamental insight of Git design is: a SHA represents not only current state, but also the full history due to the Merkle tree implementation, see notably:
This makes it so that you will always notice if you are overwriting history on the remote, even if you are developing from two separate local computers (or more commonly, two people in two different local computers) and therefore will never lose any work accidentally.
It is very hard to achieve that without the Merkle tree.
Consider for example the most naive approach possible of marking versions with consecutive numbers:
GitHub's replacement of
master branch with main (2020) Updated 2025-07-16By GitHub around Black Lives Matter, due to a possible ludicrous relationship with slavery of black people:
For the love of God, the word "master" is much more general than black slavery. If you are going to ban it, you might as well ban the word "evil".
GitLab Updated 2025-07-16
See also: Ciro Santilli's minor projects.
Unlisted articles are being shown, click here to show only listed articles.