
Incoming links: Ciro Santilli
ChatGPT is killing Stack Overflow Created 2025-01-21 Updated 2025-07-16
Ciro Santilli believes that these tools basically solve all the brain-dead problems which newbies would ask, and easy rep seekers would reply to.
Also, because Ciro Santilli only goes for long term reputation, which often means hard questions, this shot his yearly reputation rankings up without him doing anything, because all the guys who answered easy questions were decimated.
This was followed by Stack Overflow attempting to immorally and likely illegally trying to restrict free access to its previously commendable data dumps:which people were using to train LLMs.
This can be very clearly seen by several metrics on Stack Exchange Data Explorer, e.g. Ciro Santilli noticed that very clearly at: Total reputation in Stack Overflow over time how activity has been steadily falling since 2020.

By Ciro Santilli using gnuplot. Methodology described at: Ciro Santilliś answer to the question "Total reputation in Stack Overflow over time". The 15 year old question was then closed soon after Ciro Santilli answered it, because of course that attracted some attention to the question, which of course was off-topic.

Questions asked per month on Stack Overflow
. Source. Also announced at:Related posts:
- www.reddit.com/r/programming/comments/1592s82/the_fall_of_stack_overflow/. www.reddit.com/r/programming/comments/1592s82/comment/jte8aju/ is amazing:Well known Stack Overflow user mipadi comments:You've fallen for the common misconception that the goal of stackoverflow is helping users solve problems.When the reality is that it's actually a video game. The only players are the admins/mods, and their goal is to use their "hammers" and attempts at pedantry/nitpicking (correctness not important) to compete with each other to get the highest "close" point scores. Pew pew pew!!! Bang bang bang!!! How many points can you score today?!?!Ciro Santilli concurs, for professional niche sites. Non-professional ones are fine.
And the niche Stack Exchange sites tend to be even worse, although I can still get a question answered after much teeth gnashing, usually.
- www.reddit.com/r/programming/comments/195ygru/stackoverflow_questions_down_66_in_2023_compared/ StackOverflow Questions Down 66% in 2023 Compared to 2020. Links to: x.com/v_lugovsky/status/1746275445228654728 "What's happening with StackOverflow?" by user Vlad
- www.reddit.com/r/computerscience/comments/1fri2jt/does_anyone_still_use_stack_overflow_or_has_the/
- observablehq.com/@ayhanfuat/the-fall-of-stack-overflow
- data.stackexchange.com/stackoverflow/query/1882511/questions-asked-per-year-on-stack-overflow#graph Questions asked per year on Stack Overflow
- news.ycombinator.com/item?id=41364798
China Updated 2025-07-16
The most awesome country in the world, except for it's horrible government as of 2019 which Ciro Santilli is trying to replace with democracy.
Chinese cuisine Updated 2025-07-16
One of the best in the world, but you need to know how to find real restaurants if you are not in China.
But worry not, Ciro Santilli has got you covered: github.com/cirosantilli/china-dictatorship/restaurants
- www.youtube.com/channel/UC54SLBnD5k5U3Q6N__UjbAw Chinese Cooking Demystified. Possibly the best YouTube channel at explaining how to make key Chinese dishes and sauces in English.
Some stuff at: cirosantilli.com/china-dictatorship/#the-best-chinese-food but that is bound to die one guesses.
Chinese traditional music Updated 2025-07-16
The best instrumental songs: Section "The best Chinese traditional instrumental music"
In the process of moving out of: cirosantilli.com/china-dictatorship/music
Bibliography:
- Ciro Santilli's YouTube playlist: www.youtube.com/playlist?list=PLcZOZrP1P_V5J2P3ogZNpya0BAuPEgyuE
- Reddit:
- www.reddit.com/r/classicalmusic/comments/op54d5/traditional_chinese_music_recommendations_helpful/ "Traditional Chinese Music Recommendations & Helpful Sources" by
_AsyA_(2021). This user knows a bit as shown in description. - www.reddit.com/r/China/comments/1ejy8jw/how_to_get_into_traditionalclassical_chinese_music/ "How to get into traditional/classical chinese music?" by Ultimate_CockSucker (2024)
- www.reddit.com/r/Chinese/comments/150sf4y/what_are_some_really_good_traditional_chinese/ "What are some really good Traditional Chinese music artists?" by Flimsy-Assumption513 (2023)
- www.reddit.com/r/classicalmusic/comments/op54d5/traditional_chinese_music_recommendations_helpful/ "Traditional Chinese Music Recommendations & Helpful Sources" by
Chromium sometimes freezes due to autofill on omnibox Created 2025-03-20 Updated 2025-07-16
This has happened a few times a day on Ubuntu 24.10 and Chromium 133. It has also been happening in previous versions of Ubuntu and Chromium.
As Ciro Santilli starts typing on the omnibox, sometimes the window freezes and the dreaded "is not responding" window shows up.
CIA 2010 covert communication websites Updated 2026-02-12
This article is about covert agent communication channel websites used by the CIA in many countries from the mid 2000s until the early 2010s, when they were uncovered by counter intelligence of some of the targeted countries, notably Iran and China, circa 2010-2013.
This article uses publicly available information to publicly disclose for the first time a few hundred of what we feel are extremely likely candidate sites of the network. The starting point for this research was the September 2022 Reuters article "America’s Throwaway Spies" which for the first time gave nine example websites, and their analyst from Citizenlabs claims to have found 885 websites in total, but did not publicly disclose them. Starting from only the nine disclosed websites, we were then able to find a few hundred websites that share so many similarities with them, i.e. a common fingerprint, that we believe makes them beyond reasonable doubt part of the same network.
If you enjoy this article, consider dropping some Monero at: 4A1KK4uyLQX7EBgN7uFgUeGt6PPksi91e87xobNq7bT2j4V6LqZHKnkGJTUuCC7TjDNnKpxDd8b9DeNBpSxim8wpSczQvzf so I can waste it on my foolish attempts to improve higher education. Other sponsorship methods: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
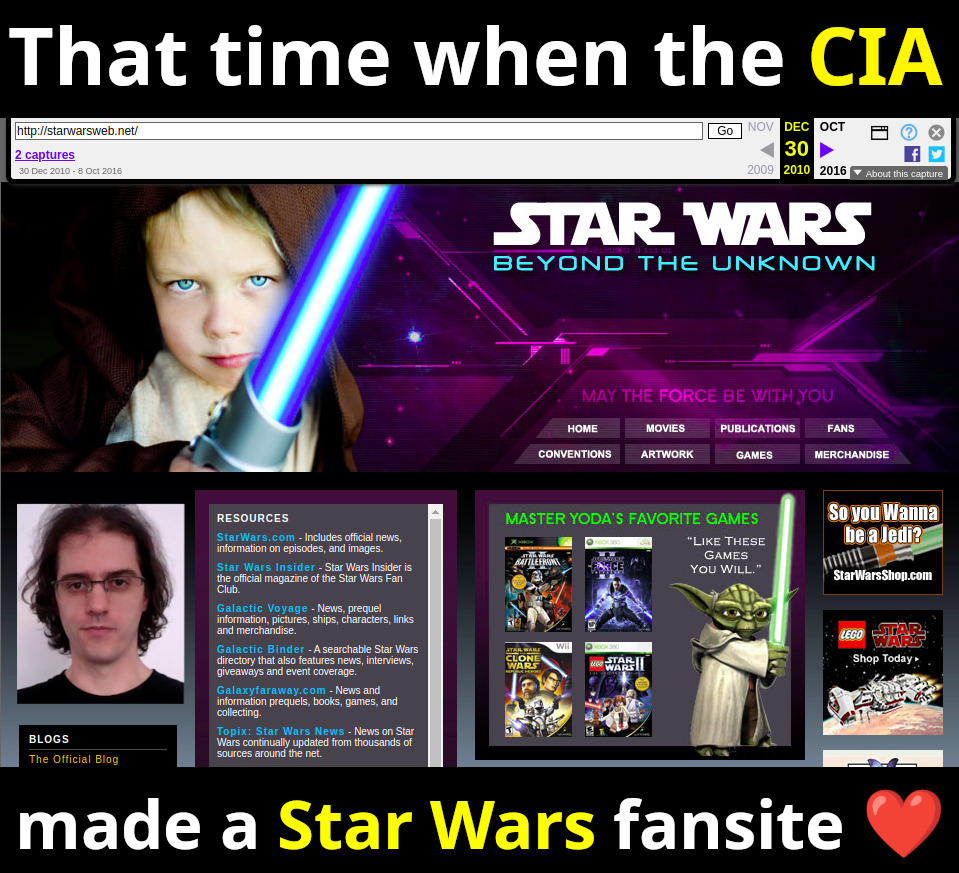
The discovery of these websites by Iranian and Chinese counterintelligence led to the imprisonment and execution of several assets in those countries, and subsequent shutdown of the channel by the CIA when they noticed that things had gone wrong. This is likely a Wikipedia page that talks about the disastrous outcome of the websites being found out: 2010–2012 killing of CIA sources in China, although it contained no mention of websites before Ciro Santilli edited it in.
Of particular interest is that based on their language and content, certain of the websites seem to have targeted other democracies such as Germany, France, Spain and Brazil.
If anyone can find others websites, or has better techniques feel free to contact Ciro Santilli at: Section "How to contact Ciro Santilli". Contributions will be clearly attributed if desired. Some of the techniques used so far have been very heuristic, and that added to the limited amount of data makes it almost certain that some websites have been missed. Broadly speaking, there are two types of contributions that would be possible:
- finding new IP ranges: harder and more exiting, and potentially requires more intelligence
- better IP to domain name databases to fill in known gaps in existing IP ranges
The fact that citizenlabs reported exactly 885 websites being found makes it feel like they might have found find a better fingerprint which we have not managed to find yet. We have not yet had to pay for our data. If someone wants to donate to the research, some ideas include:
- dump $400 on WhoisXMLAPI to dump whois history of all known hits and search for other matches. Small discoveries were made like this in the past and we'd expect a few more to be left. We don't expect huge breakthroughs from this, but at only $400 it is not so bad
- dump a lot more ($15k+? needs confirmation as opaque pricing) on DomainTools. We are not certain that they have any superior data since there is no free trial of any kind, but it would be interesting to test the quality of the data they acquired from Farsight DNSDB if you are really loaded
Disclaimers:
- the network fell in 2013, followed by fully public disclosures in 2018 and 2022, so we believe that the benefit of giving the public this broader historic understanding outweighs the risks that agents could be found so many years later by sloppy secret services
- Ciro Santilli's political bias is strongly pro-democracy and anti-dictatorship, but with a good pinch of skepticism about the morality US foreign policy in the last century
CIA 2010 covert communication websites Backlinks Updated 2025-08-08
Announcements and updates by self:
- 2023-06-10: initial announcements
- twitter.com/cirosantilli/status/1667532991315230720. Follow up when more domains were found: twitter.com/cirosantilli/status/1717445686214504830
- www.reddit.com/r/OSINT/comments/146185r/i_found_16_new_cia_covert_communication_websites/. Marked as SPAM 5 by mods days later. After reaching 92 votes, a very positive reply for that niche sub, and being obviously on topic. Weird. Anyways, did its job and likely kicked off hackernews.
- www.facebook.com/cirosantilli/posts/pfbid04KvRbEXghJakcD4AQz4379L5oVjPZ6vrBF1Eak3p81VnqRSXuXdvvYonCWPhGfQXl
- 2023-10-26 twitter.com/cirosantilli/status/1717445686214504830: announcement by self after finding 75 more sites
- Shared by others soo after:
- www.reddit.com/r/conspiracy/comments/14705gp/cia_2010_covert_communication_websites/ failed attempt with bad link unfortunately
- 2024-01-15: twitter.com/cirosantilli/status/1747742453778559165 Oleg Shakirov's findings
- 2024-01-23: mastodon.social/@cirosantilli/111807480628392615 ipinf.ru gives 4 hits and 4 new suspects, announced at:
- 2024-09 Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects
- 2025-03-13: 44 new domains found: Section "44 new CIA websites"
- 2025-04-14: cqcounter screenshots used to confirm many new hits: Section "60 new CIA website screenshots discovered on CQ Counter"
- 2025-05-23: Section "Backing up CIA website archives for research and posterity"
Pings by self:
- 2025-03-13:
- x.com/cirosantilli/status/1900278353065894324 pings x.com/JackRhysider Jack Rhysider, host of the Darkent Diaries podcast
- x.com/cirosantilli/status/1900828210578727276 pings x.com/JennaMC_Laugh Jenna McLaughlin and x.com/zachsdorfman Zach Dorfman, authors of the 2018 Yahoo articles
- 2025-03-31 going to find random interested people on Twitter:
- 2025-05-05:
- inteltoday.org/2021/07/31/us-national-whistleblower-day-july-30-2021-i-john-reidy-declare-cia-debacle-in-iran-china/#comment-46375 pings the author Dr. Ludwig De Braeckeleer. Besides his interest in intelligence, the dude actually also won a Breakthrough Prize in Physics, holy fuck it's mind boggling.
- x.com/cirosantilli/status/1919391488422662245 pings x.com/marisaataylor Marisa Taylor, author of the 2014, McClathy DC article
- x.com/cirosantilli/status/1919859345593880812 and x.com/cirosantilli/status/1919846838850499002 pings x.com/billmarczak Bill Marczak and x.com/thezedwards Zach Edwards, technical analysts for the Reuters article
- x.com/cirosantilli/status/1919860643408007644 pings x.com/joel_schectman Joel Schectman and x.com/bozorgmehr Bozorgmehr Sharafedin authors of the Reuters article
- x.com/cirosantilli/status/1919870831758365113 pings x.com/zachsdorfman Zach Dorfman (protected account) author of the Foreign Policy article
- x.com/cirosantilli/status/1920073080363241727 pings x.com/markmazzettinyt Mark Mazzetti, x.com/nytmike Michael S. Schmidt and x.com/mattapuzzo Matt Apuzzo authors of the 2017 New York Times article. Could not find a Twitter for the fourth author Adam Goldman.
- x.com/PeteWilliamsNBC Pete Williams author of the 2018 NCB News artricle: he's retired and not active on Twitter, not going to bother pinging
Reactions by others:
- 2023-06-19: www.reddit.com/r/numberstations/comments/14dexiu/after_numbers_stations_vanished/ (30 points) off topic on that sub, but thankfully was not deleted, interesting sub topic
- 2023-10-26: Google Analytics backlink from lms.fh-wedel.de/ path unknown. Some shitty German university: en.wikipedia.org/wiki/Fachhochschule_Wedel_University_of_Applied_Sciences LMS stands for Learning management system, apparently a Moodle instance. Maybe they have some Open educational resources, but all in German so pointless
- Second wave:
- 2023-12-01: news.ycombinator.com/item?id=38492304 (65 points). Second submission but pointing to OurBigBook.com rather than cirosantilli.com: ourbigbook.com/cirosantilli/cia-2010-covert-communication-websites We take those. Reached only 65 points as of January 2024.
- 2023-12-02: buttondown.email/grugq/archive/december-2-2023/. "grugq" is the handle of a zero day dealer whose received some scrutiny in 2012 after a Forbes protile was written about him: archive.ph/7mUG5. He comments:presumably referring to DNS Census 2013.
I don’t think anyone anticipated that databases leaked by hackers would enable OSINT researchers to conduct counterintelligence investigations that rival the state security services.
- 2024-01-12: twitter.com/jeremy_wokka/status/1745657801584656564 (40k followers, mid of thread)
- 2025-04-02: www.reddit.com/r/wikipedia/comments/1kd7rzo/comment/mqoocu7/?context=3 user Gilda1234_ mentions this project in a comment to "Between 2010 and 2012, China identified and killed at least 30 CIA informants in the country" by idlikebab
- 2025-05-26 The CIA Secretly Ran a Star Wars Fan Site by Joseph Cox from 404 media, an upstart publication covering edgy digital subjects. This was likely a result of Ciro publicly pinging x.com/zachsdorfman Zach Edwards, one of the analysts for the Reuters article, at x.com/cirosantilli/status/1919846838850499002, as he is cited in the article as having done a technical review. This had a massive knowdown effect and several other media picked the story up. Ciro announcing it at:Forum threads spawned from it:Other media that picked it up:
- Reddit
- www.reddit.com/r/StarWars/comments/1kvtzwm/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/StarWarsEU/comments/1kvu5g8/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/nottheonion/comments/1kxtpw4/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/nottheonion/comments/1kxtpw4/comment/muu531n/A source: www.thesun.co.uk/sport/33904606/putin-spies-cristiano-ronaldo-youtube-videos-messages/
They aren’t the only ones who do stuff like this, Russian agents were using Ronaldo highlight vids on YouTube to communicate 😭
- www.reddit.com/r/nottheonion/comments/1kxtpw4/comment/muu531n/
- www.reddit.com/r/Games/comments/1kye0pj/the_cia_operated_a_network_of_gaming_sites_and/
- www.reddit.com/r/technology/comments/1kvvx48/the_cia_secretly_ran_a_star_wars_fan_site_the/
- www.reddit.com/r/realtech/comments/1kvwigb/the_cia_secretly_ran_a_star_wars_fan_site_the/
- www.reddit.com/r/conspiracy/comments/1kw991t/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/LowStakesConspiracies/comments/1kwbf2y/the_cia_run_a_star_wars_fansite/
- www.reddit.com/r/andor/comments/1kw587c/very_andor_the_cia_secretly_ran_a_star_wars_fan/
- www.reddit.com/r/BrasildoB/comments/1kw6qah/um_brasileiro_acaba_de_publicar_detalhes_sobre_os/
- www.reddit.com/r/mexico/comments/1kwhuqg/la_incre%C3%ADble_web_de_star_wars_que_us%C3%B3_la_cia_para/
- www.reddit.com/r/KotakuInAction/comments/1kwoch5/the_cia_ran_a_star_wars_fan_site_to_secretly/
- www.reddit.com/r/starwarscanon/comments/1kwoxoq/til_the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/TrueAnon/comments/1kwhxmj/cia_ran_star_wars_fan_site/
- www.reddit.com/r/MauLer/comments/1kxqim9/figures/
- www.reddit.com/r/Intelligence/comments/1kwybso/cia_uses_star_wars_website_to_communicate_with/
- www.reddit.com/r/StarWarsCirclejerk/comments/1kwzeto/in_my_mind_all_last_jedi_haters_are_feds/
- www.reddit.com/r/memes/comments/1kw5x9n/the_cia_really_gets_creative_sometimes/
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/the_cia_secretly_ran_a_star_wars_fan_site_for/
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/comment/muemkhk/ brings up
europeangoldfinch.netfirst described in Season 2 of Prison Break in 2007.Europeangoldfinch.net was a website used by Michael Scofield that allowed the Fox River Eight to communicate with each other on its online message board
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/comment/muemkhk/ brings up
- Decent tweets:
- x.com/CultureCrave/status/1927119278047727908 600k followers
- x.com/val_reloaded/status/1927349417306161165 Argentinian Twitcher 400k followers
- news.ycombinator.com/item?id=44098274 failed unfortunately
- knockout.chat/thread/72492/1
- fanlore.org/wiki/2009-2013_CIA_communications_websites
- YouTube
Video 1. . Source. 2025-05-27. 180k subs. This one focuses on talking about the games and uses this article as the mainreference. He makes that nice note that the game Star Wars Battlefront II reached all time highs in the days following the CIA releasejThe articles apparenty coincided with the reelase of Star Wars Battlefront III alpha to lukewarm reception. Video 2. Star Wars Fan Sites Are Run by THE FEDS?! by Clownfish TV. Source. 2025-05-27. 600k subs. Video didn't take off however. The channel seems to be semi dead. But it is cool to see an American with YouTube-worth eloquence going over it.Video 3. . Source. 2025-05-28. 2M subs. He's basically reading the techspot article: www.techspot.com/news/108062-cia-used-star-wars-fan-site-secretly-communicate.html. Video 5. . Source. Seytonic had previously covered Reuters article at this other video:Video 8. . Source. 2025-06-13. 12k subs. This video draws on some research from this article, citing it on the source list: docs.google.com/document/d/1k7-YoOMRTL8qKE_FoRnyvR1QDa0JTBJo_a-SRwVMEu4/edit?tab=t.0 and using some of the screenshots.This video has some good mentions of the details of Jerry Chun Shing Lee's story which Ciro Santilli was not aware of. - other voice media:
- Meneame, a Spanish Reddit: 2025-05-27 www.meneame.net/m/tecnolog%C3%ADa/increible-web-star-wars-uso-cia-espiar-espana-mexico-otros/standard
Starting on that same day someone made starwarsweb.net redirect to cia.gov at 2025-05-26T13:28:02Z: www.whois.com/whois/starwarsweb.net- "mainstream":
- www.dailymail.co.uk/news/article-14752155/CIA-fake-websites-Star-Wars-communicate-spies.html Also announcing that:
* mastodon.social/@cirosantilli/114580297330915997
* x.com/cirosantilli/status/1927373757829583344
* www.linkedin.com/posts/cirosantilli_the-cia-secretly-ran-a-star-wars-fan-site-activity-7333140418504646656-eRzq/
* www.facebook.com/cirosantilli/posts/pfbid026kssQcXm7TwAHDJ4BQ73RKFCmJRLJsT1dfRpEmZ5GZdmsp8DukaqrbefFuGDqNZvl - www.themirror.com/news/us-news/cia-uses-star-wars-website-1174874
- www.dailymail.co.uk/news/article-14752155/CIA-fake-websites-Star-Wars-communicate-spies.html Also announcing that:
- "mainstream" non-English:
- www.france24.com/fr/%C3%A9co-tech/20250528-star-wars-bourse-ou-football-les-etranges-sites-pour-les-informateurs-de-la-cia (French)
- francais.rt.com/international/121266-espionnage-cia-utilisait-sites-fans-star-wars-pour-communiquer-secretement-avec-ses-agents-etrangers RT in French, God
- www.derstandard.at/consent/tcf/story/3000000271640/die-cia-hat-heimlich-eine-star-wars-fanseite-betrieben Der Standard (Austria)
- tw.news.yahoo.com/玩家可能都用過?原來「美國中情局」cia曾營運過遊戲媒體網站掩護行動-070742215.html (Yahoo Taiwan)
- www.abc.es/internacional/cia-empleo-sitios-web-inofensivos-paginas-star-20250528171402-nt.html (Spain)
- "non-mainstream":
- www.dexerto.com/entertainment/the-cia-secretly-used-a-star-wars-fan-site-to-talk-to-spies-report-3199318/ and x.com/Dexerto/status/1927000891963363406 large-ish publication
- www.thegamer.com/star-wars-fan-website-cia-usa-government-spies-controlled/
- www.techspot.com/news/108062-cia-used-star-wars-fan-site-secretly-communicate.html This was one of the biggest hits on Google Analytics actually.
- gigazine.net/news/20250527-starwars-fan-sites-made-by-cia/ Japanese
- Wired:
- www.pcgamer.com/gaming-industry/the-cia-operated-a-network-of-gaming-sites-and-even-a-star-wars-fanpage-that-were-part-of-one-of-its-worst-ever-intelligence-catastrophes/
- www.msn.com/en-us/news/technology/the-cia-secretly-ran-a-star-wars-fan-site-to-communicate-with-spies/ar-AA1FASFY
- www.gamespot.com/articles/the-cia-once-ran-a-star-wars-fan-site-as-part-of-a-global-intelligence-effort/1100-6532045/
- www.darkhorizons.com/how-u-s-spies-used-a-star-wars-fan-page/
- gigazine.net/news/20250527-starwars-fan-sites-made-by-cia/
- Reddit
- 2025-08-01 saw another mini-trend due to The CIA Built Hundreds of Covert Websitesby Alan Macleod: www.mintpressnews.com/cia-secret-network-885-fake-websites/290325/
This then spawned some sindicated posts:and forum threads:- www.sott.net/article/500997-The-CIA-built-hundreds-of-covert-websites-Heres-what-they-were-hiding
- scheerpost.com/2025/08/02/the-cia-built-hundreds-of-covert-websites-heres-what-they-were-hiding/
- 2025-08-02 alethonews.com/2025/08/02/the-cia-built-hundreds-of-covert-websites-heres-what-they-were-hiding/ (Greek)
- 2025-08-02 popularresistance.org/the-cia-built-hundreds-of-covert-websites/
- 2025-08-04 cz24.news/alan-macleod-cia-vytvorila-stovky-tajnych-webu-globalni-spionazni-terminaly-co-vlastne-skryvaly/ (Czech)
Notable reactions to the websites themselves:
- 2022-09-29 www.reddit.com/r/soccer/comments/xrgua4/the_cia_used_a_message_board_on_a_fake_soccer/ "The CIA used a message board on a fake soccer website called "Iraniangoals.com" to communicate with Iranian spies, dozens of whom were arrested after the website was discovered." by user Carlos-Dangerzone
CIA 2010 covert communication websites ipinf.ru Updated 2025-07-16
alljohnny.com had a hit: ipinf.ru/domains/alljohnny.com/, and so Ciro started looking around... and a good number of other things have hits.Not all of them, definitely less data than viewdns.info.
But they do reverse IP, and they show which nearby reverse IPs have hits on the same page, for free, which is great!
Shame their ordering is purely alphabetical, doesn't properly order the IPs so it is a bit of a pain, but we can handle it.
OMG, Russians!!!
CIA 2010 covert communication websites IP range search Updated 2025-07-16
One promising way to find more of those would be with IP searches, since it was stated in the Reuters article that the CIA made the terrible mistake of using several contiguous IP blocks for those website. What a phenomenal OPSEC failure!!!
The easiest way would be if Wayback Machine itself had an IP search function, but we couldn't find one: Search Wayback Machine by IP.
viewdns.info was the first easily accessible website that Ciro Santilli could find that contained such information.
Our current results indicate that the typical IP range is about 30 IPs wide.
E.g. searching: viewdns.info/iphistory and considering only hits from 2011 or earlier we obtain:
- capture-nature.com
- 65.61.127.163 - Greenacres - United States - TierPoint - 2013-10-19
- activegaminginfo.com
- 66.175.106.148 - United States - Verizon Business - 2012-03-03
- iraniangoals.com
- 68.178.232.100 - United States - GoDaddy.com - 2011-11-13
- 69.65.33.21 - Flushing - United States - GigeNET - 2011-09-08
- rastadirect.net
- 68.178.232.100 - United States - GoDaddy.com - 2011-05-02
- iraniangoalkicks.com
- 68.178.232.100 - United States - GoDaddy.com - 2011-04-04
- headlines2day.com
- 118.139.174.1 - Singapore - Web Hosting Service - 2013-06-30. Source: viewdns.info
- 184.168.221.91 2013-08-12T06:17:39. Source: 2013 DNS Census grep
- fightwithoutrules.com
- fitness-dawg.com
Neither of these seem to be in the same ranges, the only common nearby hit amongst these ranges is the exact
68.178.232.100, and doing reverse IP search at viewdns.info/reverseip/?host=68.178.232.100&t=1 states that it has 2.5 million hostnames associated to it, so it must be some kind of Shared web hosting service, see also: superuser.com/questions/577070/is-it-possible-for-many-domain-names-to-share-one-ip-address, which makes search hard.Ciro then tried some of the other IPs, and soon hit gold.
Initially, Ciro started by doing manual queries to viewdns.info/reversip until his IP was blocked. Then he created an account and used his 250 free queries with the following helper script: ../cia-2010-covert-communication-websites/viewdns-info.sh. The output of that script can be seen at: github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/viewdns-info.sh.
CIA 2010 covert communication websites "Mass Deface III" pastebin Updated 2025-07-16
pastebin.com/CTXnhjeS dated mega early on Sep 30th, 2012 by CYBERTAZIEX.
This source was found by Oleg Shakirov.
This pastebin contained a few new hits, in addition to some pre-existing ones. Most of the hits them seem to be linked to the IP 72.34.53.174, which presumably is a major part of the fingerprint found by CYBERTAZIEX, though unsurprisingly methodology is unclear. As documented, the domains appear to be linked to a "Condor hosting" provider, but it is hard to find any information about it online.
From the title, it would seem that someone hacked into Condor and defaced all of its sites, including unknowingly some CIA ones which is LOL.
Ciro Santilli checked every single non-subdomain domain in the list.
Other files under the same account: pastebin.com/u/cybertaziex did not seem of interest.
The author's real name appears to be Deni Suwandi: twitter.com/denz_999 from Indonesia, but all accounts appear to be inactive, otherwise we'd ping him to ask for more info about the list.
www.zone-h.com lists some of the domains. They also seem to have intended to have snapshots of the defaces but we can't see them which is sad:
- www.zone-h.com/mirror/id/18994983 Inspecting the source we see an image zonehmirrors.org/defaced/2013/01/14/vypconsulting.com//tmp/sejeal.jpg "Sejeal" "Memorial of Gaza Martyrs". Sejeal defacements are mentioned e.g. at:
- www.zone-h.com/mirror/id/18410811 inspecting source we find: zonehmirrors.org/defaced/2012/09/30/ambrisbooks.com/ which lists the team:
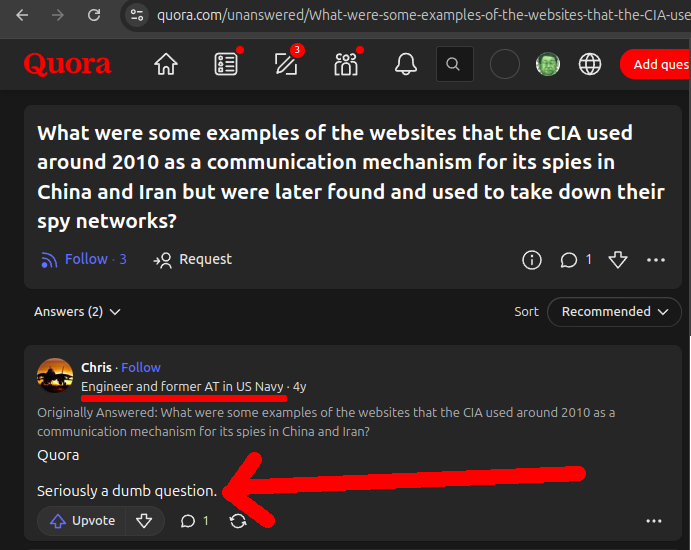
CIA 2010 covert communication websites Overview of Ciro Santilli's investigation Created 2025-05-07 Updated 2025-07-19
Ciro Santilli hard heard about the 2018 Yahoo article around 2020 while studying for his China campaign because the websites had been used to take down the Chinese CIA network in China. He even asked on Quora about it, but there were no publicly known domains at the time to serve as a starting point. Chris, Electrical Engineer and former Avionics Tech in the US Navy, even replied suggesting that obviously the CIA is so competent that it would never ever have its sites leaked like that:
Seriously a dumb question.
{kind=link}
In 2023, one year after the Reuters article had been published, Ciro Santilli was killing some time on YouTube when he saw a curious video: Video 1. "Compromised Comms by Darknet Diaries (2023)". As soon as he understood what it was about and that it was likely related to the previously undisclosed websites that he was interested in, he went on to read the Reuters article that the podcast pointed him to.
Being a half-arsed web developer himself, Ciro knows that the attack surface of a website is about the size of Texas, and the potential for fingerprinting is off the charts with so many bits and pieces sticking out. And given that there were at least 885 of them, surely we should be able to find a few more than nine, right?
In particular, it is fun how these websites provide to anyone "live" examples of the USA spying on its own allies in the form of Wayback Machine archives.
Given all of this, Ciro knew he had to try and find some of the domains himself using the newly available information! It was an irresistible real-life capture the flag.
Chris, get fucked.
It was the YouTube suggestion for this video that made Ciro Santilli aware of the Reuters article almost one year after its publication, which kickstarted his research on the topic.
Full podcast transcript: darknetdiaries.com/transcript/75/
Ciro Santilli pinged the Podcast's host Jack Rhysider on Twitter and he ACK'ed which is cool, though he was skeptical about the strength of the fingerprints found, and didn't reply when clarification was offered. Perhaps the material is just not impactful enough for him to produce any new content based on it. Or also perhaps it comes too close to sources and methods for his own good as a presumably American citizen.
The first step was to try and obtain the domain names of all nine websites that Reuters had highlighted as they had only given two domains explicitly.
Thankfully however, either by carelessness or intentionally, this was easy to do by inspecting the address of the screenshots provided. For example, one of the URLs was:which corresponds to
https://www.reuters.com/investigates/special-report/assets/usa-spies-iran/screencap-activegaminginfo.com.jpg?v=192516290922activegaminginfo.com.Once we had this, we were then able to inspect the websites on the Wayback Machine to better understand possible fingerprints such as their communication mechanism.
The next step was to use our knowledge of the sequential IP flaw to look for more neighbor websites to the nine we knew of.
This was not so easy to do because the websites are down and so it requires historical data. But for our luck we found viewdns.info which allowed for 200 free historical queries (and they seem to have since removed this hard limit and moved to only throttling), leading to the discovery or some or our own new domains!
This gave us a larger website sample size in the order of the tens, which allowed us to better grasp more of the possible different styles of website and have a much better idea of what a good fingerprint would look like.
viewdns.info
. Source. activegameinfo.com domain to IPviewdns.info
. Source. aroundthemiddleeast.com IP to domainThe next major and difficult step would be to find new IP ranges.
This was and still is a hacky heuristic process for us, but we've had the most success with the following methods:
- step 1) get huge lists of historic domain names. The two most valuable sources so far have been:
- step 2) filter the domain lists down somehow to a more manageable number of domains. The most successful heuristics have been:
- for 2013 DNS Census which has IPs, check that they are the only domain in a given IP, which was the case for the majority of CIA websites, but was already not so common for legitimate websites
- they have the word
newson the domain name, given that so many of the websites were fake news aggregators
- step 3) search on Wayback machine if any of those filtered domains contain URL's that could be those of a communication mechanism. In particular, we've used a small army of Tor bots to overcome the Wayback Machine's IP throttling and greatly increase our checking capacity
amazon.com,2012-02-01T21:33:36,72.21.194.1
amazon.com,2012-02-01T21:33:36,72.21.211.176
amazon.com,2013-10-02T19:03:39,72.21.194.212
amazon.com,2013-10-02T19:03:39,72.21.215.232
amazon.com.au,2012-02-10T08:03:38,207.171.166.22
amazon.com.au,2012-02-10T08:03:38,72.21.206.80
google.com,2012-01-28T05:33:40,74.125.159.103
google.com,2012-01-28T05:33:40,74.125.159.104
google.com,2013-10-02T19:02:35,74.125.239.41
google.com,2013-10-02T19:02:35,74.125.239.46
The four communication mechanisms used by the CIA websites
. Java Applets, Adobe Flash, JavaScript and HTTPS
Expired domain names by day 2011
. Source. The scraping of expired domain trackers to Github was one of the positive outcomes of this project.Finally, at the very end of our pipeline, we were left with a a few hundred domains, and we just manually inspected them one by one as far as patience would allow it to confirm or discard them.

You can never have enough Wayback Machine tabs open
. This is how the end of the fingerprint pipeline looks like: as many tabs as you have the patience to go through one by one!