In which roads is it OK to ride your bike based on car speed limits by  Ciro Santilli 40 Updated 2025-07-16
Ciro Santilli 40 Updated 2025-07-16
Ciro Santilli 40 Updated 2025-07-16Maybe Ciro Santilli should do something useful and remarkable so that someone might actually want to read his biography in the first place. But hey, procrastination.
Ciro Santilli was born in Brazil in the small/medium city of Rio Claro, São Paulo (~200k people in 2020) in the State of São Paulo in 1989 AD.
The family then moved to Jundiaí in 1995, and then finally to Santos, São Paulo, Brazil in 1997.
At the age of 10, Ciro Santilli spent 10 months in Coventry, United Kingdom, where he greatly improved his English.
After Coventry, Ciro's family went back to Santos, São Paulo, Brazil, which made a deep impression on Ciro, until he Ciro Santilli's undergrad studies at the University of São Paulo in 2007.
In 2010, as mentioned at Section "Ciro Santilli's formal education", Ciro as admitted in a double degree program at the École Polytechnique, France, where he stayed until 2013. Going to France was a mind blowing, life changing event.
Ciro's parents put him to play the piano. This is partly influenced by Ciro's paternal grandfather, an energetic Italian descendant who liked music

The teachers were nice old ladies who followed a very traditional and methodic approach which was just like regular school, instead of doing what actually needed to be done: inspire kids into becoming creative musical geniuses that can compose their own stuff.
The electric guitar environment was much less formalized in general, and he took courses with an awesome teacher (archive), who actually tried to inspire his students to create their own music and improvisation.
In his early teens, Ciro listened to the usual canned music his friends listened to: music teenager Ciro Santilli liked to listen to, until he started to stumble upon jazz.
Ciro remembers clearly rainy weekend days where he would go to a run down second hand shop near his home in someone's garage (Sebo do Alfaiate, R. Frei Francisco de Sampaio, 183 - Embaré, Santos - SP, 11040-220, Brazil :-)), and buy amazing second hand Jazz CDs. It was just a matter of time until he would start scouring the web for "the best jazz albums of all time" and start listening to all of them, see e.g. the best modern instrumental Western music. digitaldreamdoor.com/index.html was a good resource from those times!
Ciro ultimately decided his bad memory and overwhelming passion for the natural sciences would better suit a scientific carrier.
He also learnt that the computer is also an extremely satisfying artistic instrument.
Also, with a computer, boring dexterity limitations are no more: you can just record perfect played segments or program things note by note to achieve whatever music or action you want!
Although Ciro quit playing musical instruments, his passion for the music has remained, and who knows how it has influenced his life.
Equation 1.
Lorentz force
. A little suspicious that it bears the name of Lorentz, who is famous for special relativity, isn't it? See: Maxwell's equations require special relativity.
Found through Google with no direct relation known to Ciro Santilli:
- en.wikipedia.org/wiki/Santilli: Wikipedia page of the glorious family, Santillis with their own Wikipedia page:
- Ruggero Santilli: "fringe science guy", by far dominates Google as of 2019. Created the respectable R.M. Santilli Foundation
- Ray Santilli made a fake 1995 alien autopsy movie, YouTube sample: www.youtube.com/watch?v=sVcaT2QnoDs
- Ivana Santilli: Canadian singer, pop-electric-chill: www.youtube.com/watch?v=hQRuVN0H8dM
- accounts on important websites
- github.com/santilli anonymous GitHub as of 2019
- santilli.com/ for rent by realnames.com/ (wiki page) as of 2019
- Also Brazilian and tech related like Ciro Santilli.
- www.youtube.com/user/TheOverthrowShow thepetesantillishow.com/ Pete Santilli, American Conservative news commentator show, makes Ciro cringe of boredom. At least he has a passion.
Possibly related variants:
- Santillo:
- Will Santillo who makes somewhat artistic porn photos. His website with several free demos: santillophotography.com/
- www.linkedin.com/in/ciro-santillo-2025a6ba/ a "Ciro Santillo", github.com/Ciruxx, also a programmer
- Santilly, a town in Saône-et-Loire department, France
- santilly.com/ redirects to www.pompes-funebres-santilly.com/fr/, a French funerary service

The website system that runs OurBigBook.com. For further information see:Relies on the OurBigBook Library to compile OurBigBook Markup.
- OurBigBook.com: rationale
- cirosantilli.com/ourbigbook/ourbigbook-web: project documentation
Basically everything that applies to the blogs section also applies here, but university lecture notes are so important to us that they deserve a bit more talk.
It is arguable that this is currently the best way to learn any university subject, and that it can already be used to learn any subject.
We basically just want to make the process more efficient and enjoyable, by making it easier:
One major problem with lecture notes is that, as the name suggests, they are merely a complement to the lecture, and don't contain enough detail for you to really learn solely from them without watching the lecture.
The only texts that generally teach in enough depth are actual books, which are almost always commercial.
So in a sense, this project can be seen as a path to upgrade free lecture notes into full blown free books, from which you can learn from scratch without any external material.
And a major way in which we believe this can be done is through the reuse of sections of lecture notes by from other universities, which greatly reduces the useless effort of writing things from scratch.
The intended mental picture is clear: the topics feature docs.ourbigbook.com/#ourbigbook-web-topics will is intended to act as the missing horizontal topic integration across lecture notes of specific universities, e.g:
MIT calculus course UCLA calculus course
* Calculus <---> * Calculus
* Limit <---> * Limit
* Limit of a function
* Limit of a series <---> * Limit of a series
* Derivative <---> * Derivative
* L'Hôpital's rule
* Integral <---> * Integral
Example topics page of OurBigBook.com
. One important advantage of lecture notes is that since they are written by the teacher, they should match exactly what "students are supposed to learn to get good grades", which unfortunately is a major motivation for student's learning weather we want it or not.
One big open question for this project is to what extent notes written for lectures at one university will be relevant to the lectures at another university?
Is it possible to write notes in a way that they are naturally reusable?
It is our gut feeling that this is possible. But it almost certainly requires an small intentional effort on the part of authors.
The question then becomes whether the "become famous by getting your content viewed in other universities" factor is strong enough to attract users.
And we believe that it might, it just might be.
- HyperCard: we are kind of a "multiuser" version of HyperCard, trying to tie up cards made by different users. It is worth noting that HyperCard was one of the inspirations for WikiWikiWeb, which then inspired Wikipedia
- Semantic Web
- NLab
- physicstravelguide.com/ Nice manifesto: physicstravelguide.com/about by Jakob Schwichtenberg.
- OpenStax
- www.ft.com/content/5515ec3e-0040-4d90-85a9-df19d6e3ebd2 (archive) Twilio’s Jeff Lawson: an evangelist for software developersYou can never be first. But you can have the correct business model. That company's website must have gone into IP Purgatory, and could never be released as an open source website.As a student at the University of Michigan, he started a company that made lecture notes available free online, drawing a large audience of Midwestern college students and, soon enough, advertisers. At the height of the dotcom bubble, he dropped out of college, raised $10m from the venture firm Venrock and moved the company to Silicon Valley.His start-up drew interest from an acquirer that was planning to go public early in 2000. They closed the acquisition but missed their IPO window as the market plunged, and by August the company had filed for bankruptcy. Stock that Lawson and investors in his start-up received from the sale became worthless.He might actually be interested in donating to OurBigBook.com if it move forward now that he's a billionaire.
- Knol: basically the exact same thing by Google but 14 years earlier and declared a failure. Quite ominous:
- leanpub: similar goals, markdown-based, but the usual "you own your book copyright and you are trying to sell your book" approach
- nature Scitable
OK, just going random now:
The geometry of divisors is a topic in algebraic geometry that deals with the study of divisors on algebraic varieties, particularly within the context of the theory of algebraic surfaces and higher-dimensional varieties. A divisor on an algebraic variety is an algebraic concept that intuitively represents "subvarieties" or "subsets", often associated with codimension 1 subvarieties, such as curves on surfaces or hypersurfaces in higher dimensions.
This mini-project walks the category hierarchy Wikipedia dumps and dumps them in various simple formats, HTML being the most interesting!
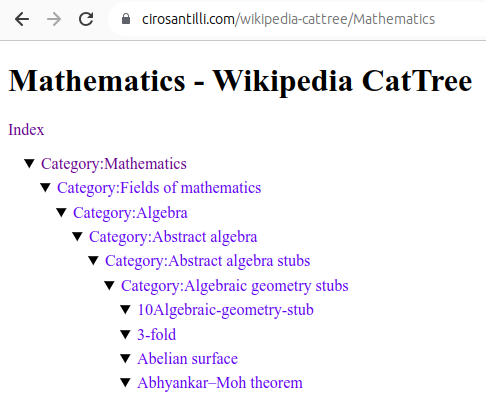
Mathematics dump of Wikipedia CatTree
. Source. Some of the contributions are subjectively self evaluated based on:
Ciro Santilli's open source contributions Bug reports and feature requests by Ciro Santilli 40 Updated 2025-07-16
Ciro Santilli 40 Updated 2025-07-16This shall not list bugs solved by my accepted pull requests.

Alain Aspect in 2016
. Source. Alain Aspect in Quantum entanglement Documentary (1985)
Source. The moustache and broken English were already his trademarks back then!!! Also cool to get a glimpse of his lab, and good schematics of the experiment. TODO exact lab location? Documentary says in Paris, but where? Pinned article: Introduction to the OurBigBook Project
Welcome to the OurBigBook Project! Our goal is to create the perfect publishing platform for STEM subjects, and get university-level students to write the best free STEM tutorials ever.
Everyone is welcome to create an account and play with the site: ourbigbook.com/go/register. We belive that students themselves can write amazing tutorials, but teachers are welcome too. You can write about anything you want, it doesn't have to be STEM or even educational. Silly test content is very welcome and you won't be penalized in any way. Just keep it legal!
Intro to OurBigBook
. Source. We have two killer features:
- topics: topics group articles by different users with the same title, e.g. here is the topic for the "Fundamental Theorem of Calculus" ourbigbook.com/go/topic/fundamental-theorem-of-calculusArticles of different users are sorted by upvote within each article page. This feature is a bit like:
- a Wikipedia where each user can have their own version of each article
- a Q&A website like Stack Overflow, where multiple people can give their views on a given topic, and the best ones are sorted by upvote. Except you don't need to wait for someone to ask first, and any topic goes, no matter how narrow or broad
This feature makes it possible for readers to find better explanations of any topic created by other writers. And it allows writers to create an explanation in a place that readers might actually find it.
Figure 1. Screenshot of the "Derivative" topic page. View it live at: ourbigbook.com/go/topic/derivativeVideo 2. OurBigBook Web topics demo. Source. - local editing: you can store all your personal knowledge base content locally in a plaintext markup format that can be edited locally and published either:This way you can be sure that even if OurBigBook.com were to go down one day (which we have no plans to do as it is quite cheap to host!), your content will still be perfectly readable as a static site.
- to OurBigBook.com to get awesome multi-user features like topics and likes
- as HTML files to a static website, which you can host yourself for free on many external providers like GitHub Pages, and remain in full control

Figure 3. Visual Studio Code extension installation.
Figure 4. Visual Studio Code extension tree navigation.
Figure 5. Web editor. You can also edit articles on the Web editor without installing anything locally.Video 3. Edit locally and publish demo. Source. This shows editing OurBigBook Markup and publishing it using the Visual Studio Code extension.Video 4. OurBigBook Visual Studio Code extension editing and navigation demo. Source. 
- Infinitely deep tables of contents:


{kind=link}
All our software is open source and hosted at: github.com/ourbigbook/ourbigbook
Further documentation can be found at: docs.ourbigbook.com
Feel free to reach our to us for any help or suggestions: docs.ourbigbook.com/#contact