Sometimes Ciro Santilli regrets not having done a PhD. But this section makes him feel better about himself. To be fair, part of the merit is on him, part of the reason he didn't move on was the strong odour of bullshit oozing down to Masters level. A good PhH might have opened interesting job opportunities however, given that you don't really learn anything useful before that point in your education.
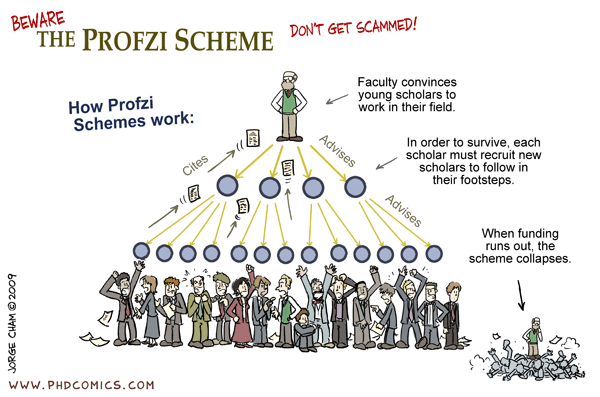
Profzi scheme by PhD Comics
. A Ponzi scheme that trains people in new skills is not necessarily a terrible thing. It is a somewhat more useful version than standard exam based education.
Perhaps the problem is "forcing" 35 year olds to go down that path when they might also want to have boring stuff like families and security.
If people could get to the PhD level much, much sooner, it wouldn't be as obscene: Section "Students must be allowed to progress as fast as they want".
2023: You can't apparently fire someone in academia!
One of the world’s most cited scientists, Rafael Luque, suspended without pay for 13 years
Rafael Luque, has been suspended without pay for the next 13 years
One is reminded of Nick Leeson.
One things must be said: the root cause of all of this is the replication crisis.
This is why he managed to go on for so long.
- Autonomous agents research group of the University of Edinburgh
- QMUL research group
- Research group of the Department of Engineering science of the University of Oxford
- Research group of the Department of physics of the University of Oxford
- Stanford University research group
- University of Bristol research group
- experimentalhistory.substack.com/p/the-rise-and-fall-of-peer-review The rise and fall of peer review by Adam Mastroianni (2022)
One of the most beautiful things is how they paywall even public domain works. E.g. here: www.nature.com/articles/119558a0 was published in 1927, and is therefore in the public domain as of 2023. But it is of course just paywalled as usual throughout 2023. There is zero incentive for them to open anything up.
This metric is so dumb! It only helps maintain existing closed journals closed! Why not just do a PageRank on the articles themselve instead? Like the h-index does for authors? That would make so much more sense!
Publications by the Prussian Academy of Sciences.
Links to their publications: de.wikisource.org/wiki/Sitzungsberichte_der_K%C3%B6niglich_Preu%C3%9Fischen_Akademie_der_Wissenschaften_zu_Berlin
Notable papers:
This was the God OG physics journal of the early 20th century, before the Nazis fucked German science back to the Middle Ages!
Notable papers:
Notable papers:
By "Academic paper database" we mean a database that collects paper metadata such as authors and citations, but not necessarily the full article content.
Academia is so broken that there isn't even one be-all and end-all database of:It's closed access academic journals are evil to the extreme.
By "open" we also mean that you can download their database locally and that it has an open license, not just free access.
TODO evaluate:
- www.crossref.org/. No papers by author attempt unless they have ORCID: community.crossref.org/t/get-all-works-of-a-particular-author-without-orcid/3751 so what's the point of this project? www.crossref.org/services/funder-registry/ this Funder registry thing sounds cool though.
Full database download is described at: pubmed.ncbi.nlm.nih.gov/download/
The only problem with it is scope, being life sciences-only.
E.g. list of papers by Isidor Isaac Rabi which includes A New Method of Measuring Nuclear Magnetic Moment.
neurotree.org/neurotree/faq.php explains that you have to contact an admin to download the database, kind of sad:
That page also explains how they disambiguate authors with the same name:
How do you identify researchers' publications?Publications data are drawn from two databases: Medline and Scopus. Because of the large number of researchers with the same name, a disambiguation algorithm is required to accurately link researchers to papers they have authored. We match authors to papers using a two-step process. First, we identify candidate publications based on a simple string match between researcher name and the author list. Second, we look for overlap between co-authors and other individuals in the researcher's mentor network (trainees, mentors, collaborators, etc), and label publications with overlap as high-probability matches. Thus a complete family tree is likely to produce more accurate publication matches.
These are free to query, but you can't download their database. For those that allow database download see: Open academic paper database.
Does this contain any structured data? E.g. can you list all papers by a given author besides just searching and hoping there are no homonyms?
You are nothing but useless leeches in the Internet age.
You must go bankrupt all of you, ASAP.
Researchers and reviewers all work for peanuts, while academic publishers get money for doing the work that an algorithm could do. OurBigBook.com.
When Ciro learned URLs such as www.nature.com/articles/181662a0 log you in automatically by IP, his mind blew! The level of institutionalization of this theft is off the charts! The institutionalization of theft is also clear from article prices, e.g. 32 dollars for a 5 page article.
Long live the Guerilla Open Access Manifesto by Aaron Swartz (2008).
Key physics papers from the 50's are still copyright encumbered as of 2020, see e.g. Lamb-Retherford experiment. Authors and reviewers got nothing for it. Something is wrong.
Infinite list of other people:
- blog.machinezoo.com/public-domain-theft by Robert Važan:
Scientific journals are perhaps one of the most damaging IP rackets. Scientists are funded by governments to do research and publish papers. Reviews of these papers are done by other publicly funded scientists. Even paper selection and formatting for publication is done by scientists. So what do journals actually do? Nearly nothing.
Academic Publishing by Dr. Glaucomflecken (2022)
Source. Part of the motivation letter required by some American universities explaining how amazing of a teacher you are, e.g.: wstein.org/job/Teaching/index.html
Short for Doctor of Philosophy, it's how some weird places like the University of Oxford say PhD. In Oxford they also analogously say MPHil.
Notably in STEM, not so interested in literature of course:
Here's a SPARQL sketch for Wikidata that can be run at query.wikidata.org/. It gathers all the relevant data, but TODO we don't know how to do the proper query yet:
# List of living Nobel Laureates sorted by date of birth
SELECT DISTINCT ?recipient ?recipientLabel $birthDate ?awardLabel ?nobelDate ?educatedAtLabel ?academicDegree ?academicDegreeLabel ?doctorateDate
WHERE {
?recipient wdt:P31 wd:Q5 ; # recepient is human (Peace prize can go to organizations)
wdt:P569 ?birthDate ;
p:P166 ?awardStat . # recepient was awarded something
?awardStat ps:P166 ?award .
?award wdt:P279* wd:Q7191 . # received any subclass of nobel prize (physics, chemistry, etc.)
?awardStat pq:P585 ?nobelDate .
?recipient p:P69 ?recipientEducatedAt .
?recipientEducatedAt ps:P69 ?educatedAt .
?recipientEducatedAt pq:P512 ?academicDegree .
?academicDegree wdt:P279* wd:Q849697 .
OPTIONAL{ ?recipientEducatedAt pq:P582 ?doctorateDate . }
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" . }
}
ORDER BY ASC(?birthDate) ASC(?nobelDate) ASC(?awardLabel) Articles by others on the same topic
There are currently no matching articles.