Previously, updates were being done with more focus to sponsors in the format of the child sections to this section. That format is now retired in favor of the more direct Section "Updates" format.
OurBigBook Web error reporting starting to look amazing.
Source. I can't help to feel how the speed of developments reflects my relative mastery of the stack, I'm very happy about how it went.
This is a major feature: we have now started to inject the following buttons next to every single pre-rendered header:
This crucial feature makes it clear to every new user that every single header has its own separate metadata, which is a crucial idea of the website.
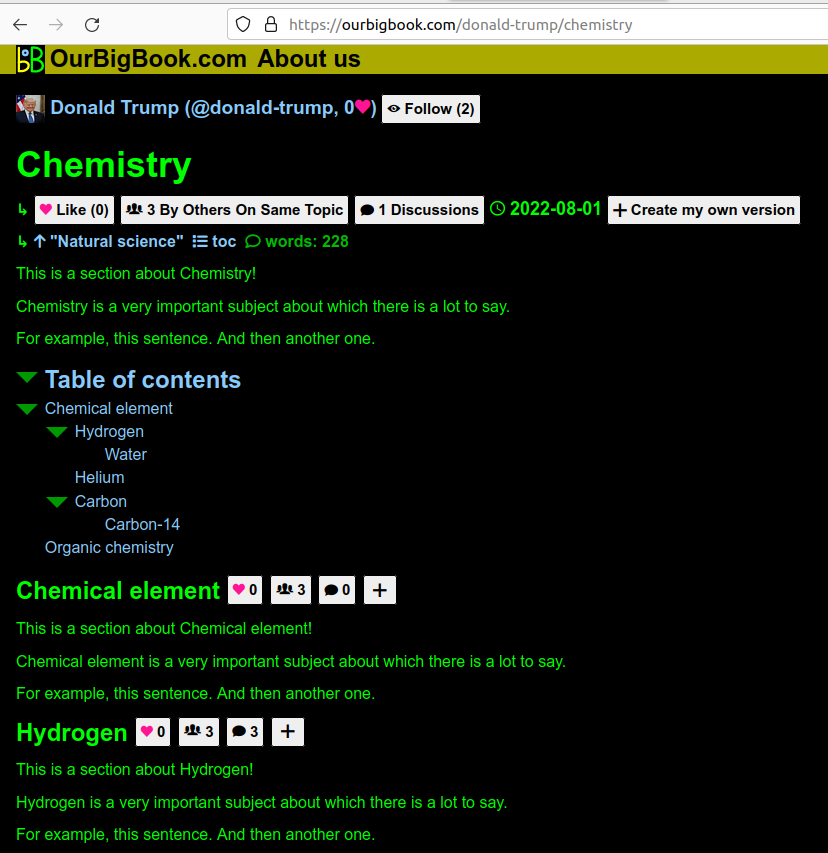
Screenshot showing metadata next to each header
. The page is: ourbigbook.com/donald-trump/chemistry. Note how even the subheaders "Chemical element" and "Hydrogen" show the metadata.The new default homepage for a logged out user how shows a list of the topics with the most articles.
This is a reasonable choice for default homepage, and it immediately exposes users to this central feature of the website: the topic system.
Doing this required in particular calculating the best title for a topic, since it is possible to have different titles with the same ID, the most common way being with capitalization changes, e.g.:would both have topic ID
JavaScript
Javascriptjavascript.The algorithm chosen is to pick the top 10 most upvoted topics, and select the most common title from amongst them. This should make topic title vandalism quite hard. This was made in a single SQL query, and became the most complext SQL query Ciro Santilli has ever written so far: twitter.com/cirosantilli2/status/1549721815832043522
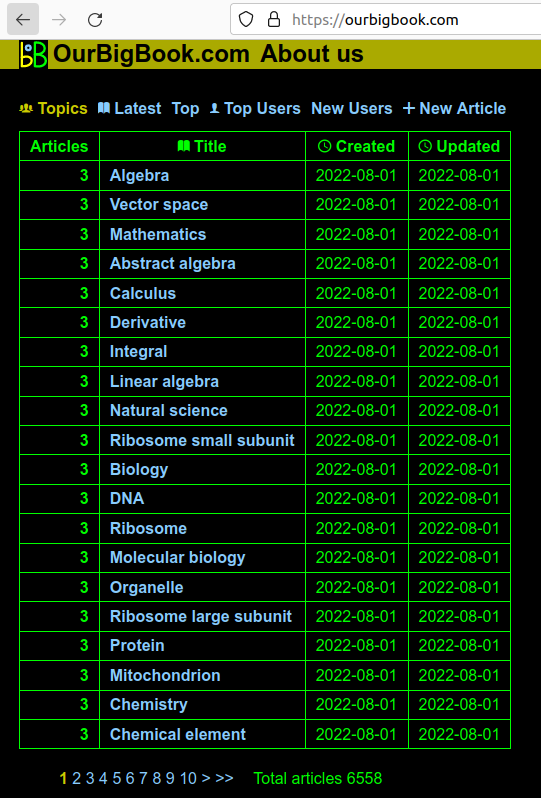
Screenshot showing the list of topics
. The page is: ourbigbook.com for the logged out user, ourbigbook.com/go/topics for the logged in user.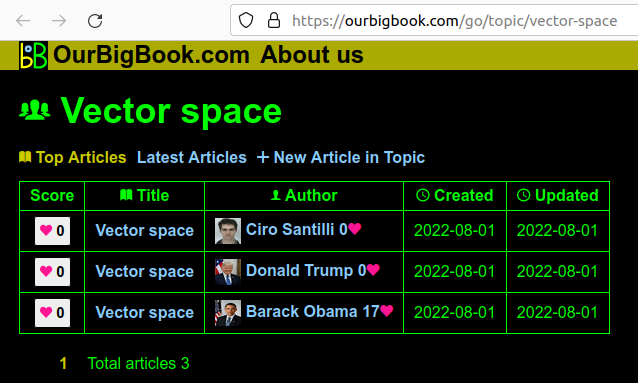
Screenshot showing a topic page
. The page is: ourbigbook.com/go/topic/vector-space. Before this sprint, we didn't have the "Vector Space" at the top, as it wasn't necessarily trivial to determine what the preferred title would be.Limited the number of articles, and the size of article bodies. This, together with the reCAPTCHA setup from Email verification and reCAPTCHA signup protection should prevent the most basic types of denial-of-service attacks by filling up our database.
The limits can be increased by admin users from the web UI, and will be done generously when it is evident that it is not a DoS attack. Admin users are also a recently added feature.
I guess ended up doing all the "how things should look like" features because they clarify what the website is supposed to do, and I already have my own content to bring it alive via
ourbigbook --web upload.But now I honestly feel that all the major elements of "how things should look like" have fallen into place.
I was really impressed by Trillium Notes. I should have checked it long ago. The UI is amazing, and being all Js-based, could potentially be reused for our purposes. The project itself is a single-person/full trust notetaking only for now however, so not a direct replacement to OurBigBook.
Added this basic but fundamental protection layer to the website.
The email setup will of course be reused when notifications are eventually implemented.
Adding reCAPTCHA immediately after email is a must otherwise an attacker could send infinitely many emails to random addresses, which would lead to the domain being marked as spam. I was pleasantly surprised about how easy the integration ended up being.
Every article now has a (very basic) GitHub-like issue tracker. Comments now go under issues, and issues go under articles. Issues themselves are very similar to articles, with a title and a body.
This was part of 1.0, but not the first priority, but I did it now anyways because I'm trying to do all the database changes ASAP as I'm not in the mood to write database migrations.
Here's an example:
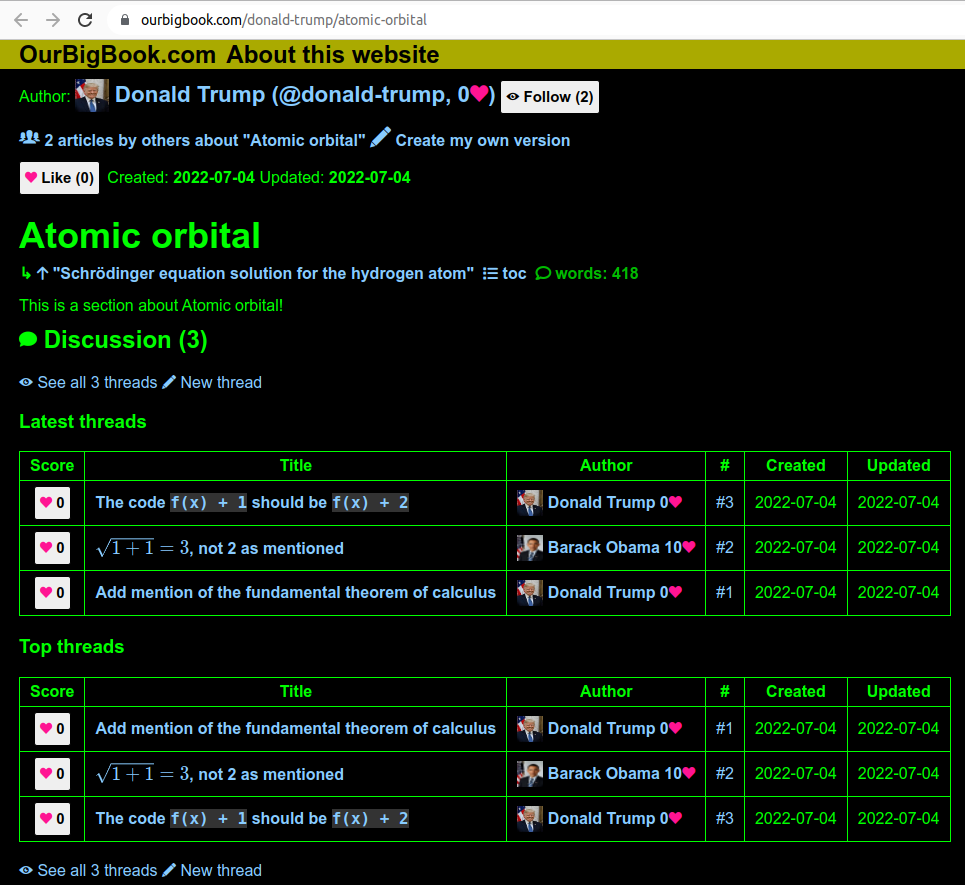
- ourbigbook.com/go/issue/2/donald-trump/atomic-orbital a specific issue about the article "Atomic Orbital" by Donald Trump. Note the comments possibly by other users at the bottom.
- ourbigbook.com/go/issues/1/donald-trump/atomic-orbital list of issues about the article "Atomic Orbital" by Donald Trump
You can now write:in lieu of the old:
<Blue cats> are nice.
= Blue cat
= Big blue cat
{parent=Blue cat}\x[blue-cat]{c}{p} are nice.
= Blue cat
= Big blue cat
{parent=blue-cat}Added
ourbigbook --format-source automatic code formatting. I implemented it for the following reasons:- I want to do certain automatic modifications to source code on web, e.g.:
- later on, much later, this will allow WYSIWYG export to plaintext
This also ended up having one unexpected benefit: whenever a new feature is added that deprecates an old feature, by converting the large corpus from github.com/cirosantilli/cirosantilli.github.io to the new feature I can test the new preferred feature very well.
For example, converting
\x[blue cat] en masse to the new insane syntax <blue cat> found several bugs with the new insane syntax.This seemed somewhat easy at first, so I started it as a way of procrastinating more urgent Web features (web scares me, you know), but it ended being insanely hard to implement, because there are many edge cases. Also, most bugs are not acceptable, as they would corrupt your precious source code and potentially output.
But well, it is done!
Improve article editing which is very buggy and inconvenient!
I'll also look into some more likely easy but very important topic improvements:
I was trying to learn about how some types of quantum computers work, when I came across this pearl:
en.wikipedia.org/wiki/Wolfgang_Paul#Scientific_results Wolfgang Paul, 1989 Nobel Prize in Physics winner, referred to Wolfgang Pauli, 1945 winner, as his "imaginary part".
I also did a bit of cycling tourism: bicycles.stackexchange.com/questions/3779/im-going-to-take-my-bike-with-me-on-a-plane-do-i-really-need-a-special-bike-tr/84238#84238
Managed to upload the content from the static website cirosantilli.com (OurBigBook Markup source at github.com/cirosantilli/cirosantilli.github.io) to ourbigbook.com/cirosantilli.
Although most of the key requirements were already in place since the last update, as usual doing things with the complex reference content stresses the system further and leads to the exposition of several new bugs.
The upload of OurBigBook Markup files to ourbigbook.com was done with the newly added OurBigBook CLI
ourbigbook --web option. Although fully exposed to end users, the setup is not super efficient: a trully decent implementation should only upload changed files, and would basically mean reimplementing/using Git, since version diffing is what Git shines at. But I've decided not to put much emphasis on CLI upload for now, since it is expected that initially the majority of users will use the Web UI only. The functionality was added primarily to upload the reference content.This is a major milestone, as the new content can start attracting new users, and makes the purpose of the website much clearer. Just having this more realistic content also immediately highlighted what the next development steps need to be.
Once v1.0 is reached, I will actually make all internal links of cirosantilli.com to point to ourbigbook.com/cirosantilli to try and drive some more traffic.
The new content blows up by far the limit of the free Heroku PostgreSQL database of 10k lines. This meant that I needed to upgrade the Heroku Postgres plugin from the free Hobby Dev to the 9 USD/month Hobby Basic: elements.heroku.com/addons/heroku-postgresql, so now hosting costs will increase from 7 USD/month for the dyno to 7 + 9 = 16 UDS/month. After this upgrade and uploading all of cirosantilli.com to ourbigbook.com, Heroku dashboard reads reads:so clearly if we are ever forced to upgrade plans again, it means that a bunch of people are using the website and that things are going very very well! Happy how this storage cost turned out so far.
One key limitation found was that Heroku RAM memory is quite limited at 512MB, and JavaScript is not exactly the most memory economical language out there. Started investigation at: github.com/ourbigbook/ourbigbook/issues/230 Initially working around that by simply splitting the largest files. We were just on the verge of what could be ran however luckily, so a few dozen splits was enough, it managed to handle 70 kB OurBigBook Markup inputs. So hopefully if we manage to optimize a bit more we will be able to set a maximum size of 100 kB and still have a good safety margin.
Made the website navbar and article lists more mobile friendly. Main motivation: improvised demos to people I meet IRL!
I've started rewatching The Water Margin, it is just so good. I'm taking some reasonable notes this time however, because due to Ciro Santilli's bad old event memory I'll forget the details again otherwise.
That type of rebellion symbology could also be useful against the Chinese government. It is interesting that Mao Zedong loved the novel.
Water Margin tribute to Chinese dissidents
. Source. This was the major final step of fully integrating the OurBigBook CLI into the dynamic website (besides fixing some nasty bugs that escaped passed by me from the previous newsletter).
The implementation was done by "simply" reusing scopes, e.g.:
cirosantilli's article about mathematics has scope cirosantilli and full ID cirosantilli/mathematics.The problem is that a bunch of subdirectory scope operations were broken locally as well, as it simply wasn't a major use case. But now they became a major use case for , so I fixed them.

Before
. 
After
. Added font awesome icons. github.com/ourbigbook/ourbigbook/issues/151
Didn't manage to subset, but so be it for now: stackoverflow.com/questions/62395038/how-can-i-export-only-one-character-from-ttf-woff-file-to-avoid-load-unnecessa/71197892#71197892
This means while developing a website locally with the OurBigBook CLI, if you have a bunch of files with an error in one of them, your first run will run slowly until the error:but further runs will blast through the files that worked, skipping all files that have sucessfully converted:so you can fix file by file and move on quickly.
extract_ids README.ciro
extract_ids README.ciro finished in 73.82836899906397 ms
extract_ids art.ciro
extract_ids art.ciro finished in 671.1738419979811 ms
extract_ids ciro-santilli.ciro
extract_ids ciro-santilli.ciro finished in 1009.6256089992821 ms
extract_ids science.ciro
error: science.ciro:13686:1: named argument "parent" given multiple times
extract_ids science.ciro finished in 1649.6193730011582 msextract_ids README.ciro
extract_ids README.ciro skipped by timestamp
extract_ids art.ciro
extract_ids art.ciro skipped by timestamp
extract_ids ciro-santilli.ciro
extract_ids ciro-santilli.ciro skipped by timestamp
extract_ids science.ciroMore details at: cirosantilli.com/ourbigbook#no-render-timestamp
This was not fully trivial to implement because we had to rework how duplicate IDs are checked. Previously, we just nuked the DB every time on a directory conversion, and then repopulated everything. If a duplicated showed up on a file, it was a duplicate.
But now that we are not necessarily extracing IDs from every file, we can't just nuke the database anymore, otherwise we'd lose the information. Therefore, what we have to do is to convert every file, and only at the end check the duplicates.
Managed to do that with a single query as documented at: stackoverflow.com/questions/71235548/how-to-find-all-rows-that-have-certain-columns-duplicated-in-sequelize/71235550#71235550
The name cirodown should not appear anywhere now, except with very few exceptions, e.g.:
- github.com/cirosantilli/cirodown to github.com/ourbigbook/ourbigbook
- file extension from
.ciroto.bigb - the Node.js NPM package was renamed from
cirodowntoourbibook. - all in-code instances
I have also squatted
OurBigBook on all major social media handles for near future usage, e.g.: twitter.com/ourbigbook and so on.I was going to do this sooner or later, it was inevitable, but the timing was partly triggered due to noticing that English speakers (and likely many other nationalities) are not able to easily read/hear/pronounce "Ciro".
After breaking production and sweating for a bit hotfixing (not that anyone uses the website yet), I decided to be smart and created a staging server: ourbigbook-staging.herokuapp.com. Now I can blow that server up as I wish without afecting users. Documented at: cirosantilli.com/ourbigbook/staging-deployment
After something broke on the website due to SQLite vs PostgreSQL inconsistencies and took me a day to figure it out, I finally decided to update the test system so that
OURBIGBOOK_POSTGRES=true npm test will run the tests on PostgreSQL.Originally, these were being run only on SQLite, which is the major use case for OurBigBook CLI, which came before the website.
One of the key advances of the previous update was to show include headers on the table of contents.
This was to allow splitting source files freely.
While that goal was in principle achieved in that commit, when I went ahead to split the huge index of cirosantilli.com into multiple files, I notice several bugs that took a week to fix.
After all of these were solved, I finally managed to split the README at: github.com/cirosantilli/cirosantilli.github.io/commit/84c8a6e7fdbe252041accfb7a06d9b7462287131 and keep the previous desired output. You can now see that the README contains just:
\Include[ciro-santilli]
\Include[science]
\Include[mathematics]
\Include[technology]
\Include[art]This split led to a small positive modification of the output as follows. Previously, a section such as "Quantum Electrodynamics" would have been present in the monolithic README.ciro as:If you visited cirosantilli.com/quantum-electrodynamics, you would see see a link to the "nosplit" version, which would link you back to cirosantilli.com#quantum-electrodynamics, but that is not great, since this is was a humongous page with all of the README.ciro, and took long to display.
= Quantum electrodynamicsAfter the split,
= Quantum electrodynamics is present under science.ciro, and the nosplit version is the more manageable cirosantilli.com/science#quantum-electrodynamics.The key changes that were missing for that to happen were:
Issue report at: github.com/ourbigbook/ourbigbook/issues/198 Suppose you had:
programming-language.ciro
= Programming language
\Image[https://raw.githubusercontent.com/cirosantilli/media/master/python-logo.jpg]
{title=The \x[python-programming-language] logo}
== Python
{c}
{disambiguate=programming-language}= Logos I like
\x[image-the-python-logo]Now, when rendering
\x[image-the-python-logo], we would need to fetch two IDs:image-the-python-logofor theTheandlogopartpython-programming-languageitself, to know that\x[python-programming-language]should render asPython
But after group all SQL queries together was done, there was no way to know that rendering
image-the-python-logo would imply also fetching python-programming-language.This was solved by adding a new database entry type,
REFS_TABLE_X_TITLE_TITLE to the existing References table, which tracks dependencies between IDs.After this was setup, we can now know that
image-the-python-logo depends on image-the-python-logo, and then fetch both of them together in a single JOIN.- upload all of cirosantilli.com to ourbigbook.com. I will do this by implementing an import from filesystem functionality based on the OurBigBook CLI. This will also require implementing slit headeres on the server to work well, I'll need to create one
Articlefor every header on render. - get
\xand\Includeworking on the live web preview editor. This will require creating a new simple API, currently the editor jus shows broken references, but final render works because it goes through the database backend - implement email verification signup. Finally! Maybe add some notifications too, e.g. on new comments or likes.
Some smart people just brought up to my attention that OurBigBook.com is a bit like: roamresearch.com/ and other graph knowledges. I feel ashemed for not having seen this software and its alternatives before. I was so focused on the "book aspect" of it that I didn't search much in there. I couldn't find an immediate project killer superset from the options in that area, but maybe one exists. We'll see.
The China front was of course the Russia front this time: stackoverflow.com/users/895245 (web.archive.org/web/20220322230513/https://stackoverflow.com/users/895245/ciro-santilli-Путлер-Капут-六四事)
I read Human Compatible by Stuart J. Russell (2019). Some AI safety people were actually giving out free copies after a talk, can you believe it! Good book.
I had meant to make an update earlier, but I wanted to try and add some more "visible end-user changes" to OurBigBook.com.
Just noticed BTW that signup on the website is broken. Facepalm. Not that it matters much since it is not very useful in the current state, but still. Going to fix that soon. EDIT: nevermind, it wasn't broken, I just had JavaScript disabled on that website with an extension to test if pages are visible without JavaScript, and yes, they are perfectly visible, you can't tell the difference! But you can't login without JavaScript either!
I still haven't the user visible ones I wanted, but I've hit major milestones, and it feels like time for an update.
I have now finished all the OurBigBook CLI features that I wanted for 1.0, all of which will be automatically reused in ourbigbook.com.
The two big things since last email were the following:
A secondary but also important advance was: further improvements to the website's base technology.
I knew I was going to do them for several months now, and I knew they were going to hurt, and they did, but I did them.
These change caused two big bugs that I will solve next, one them infinite recursion in the database recursive query, but they shouldn't be too hard.
And do 5 big queries instead of hundreds of smaller ones.
For example, a README.ciro document that references another document saying:needs to fetch "speed-of-light" from the ID database (previously populated e.g. by preparsing light.ciro:to decide that it should display as "Speed of light" (the title rather than the ID).
The \x[speed-of-light] is fast.= Light
== Speed of lightPreviously, I was doing a separate fetch for each
\x[] as they were needed, leading to hundreds of them at different times.Now I refactored things so that I do very few database queries, but large ones that fetch everything during parsing. And then at render time they are all ready in cache.
This will be fundamental for the live preview on the browser, where the roundtrip to server would make it impossible
E.g.:
README.cironot-readme.cirothe table of contents for
= My website
== h2
\Include[not-readme]= Not readme
== Not readme h2index.html also contains the headers for not-readme.ciro producing:This feature means that you can split large input files if rendering starts to slow you down, and things will still render exactly the same, with the larger table of contents.
This will be especially important for the website because initially I want users to be able to edit one header at a time, and join all headers with
\Include. But I still want the ToC to show those children.This was a bit hard because it required doing RECURSIVE SQL queries, something I hadn't done before: stackoverflow.com/questions/192220/what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree/192462#192462 + of course the usual refactor a bunch of stuff and fix tests until you go mad.
github.com/cirosantilli/node-express-sequelize-nextjs-realworld-example-app contains the same baseline tech as OurBigBook, and I have been use to quickly test/benchmark new concepts for the website base.
I'm almost proud about that project, as a reasonable template for a Next.js project. It is not perfect, notably see issues on the issue tracker, but it it quite reasonable.
The side effects of ambitious goals are often the most valuable thing achieved once again? I to actually make the project be more important thatn the side effects this time, but we'll see.
Since the last update, I've made some major improvements to the baseline tech of the website, which I'll move little by little into OurBigBook. Some of the improvements actually started in OurBigBook.com. The improvements were:
- got a satisfactorily comprehensive linting working at: this commit. Nothing is easy, not even that! Part of the wisdom extracted to: stackoverflow.com/questions/58233482/next-js-setting-up-eslint-for-nextjs/70519682#70519682.
- fully rationalized directory structure to avoid nasty errors that show up in Next.js when accidentally requiring backend stuff on the client. Commit. A detailed explanation of this was extracted to: stackoverflow.com/questions/64926174/module-not-found-cant-resolve-fs-in-next-js-application/70363153#70363153.
- create an extremely clean and rationalized way to do API tests from a simple
npm test. These now actually start a clean server, and make full HTTP requests to that server. Commit. Wisdom extracted to: stackoverflow.com/questions/63762896/whats-the-best-way-to-test-express-js-api/70479940#70479940. - greatly reduce the number of SQL queries, fully understood every problem
- more intelligently using JOINs where I have managed to get Sequelize to do what I fucking want. This also led to several sequelize Stack Overflow answers as usual: stackoverflow.com/search?tab=newest&q=user%3a895245%20%5bsequelize%5dEverything that I didn't manage to do because of crappy sequelize is documented at: github.com/cirosantilli/node-express-sequelize-nextjs-realworld-example-app/issues/5
- better understanding Next.js/React/useSWR do avoid doing double API queries
Currently, none of the crucial cross file features like
\x, \Include and table of contents are working. I was waiting until the above mentioned features were done, and now I'm going to get to that.I've finally had enough of Nvidia breaking my Ubuntu 21.10 suspend, so I investigated some more and found a workaround on the NVIDIA forums: stackoverflow.com/questions/58233482/next-js-setting-up-eslint-for-nextjs/70519682#70519682.
Thanks enormously to heroic user humblebee, and once again, Nvidia, fuck you.
At github.com/cirosantilli/china-dictatorship/issues/738 a user made a comment about gang raping my mother (more like country-raping).
As mentioned at github.com/cirosantilli/china-dictatorship/issues/739, ally Martin then reported the issue, and GitHub took down the wumao's account for a while using their undocumented shadowban feature, until the wumao edited the issue.
Based on the discussion with Martin, I then recommended at github.com/cirosantilli/china-dictatorship/blob/41b4741a4e6553f44f5f1ef85cf63c55eb7b8277/CONTRIBUTING.md that we do not report such issues, and that GitHub do not delete such accounts, with rationale explained on the CONTRIBUTING.
Some further comments at: Section "Cataclysm: Dark Days Ahead".
Articles by others on the same topic
There are currently no matching articles.