
CIA 2010 covert communication websites 2013 DNS Census virtual host cleanup heuristic keyword searches Updated 2025-07-16
There are two keywords that are killers: "news" and "world" and their translations or closely related words. Everything else is hard. So a good start is:
grep -e news -e noticias -e nouvelles -e world -e globaliran + football:
- iranfootballsource.com: the third hit for this area after the two given by Reuters! Epic.
3 easy hits with "noticias" (news in Portuguese or Spanish"), uncovering two brand new ip ranges:
- 66.45.179.205 noticiasporjanua.com
- 66.237.236.247 comunidaddenoticias.com
- 204.176.38.143 noticiassofisticadas.com
Let's see some French "nouvelles/actualites" for those tumultuous Maghrebis:
- 216.97.231.56 nouvelles-d-aujourdhuis.com
news + global:
- 204.176.39.115 globalprovincesnews.com
- 212.209.74.105 globalbaseballnews.com
- 212.209.79.40: hydradraco.com
OK, I've decided to do a complete Wayback Machine CDX scanning of
news... Searching for .JAR or https.*cgi-bin.*\.cgi are killers, particularly the .jar hits, here's what came out:- 62.22.60.49 telecom-headlines.com
- 62.22.61.206 worldnewsnetworking.com
- 64.16.204.55 holein1news.com
- 66.104.169.184 bcenews.com
- 69.84.156.90 stickshiftnews.com
- 74.116.72.236 techtopnews.com
- 74.254.12.168 non-stop-news.net
- 193.203.49.212 inews-today.com
- 199.85.212.118 just-kidding-news.com
- 207.210.250.132 aeronet-news.com
- 212.4.18.129 sightseeingnews.com
- 212.209.90.84 thenewseditor.com
- 216.105.98.152 modernarabicnews.com
"headline": only 140 matches in 2013-dns-census-a-novirt.csv and 3 hits out of 269 hits. Full inspection without CDX led to no new hits.
CIA 2010 covert communication websites activegameinfo.com Updated 2025-07-16
whoisxmlapi WHOIS history March 22, 2011:
- Registrar Name: NETWORK SOLUTIONS, LLC.
- Created Date: January 26, 2010 00:00:00 UTC
- Updated Date: November 27, 2010 00:00:00 UTC
- Expires Date: January 26, 2012 00:00:00 UTC
- Registrant Name: Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions
- Registrant Street: PO Box 459
- Registrant City: PA
- Registrant State/Province: US
- Registrant Postal Code: 18222
- Registrant Country: UNITED STATES
- Administrative Name: Corral, Elizabeth|ATTN ACTIVEGAMINGINFO.COM|care of Network Solutions
- Administrative Street: PO Box 459
- Administrative City: Drums
- Administrative State/Province: PA
- Administrative Postal Code: 18222
- Administrative Country: UNITED STATES
- Administrative Email: xc2mv7ur8cw@networksolutionsprivateregistration.com
- Administrative Phone: 5707088780
- Name servers: NS23.DOMAINCONTROL.COM|NS24.DOMAINCONTROL.COM
CIA 2010 covert communication websites Are there .org hits? Updated 2025-07-16
Previously it was unclear if there were any .org hits, until we found the first one with clear comms: web.archive.org/web/20110624203548/http://awfaoi.org/hand.jar
Later on, two more clear ones were found with expired domain trackers:further settling their existence. Later on newimages.org also came to light.
Others that had been previously found in IP ranges but without clear comms:
.org is very rare, and has been excluded from some of our search heuristics. That was a shame, but likely not much was missed.
CIA 2010 covert communication websites atomworldnews.com Updated 2025-07-16
whoisxmlapi WHOIS record on April 17, 2011
CIA 2010 covert communication websites Backlinks Updated 2025-08-08
Announcements and updates by self:
- 2023-06-10: initial announcements
- twitter.com/cirosantilli/status/1667532991315230720. Follow up when more domains were found: twitter.com/cirosantilli/status/1717445686214504830
- www.reddit.com/r/OSINT/comments/146185r/i_found_16_new_cia_covert_communication_websites/. Marked as SPAM 5 by mods days later. After reaching 92 votes, a very positive reply for that niche sub, and being obviously on topic. Weird. Anyways, did its job and likely kicked off hackernews.
- www.facebook.com/cirosantilli/posts/pfbid04KvRbEXghJakcD4AQz4379L5oVjPZ6vrBF1Eak3p81VnqRSXuXdvvYonCWPhGfQXl
- 2023-10-26 twitter.com/cirosantilli/status/1717445686214504830: announcement by self after finding 75 more sites
- Shared by others soo after:
- www.reddit.com/r/conspiracy/comments/14705gp/cia_2010_covert_communication_websites/ failed attempt with bad link unfortunately
- 2024-01-15: twitter.com/cirosantilli/status/1747742453778559165 Oleg Shakirov's findings
- 2024-01-23: mastodon.social/@cirosantilli/111807480628392615 ipinf.ru gives 4 hits and 4 new suspects, announced at:
- 2024-09 Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects
- 2025-03-13: 44 new domains found: Section "44 new CIA websites"
- 2025-04-14: cqcounter screenshots used to confirm many new hits: Section "60 new CIA website screenshots discovered on CQ Counter"
- 2025-05-23: Section "Backing up CIA website archives for research and posterity"
Pings by self:
- 2025-03-13:
- x.com/cirosantilli/status/1900278353065894324 pings x.com/JackRhysider Jack Rhysider, host of the Darkent Diaries podcast
- x.com/cirosantilli/status/1900828210578727276 pings x.com/JennaMC_Laugh Jenna McLaughlin and x.com/zachsdorfman Zach Dorfman, authors of the 2018 Yahoo articles
- 2025-03-31 going to find random interested people on Twitter:
- 2025-05-05:
- inteltoday.org/2021/07/31/us-national-whistleblower-day-july-30-2021-i-john-reidy-declare-cia-debacle-in-iran-china/#comment-46375 pings the author Dr. Ludwig De Braeckeleer. Besides his interest in intelligence, the dude actually also won a Breakthrough Prize in Physics, holy fuck it's mind boggling.
- x.com/cirosantilli/status/1919391488422662245 pings x.com/marisaataylor Marisa Taylor, author of the 2014, McClathy DC article
- x.com/cirosantilli/status/1919859345593880812 and x.com/cirosantilli/status/1919846838850499002 pings x.com/billmarczak Bill Marczak and x.com/thezedwards Zach Edwards, technical analysts for the Reuters article
- x.com/cirosantilli/status/1919860643408007644 pings x.com/joel_schectman Joel Schectman and x.com/bozorgmehr Bozorgmehr Sharafedin authors of the Reuters article
- x.com/cirosantilli/status/1919870831758365113 pings x.com/zachsdorfman Zach Dorfman (protected account) author of the Foreign Policy article
- x.com/cirosantilli/status/1920073080363241727 pings x.com/markmazzettinyt Mark Mazzetti, x.com/nytmike Michael S. Schmidt and x.com/mattapuzzo Matt Apuzzo authors of the 2017 New York Times article. Could not find a Twitter for the fourth author Adam Goldman.
- x.com/PeteWilliamsNBC Pete Williams author of the 2018 NCB News artricle: he's retired and not active on Twitter, not going to bother pinging
Reactions by others:
- 2023-06-19: www.reddit.com/r/numberstations/comments/14dexiu/after_numbers_stations_vanished/ (30 points) off topic on that sub, but thankfully was not deleted, interesting sub topic
- 2023-10-26: Google Analytics backlink from lms.fh-wedel.de/ path unknown. Some shitty German university: en.wikipedia.org/wiki/Fachhochschule_Wedel_University_of_Applied_Sciences LMS stands for Learning management system, apparently a Moodle instance. Maybe they have some Open educational resources, but all in German so pointless
- Second wave:
- 2023-12-01: news.ycombinator.com/item?id=38492304 (65 points). Second submission but pointing to OurBigBook.com rather than cirosantilli.com: ourbigbook.com/cirosantilli/cia-2010-covert-communication-websites We take those. Reached only 65 points as of January 2024.
- 2023-12-02: buttondown.email/grugq/archive/december-2-2023/. "grugq" is the handle of a zero day dealer whose received some scrutiny in 2012 after a Forbes protile was written about him: archive.ph/7mUG5. He comments:presumably referring to DNS Census 2013.
I don’t think anyone anticipated that databases leaked by hackers would enable OSINT researchers to conduct counterintelligence investigations that rival the state security services.
- 2024-01-12: twitter.com/jeremy_wokka/status/1745657801584656564 (40k followers, mid of thread)
- 2025-04-02: www.reddit.com/r/wikipedia/comments/1kd7rzo/comment/mqoocu7/?context=3 user Gilda1234_ mentions this project in a comment to "Between 2010 and 2012, China identified and killed at least 30 CIA informants in the country" by idlikebab
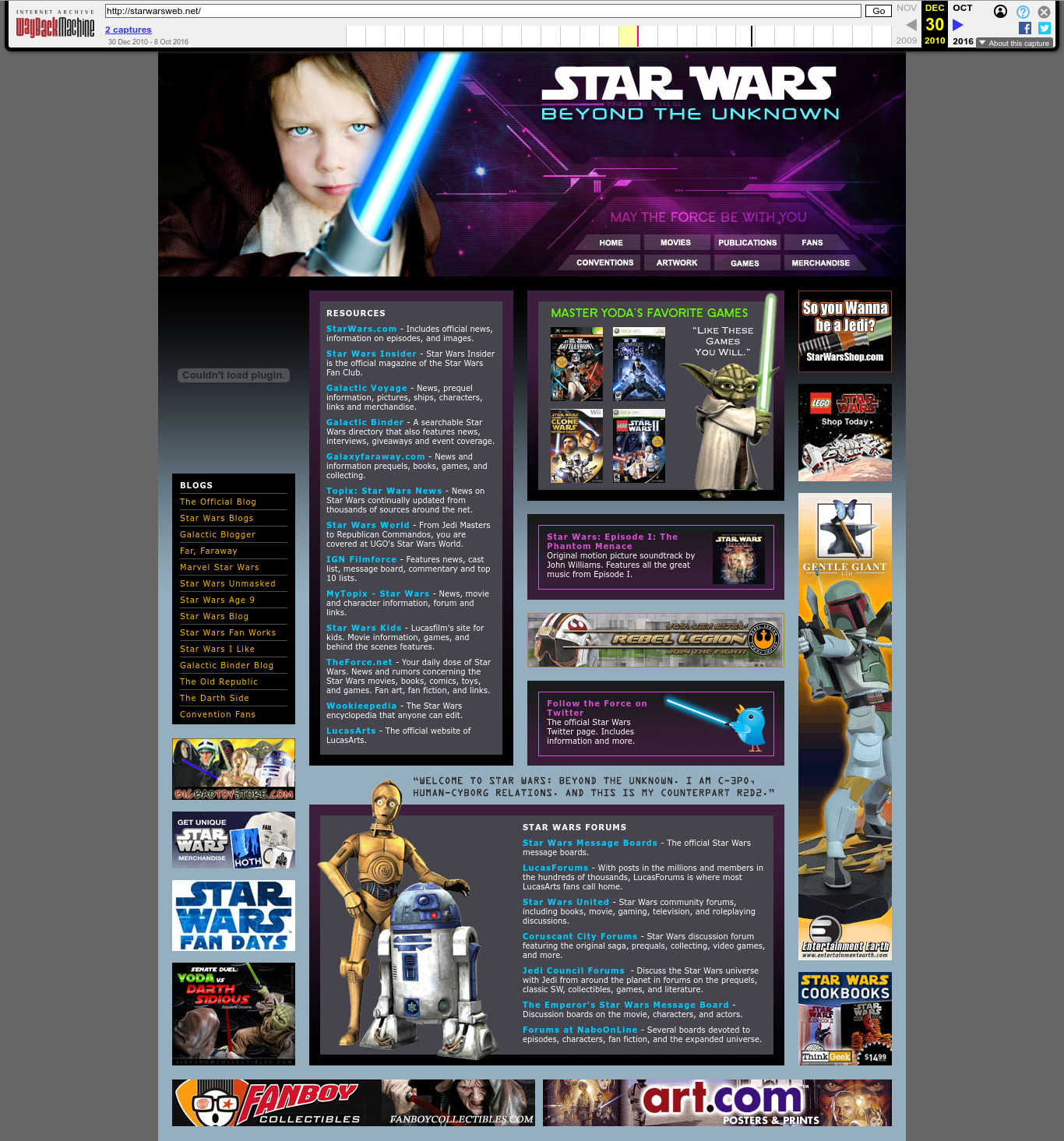
- 2025-05-26 The CIA Secretly Ran a Star Wars Fan Site by Joseph Cox from 404 media, an upstart publication covering edgy digital subjects. This was likely a result of Ciro publicly pinging x.com/zachsdorfman Zach Edwards, one of the analysts for the Reuters article, at x.com/cirosantilli/status/1919846838850499002, as he is cited in the article as having done a technical review. This had a massive knowdown effect and several other media picked the story up. Ciro announcing it at:Forum threads spawned from it:Other media that picked it up:
- Reddit
- www.reddit.com/r/StarWars/comments/1kvtzwm/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/StarWarsEU/comments/1kvu5g8/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/nottheonion/comments/1kxtpw4/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/nottheonion/comments/1kxtpw4/comment/muu531n/A source: www.thesun.co.uk/sport/33904606/putin-spies-cristiano-ronaldo-youtube-videos-messages/
They aren’t the only ones who do stuff like this, Russian agents were using Ronaldo highlight vids on YouTube to communicate 😭
- www.reddit.com/r/nottheonion/comments/1kxtpw4/comment/muu531n/
- www.reddit.com/r/Games/comments/1kye0pj/the_cia_operated_a_network_of_gaming_sites_and/
- www.reddit.com/r/technology/comments/1kvvx48/the_cia_secretly_ran_a_star_wars_fan_site_the/
- www.reddit.com/r/realtech/comments/1kvwigb/the_cia_secretly_ran_a_star_wars_fan_site_the/
- www.reddit.com/r/conspiracy/comments/1kw991t/the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/LowStakesConspiracies/comments/1kwbf2y/the_cia_run_a_star_wars_fansite/
- www.reddit.com/r/andor/comments/1kw587c/very_andor_the_cia_secretly_ran_a_star_wars_fan/
- www.reddit.com/r/BrasildoB/comments/1kw6qah/um_brasileiro_acaba_de_publicar_detalhes_sobre_os/
- www.reddit.com/r/mexico/comments/1kwhuqg/la_incre%C3%ADble_web_de_star_wars_que_us%C3%B3_la_cia_para/
- www.reddit.com/r/KotakuInAction/comments/1kwoch5/the_cia_ran_a_star_wars_fan_site_to_secretly/
- www.reddit.com/r/starwarscanon/comments/1kwoxoq/til_the_cia_secretly_ran_a_star_wars_fan_site/
- www.reddit.com/r/TrueAnon/comments/1kwhxmj/cia_ran_star_wars_fan_site/
- www.reddit.com/r/MauLer/comments/1kxqim9/figures/
- www.reddit.com/r/Intelligence/comments/1kwybso/cia_uses_star_wars_website_to_communicate_with/
- www.reddit.com/r/StarWarsCirclejerk/comments/1kwzeto/in_my_mind_all_last_jedi_haters_are_feds/
- www.reddit.com/r/memes/comments/1kw5x9n/the_cia_really_gets_creative_sometimes/
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/the_cia_secretly_ran_a_star_wars_fan_site_for/
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/comment/muemkhk/ brings up
europeangoldfinch.netfirst described in Season 2 of Prison Break in 2007.Europeangoldfinch.net was a website used by Michael Scofield that allowed the Fox River Eight to communicate with each other on its online message board
- www.reddit.com/r/BurnNotice/comments/1kw4b5k/comment/muemkhk/ brings up
- Decent tweets:
- x.com/CultureCrave/status/1927119278047727908 600k followers
- x.com/val_reloaded/status/1927349417306161165 Argentinian Twitcher 400k followers
- news.ycombinator.com/item?id=44098274 failed unfortunately
- knockout.chat/thread/72492/1
- fanlore.org/wiki/2009-2013_CIA_communications_websites
- YouTube
Video 1. . Source. 2025-05-27. 180k subs. This one focuses on talking about the games and uses this article as the mainreference. He makes that nice note that the game Star Wars Battlefront II reached all time highs in the days following the CIA releasejThe articles apparenty coincided with the reelase of Star Wars Battlefront III alpha to lukewarm reception. Video 2. Star Wars Fan Sites Are Run by THE FEDS?! by Clownfish TV. Source. 2025-05-27. 600k subs. Video didn't take off however. The channel seems to be semi dead. But it is cool to see an American with YouTube-worth eloquence going over it.Video 3. . Source. 2025-05-28. 2M subs. He's basically reading the techspot article: www.techspot.com/news/108062-cia-used-star-wars-fan-site-secretly-communicate.html. Video 5. . Source. Seytonic had previously covered Reuters article at this other video:Video 8. . Source. 2025-06-13. 12k subs. This video draws on some research from this article, citing it on the source list: docs.google.com/document/d/1k7-YoOMRTL8qKE_FoRnyvR1QDa0JTBJo_a-SRwVMEu4/edit?tab=t.0 and using some of the screenshots.This video has some good mentions of the details of Jerry Chun Shing Lee's story which Ciro Santilli was not aware of. - other voice media:
- Meneame, a Spanish Reddit: 2025-05-27 www.meneame.net/m/tecnolog%C3%ADa/increible-web-star-wars-uso-cia-espiar-espana-mexico-otros/standard
Starting on that same day someone made starwarsweb.net redirect to cia.gov at 2025-05-26T13:28:02Z: www.whois.com/whois/starwarsweb.net- "mainstream":
- www.dailymail.co.uk/news/article-14752155/CIA-fake-websites-Star-Wars-communicate-spies.html Also announcing that:
* mastodon.social/@cirosantilli/114580297330915997
* x.com/cirosantilli/status/1927373757829583344
* www.linkedin.com/posts/cirosantilli_the-cia-secretly-ran-a-star-wars-fan-site-activity-7333140418504646656-eRzq/
* www.facebook.com/cirosantilli/posts/pfbid026kssQcXm7TwAHDJ4BQ73RKFCmJRLJsT1dfRpEmZ5GZdmsp8DukaqrbefFuGDqNZvl - www.themirror.com/news/us-news/cia-uses-star-wars-website-1174874
- www.dailymail.co.uk/news/article-14752155/CIA-fake-websites-Star-Wars-communicate-spies.html Also announcing that:
- "mainstream" non-English:
- www.france24.com/fr/%C3%A9co-tech/20250528-star-wars-bourse-ou-football-les-etranges-sites-pour-les-informateurs-de-la-cia (French)
- francais.rt.com/international/121266-espionnage-cia-utilisait-sites-fans-star-wars-pour-communiquer-secretement-avec-ses-agents-etrangers RT in French, God
- www.derstandard.at/consent/tcf/story/3000000271640/die-cia-hat-heimlich-eine-star-wars-fanseite-betrieben Der Standard (Austria)
- tw.news.yahoo.com/玩家可能都用過?原來「美國中情局」cia曾營運過遊戲媒體網站掩護行動-070742215.html (Yahoo Taiwan)
- www.abc.es/internacional/cia-empleo-sitios-web-inofensivos-paginas-star-20250528171402-nt.html (Spain)
- "non-mainstream":
- www.dexerto.com/entertainment/the-cia-secretly-used-a-star-wars-fan-site-to-talk-to-spies-report-3199318/ and x.com/Dexerto/status/1927000891963363406 large-ish publication
- www.thegamer.com/star-wars-fan-website-cia-usa-government-spies-controlled/
- www.techspot.com/news/108062-cia-used-star-wars-fan-site-secretly-communicate.html This was one of the biggest hits on Google Analytics actually.
- gigazine.net/news/20250527-starwars-fan-sites-made-by-cia/ Japanese
- Wired:
- www.pcgamer.com/gaming-industry/the-cia-operated-a-network-of-gaming-sites-and-even-a-star-wars-fanpage-that-were-part-of-one-of-its-worst-ever-intelligence-catastrophes/
- www.msn.com/en-us/news/technology/the-cia-secretly-ran-a-star-wars-fan-site-to-communicate-with-spies/ar-AA1FASFY
- www.gamespot.com/articles/the-cia-once-ran-a-star-wars-fan-site-as-part-of-a-global-intelligence-effort/1100-6532045/
- www.darkhorizons.com/how-u-s-spies-used-a-star-wars-fan-page/
- gigazine.net/news/20250527-starwars-fan-sites-made-by-cia/
- Reddit
- 2025-08-01 saw another mini-trend due to The CIA Built Hundreds of Covert Websitesby Alan Macleod: www.mintpressnews.com/cia-secret-network-885-fake-websites/290325/
This then spawned some sindicated posts:and forum threads:- www.sott.net/article/500997-The-CIA-built-hundreds-of-covert-websites-Heres-what-they-were-hiding
- scheerpost.com/2025/08/02/the-cia-built-hundreds-of-covert-websites-heres-what-they-were-hiding/
- 2025-08-02 alethonews.com/2025/08/02/the-cia-built-hundreds-of-covert-websites-heres-what-they-were-hiding/ (Greek)
- 2025-08-02 popularresistance.org/the-cia-built-hundreds-of-covert-websites/
- 2025-08-04 cz24.news/alan-macleod-cia-vytvorila-stovky-tajnych-webu-globalni-spionazni-terminaly-co-vlastne-skryvaly/ (Czech)
Notable reactions to the websites themselves:
- 2022-09-29 www.reddit.com/r/soccer/comments/xrgua4/the_cia_used_a_message_board_on_a_fake_soccer/ "The CIA used a message board on a fake soccer website called "Iraniangoals.com" to communicate with Iranian spies, dozens of whom were arrested after the website was discovered." by user Carlos-Dangerzone
CIA 2010 covert communication websites Find missing hits in IP ranges Updated 2025-07-16
It is because there was nothing there, or just because we don't have a good enough reverse IP database?
It is possible that DomainTools could help with a more complete database, but its access is extremely expensive and out of reach at the moment.
Putting 140 USD into WhoisXMLAPI to get all whois histories of interest for possible reverse searches would also be of interest.
CIA 2010 covert communication websites Fingerprints Updated 2025-07-16
From The Reuters websites and others we've found, we can establish see some clear stylistic trends across the websites which would allow us to find other likely candidates upon inspection:The most notable dissonance from the rest of the web is that there are no commercial looking website of companies, presumably because it was felt that it would be possible to verify the existence of such companies.
- natural sounding, sometimes long-ish, domain names generally with 2 or 3 full words. Most in English language, but a few in Spanish, and very few in other languages like French.
- shallow websites with a few tabs, many external links, sometimes many images, and few internal pages
- common themes include:
- .com and .net top-level domains, plus a few other very rare non .com .net TLDs, notably .info and .org
- each one has one "communication mechanism file": communication mechanisms
- narrow page width like in the days of old, lots of images
- split header images
- some common pattern they follow in their news lists:
ul.rss-items > li.rss-item, e.g.: web.archive.org/web/20110202092126/http://beamingnews.com/- links with class
a.newslinkanda.newslinkalte.g. web.archive.org/web/20110128181622/http://profile-news.com/
Most domains are the only domain for its IP, i.e. the websites are mostly private hosted. However we have later found many exceptions to this general indicator, so it should not be used as a strong exclusion rule.
{kind=link}
CIA 2010 covert communication websites Breakthroughs Updated 2025-07-16
Some less-trivial breakthroughs:
- finding 2013 DNS Census
- CGI comms characterization
- secure subdomain search on 2013 DNS Census let to a few hits
- 2013 DNS Census virtual host cleanup heuristic keyword searches was massive and led to many new ranges
CIA 2010 covert communication websites CGI comms Updated 2025-07-16
We've come across a few shallow and stylistically similar websites on suspicious ranges with this pattern.
No JS/JAR/SWF comms, but rather a subdomain, and an HTTPS page with .cgi extension that leads to a login page. Some names seen for this subdomain:
The question is, is this part of some legitimate tooling that created such patterns? And if so which? Or are they actual hits with a new comms mechanism not previously seen?
The fact that:suggests to Ciro that they are an actual hit.
- hits of this type are so dense in the suspicious ranges
- they are so stylistically similar between on another
- citizenlabs specifically mentioned a "CGI" comms method
In particular, the
secure and ssl ones are overused, and together with some heuristics allowed us to find our first two non Reuters ranges! Section "secure subdomain search on 2013 DNS Census"Some currently known URLsIf we could do a crawl search for
- backstage.musical-fortune.net/cgi-bin/backstage.cgi
- clients.smart-travel-consultant.com/cgi-bin/clients.cgi
- members.it-proonline.com/cgi-bin/members.cgi
- members.metanewsdaily.com/cgi-bin/ABC.cgi
- miembros.todosperuahora.com/cgi-bin/business.cgi
- secure.altworldnews.com/cgi-bin/desk.cgi
- secure.driversinternationalgolf.com/cgi-bin/drivers.cgi
- secure.freshtechonline.com/cgi-bin/tech.cgi
- secure.globalnewsbulletin.com/cgi-bin/index.cgi
- secure.negativeaperture.com/cgi-bin/canon.cgi
- secure.riskandrewardnews.com/cgi-bin/worldwide.cgi
- secure.theworld-news.net/cgi-bin/news.cgi
- secure.topbillingsite.com/cgi-bin/main.cgi
- secure.worldnewsandent.com/cgi-bin/news.cgi
- ssl.beyondnetworknews.com/cgi-bin/local.cgi
- ssl.newtechfrontier.com/cgi-bin/tech.cgi
- www.businessexchangetoday.com/cgi-bin/business.cgi
- heal.conquermstoday.com (path unknown)
secure.*com/cgi-bin/*.cgi that might be a good enough fingerprint, maybe even *.*com/cgi-bin/*.cgi. Edit: it is not perfect, but we kind of did it: Section "secure subdomain search on 2013 DNS Census". CIA 2010 covert communication websites CGI comms variant Updated 2025-07-16
Later on, we've also come across some stylistic hits in IP ranges with apparent slight variations of the CGI comms pattern:
Since these are so rare, it is still a bit hard to classify them for sure, but they are of great interest no doubt, as as we start to notice these patterns more tend to come if it is a thing.
CIA 2010 covert communication websites club.domain.cn Updated 2025-07-16
TODO what does this Chinese forum track? New registrations? Their focus seems to be domain name speculation
Some of the threads contain domain dumps. We haven't yet seen a scrapable URL pattern, but their data goes way back and did have various hits. The forum seems to have started in 2006: club.domain.cn/forum.php?mod=forumdisplay&fid=41&page=10127
club.domain.cn/forum.php?mod=viewthread&tid=241704 "【国际域名拟删除列表】2007年06月16日" is the earliest list we could find. It is an expired domain list.
Some hits:
- club.domain.cn/forum.php?mod=viewthread&tid=709388 contains
alljohnny.comThe thread title is "2009.5.04". The post date 2009-04-30Breadcrumb nav: 域名论坛 > 域名增值交易区 > 国际域名专栏 (domain name forum > area for domain names increasing in value > international domais)
CIA 2010 covert communication websites Common Crawl Updated 2025-07-16
So far, no new domains have been found with Common Crawl, nor have any existing known domains been found to be present in Common Crawl. Our working theory is that Common Crawl never reached the domains How did Alexa find the domains?
Let's try and do something with Common Crawl.
Unfortunately there's no IP data apparently: github.com/commoncrawl/cc-index-table/issues/30, so let's focus on the URLs.
Using their Common Crawl Athena method: commoncrawl.org/2018/03/index-to-warc-files-and-urls-in-columnar-format/
Sample first output line:So
# 2
url_surtkey org,whwheelers)/robots.txt
url https://whwheelers.org/robots.txt
url_host_name whwheelers.org
url_host_tld org
url_host_2nd_last_part whwheelers
url_host_3rd_last_part
url_host_4th_last_part
url_host_5th_last_part
url_host_registry_suffix org
url_host_registered_domain whwheelers.org
url_host_private_suffix org
url_host_private_domain whwheelers.org
url_host_name_reversed
url_protocol https
url_port
url_path /robots.txt
url_query
fetch_time 2021-06-22 16:36:50.000
fetch_status 301
fetch_redirect https://www.whwheelers.org/robots.txt
content_digest 3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ
content_mime_type text/html
content_mime_detected text/html
content_charset
content_languages
content_truncated
warc_filename crawl-data/CC-MAIN-2021-25/segments/1623488519183.85/robotstxt/CC-MAIN-20210622155328-20210622185328-00312.warc.gz
warc_record_offset 1854030
warc_record_length 639
warc_segment 1623488519183.85
crawl CC-MAIN-2021-25
subset robotstxturl_host_3rd_last_part might be a winner for CGI comms fingerprinting!Naive one for one index:have no results... data scanned: 5.73 GB
select * from "ccindex"."ccindex" where url_host_registered_domain = 'conquermstoday.com' limit 100;Let's see if they have any of the domain hits. Let's also restrict by date to try and reduce the data scanned:Humm, data scanned: 60.59 GB and no hits... weird.
select * from "ccindex"."ccindex" where
fetch_time < TIMESTAMP '2014-01-01 00:00:00' AND
url_host_registered_domain IN (
'activegaminginfo.com',
'altworldnews.com',
...
'topbillingsite.com',
'worldwildlifeadventure.com'
)Sanity check:has a bunch of hits of course. Data scanned: 212.88 MB,
select * from "ccindex"."ccindex" WHERE
crawl = 'CC-MAIN-2013-20' AND
subset = 'warc' AND
url_host_registered_domain IN (
'google.com',
'amazon.com'
)WHERE crawl and subset are a must! Should have read the article first.Let's widen a bit more:Still nothing found... they don't seem to have any of the URLs of interest?
select * from "ccindex"."ccindex" WHERE
crawl IN (
'CC-MAIN-2013-20',
'CC-MAIN-2013-48',
'CC-MAIN-2014-10'
) AND
subset = 'warc' AND
url_host_registered_domain IN (
'activegaminginfo.com',
'altworldnews.com',
...
'worldnewsandent.com',
'worldwildlifeadventure.com'
) CIA 2010 covert communication websites Communication mechanism Updated 2025-07-16
There are four main types of communication mechanisms found:These have short single word names with some meaning linked to their website.
- There is also one known instance where a .zip extension was used! web.archive.org/web/20131101104829*/http://plugged-into-news.net/weatherbug.zip as:
<applet codebase="/web/20101229222144oe_/http://plugged-into-news.net/" archive="/web/20101229222144oe_/http://plugged-into-news.net/weatherbug.zip"JAR is the most common comms, and one of the most distinctive, making it a great fingerprint. - JavaScript file. There are two subtypes:
- JavaScript with SHAs. Rare. Likely older. Way more fingerprintable.
- JavaScript without SHAs. They have all been obfuscated slightly different and compressed. But the file sizes are all very similar from 8kB to 10kB, and they all look similar, so visually it is very easy to detect a match with good likelyhood.
- Adobe Flash swf file. In all instances found so far, the name of the SWF matches the name of the second level domain exactly, e.g.:While this is somewhat of a fingerprint, it is worth noting that is was a relatively commonly used pattern. But it is also the rarest of the mechanisms. This is a at a dissonance with the rest of the web, which circa 2010 already had way more SWF than JAR apparently.
http://tee-shot.net/tee-shot.swfSome of the SWF websites have archives for empty/servletpages:which makes us think that it is a part of the SWF system../bailsnboots.com/20110201234509/servlet/teammate/index.html ./currentcommunique.com/20110130162713/servlet/summer/index.html ./mynepalnews.com/20110204095758/servlet/SnoopServlet/index.html ./mynepalnews.com/20110204095403/servlet/release/index.html ./www.hassannews.net/20101230175421/servlet/jordan/index.html ./zerosandonesnews.com/20110209084339/servlet/technews/index.html - CGI comms
Because the communication mechanisms are so crucial, they tend to be less varied, and serve as very good fingerprints. It is not ludicrous, e.g. identical files, but one look at a few and you will know the others.
CIA 2010 covert communication websites iraniangoalkicks.com Updated 2025-07-16
whoisxmlapi WHOIS history March 23, 2011:
whoisrequest.com/history/ mentions:
1 May, 2007: Domain created*, nameservers added. Nameservers:
1 May, 2007: Domain created*, nameservers added. Nameservers:
- ns1.qwknetllc.com
- ns2.qwknetllc.com
Ciência sem Fronteiras Updated 2025-07-16
CIA 2010 covert communication websites Data sources Updated 2025-07-16
This is a dark art, and many of the sources are shady as fuck! We often have no idea of their methodology. Also no source is fully complete. We just piece up as best we can.
- www.zone-h.org/archive/ip=208.76.80.93/page=11?hz=1 mentions
newsupdatesite.comand mentions "defacement", the "Mass Deface III" pastebin comes to mind. No other nearby hits on quick inspection.
CIA 2010 covert communication websites DNS Census 2013 Updated 2025-07-16
Main article: DNS Census 2013.
This data source was very valuable, and led to many hits, and to finding the first non Reuters ranges with Section "secure subdomain search on 2013 DNS Census".
CIA 2010 covert communication websites dnshistory.org Updated 2025-07-16
dnshistory.org contains historical domain -> mappings.
We have not managed to extract much from this source, they don't have as much data on the range of interest.
But they do have some unique data at least, perhaps we should try them a bit more often, e.g. they were the only source we've seen so far that made the association: headlines2day.com -> 212.209.74.126 which places it in the more plausible globalbaseballnews.com IP range.
TODO can it do IP to domain? Or just domain to IP? Asked on their Discord: discord.com/channels/698151879166918727/968586102493552731/1124254204257632377. Their banner suggests that yes:
With our new look website you can now find other domains hosted on the same IP address, your website neighbours and more even quicker than before.
Owner replied, you can't:
At the moment you can only do this for current not historical records
In principle, we could obtain this data from search engines, but Google doesn't track that entire website well, e.g. no hits for
site:dnshistory.org "62.22.60.48" presumably due to heavy IP throttling.Homepage dnshistory.org/ gives date starting in 2009:and it is true that they do have some hits from that useful era.
Here at DNS History we have been crawling DNS records since 2009, our database currently contains over 1 billion domains and over 12 billion DNS records.
Any data that we have the patience of extracting from this we will dump under github.com/cirosantilli/media/blob/master/cia-2010-covert-communication-websites/hits.json.
CIA 2010 covert communication websites Expired domain trackers Updated 2025-07-16
When you Google most of the hit domains, many of them show up on "expired domain trackers", and above all Chinese expired domain trackers for some reason, notably e.g.:This suggests that scraping these lists might be a good starting point to obtaining "all expired domains ever".
- hupo.com: e.g. static.hupo.com/expdomain_myadmin/2012-03-06(国际域名).txt. Heavily IP throttled. Tor hindered more than helped.Scraping script: ../cia-2010-covert-communication-websites/hupo.sh. Scraping does about 1 day every 5 minutes relatively reliably, so about 36 hours / year. Not bad.Results are stored under
tmp/humo/<day>.Check for hit overlap:The hits are very well distributed amongst days and months, at least they did a good job hiding these potential timing fingerprints. This feels very deliberately designed.grep -Fx -f <( jq -r '.[].host' ../media/cia-2010-covert-communication-websites/hits.json ) cia-2010-covert-communication-websites/tmp/hupo/*There are lots of hits. The data set is very inclusive. Also we understand that it must have been obtains through means other than Web crawling, since it contains so many of the hits.Some of their files are simply missing however unfortunately, e.g. neither of the following exist:webmasterhome.cn did contain that one however: domain.webmasterhome.cn/com/2012-07-01.asp. Hmm. we might have better luck over there then?2018-11-19 is corrupt in a new and wonderful way, with a bunch of trailing zeros:ends in:wget -O hupo-2018-11-19 'http://static.hupo.com/expdomain_myadmin/2018-11-19%EF%BC%88%E5%9B%BD%E9%99%85%E5%9F%9F%E5%90%8D%EF%BC%89.txt hd hupo-2018-11-19000ffff0 74 75 64 69 65 73 2e 63 6f 6d 0d 0a 70 31 63 6f |tudies.com..p1co| 00100000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 0018a5e0 00 00 00 00 00 00 00 00 00 |.........|More generally, several files contain invalid domain names with non-ASCII characters, e.g. 2013-01-02 contains365<D3>л<FA><C2><CC>.com. Domain names can only contain ASCII charters: stackoverflow.com/questions/1133424/what-are-the-valid-characters-that-can-show-up-in-a-url-host Maybe we should get rid of any such lines as noise.Some files around 2011-09-06 start with an empty line. 2014-01-15 starts with about twenty empty lines. Oh and that last one also has some trash bytes the end<B7><B5><BB><D8>. Beauty. - webmasterhome.cn: e.g. domain.webmasterhome.cn/com/2012-03-06.asp. Appears to contain the exact same data as "static.hupo.com"Also has some randomly missing dates like hupo.com, though different missing ones from hupo, so they complement each other nicely.Some of the URLs are broken and don't inform that with HTTP status code, they just replace the results with some Chinese text 无法找到该页 (The requested page could not be found):Several URLs just return length 0 content, e.g.:It is not fully clear if this is a throttling mechanism, or if the data is just missing entirely.
curl -vvv http://domain.webmasterhome.cn/com/2015-10-31.asp * Trying 125.90.93.11:80... * Connected to domain.webmasterhome.cn (125.90.93.11) port 80 (#0) > GET /com/2015-10-31.asp HTTP/1.1 > Host: domain.webmasterhome.cn > User-Agent: curl/7.88.1 > Accept: */* > < HTTP/1.1 200 OK < Date: Sat, 21 Oct 2023 15:12:23 GMT < Server: Microsoft-IIS/6.0 < X-Powered-By: ASP.NET < Content-Length: 0 < Content-Type: text/html < Set-Cookie: ASPSESSIONIDCSTTTBAD=BGGPAONBOFKMMFIPMOGGHLMJ; path=/ < Cache-control: private < * Connection #0 to host domain.webmasterhome.cn left intactStarting around 2018, the IP limiting became very intense, 30 mins / 1 hour per URL, so we just gave up. Therefore, data from 2018 onwards does not contain webmasterhome.cn data.Starting from2013-05-10the format changes randomly. This also shows us that they just have all the HTML pages as static files on their server. E.g. with:we see:grep -a '<pre' * | s2013-05-09:<pre style='font-family:Verdana, Arial, Helvetica, sans-serif; '><strong>2013<C4><EA>05<D4><C2>09<C8>յ<BD><C6>ڹ<FA><BC><CA><D3><F2><C3><FB></strong><br>0-3y.com 2013-05-10:<pre><strong>2013<C4><EA>05<D4><C2>10<C8>յ<BD><C6>ڹ<FA><BC><CA><D3><F2><C3><FB></strong> - justdropped.com: e.g. www.justdropped.com/drops/010112com.html. First known working day:
2006-01-01. Unthrottled. - yoid.com: e.g.: yoid.com/bydate.php?d=2016-06-03&a=a. First known workding day:
2016-06-01.
Data comparison:
- 2012-01-01Looking only at the
.com:The lists are quite similar however.- webmastercn has just about ten extra ones than justdropped, the rest is exactly the same
- justdropped has some extra and some missing from hupo
We've made the following pipelines for hupo.com + webmasterhome.cn merging:
./hupo.sh &
./webmastercn.sh &
./justdropped.sh &
wait
./justdropped-post.sh
./hupo-merge.sh
# Export as small Google indexable files in a Git repository.
./hupo-repo.sh
# Export as per year zips for Internet Archive.
./hupo-zip.sh
# Obtain count statistics:
./hupo-wc.shCount unique domains in the repos:
( echo */*/*/* | xargs cat ) | sort -u | wcThe extracted data is present at:Soon after uploading, these repos started getting some interesting traffic, presumably started by security trackers going "bling bling" on certain malicious domain names in their databases:
- archive.org/details/expired-domain-names-by-day
- github.com/cirosantilli/expired-domain-names-by-day-* repos:
- github.com/cirosantilli/expired-domain-names-by-day-2006
- github.com/cirosantilli/expired-domain-names-by-day-2007
- github.com/cirosantilli/expired-domain-names-by-day-2008
- github.com/cirosantilli/expired-domain-names-by-day-2009
- github.com/cirosantilli/expired-domain-names-by-day-2010
- github.com/cirosantilli/expired-domain-names-by-day-2011 (~11M)
- github.com/cirosantilli/expired-domain-names-by-day-2012 (~18M)
- github.com/cirosantilli/expired-domain-names-by-day-2013 (~28M)
- github.com/cirosantilli/expired-domain-names-by-day-2014 (~29M)
- github.com/cirosantilli/expired-domain-names-by-day-2015 (~28M)
- github.com/cirosantilli/expired-domain-names-by-day-2016
- github.com/cirosantilli/expired-domain-names-by-day-2017
- github.com/cirosantilli/expired-domain-names-by-day-2018
- github.com/cirosantilli/expired-domain-names-by-day-2019
- github.com/cirosantilli/expired-domain-names-by-day-2020
- github.com/cirosantilli/expired-domain-names-by-day-2021
- github.com/cirosantilli/expired-domain-names-by-day-2022
- github.com/cirosantilli/expired-domain-names-by-day-2023
- github.com/cirosantilli/expired-domain-names-by-day-2024
- GitHub trackers:
- admin-monitor.shiyue.com
- anquan.didichuxing.com
- app.cloudsek.com
- app.flare.io
- app.rainforest.tech
- app.shadowmap.com
- bo.serenety.xmco.fr 8 1
- bts.linecorp.com
- burn2give.vercel.app
- cbs.ctm360.com 17 2
- code6.d1m.cn
- code6-ops.juzifenqi.com
- codefend.devops.cndatacom.com
- dlp-code.airudder.com
- easm.atrust.sangfor.com
- ec2-34-248-93-242.eu-west-1.compute.amazonaws.com
- ecall.beygoo.me 2 1
- eos.vip.vip.com 1 1
- foradar.baimaohui.net 2 1
- fty.beygoo.me
- hive.telefonica.com.br 2 1
- hulrud.tistory.com
- kartos.enthec.com
- soc.futuoa.com
- lullar-com-3.appspot.com
- penetration.houtai.io 2 1
- platform.sec.corp.qihoo.net
- plus.k8s.onemt.co 4 1
- pmp.beygoo.me 2 1
- portal.protectorg.com
- qa-boss.amh-group.com
- saicmotor.saas.cubesec.cn
- scan.huoban.com
- sec.welab-inc.com
- security.ctrip.com 10 3
- siem-gs.int.black-unique.com 2 1
- soc-github.daojia-inc.com
- spigotmc.org 2 1
- tcallzgroup.blueliv.com
- tcthreatcompass05.blueliv.com 4 1
- tix.testsite.woa.com 2 1
- toucan.belcy.com 1 1
- turbo.gwmdevops.com 18 2
- urlscan.watcherlab.com
- zelenka.guru. Looks like a Russian hacker forum.
- LinkedIn profile views:
- "Information Security Specialist at Forcepoint"
Check for overlap of the merge:
grep -Fx -f <( jq -r '.[].host' ../media/cia-2010-covert-communication-websites/hits.json ) cia-2010-covert-communication-websites/tmp/merge/*Next, we can start searching by keyword with Wayback Machine CDX scanning with Tor parallelization with out helper ../cia-2010-covert-communication-websites/hupo-cdx-tor.sh, e.g. to check domains that contain the term "news":produces per-year results for the regex term OK lets:
./hupo-cdx-tor.sh mydir 'news|global' 2011 2019news|global between the years under:tmp/hupo-cdx-tor/mydir/2011
tmp/hupo-cdx-tor/mydir/2012./hupo-cdx-tor.sh out 'news|headline|internationali|mondo|mundo|mondi|iran|today'Other searches that are not dense enough for our patience:
world|global|[^.]infoOMG and a few more. It's amazing.
news search might be producing some golden, golden new hits!!! Going full into this. Hits:- thepyramidnews.com
- echessnews.com
- tickettonews.com
- airuafricanews.com
- vuvuzelanews.com
- dayenews.com
- newsupdatesite.com
- arabicnewsonline.com
- arabicnewsunfiltered.com
- newsandsportscentral.com
- networkofnews.com
- trekkingtoday.com
- financial-crisis-news.com
CIA 2010 covert communication websites feedsdemexicoyelmundo.com Updated 2025-07-16
whoisxmlapi WHOIS record on April 28, 2011
There are unlisted articles, also show them or only show them.