
Incoming links: SQL
Cool data embedded in the Bitcoin blockchain etchablock.com Created 2025-03-24 Updated 2025-07-16
etchablock.com was presumably an inscription service that allowed people to pay to have Base58 messages inscribed on the Bitcoin blockchain.
The service failed to gain popularity and not much is known about it. justdropped.com marks the domain as having expired on 2013-02-03.[ref].
The first known mentions of the service date back to December 2011, when it started self-advertizing in the blockchain around tx 8ffacbb18f63576fe323cbf2acc6c4c01c86aadf13d8352cfdd39d91916d98c8 block 156164 (2011-12-05) by repeating the following 3 messages 80 times:decoding to:
11EtchABLockDotComGivesYouXZHcYVz
11BLockChain1mmortaLityXXXXYRZD5m
11VisitEtchABLockDotComNowXTbeZZ9etchablock.com gives you blockchain immortaility. Visit etchablock.com now.
The website was down as of 2021, and there were no decent archives unfortunately: web.archive.org/web/20130301000000*/http://etchablock.com/.
Some surviging online mentions include:
- www.reddit.com/r/Bitcoin/comments/s9cra/comment/c4d5x9b/ Gold, Silver, and Bitcoin spot prices are now only a call (or text) away (2012-04-14) suggests that the creator is a "Jonathan Ryan Owens" since user jonathanryanowens comments:Some profiles:
Aside from Bitcoinduit, which was the first project we worked on for the purpose of investigating the inner workings of the bitcoin network and double spend threats? Ok.. here's a few: We developed custom bitcoin signing agents (etchablock.com), we did the first facebook bitcoin wallet (yougotcoin.com), we have our own custom c++ libraries that completely reimplement bitcoind for our own applications, we have an actual working double spend detection and alerter infrastructure, and also a coming slew of apps related to microlending and fixed exchange services..
- bitcointalk.org/index.php?topic=53752.msg651512#msg651512 says on 2011-12-15:by user TT.
Try etchablock.com!
- dune.com/queries/3857233 has a random looking commented out mention of
etchablock.comon the SQL
Database management system Updated 2025-07-16
Gordon Linoff Updated 2025-07-16
Infinitely many SQL answers.
As mentioned at Ciro Santilli's Stack Overflow contributions, he just answers every semi-duplicate immediatly as it is asked, and is therefore able to overcome the Stack Overflow maximum 200 daily reputation limit by far. E.g. in 2018, Gordon reached 135k (archive), thus almost double the 73k yearly limit due to the 200 daily limit, all of that with accepts.
This is in contrast to Ciro Santilli's contribution style which is to only answer questions as he needs the subject, or generally important questions that aroused his interest.
2014 Blog post describing his activity: blog.data-miners.com/2014/08/an-achievement-on-stack-overflow.html, key quote:so that suggests his contributions also take a meditative value.
For a few months, I sporadically answered questions. Then, in the first week of May, my Mom's younger brother passed away. That meant lots of time hanging around family, planning the funeral, and the like. Answering questions on Stack Overflow turned out to be a good way to get away from things. So, I became more intent.
www.data-miners.com/linoff.htm mentions he's an SQL consultant that consulted for several big companies.
How to decide if an ORM is good? Updated 2025-07-16
How to decide if an ORM is decent? Just try to replicate every SQL query from nodejs/sequelize/raw/many_to_many.js on PostgreSQL and SQLite.
There is only a very finite number of possible reasonable queries on a two table many to many relationship with a join table. A decent ORM has to be able to do them all.
If it can do all those queries, then the ORM can actually do a good subset of SQL and is decent. If not, it can't, and this will make you suffer. E.g. Sequelize v5 is such an ORM that makes you suffer.
The next thing to check are transactions.
Basically, all of those come up if you try to implement a blog hello world world such as gothinkster/realworld correctly, i.e. without unnecessary inefficiencies due to your ORM on top of underlying SQL, and dealing with concurrency.
IBM Updated 2025-07-16
Isolation (database systems) Updated 2025-07-16
Determines what can or cannot happen when multiple queries are running in parallel.
See Section "SQL transaction isolation level" for the most common context under which this is discussed: SQL.
Nested set model Updated 2025-07-16
This is particularly important in SQL: Nested set model in SQL, as it is an efficient way to transverse trees there, since querying parents every time would require multiple disk accesses.
The ASCII art visualizations from stackoverflow.com/questions/192220/what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree/194031#194031 are worth reproducing.
As the sets:
__________________________________________________________________________
| Root 1 |
| ________________________________ ________________________________ |
| | Child 1.1 | | Child 1.2 | |
| | ___________ ___________ | | ___________ ___________ | |
| | | C 1.1.1 | | C 1.1.2 | | | | C 1.2.1 | | C 1.2.2 | | |
1 2 3___________4 5___________6 7 8 9___________10 11__________12 13 14
| |________________________________| |________________________________| |
|__________________________________________________________________________|Consider the following nested set:
0, 8, root
1, 7, mathematics
2, 3, geometry
3, 6, calculus
4, 5, derivative
5, 6, integral
6, 7, algebra
7, 8, physics Nested set model in SQL Updated 2025-07-16
How to implement Nested set model in SQL:
- stackoverflow.com/questions/192220/what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree/42781302#42781302 contains the correct left/size representation and update queries, which makes it much easier to maintain the tree without having to worry about the sizes of siblings which are constant
- stackoverflow.com/questions/192220/what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree/194031#194031 amazing ASCII art representations of the structure. Unfortunately uses a wonky left/right representation, rather than the much more natural left/size representation from the other post
Oracle Corporation Updated 2025-07-16
Evil company that desecrated the beauty created by Sun Microsystems, and was trying to bury Java once and or all in the 2010's.
Their database is already matched by open source e.g. PostgreSQL, and ERP and CRM specific systems are boring.
Oracle basically grew out of selling one of the first SQL implementations in the late 70's, and notably to the United States Government and particularly the CIA. They did deliver a lot of value in those early pre-internet days, but now open source is and will supplant them entirely.
Sequelize raw query Updated 2025-07-16
Exampes under nodejs/sequelize/raw:
- nodejs/sequelize/raw/index.js: Sequelize raw query hello world. Ideally one should never use a raw query in a real project. We use raw examples mostly as a SQL tutorial under SQL example, and will not comment on them much further on this section.
Ciro's Edict #8 List topics on home page Updated 2025-07-16
The new default homepage for a logged out user how shows a list of the topics with the most articles.
This is a reasonable choice for default homepage, and it immediately exposes users to this central feature of the website: the topic system.
Doing this required in particular calculating the best title for a topic, since it is possible to have different titles with the same ID, the most common way being with capitalization changes, e.g.:would both have topic ID
JavaScript
Javascriptjavascript.The algorithm chosen is to pick the top 10 most upvoted topics, and select the most common title from amongst them. This should make topic title vandalism quite hard. This was made in a single SQL query, and became the most complext SQL query Ciro Santilli has ever written so far: twitter.com/cirosantilli2/status/1549721815832043522
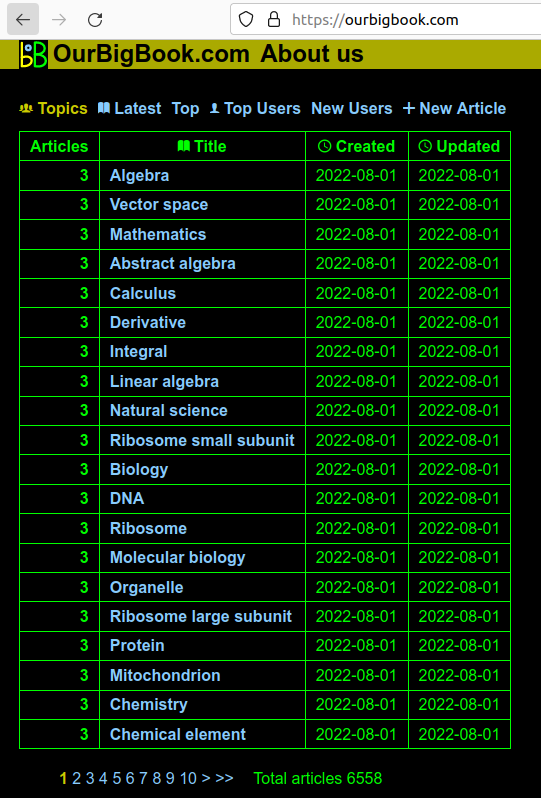
Screenshot showing the list of topics
. The page is: ourbigbook.com for the logged out user, ourbigbook.com/go/topics for the logged in user.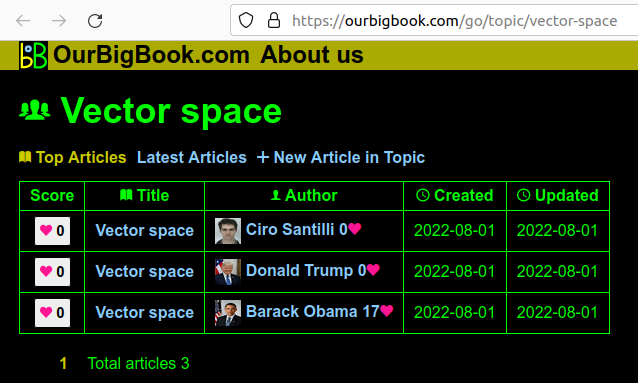
Screenshot showing a topic page
. The page is: ourbigbook.com/go/topic/vector-space. Before this sprint, we didn't have the "Vector Space" at the top, as it wasn't necessarily trivial to determine what the preferred title would be. SQL example Updated 2025-07-16
Sequelize is used minimally, just to feed raw queries in transparently to any underlying database, and get minimally parsed results out for us, which we then assert with standard JavaScript. The queries themselves are all written by hand.
By default the examples run on SQLite. Just like the examples from sequelize example, you can set the database at runtime as:
./index.jsor./index.js l: SQLite./index.js p: PostgreSQL. You must manually create a database calledtmpand ensure that peer authentication works for it
Here we list only examples which we believe are standard SQL, and should therefore work across different SQL implementations:
- nodejs/sequelize/raw/index.js: basic hello world to demonstrate the setup and very simple functionality
- nodejs/sequelize/raw/many_to_many.js: illustrates many-to-many relations with JOIN. Contains:
- SQL transaction examples:
- nodejs/sequelize/raw/commit_error.js: stackoverflow.com/questions/27245101/why-should-we-use-rollback-in-sql-explicitly/27245234#27245234 and stackoverflow.com/questions/48277519/how-to-use-commit-and-rollback-in-a-postgresql-function/48277708#48277708 suggest that on PostgreSQL, once something fails inside a transaction, all queries in the current transaction are ignored, and
COMMITsimply does aROLLBACK. Let's check. Yup, true for Postgres, but false for SQLite, SQLite just happily runs anything it can, you really needROLLBACKfor it. - SQL isolation level example
- nodejs/sequelize/raw/commit_error.js: stackoverflow.com/questions/27245101/why-should-we-use-rollback-in-sql-explicitly/27245234#27245234 and stackoverflow.com/questions/48277519/how-to-use-commit-and-rollback-in-a-postgresql-function/48277708#48277708 suggest that on PostgreSQL, once something fails inside a transaction, all queries in the current transaction are ignored, and
- GROUP BY and SQL aggregate functions:
- nodejs/sequelize/raw/group_by_extra_column.js: let's see if it blows up or not on different DB systems,
sqlite3Node.js package allows it:- github.com/sequelize/sequelize/issues/5481#issuecomment-964387232
- dba.stackexchange.com/questions/141594/how-select-column-does-not-list-in-group-by-clause/141600 says that it was allowed in SQL:1999 when there are no ambiguities due to constraints, e.g. when grouping by unique columns
- github.com/postgres/postgres/blob/REL_13_5/src/test/regress/sql/functional_deps.sql#L27 shows that PostgreSQL wants it to work for
UNIQUE NOT NULL, but they just haven't implemented it as of 13.5, where it only works if you group byPRIMARY KEY - dba.stackexchange.com/questions/158015/why-can-i-select-all-fields-when-grouping-by-primary-key-but-not-when-grouping-b also says that
UNIQUE NOT NULLdoesn't work. Dan Lenski then points to a rationale mailing list thread.
- nodejs/sequelize/raw/group_by_max_full_row.js: here we try to get the full row of each group at which a given column reaches the max of the group
- Postgres: has
SELECT DISCINTCT ONwhich works perfectly if you only want one row in case of multiple rows attaining the max.ONis an extension to the standard unfortunately: www.postgresql.org/docs/9.3/sql-select.html#SQL-DISTINCT Docs specify that it always respectsORDER BYwhen selecting the row.- stackoverflow.com/questions/586781/postgresql-fetch-the-row-which-has-the-max-value-for-a-column asks it without the multiple matches use case
- stackoverflow.com/questions/586781/postgresql-fetch-the-rows-which-have-the-max-value-for-a-column-in-each-group/587209#587209 also present in simpler form at stackoverflow.com/questions/121387/fetch-the-rows-which-have-the-max-value-for-a-column-for-each-distinct-value-of/123481#123481 gives a very nice OUTER JOIN only solution! Incredible, very elegant.
- dba.stackexchange.com/questions/171938/get-only-rows-with-max-group-value asks specifically the case of multiple matches to the max
- stackoverflow.com/questions/586781/postgresql-fetch-the-row-which-has-the-max-value-for-a-column asks it without the multiple matches use case
- SQLite:
- stackoverflow.com/questions/48326957/row-with-max-value-per-group-sqlite
- stackoverflow.com/questions/48326957/row-with-max-value-per-group-sqlite/48328243#48328243 teaches us that in SQLite min and max are magic and guarantee that the matching row is returned
- stackoverflow.com/questions/48326957/row-with-max-value-per-group-sqlite/72996649#72996649 Ciro Santilli uses the magic of
ROW_NUMBER
- stackoverflow.com/questions/17277152/sqlite-select-distinct-of-one-column-and-get-the-others/71924314#71924314 get any full row without specifying which, we teach how to specify
- code.djangoproject.com/ticket/22696 WONTFIXed
DISTINCT ON- stackoverflow.com/questions/50846722/what-is-the-difference-between-postgres-distinct-vs-distinct-on/72997494#72997494
DISTINCTvsDISTINCT ON, somewhat related question
- stackoverflow.com/questions/50846722/what-is-the-difference-between-postgres-distinct-vs-distinct-on/72997494#72997494
- stackoverflow.com/questions/48326957/row-with-max-value-per-group-sqlite
- stackoverflow.com/questions/5803032/group-by-to-return-entire-row asks how to take the top N with distinct after order limit. I don't know how to do it in Postgres
- Postgres: has
- nodejs/sequelize/raw/most_frequent.js: illustrates a few variants of findind the mode, including across GROUP
- nodejs/sequelize/raw/group_by_max_n.js: get the top N in each group
- nodejs/sequelize/raw/group_by_extra_column.js: let's see if it blows up or not on different DB systems,
- order results in the same order as
IN: - LIMIT by a running total: TODO links
SQL TRIGGER Updated 2025-07-16
In particular, everything that happens in a trigger happens as if it were in a transaction. This way, you can do less explicit transactions when you use triggers. It is a bit like the advantages of SQL CASCADE.
DBMS:
Stack Exchange Data Explorer Created 2024-12-13 Updated 2025-07-16
Long story short, the project is so far a complete failure on the most important metric: number of regular users, which current sits at exactly one: myself.
There were notable users who found the project online and who actually tried to use the website for some content and provided extremely valuable feedback:Unfortunately after the period of a few weeks they stopped using it to follow their other priorities instead. Which is of course totally fine, however sad.
I still believe that the OurBigBook Web feature is a significant tech innovation that could make the website go big.
I also believe that the project gets many fundamentals of braindumping right, notably the infinitely deep table of contents without forced scoping, e.g.:does not make Calculus have an ID orr URL of
- Mathematics
- Calculusmathematics/calculus, rather it's just calculus.But there is a fundamental difficulty in reaching critical mass to that self-sustaining point, as people don't seem to be convinced by these logical "my system is better" argument alone, as opposed to having them Google into stuff they need now and then understand that the project is awesome.
A closely related critical mass issue is that existing big multiuser knowledge base websites such as Stack Overflow and Wikipedia have a tremendous advantage on PageRank. No matter how useless a Wikipedia article about something is, it will always be on top of Google within a week of creation for title hits. And since the main goal of publishing your stuff is to get it seen, it makes much more sense for writers to publish on such existing websites whenever possible, because anywhere else it is way way less likely to be seen by anybody.
Even I end up writing way more on Stack Overflow than on OurBigBook as a programmer. But I still believe that there is a value to OurBigBook, for the usual reasons of:
Perhaps what saddens me the most is that even on GitHub stars/Twitter/Hacker news terms there is almost no interest in the project despite the fact that I consider that it has innovations, while many other note taking apps as well in the thousands of stars. Maybe I'm just delusional and all the tech that I'm doing is completely useless?
Part of the issue is probably linked to the fact that most other note taking apps focus on "help me organize my ideas so I can make more money" and often completely ignore "I want to publish my knowledge", and stuff that helps you make money is always easier to sell and promote.
OurBigBook on the other hand a huge focus on "I want to publish me knowledge". It aims almost single mindedly in being the best tool ever for that. However this doesn't make money for people, and therefore there are going to be way less potential users.
I do believe strongly that all it takes is a few users for the project to snowball. For some people, once you start braindumping, it is very addictive, and you never want to stop basically. So with only a few of those we can open large parts of undergrad knowledge to the world. But these people are few, and so far I haven't been able to find even a single one like me, and on top of that convince them that I have created the ultimate system for their knowledge publishing desires.
Another general lesson is that I should perhaps aimed for greater compatibility with existing systems such as Obsidian. Taking something that many people already know and use can have a huge impact on acceptance. E.g. anything that touches Obsidian can reach thousands of stars: github.com/KosmosisDire/obsidian-webpage-export. Note taking apps that aim for "markdown" compatibility also tend to fare better, even if in the end you inevitably have to extend the Markdown for some of your features. And WYSIWYG, which I want but don't have, is perhaps the ultimate familiarity.
Another issue compared to other platforms is that OurBigBook just came out late. Obsidian launched in 2020. Roam Research and Trillium Notes also came earlier. And it is hard to fight the advantage already gained by those on the "I'm going to take some personal notes" area. I do believe however that there a strong separation between "these are my personal notes" and "I want to publish these". Once you decide to publish your knowledge, you immediately start to write in a different way, and it is very hard to convert pre-existing "private" notes into ones suitable for public consumption.