
Ciro Santilli's hardware Skullcandy Smokin' Buds 2 Updated 2025-07-16
2023-07: one of the sides broke near center, rebuying.
2021-07: wire half broke near connector, only works in some positions. The funny thing is: only voices seem to be blocked out! Rebuying.
2021-06: a small bottom piece of the left earpiece broke. Wire seems find, that is like a little extension to protect wire. Let's see for how long.
2020-20: wires at one of ears broke, not sure how.
Look they looked exactly like: "Skullcandy Smokin' Buds 2 In-Ear Audio Earbud Headphones with In-Line Microphone - Black".
Re-buying that one 10 pounds:
Tech specs:
Connection Type: 3.5mm AUX CableImpedence: 32 ohmsDriver Diameter: 9mmSound Pressure Level: 95 dB (1mW/500Hz)Frequency Response: 20kHz - 20HzHeadphone Type: In-Ear
Ciro Santilli's hardware Tefal rice cooker (2017) Updated 2025-07-16
Bought around: 2017-09.
TEFAL Multicook 8in1 RK302E15 MultiCooker - 4 Portions / 5L.
Likely bought from: www.johnlewis.com/tefal-rk302e15-8-in-1-multi-cooker/p231378165
How to open videos: can't find any, but the hard part (remove top lid) was the same as the video for joyoung rice cooker (2014), can be done by inserting a thin metal and going around it.
Bottom opens by taking off a single screw on the bottom and pulling it out (not obvious, a little bit of force).
2021-01: while making congee it overflowed without us noticing it, and next time we were going to cook something, it started to burn bits of congee that stuck to the heat plate. Opened it up and tried to clean everything.
2020-03: E01 error, looked up on manual and it is a top wire broken, opened up and confirmed one of the three wires going up broken, exactly like the previous one joyoung rice cooker (2014). Managed to fix easily with heat gun and Solder Seal Heat Shrink, no soldering iron, that thing is amazing: www.amazon.co.uk/dp/B085415G8N Let's see how long it lasts.
Ciro Santilli's hardware Toshiba MK1059GSM Updated 2025-07-16
Ciro Santilli's hardware TP Link ARCHER VR2800 Updated 2025-07-16
Manual: www.tp-link.com/uk/support/download/archer-vr2800/ In particular, the user guide: static.tp-link.com/1910012125_Archer%20VR2800(EU)_V1_UG.pdf
Admin IP address: 192.168.1.1/ It also works over Wifi and people don't know how to disable that: community.tp-link.com/en/home/forum/topic/1460
Ciro Santilli's hardware WD10EADS-42P6B0 Updated 2025-07-16
Ciro Santilli's hardware WD Elements 20TB Updated 2025-07-16
Bought December 2023 for 300 pounds, so 15 pounds / TB. Needs power supply unfrotunately besides USB, the largest one without needing power supply was only 5 TB at the time so not worth it, given that my P14s alreay carriers 2 TB. 10x is a must for the external crap.
www.westerndigital.com/en-gb/products/external-drives/wd-elements-desktop-usb-3-0-hdd?sku=WDBWLG0030HBK-EESN (archive)
Noise: it has a constant pleasant hum, with a not so nice click every 5 seconds or so. Reasonable, but not amazingly incredible.
The size is reasonable, not megaportable, but definitely reasonable.
Ciro Santilli's hardware Yamaha P-45B digital piano Updated 2025-07-26
Likely came in a bundle: www.gak.co.uk/en/yamaha-p45-digital-piano-bundle/908294
Ciro Santilli's homonyms Updated 2025-07-16
If any of you ever read this, do send me an email to Ciro Santilli saying hi and we can agree on a clear separation of usernames.
Although if you are just starting out, maybe you should just go from scratch with a unique Internet alias.
A younger unrelated Argentinian homonym who likes soccer that can be found through Google:Ciro used to like playing soccer too! :-)
- twitter.com/ciro_santilli
- www.facebook.com/profile.php?id=100009065024069
- www.instagram.com/ciro.santilli/ contains a few cool-sexy-boy-selfies as of 2025 when he hit that stage
- www.youtube.com/@cirosantilli9603
- www.linkedin.com/in/ciro-santilli-bb77b72b7
www.ancestry.com.au/genealogy/records/ciro-santilli-24-bkmssg documents a "Ciro Santilli" born 31 Jan 1887 at Castelvécchio in Subéquo, L'Aquila, in the Abruzzo region, just like Ciro Santilli's ancestors. Parents Francesco Santilli and Anna Silveri. The page also mentions:
- Ciro Santilli found in New York, Passenger and Crew Lists (including Castle Garden and Ellis Island), 1820-1957
- Ciro Santilli found in Oregon, Naturalization Records 1865-1991
Ciro Santilli's ideal city to live in Updated 2025-07-16
Ciro's ideal city to live in contains the following in order of decreasing importance:
- high tech
- beach and warm weather, influenced by Ciro's love for the City of Santos where he once lived
- enough recent Chinese immigrants to sustain Chinese cuisine
Ciro Santilli's knee Updated 2025-07-16
If Achilles' had his heel, Ciro had his knee.
First during University in Brazil while trying a kick up during the development of Cirodance his knee went a bit weird for a few weeks.
Then, just after arriving in France for École Polytechnique, the boys were playing indoor soccer, and to impress the girls Ciro was playing really hard, even took off his shirt, and suddenly when he was running by himself his knee snapped, he fell and it hurt like hell.
Ciro was on crutches for a few weeks, but the inflammation went away, but then he tried to play more soccer, but the knee was not as stable as before, and once he tried to run full speed, it slipped and hurt him a bit more (less severely) and so he gave up. For some reason it was not visible on the tomography made at the hospital.
Maybe Ciro should have investigated more though, certainly an experienced doctor could have done a hand pressure exam to determine which joint was damaged manually even. That was a medical failure.
So from this day on Ciro gave up on all interesting sports, and confined himself to more repetitive stuff like gym weights and cycling: Section "Ciro Santilli's sport practice". At Polytechnique he was forced to take up swimming as his mandatory sport, that was unbearably boring.
This defect is likely genetic since a close relative had similar problems.
But oh well, his then not-even girlfriend was impressed enough by the soccer or sorry enough for the sucker to marry him, so it worked out.
Classical limit Updated 2025-07-16
The idea tha taking the limit of the non-classical theories for certain parameters (relativity and quantum mechanics) should lead to the classical theory.
It appears that classical limit is only very strict for relativity. For quantum mechanics it is much more hand-wavy thing. See also: Subtle is the Lord by Abraham Pais (1982) page 55.
Classical mechanics Updated 2025-07-16
Ciro Santilli's knowledge hoarding Updated 2025-07-16
His uncle, which Ciro rassembles in many ways, was like that. But he collected physical objects such as wines and stamps. Or even worse, objects that were meant to be collected such Panini soccer sticker albums! This Ciro looks down on.
With computers, knowledge takes no physical space and can be immediately shared with the hole world, and there is great beauty to that, as you can just keep collecting forever without filling up your house.
But of course, physical or not, all attachments futile.
Like other types collecting, once Ciro decides that "he must know everything about a given subject", he will keep coming back to that subject over and over. Not in a systematic way of course, since Ciro is a lazy bastard, but he will keep coming back for a very long time, and eventually become an expert at it.
This compulsive hoarding, together with Ciro Santilli's bad old event memory, are the fundamental reasons for OurBigBook.com.
Ciro Santilli's legs sometimes itch when he runs Updated 2025-07-16
Ciro Santilli has an undiagnozed condition where his upper legs and lower torso often start to itch when he runs, to the point of being extremely annoying and removing all pleasure form the activity.
If some doctor knows why this could be, please tell him!!!
The problem is a bit hard to reproduce however, and Ciro hasn't been able to determine which exact condition triggers it: temperature, nutrition, something else?
Ciro believes that this is not chiefly due to transpiration, but rather to the impact motion that running does on the muscles, as he has felt something similar on his arms some times while cycling in very rough terrain, which made his arms shake in a similar fashion. or for example if he has a water bottle on a tightly tied backpack that rubs his back, then the back itches at that point.
Also, running on a threadmill is not a problem at all. Ciro believes that this is because the threadmill is better amortized, and therefore does not cause the same mechanical stress required to create the itching as running on pavement.
Interestingly, Ciro didn't feel that at all when he played soccer enthusiastically as a child, and he was one of the fastest runners of the group for sure at that time. So he's not sure if it started when he got older, or if it is just because the difference in workloads between soccer and running.
youtu.be/PNgYW5N95z8?t=945 "My back itches" after riding on a bumpy makeshift motorcycle.
Ciro Santilli's love advice Updated 2025-07-16
In the field of Love and Friendship, Ciro is a big believer in the merciless application of tit for tat. Never desire someone's love if you give and what comes back is not proportional. Cut your attempts to reach out immediately in such cases.
Never tell a woman you like her before she is in your bed.
If someone likes you and you don't like them as much, make that clear to them. Don't put this off, be it for compassion, curiosity, loneliness, or narcissism.
youtu.be/Sb0VHGnhX4M?t=174 from Video "Charles Bukowski Scandanavian TV interviews":
The way to get a woman is not to have money, not to look nice, not to have a nice personality. The way to get a woman, is to always be available, night or day. Any time you phone, you're there, or you're at the bar. They know that you are available at all times. It is very, very important to a woman.
See also: Section "Ciro Santilli's wife".
Ciro Santilli's mother-in-law Updated 2025-07-16
The old lady was arrested in 2015 for a few days for doing Falun Gong, which was an important motivation to Ciro Santilli's campaign for freedom of speech in China.

Ciro Santilli's natural languages skills Updated 2025-07-16
- English: Cambridge CPE grade B in 2004. Proficient, with minor defects in collocation/pronunciation. Learned from formal courses and from living in the UK for a few months when he was 10.
- French: TCF grade C2 in 2011. Proficient, with a bit more defects than English. Studied and lived in France.
- Brazilian Portuguese: Native speaker
- Chinese: see github.com/cirosantilli/china-dictatorship/tree/df0852b22e585785d734ec69719eddf63f9676a5#do-you-speak-chinese
Ciro Santilli's undergrad studies at the University of São Paulo Updated 2025-07-16
Ciro's official diploma from the University of São Paulo read "Automation and Control Engineer at the Polytechnic School of the University of São Paulo".
The University of São Paulo had been elected the best South American university in the Times Ranking 2013 (archive) in all subjects.
Ciro finished the course with honors of "The Best Student in Automation and Control of the year 2013".
Ciro didn´t learn basically any control engineering however unfortunately. He did only the 3 base years of the electrical engineering course, and the rest got lost on stupid politics of having to go back to do 6 months from France to validate his Brazilian degree, see also: Section "Don't force international exchange students to come back early".
Ciro Santilli's naughty projects Updated 2025-07-16
If Ciro Santilli weren't a natural born activist, he chould have made an excellent intelligence analyst! See also: Section "Being naughty and creative are correlated".
- Stack Overflow Vote Fraud Script
- GitHub makes Ciro feel especially naughty:
- All GitHub Commit Emails: he extracted (almost) all Git commit emails from GitHub with Google BigQuery
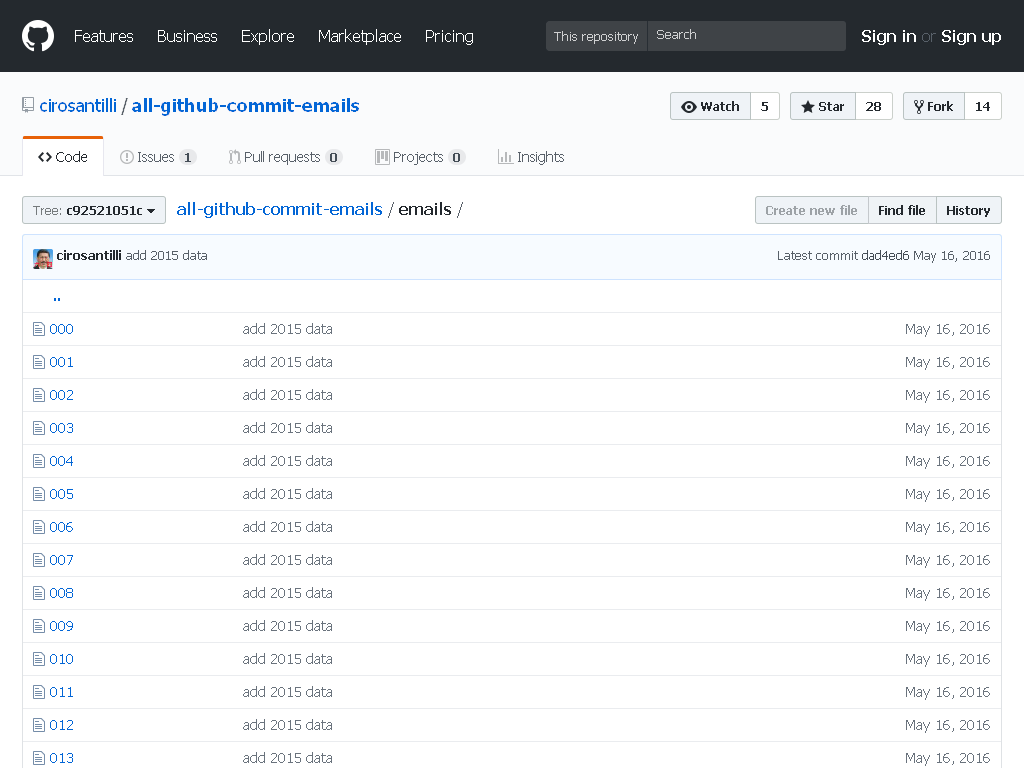
Figure 1. All GitHub Commit Emails repo before takedown. Screenshot from archive.is. - A repository with 1 million commits: likely the live repo with the most commits as of 2017
- An 100 year GitHub streak, likely longest ever when that existed. It was consuming too much server resources however, which led to GitHub admins manually turning off his contribution history.
- 500 on adoc infinite header xref recursion: that was fun while it lasted

Ciro Santilli's open source contributions Merged by Ciro Updated 2025-07-16
Patches which were merged by Ciro himself on repositories which eh feels have large public visibility, e.g. those to which he has been given push permission.
Repositories to which Ciro gained push permission because of his contributions:
There are unlisted articles, also show them or only show them.