As the name suggests, this is not very sturdy, and was quickly replaced by bipolar junction transistor.
- 1: Jim Prideaux captured. Some ex-colleague invites Smiley to dinner and keeps asking how incompetent people like Alleline climbed to the top of the Circus. Smiley recalled to service to meet Ricki Tarr.
- 2: Ricki Tarr tells his story to Smiley. Peter Guillam starts stealing material from the Circus, find missing page on the communication officer list. Smiley sets up his investigation operation.
- 3: Smiley meets Connie who tells that she was fired for suspecting Poliakov. Flashbacks show the ousting of Control and Smiley.
- 4: Guillam steals more material from the circus. While doing that, he is called by the top officers to inquire about Ricki Tarr being in England, which they suspect because they discovered that his family has come.
- 5: Jim Prideaux tells his story to Smiley, who cannot easily access the Circus reports about it. When he is returned to England, there was basically no debriefing, and Esterhase already knew about the Tinker Tailor codenames, presumably through Merlin.
- 6: Smiley hears the story of yet another ousted man, who heard the Russians knew in advance about Jim Prideaux' coming. Toby Esterhase dismissed him for alcoholism.
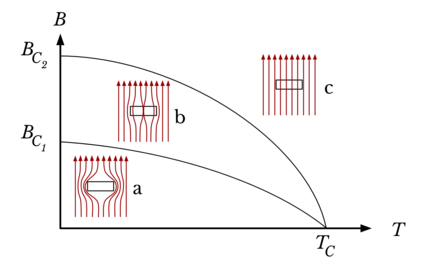
Appears to be an unsolved physics problem. TODO why? Don't they all fit into the Standard Model already? So why is strong force less unified with electroweak, than electromagnetic + weak is unified in electroweak?
The Eighth Day of Creation has a related quote:
In a conversation a few weeks earlier at the faculty club of the Massachusetts Institute of Technology, a couple of biologists had speculated whether Pauling, whose recent popular book on the benefits to health and sanity of massive doses of vitamin C was stacked in display near the entrance of the M.I.T. bookstore, was showing signs of what one of the men called "old scientist's disease" - which they defined as what happens to great men when they grow beyond the psychological reach of the salutary system by which scientists blow the whistle on one another's mistakes.
The Nobel Prize Winners With Crazy Theories by Qxir
. Source. Gilberto is definitely the most psychedelic/tribal one of the The Holy Trinity of popular Brazilian music, though he also has a boyish quality to his soul.
He is also perhaps the one that impresses Ciro Santilli the most, at times he can't help but feel:
OMG how the hell did he come up with that?!


Gilberto Gil in the cover of his 1977 album Refavela
. Source. Ciro's word of caution for 2019 aspiring system programmers: Should you waste your life with systems programming?
This is basically a direct consequence of backward design.
The higher the level you can operate at, the better.
The ideal level to operate at, and one of humankind's greatest ambitions is "AGI, make me money", the highest possible level.
Only go down a level when it seems necessary.
{kind=link}
The opposite of quasiparticle, see notaby: quasiparticles vs elementary particles.
These are some users Ciro Santilli particularly respects, mostly due to their contributions to systems programming subjects:
- unix.stackexchange.com/users/885/gilles-so-stop-being-evil
- stackoverflow.com/users/379897/r-github-stop-helping-icea
- stackoverflow.com/users/196561/osgx
- stackoverflow.com/users/50617/employed-russian Employed Russian. Binutils, ELF, GDB, claims to work at Google. The only Russian sounding name on GDB and Binutils git log is that of Paul Pluzhnikov: www.linkedin.com/in/paul-pluzhnikov-61b9676/ and Employed Russian mentions one of his commits at: stackoverflow.com/questions/3718072/gdb-takes-too-long-and-ctrl-c-has-no-effect Ex physicist: www.researchgate.net/profile/Paul_Pluzhnikov
Ciro also really likes the following users, a bit less like Gods, and bit more like friends:
- partly because they were close by on the yearly reputation charts for a long time circa 2020, so it feels like they also focus on replying to important questions rather than answering new duplicates immediately:
- stackoverflow.com/users/642706/basil-bourque: GCC dev, but started replying lots of Java questions as of 2021 it seems for some reason
- stackoverflow.com/users/541136/aaron-hall: Python, NixOS and Haskell more and more it seems. Also pro freedom of speech, gotta love those religious liberal Republicans. Reminds Ciro of Ron Maimon very slightly, maybe it's just the New Yorkedneess. Ciro once met another intelligent dude who liked both Haskell and NixOS, there must be some correlation.
- VonC: Git God, VonC is just Super nice, gives clear credit to others, always positive interactions. Love this dude. He was the one that held the Necromancer record in 2019 before Ciro took it.
- Peter Cordes. An assembly maniac this one. And a really nice one too. Sometimes pedantic, but always nice, and always correct. He's been going into God level more and more it must be said:In 2024 VonC was found to have been used LLMs to generate part of his answers, and later publicly apologized: meta.stackoverflow.com/questions/430072/a-commitment-to-amend-and-move-forward It is not clear why he had used them though. He remained user #1 in 2025 however, even despite not using them anymore as far as it is known.
Other interesting people:
- stackoverflow.com/users/560648/lightness-races-in-orbit Lightness Races in Orbit. C++ God. Interesting aesthetics. Real name: Tom Lachecki, British, as per:As of 2023 marked "retired" from Stack Overflow, rep graph suggests since 2020.
- stackoverflow.com/users/3681880/suragch the number 3 necromancer dude. But then in 2022 he found God and mostly quit: suragch.medium.com/programming-was-my-god-89b625164a69
- www.reddit.com/r/webdev/comments/1ealv82/the_fall_of_stack_overflow/ The Fall of Stack Overflow
Ciro's Edict #5 Link to an image or video in another file that has an  Ciro Santilli 40 Updated 2025-07-16
Ciro Santilli 40 Updated 2025-07-16
\x on title from another file by Ciro Santilli 40 Updated 2025-07-16Issue report at: github.com/ourbigbook/ourbigbook/issues/198 Suppose you had:
programming-language.ciro
= Programming language
\Image[https://raw.githubusercontent.com/cirosantilli/media/master/python-logo.jpg]
{title=The \x[python-programming-language] logo}
== Python
{c}
{disambiguate=programming-language}= Logos I like
\x[image-the-python-logo]Now, when rendering
\x[image-the-python-logo], we would need to fetch two IDs:image-the-python-logofor theTheandlogopartpython-programming-languageitself, to know that\x[python-programming-language]should render asPython
But after group all SQL queries together was done, there was no way to know that rendering
image-the-python-logo would imply also fetching python-programming-language.This was solved by adding a new database entry type,
REFS_TABLE_X_TITLE_TITLE to the existing References table, which tracks dependencies between IDs. There are unlisted articles, also show them or only show them.