
CIA 2010 covert communication websites How did Alexa find the domains? Updated 2025-07-16
It can't be HTML crawl because presumably there wouldn't have been links to those websites? Presumably this is why Common Crawl doesn't seem to have any hits.
The same question also applies to the 2013 DNS Census. It has less hits, but still has many.
Whatever they did, we are so so glad that they did!
CIA 2010 covert communication websites Internet Census 2012 Updated 2025-07-16
Does not appear to have any reverse IP hits unfortunately: opendata.stackexchange.com/questions/1951/dataset-of-domain-names/21077#21077. Likely only has domains that were explicitly advertised.
We could not find anything useful in it so far, but there is great potential to use this tool to find new IP ranges based on properties of existing IP ranges. Part of the problem is that the dataset is huge, and is split by top 256 bytes. But it would be reasonable to at least explore ranges with pre-existing known hits...
We have started looking for patterns on
66.* and 208.*, both selected as two relatively far away ranges that have a number of pre-existing hits. 208 should likely have been 212 considering later finds that put several ranges in 212.tcpip_fp:
- 66.104.
- 66.104.175.41: grubbersworldrugbynews.com: 1346397300 SCAN(V=6.01%E=4%D=1/12%OT=22%CT=443%CU=%PV=N%G=N%TM=387CAB9E%P=mipsel-openwrt-linux-gnu),ECN(R=N),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=N),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.48: worlddispatch.net: 1346816700 SCAN(V=6.01%E=4%D=1/2%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=1D5EA%P=mipsel-openwrt-linux-gnu),SEQ(SP=F8%GCD=3%ISR=109%TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.49: webworldsports.com: 1346692500 SCAN(V=6.01%E=4%D=9/3%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=5044E96E%P=mipsel-openwrt-linux-gnu),SEQ(SP=105%GCD=1%ISR=108%TI=Z%TS=A),OPS(O1=M550ST11NW6%O2=M550ST11NW6%O3=M550NNT11NW6%O4=M550ST11NW6%O5=M550ST11NW6%O6=M550ST11),WIN(W1=1510%W2=1510%W3=1510%W4=1510%W5=1510%W6=1510),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.50: fly-bybirdies.com: 1346822100 SCAN(V=6.01%E=4%D=1/1%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=14655%P=mipsel-openwrt-linux-gnu),SEQ(TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.104.175.53: info-ology.net: 1346712300 SCAN(V=6.01%E=4%D=9/4%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=50453230%P=mipsel-openwrt-linux-gnu),SEQ(SP=FB%GCD=1%ISR=FF%TI=Z%TS=A),ECN(R=N),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.175.106
- 66.175.106.150: noticiasmusica.net: 1340077500 SCAN(V=5.51%D=1/3%OT=22%CT=443%CU=%PV=N%G=N%TM=38707542%P=mipsel-openwrt-linux-gnu),ECN(R=N),T1(R=N),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
- 66.175.106.155: atomworldnews.com: 1345562100 SCAN(V=5.51%D=8/21%OT=22%CT=443%CU=%PV=N%DC=I%G=N%TM=5033A5F2%P=mips-openwrt-linux-gnu),SEQ(SP=FB%GCD=1%ISR=FC%TI=Z%TS=A),ECN(R=Y%DF=Y%TG=40%W=1540%O=M550NNSNW6%CC=N%Q=),T1(R=Y%DF=Y%TG=40%S=O%A=S+%F=AS%RD=0%Q=),T2(R=N),T3(R=N),T4(R=N),T5(R=Y%DF=Y%TG=40%W=0%S=Z%A=S+%F=AR%O=%RD=0%Q=),T6(R=N),T7(R=N),U1(R=N),IE(R=N)
CIA 2010 covert communication websites ipinf.ru Updated 2025-07-16
alljohnny.com had a hit: ipinf.ru/domains/alljohnny.com/, and so Ciro started looking around... and a good number of other things have hits.Not all of them, definitely less data than viewdns.info.
But they do reverse IP, and they show which nearby reverse IPs have hits on the same page, for free, which is great!
Shame their ordering is purely alphabetical, doesn't properly order the IPs so it is a bit of a pain, but we can handle it.
OMG, Russians!!!
CIA 2010 covert communication websites Wayback Machine CDX scanning with Tor parallelization Updated 2025-07-16
Dire times require dire methods: ../cia-2010-covert-communication-websites/cdx-tor.sh.
First we must start the tor servers with the and then use it on a newline separated domain name list to check;This creates a directory
tor-army command from: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983tor-army 100./cdx-tor.sh infile.txtinfile.txt.cdx/ containing:infile.txt.cdx/out00,out01, etc.: the suspected CDX lines from domains from each tor instance based on the simple criteria that the CDX can handle directly. We split the input domains into 100 piles, and give one selected pile per tor instance.infile.txt.cdx/out: the final combined CDX output ofout00,out01, ...infile.txt.cdx/out.post: the final output containing only domain names that match further CLI criteria that cannot be easily encoded on the CDX query. This is the cleanest domain name list you should look into at the end basically.
Since archive is so abysmal in its data access, e.g. a Google BigQuery would solve our issues in seconds, we have to come up with creative ways of getting around their IP throttling.
Distilled into an answer at: stackoverflow.com/questions/14321214/how-to-run-multiple-tor-processes-at-once-with-different-exit-ips/76749983#76749983
This should allow a full sweep of the 4.5M records in 2013 DNS Census virtual host cleanup in a reasonable amount of time. After JAR/SWF/CGI filtering we obtained 5.8k domains, so a reduction factor of about 1 million with likely very few losses. Not bad.
5.8k is still a bit annoying to fully go over however, so we can also try to count CDX hits to the domains and remove anything with too many hits, since the CIA websites basically have very few archives:This gives us something like:sorted by increasing hit counts, so we can go down as far as patience allows for!
cd 2013-dns-census-a-novirt-domains.txt.cdx
./cdx-tor.sh -d out.post domain-list.txt
cd out.post.cdx
cut -d' ' -f1 out | uniq -c | sort -k1 -n | awk 'match($2, /([^,]+),([^)]+)/, a) {printf("%s.%s %d\n", a[2], a[1], $1)}' > out.count12654montana.com 1
aeronet-news.com 1
atohms.com 1
av3net.com 1
beechstreetas400.com 1 CIA 2010 covert communication websites iraniangoals.com Updated 2025-07-16
whoisxmlapi WHOIS history April 11, 2011:Folowed by reuters registration in 2022.
- Created Date: March 6, 2008 00:00:00 UTC
- Updated Date: March 7, 2011 00:00:00 UTC
- Expires Date: March 6, 2014 00:00:00 UTC
- Registrant Name: domainsbyproxy.com.
- Registrant Organization: Domains by Proxy, Inc.
- Registrant Street: 15111 N. Hayden Rd., Ste 160,
- Registrant City: Scottsdale
- Registrant State/Province: Arizona
- Registrant Postal Code: 85260
- Registrant Country: UNITED STATES
- Name servers: NS29.WORLDNIC.COM|NS30.WORLDNIC.COM
whoisrequest.com/history/ mentions:
- 1 Apr, 2008: Domain created*, nameservers added. Nameservers:
- ns1.webhostingpad.com
- ns2.webhostingpad.com
CIA 2010 covert communication websites iraniangoals.com JavaScript reverse engineering Updated 2025-07-16
Some reverse engineering was done at: twitter.com/hackerfantastic/status/1575505438111571969?lang=en.
Notably, the password is hardcoded and its hash is stored in the JavaScript itself. The result is then submitted back via a POST request to
/cgi-bin/goal.cgi.TODO: how is the SHA calculated? Appears to be manual.
CIA 2010 covert communication websites JavaScript reverse engineering Updated 2025-07-16
CIA 2010 covert communication websites JavaScript with SHAs Updated 2025-07-16
There are two types of JavaScript found so far. The ones with SHA and the ones without. There are only 2 examples of JS with SHA:Both files start with precisely the same string:
- iraniangoals.com: web.archive.org/web/20110202091909/http://iraniangoals.com/journal.js Commented at: iraniangoals.com JavaScript reverse engineering
- iranfootballsource.com: web.archive.org/web/20110202091901/http://iranfootballsource.com/futbol.js
- kukrinews.com: web.archive.org/web/20100513094909/http://kukrinews.com/news.js
- todaysnewsandweather-ru.com: web.archive.org/web/20110207094735/http://todaysnewsandweather-ru.com/blacksea.js
var ms="\u062F\u0631\u064A\u0627\u0641\u062A\u06CC",lc="\u062A\u0647\u064A\u0647 \u0645\u062A\u0646",mn="\u0628\u0631\u062F\u0627\u0632\u0634 \u062F\u0631 \u062C\u0631\u064A\u0627\u0646 \u0627\u0633\u062A...\u0644\u0637\u0641\u0627 \u0635\u0628\u0631 \u0643\u0646\u064A\u062F",lt="\u062A\u0647\u064A\u0647 \u0645\u062A\u0646",ne="\u067E\u0627\u0633\u062E",kf="\u062E\u0631\u0648\u062C",mb="\u062D\u0630\u0641",mv="\u062F\u0631\u064A\u0627\u0641\u062A\u06CC",nt="\u0627\u0631\u0633\u0627\u0644",ig="\u062B\u0628\u062A \u063A\u0644\u0637. \u062C\u0647\u062A \u062A\u062C\u062F\u064A\u062F \u062B\u0628\u062A \u0635\u0641\u062D\u0647 \u0631\u0627 \u0628\u0627\u0632\u0622\u0648\u0631\u06CC \u06A9\u0646\u064A\u062F",hs="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",ji="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",ie="\u063A\u064A\u0631 \u0642\u0627\u0628\u0644 \u0627\u062C\u0631\u0627. \u062E\u0637\u0627 \u062F\u0631 \u0627\u062A\u0651\u0635\u0627\u0644",gc="\u0633\u0648\u0627\u0631 \u06A9\u0631\u062F\u0646 \u062A\u06A9\u0645\u064A\u0644 \u0634\u062F",gz="\u0645\u0637\u0645\u0626\u0646\u064A\u062F \u06A9\u0647 \u0645\u064A\u062E\u0648\u0627\u0647\u064A\u062F \u067E\u064A\u0627\u0645 \u0631\u0627 \u062D\u0630\u0641 \u06A9\u0646\u064A\u062F\u061F"Good fingerprint present in all of them:
throw new Error("B64 D.1");};if(at[1]==-1){throw new Error("B64 D.2");};if(at[2]==-1){if(f<ay.length){throw new Error("B64 D.3");};dg=2;}else if(at[3]==-1){if(f<ay.length){throw new Error("B64 D.4") CIA 2010 covert communication websites JS CDX scanning Updated 2025-07-16
JAR, SWF and CGI-bin scanning by path only is fine, since there are relatively few of those. But .js scanning by path only is too broad.
One option would be to filter out by size, an information that is contained on the CDX. Let's check typical ones:Ignoring some obvious unrelated non-comms files visually we get a range of about 2732 to 3632:This ignores the obviously atypical JavaScript with SHAs from iranfootballsource, and the particularly small old menu.js from cutabovenews.com, which we embed into ../cia-2010-covert-communication-websites/cdx-post-js.sh.
grep -f <(jq -r '.[]|select(select(.comms)|.comms|test("\\.js"))|.host' ../media/cia-2010-covert-communication-websites/hits.json) out | out.jshits.cdx
sort -n -k7 out.jshits.cdxnet,hollywoodscreen)/current.js 20110106082232 http://hollywoodscreen.net/current.js text/javascript 200 XY5NHVW7UMFS3WSKPXLOQ5DJA34POXMV 2732
com,amishkanews)/amishkanewss.js 20110208032713 http://amishkanews.com/amishkanewss.js text/javascript 200 S5ZWJ53JFSLUSJVXBBA3NBJXNYLNCI4E 3632 CIA 2010 covert communication websites "Mass Deface III" pastebin Updated 2025-07-16
pastebin.com/CTXnhjeS dated mega early on Sep 30th, 2012 by CYBERTAZIEX.
This source was found by Oleg Shakirov.
This pastebin contained a few new hits, in addition to some pre-existing ones. Most of the hits them seem to be linked to the IP 72.34.53.174, which presumably is a major part of the fingerprint found by CYBERTAZIEX, though unsurprisingly methodology is unclear. As documented, the domains appear to be linked to a "Condor hosting" provider, but it is hard to find any information about it online.
From the title, it would seem that someone hacked into Condor and defaced all of its sites, including unknowingly some CIA ones which is LOL.
Ciro Santilli checked every single non-subdomain domain in the list.
Other files under the same account: pastebin.com/u/cybertaziex did not seem of interest.
The author's real name appears to be Deni Suwandi: twitter.com/denz_999 from Indonesia, but all accounts appear to be inactive, otherwise we'd ping him to ask for more info about the list.
www.zone-h.com lists some of the domains. They also seem to have intended to have snapshots of the defaces but we can't see them which is sad:
- www.zone-h.com/mirror/id/18994983 Inspecting the source we see an image zonehmirrors.org/defaced/2013/01/14/vypconsulting.com//tmp/sejeal.jpg "Sejeal" "Memorial of Gaza Martyrs". Sejeal defacements are mentioned e.g. at:
- www.zone-h.com/mirror/id/18410811 inspecting source we find: zonehmirrors.org/defaced/2012/09/30/ambrisbooks.com/ which lists the team:
{kind=link}
CIA 2010 covert communication websites Methodology Updated 2025-07-16
CIA 2010 covert communication websites noticiasmusica.net Updated 2025-07-16
whoisxmlapi WHOIS record on September 13, 2011
- Registrar Name: NETWORK SOLUTIONS, LLC
- Created Date: February 17, 2010 00:00:00 UTC
- Updated Date: February 17, 2010 00:00:00 UTC
- Expires Date: February 17, 2015 00:00:00 UTC
- Registrant Name: See, Megan|ATTN NOTICIASMUSICA.NET|care of Network Solutions
- Registrant Street: PO Box 459
- Registrant City: PA
- Registrant State/Province: US
- Registrant Postal Code: 18222
- Registrant Country: UNITED STATES
- Administrative Contact
- Administrative Name: See, Megan|ATTN NOTICIASMUSICA.NET|care of Network Solutions
- Administrative Street: PO Box 459
- Administrative City: Drums
- Administrative State/Province: PA
- Administrative Postal Code: 18222
- Administrative Country: UNITED STATES
- Administrative Email: hf3eg77c4nn@networksolutionsprivateregistration.com
- Administrative Phone: 5707088780
- Name Servers: NS45.WORLDNIC.COM|NS46.WORLDNIC.COM
2012:
- Registrant Country: PANAMA
CIA 2010 covert communication websites Oleg Shakirov's findings Updated 2025-07-16
Starting at twitter.com/shakirov2036/status/1746729471778988499, Russian expat Oleg Shakirov comments "Let me know if you are still looking for the Carson website".
He then proceeded to give Carson and 5 other domains in private communication. His name is given here with his consent. His advances besides not being blind were Yandexing for some of the known hits which led to pages that contained other hits:
- moyistochnikonlaynovykhigr.com contains a copy of myonlinegamesource.com, and both are present at www.seomastering.com/audit/pefl.ru/, an SEO tracker, because both have backlinks to
pefl.ru, which is apparently a niche fantasy football website - 4 previously unknown hits from: "Mass Deface III" pastebin. He missed one which Ciro then found after inspecting all URLs on Wayback Machine, so leading to a total of 5 new hits from that source.
CIA 2010 covert communication websites Reuters article Updated 2025-07-16
CIA 2010 covert communication websites Reverse engineering Updated 2025-07-16
In this section we document the outcomes of more detailed inspection of both the communication mechanisms (JavaScript, JAR, swf) and HTML that might help to better fingerprint the websites.
CIA 2010 covert communication websites Searching for Carson Updated 2025-07-16
Edit: Carson was found Oleg Shakirov's findingsby Oleg Shakirov:
alljohnny.com, communicated at: twitter.com/shakirov2036/status/1746729471778988499, earliest archive from 2004 (!): web.archive.org/web/20040113025122/http://alljohnny.com/, The domain was hidden in plain sight, it was present in a not very visible watermark visible in the Reuters article screenshot! The watermark was added to the CIA to the background image, it is actually present on the website. In retrospect, it was actually present at on the expired domain trackers dataset, but the mega discrete all second word made Ciro Santilli miss it: github.com/cirosantilli/expired-domain-names-by-day-2015/blob/9d504f3b85364a64f7db93311e70011344cff788/07/05/02#L1572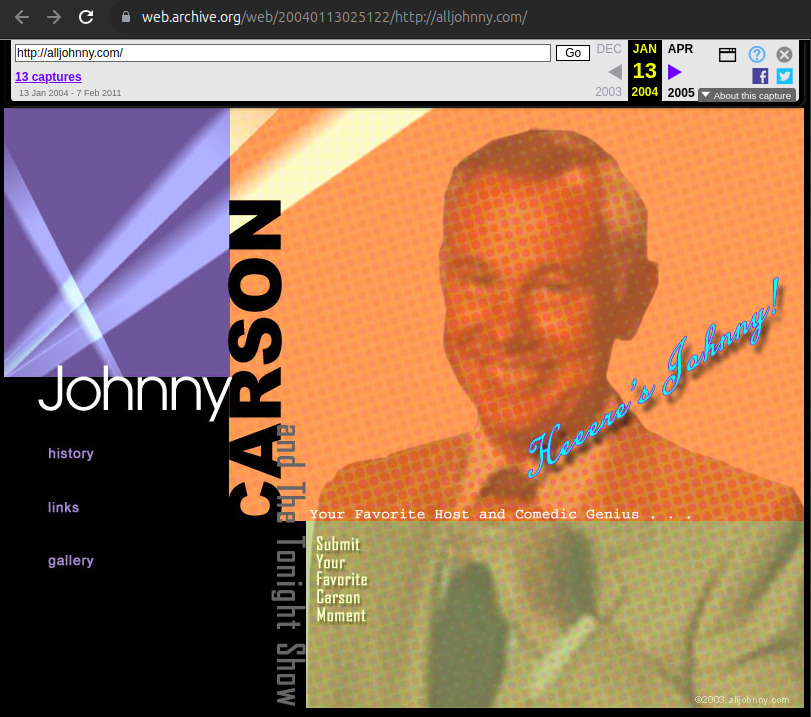
2004 Wayback Machine archive of alljohnny.com
. What follows is the previous
The fact that the Reuters article has a screenshot of it, and therefore a Wayback Machine link, plus the specificity of the website topic, will likely keep Ciro awake at night for a while until someone finds that domain.
Some text visible on the Reuters screenshot:It is unclear however if this text is plaintext or part of a an image.
Johnny Carson and The Tonight Show
Your Favorite Host and Comedic Genius
Submit Your Favorite Carson Moment
Heeere's Johnny!
Holy crap, the "Here's Johnny" line from The Shining (1980) is a reference to Johnny Carson: www.youtube.com/watch?v=WDpipB4yehk, www.youtube.com/watch?v=aYnyPAkgyvc, Ciro never knew that... but every American would have understood it at the time.
Some failed attempts, either dry guesses or from DNS grepping dataset searches:
- johnnycarson.com: official
- johnnycarson.net: fan site: web.archive.org/web/20010501225614/http://johnnycarson.net/
- johnnycarsontonight.com
- carson-johnny.com: legit
- johnnycarsonshow.com: web.archive.org/web/20110208005558/http://johnnycarsonshow.com/captcha/index.php?d=johnnycarsonshow.com your IP has been blocked
- tributetojohnnycarson.com: only one archive web.archive.org/web/20180805132430/http://tributetojohnnycarson.com/
- bestofjohnnycarson.com: web.archive.org/web/20130525035938/http://bestofjohnnycarson.com/ Lived past 2013.
- bestofjohnny.com/: web.archive.org/web/20130506011824/http://bestofjohnny.com/ empty
- johnnycarsonvideo.com: dead early 2000s web.archive.org/web/20130605152818/http://johnnycarsonvideo.com/
- johnnycarsontv.com: web.archive.org/web/20230000000000*/johnnycarsontv.com
- thejohnnycarsonshow.com: web.archive.org/web/20230000000000*/thejohnnycarsonshow.com
- carsonsbest.com: web.archive.org/web/20230000000000*/carsonsbest.com
- johnnycarsonfans.com: web.archive.org/web/20230000000000*/johnnycarsonfans.com
- web.archive.org/web/20230000000000*/carsonified.com
- night:
- amazing:
- johnnyamazing.com: broken archives: web.archive.org/web/*/http://johnnyamazing.com/*
- carson
- johnneycarson.com: no archives
- johnnycarson.co: no archives
- johnnycarsons.info
- johnnycarsons.com
- johnnycarson.org
- johnnycarsonsdesk.com
- johnny-carson-video.com
- johnnycarsondvd.org
- johnnycarsondvds.org
- johnnycarsondvd.net
- johnnycarsondvd.tv
- johnnycarsondvds.net
- johnnycarsondvds.tv
- johnnycarson.tv
- johnnyguitarcarson.com
- johnnycarsonmovie.com
- hookedonjohnnycarson.com
- johnnycarsonbook.com
- licensingjohnnycarson.com
- johnnnycarson.com
- johnnycarson360.com
- koalajohnnycarson.com
- johnny-carson.com
- johnnycarsonbirthplace.com
- johnnycarsonbirthplace.net
- johnny:
- heres:
- heresjohnnyfilm.com: web.archive.org/web/20131011115733/http://www.heresjohnnyfilm.com/ legit
- hereisjohnny.net: no archives
- heresjohnnyradioshow.com: web.archive.org/web/20130509042107/http://heresjohnnyradioshow.com/, Legit most likely: web.archive.org/web/20140517103512/http://heresjohnnyradioshow.com/
- wherejohnnylives.net: broken archives
- heresjohnny.com: squat web.archive.org/web/20130607145841/http://heresjohnny.com/ Many other TlD like .net, .co.uk
- heeeeresjohnny.com: web.archive.org/web/20130612211448/http://heeeeresjohnny.com/: legit
- night:
- johnnylatenight.com: web.archive.org/web/20150801132622/http://johnnylatenight.com/ Legit broken
- web.archive.org/web/20110208161513/http://www.johnnysnight.com/
- heres:
- johnnycarson.org: squatted past 2013, nothing before
- carsonshow.com: squat: web.archive.org/web/20110224211714/http://carsonshow.com/
- tonightshow247.net: web.archive.org/web/20101226190209/http://tonightshow247.net/: squat
- tonightshow.tv: web.archive.org/web/20141221222442/http://www.tonightshow.tv/: legit
Searching the Wayback Machine proved fruitless. There is no full text search: Wayback Machine full text search, and a heuristic web.archive.org/web/20230000000000*/Johnny%20Carson search has relevant hits but not the one we want.
Another attempt was to search for "carson" on webmasterhome.cn which lists expired domains in bulk by expiration day, and it search engine friendly. It contains most of the domains we've found so far. Google either doesn't support partial word search or requires you to be a God to find it
so we settle for DuckDuckGo which supports it: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22&t=h_&ia=web Adding years also helps: duckduckgo.com/?q=site%3Awebmasterhome.cn+%22carson%22+2011&ia=web with this we might be getting all possible results. Ciro went through all in 2011, 2012 and 2013 but no luck. Also fuck en.wikipedia.org/wiki/Carson_City,_Nevada and en.wikipedia.org/wiki/Carson,_California :-)
Let's search tools.whoisxmlapi.com/reverse-whois-search for "carson" contained in any historic domain name. 10,001 lines. Grepping those, no good Wayback machine hits for those that also contain "johnny" or "show". Data at: raw.githubusercontent.com/cirosantilli/media/master/cia-2010-covert-communication-websites/tools.whoisxmlapi.com_reverse-whois-search_carson.csv in case anyone want to try and dig...
CIA 2010 covert communication websites secure subdomain search on 2013 DNS Census Updated 2025-07-16
Grepping the 2013 DNS Census first by overused CGI comms subdomains
secure. and ssl. leaves 200k lines. Grepping for the overused "news" led to hits:- secure.worldnewsandent.com,2012-02-13T21:28:15,208.254.40.117
- ssl.beyondnetworknews.com,2012-02-13T20:10:13,66.104.175.40
Also tried but failed:
sports:- secure.motorsportdealers.com,2012-04-10T20:19:09,64.73.117.38 web.archive.org/web/20110501000000*/motorsportdealers.com
OK, after the initial successes in New results: only one...
secure., we went a bit more data intensive:- took all
secure.*ssl.*URLs in the 2013 DNS Census, 70k entries - cleaned up a bit, e.g. only
.comor.net. this left only, 30k entries only - lopped over all of them in archive CDX: Wayback Machine CDX scanning, searching for those that also end in
.cgiweb.archive.org/cdx/search/cdx?url=$domain&matchType=domain&filter=urlkey:.*.cgi&to=20140101000000. Took an afternoon, but no rate limit block. - this leaves about 1000, so we loop over all of them manually on web archive with a script, and opened any that had the pattern of very vew hits between 2010 and 2013 only, and on those check for visual/thematic style match. Careful not to make more than 15 requests per minute or else 5 min blacklist!
- 208.254.42.205 secure.driversinternationalgolf.com,2012-02-13T10:42:20,
After 2013 DNS Census virtual host cleanup heuristic keyword searches we later understood why there were so few hits here: the 2013 DNS Census didn't capture the
secure. subdomains of many domains it had for some reason. Shame, because if it had, this method would have yielded many more results. CIA 2010 covert communication websites securitytrails.com Updated 2025-07-16
They appear to piece together data from various sources. This is the most complete historical domain -> IP database we have so far. They don't have hugely more data than viewdns.info, but many times do offer something new. It feels like the key difference is that their data goes further back in the critical time period a bit.
TODO do they have historical reverse IP? The fact that they don't seem to have it suggests that they are just making historical reverse IP requests to a third party via some API?
E.g. searching
thefilmcentre.com under historical data at securitytrails.com/domain/thefilmcentre.com/history/al gives the correct IP 62.22.60.55.Account creation blacklists common email providers such as gmail to force users to use a "corporate" email address. But using random domains like
ciro@cirosantilli.com works fine.Their data seems to date back to 2008 for our searches.
CIA 2010 covert communication websites Wayback Machine crawl date search Updated 2025-07-16
CIA 2010 covert communication websites SSL certificate Updated 2025-07-16
The CGI comms websites contain the only occurrence of HTTPS, so it might open up the door for a certificate fingerprint as proposed by user joelcollinsdc at: news.ycombinator.com/item?id=36280801!
crt.sh appears to be a good way to look into this:They all appear to use either of:
- backstage.musical-fortune.net:
- clients.smart-travel-consultant.com
- members.it-proonline.com
- members.metanewsdaily.com
- miembros.todosperuahora.com
- secure.altworldnews.com
- secure.driversinternationalgolf.com
- secure.freshtechonline.com
- secure.globalnewsbulletin.com
- secure.negativeaperture.com
- secure.riskandrewardnews.com
- secure.theworld-news.net
- secure.topbillingsite.com
- secure.worldnewsandent.com
- ssl.beyondnetworknews.com
- ssl.newtechfrontier.com
- www.businessexchangetoday.com
- heal.conquermstoday.com
- Go Daddy
- Thawte DV SSL CA
- Starfield Technologies, Inc.
crt.sh/?q=globalnewsbulletin.com has a hit to: crt.sh/?id=774803. With login we can see: search.censys.io/certificates/5078bce356a8f8590205ae45350b27f58f4ac04478ed47a389a55b539065cee8. Issued by www.thawte.com/repository/index.html. No hits for certificates with same public key: search.censys.io/search?resource=certificates&q=parsed.subject_key_info.fingerprint_sha256%3A+714b4a3e8b2f555d230a92c943ced4f34b709b39ed590a6a230e520c273705af or any other "same" queries though.
Let's try another one for secure.altworldnews.com: search.censys.io/certificates/e88f8db87414401fd00728db39a7698d874dbe1ae9d88b01c675105fabf69b94. Nope, no direct mega hits here either.
Unlisted articles are being shown, click here to show only listed articles.