
Incoming links: OurBigBook Web
Home Updated 2026-05-30
Check out: OurBigBook.com, the best way to publish your scientific knowledge. It's an open source note taking system that can publish from lightweight markup files in your computer both to a multi-user mind melding dynamic website, or as a static website. It's like Wikipedia + GitHub + Stack Overflow + Obsidian mashed up. Source code: github.com/ourbigbook/ourbigbook.
Sponsor me to work on this project. For 1M USD I will quit my job and work on OurBigBook full time for three more years to try and kickstart The Higher Education Revolution. Status: ~44k / 400k USD. At 4M USD I retire/tenure and work on open STEM forever. How to donate: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
I first quit my job 1st June 2024 to work on the project for 1 year after I reached my initial 100k goal mostly via a 1000 Monero donation.
Mission: to live in a world where you can learn university-level mathematics, physics, chemistry, biology and engineering from perfect free open source books that anyone can write to get famous. More rationale: Section "OurBigBook.com"
Explaining things is my superpower, e.g. I was top user #39 on Stack Overflow in 2023[ref][ref] and I have a few 1k+ star educational GitHub repositories[ref][ref][ref][ref]. Now I want to bring that level of awesomeness to masters level Mathematics and Physics. But I can't do it alone! So I created OurBigBook.com to allow everyone to work together towards the perfect book of everything.
My life's goal is to bring hardcore university-level STEM open educational content to all ages. Sponsor me at github.com/sponsors/cirosantilli starting from 1$/month so I can work full time on it. Further information: Section "Sponsor Ciro Santilli's work on OurBigBook.com". Achieving what I call "free gifted education" is my Nirvana.
This website is written in OurBigBook Markup, and it is published on both cirosantilli.com (static website) and outbigbook.om/cirosantilli (multi-user OurBigBook Web instance). Its source code is located at: github.com/cirosantilli/cirosantilli.github.io and also at
cirosantilli.com/_dir and it is licensed under CC BY-SA 4.0 unless otherwise noted.To contact Ciro, see: Section "How to contact Ciro Santilli". He likes to talk with random people of the Internet.
GitHub | Stack Overflow | LinkedIn | YouTube | Twitter | Wikipedia | Zhihu 知乎 | Weibo 微博 | Other accounts

Besides that, I'm also a freedom of speech slacktivist and recreational cyclist. I like Chinese traditional music and classic Brazilian pop. Opinions are my own, but they could be yours too. Tax the rich.
Let's create an educational system with:
- no distinction between university and high school, students just go as fast as they can to what they really want without stupid university entry exams
- fully open source learning material
- on-demand examinations that anyone can easily take without prerequisites
- granular entry selection only for space in specific laboratories or participation in specific novel research projects
I offer:
- online private tutoring for:
- any STEM university course
- passionate younger STEM students (any age) who want to learn university level material and beyond. Can your kid be the next Fields Medalist or Nobel Prize winner? I'm here to help, especially if you are filthy rich! I focus moving students forward as fast as they want on and on producing useful novel tutorials and results
Let your child be my Emile, and me be their Adolfo Amidei, and let's see how far they can go! I will help take your child:and achieve their ambitious STEM goals!- into the best universities
- into the best PhD programs
- educational consulting for institutions looking to improve their STEM courses
- do you know that course or teacher that consistently gets bad reviews every year? I'll work with the teacher to turn the problem around!
- are you looking to create a consistent open educational resources offering to increase your institutions internationally visibility? I can help with that too.
My approach is to:For minors, parents are welcome to join video calls, and all interactions with the student will be recorded and made available to parents.
- propose interesting research projects. The starting point is always deciding the end goal: Section "Backward design"
- learn what is needed to do the project together with the student(s)
- publish any novel results or tutorials/tools produced freely licensed online, and encourage the student to do the same (Section "Let students learn by teaching", digital garden)
I have a proven track of explaining complex concepts in an interesting and useful way. I work for the learner. Teaching statement at: Section "How to teach". Pricing to be discussed. Contact details at: Section "How to contact Ciro Santilli".
I am particularly excited about pointing people to the potential next big things, my top picks these days are:I am also generally interested in:
- quantum computing
- AGI research, in particular AI code generation, automated theorem proving and robotics
- assorted molecular biology technologies
- 20th century physics, notably AMO and condensed matter
- the history of science, and in particular trying to look at seminal papers of a field

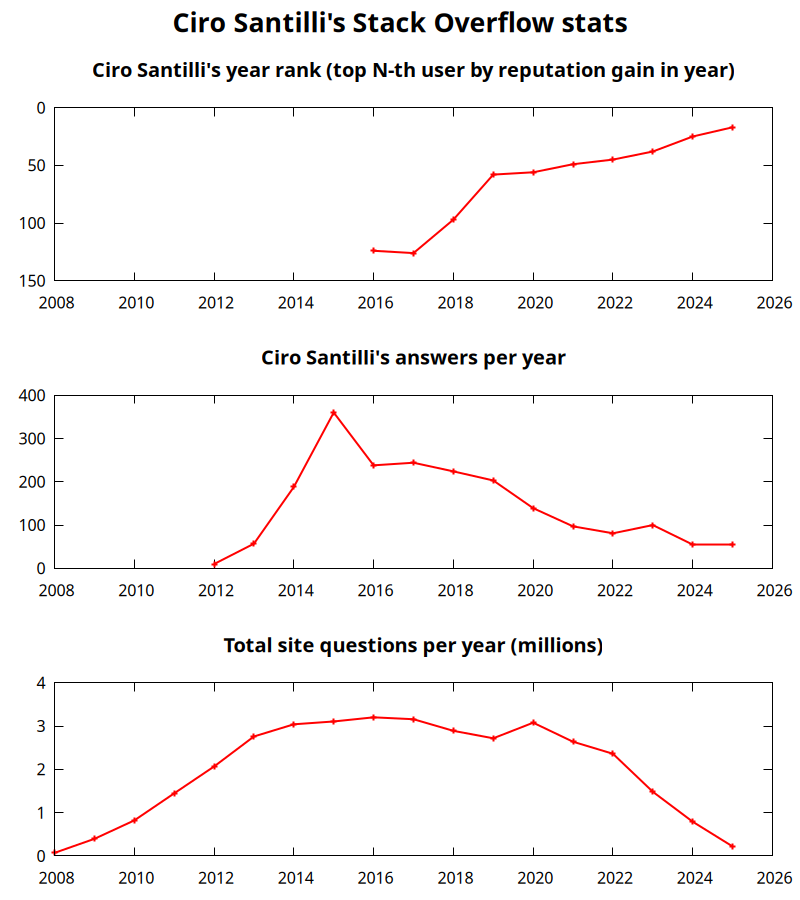
The problem with education by Ciro Santilli
. Source. In this video Ciro Santilli exposes his fundamental philosophy regarding why Education is broken. This philosophy was the key motivation behind the failed OurBigBook Project.Introduction to the OurBigBook Project
. Source. OurBigBook Web topics demo
. Source. The OurBigBook topic feature allows users to "merge their minds" in a "sort by upvote"-stack overflow-like manner for each subject. This is the killer feature of OurBigBook Web. More information at: docs.ourbigbook.com/ourbigbook-web-topics.OurBigBook dynamic article tree demo
. Source. The OurBigBook dynamic tree feature allows any of your headers to be the toplevel h1 header of a page, while still displaying its descendants. SEO loves this, and it also allows users to always get their content on the correct granularity. More information at: docs.ourbigbook.com/ourbigbook-web-dynamic-article-tree.OurBigBook local editing and publishing demo
. Source. With OurBigBook you can store your content as plaintext files in a Lightweight markup, and then publish that to either OurBigBook.com to get awesome multi-user features, or as a static website where you are in full control. More information at: docs.ourbigbook.com/publish-your-content.Top Down 2D continuous game with Urho3D C++ SDL and Box2D for Reinforcement learning by Ciro Santilli (2018)
Source. More information: Section "Ciro's 2D reinforcement learning games". This is Ciro's underwhelming stab at the fundamental question: Can AGI be trained in simulations?. This project could be taken much further.
-------------------------------------
| Force of Will 3 U U |
| --------------------------------- |
| | //////////// | |
| | ////() ()\////\ | |
| | ///_\ (--) \///\ | |
| | ) //// \_____///\\ | |
| | ) \ / / / / | |
| | ) / \ | | / _/ | |
| | ) \ ( ( / / / / \ | |
| | / ) ( ) / ( )/( ) \ | |
| | \(_)/(_)/ /UUUU \ \\\/ | | |
| .---------------------------------. |
| Interrupt |
| ,---------------------------------, |
| | You may pay 1 life and remove a | |
| | blue card in your hand from the | |
| | game instead of paying Force of | |
| | Will's casting cost. Effects | |
| | that prevent or redirect damage | |
| | cannot be used to counter this | |
| | loss of life. | |
| | Counter target spell. | |
| `---------------------------------` |
| l
| Illus. Terese Nelsen |
-------------------------------------Code 1. .
Artist unknown, uploaded December 2014. Part of Section "Cool data embedded in the Bitcoin blockchain" where Ciro Santilli maintains a curated list of such interesting inscriptions.
This was a small project done by Ciro for artistic purposes that received some attention due to the incredible hype surrounding cryptocurrencies at the time. Ciro Santilli's views on cryptocurrencies are summarized at: Section "Are cryptocurrencies useful?".

YellowRobot.jpgJPG image fully embedded in the Bitcoin blockchain depicting some kind of cut material art depicting a yellow robot, inscribed on January 29, 2017.
Ciro Santilli found this image and others during his research for Section "Cool data embedded in the Bitcoin blockchain" by searching for image fingerprints on every transaction payload of the blockchain with a script.
The image was uploaded by EMBII, co-creator of the AtomSea & EMBII upload mechanism, which was responsible for a large part of the image inscriptions in the Bitcoin blockchain.
The associated message reads:This is one of Ciro Santilli's favorite AtomSea & EMBII uploads, as it perfectly encapsules the "medium as an art form" approach to blockchain art, where even non-novel works can be recontextualized into something interesting, here depicting an opposition between the ephemeral and the immutable.
Chiharu [EMBII's Japanese wife] and I found this little yellow robot while exploring Chicago. It will be covered by tar or eventually removed but this tribute will remain. N 41.880778 E -87.629210
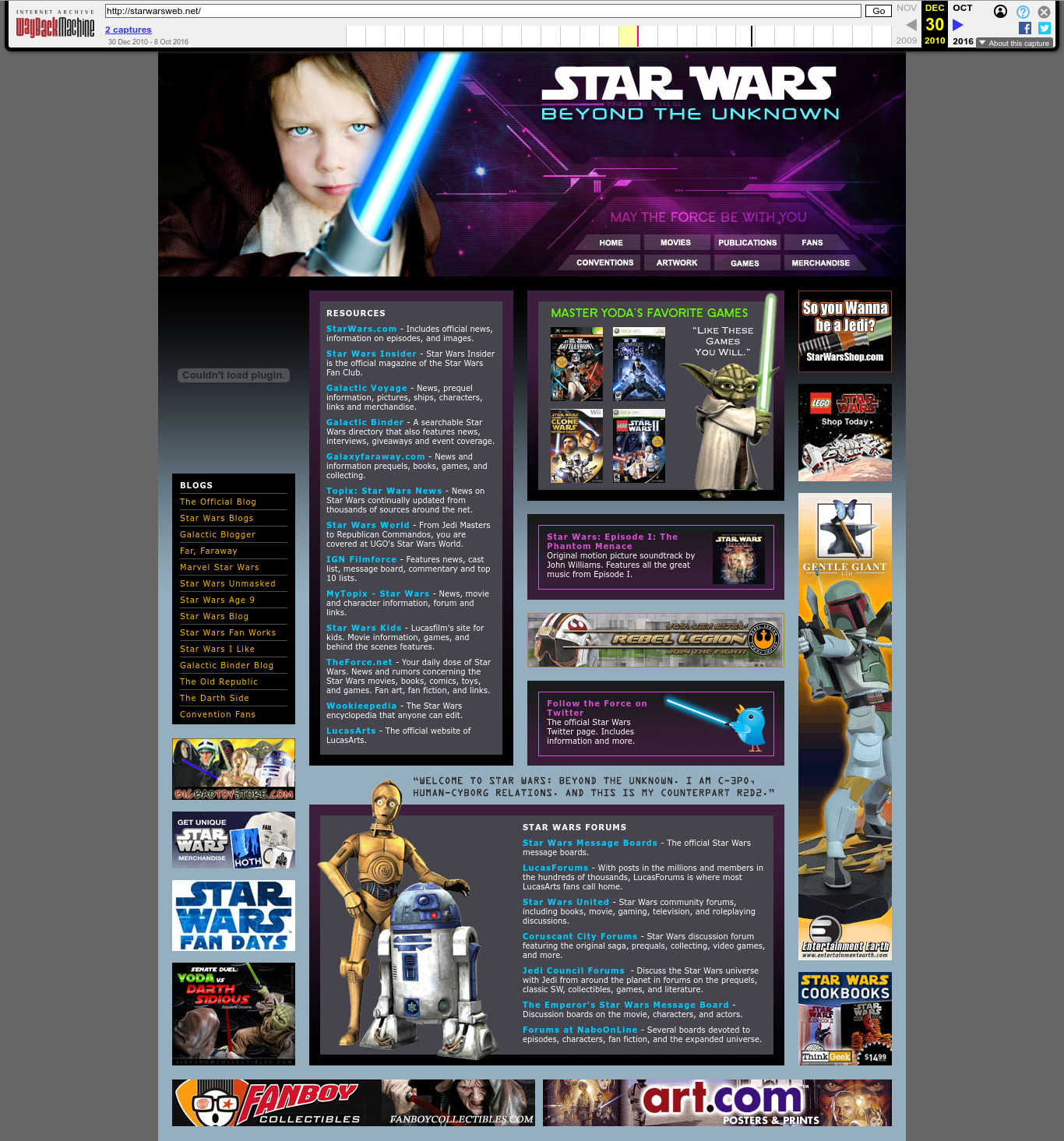
2010 Wayback Machine archive of starwarsweb.net
. This website was used as one of the CIA 2010 covert communication websites, a covert system the CIA used to communicate with its assets. More details at: Section "CIA 2010 covert communication websites".
Ciro Santilli had some naughty OSINT fun finding some of the websites of this defunct network in 2023 after he heard about the 2022 Reuters report on the matter, which for the first time gave away 7 concrete websites out of a claimed 885 total found. As of November 2023, Ciro had found about 350 of them.

2010 Wayback Machine archive of noticiasmusica.net
. This is another website that was used as one of the CIA 2010 covert communication websites. This website is written in Brazilian Portuguese, and therefore suggests that the CIA had assets in Brazil at the time, and thus was spying on a "fellow democracy".
Although Snowden's revelations made it extremely obvious to the world that the USA spies upon everyone outside of the Five Eyes, including fellow democracies, it is rare to have such a direct a concrete proof of it visible live right on the Wayback Machine. Other targeted democracies include France, Germany, Italy and Spain. More details at: USA spying on its own allies.
This investigative report by Ciro Santilli was featured on the Daily Mail after 404 Media reported on it in 2025.

Diagram of the fundamental theorem on homomorphisms by Ciro Santilli (2020)
Shows the relationship between group homomorphisms and normal subgroups.
Used in the Stack Exchange answer to What is the intuition behind normal subgroups? One of Section "The best articles by Ciro Santilli".

Spacetime diagram illustrating how faster-than-light travel implies time travel by Ciro Santilli (2021)
Used in the Stack Exchange answer to Does faster than light travel imply travelling back in time?. One of Section "The best articles by Ciro Santilli".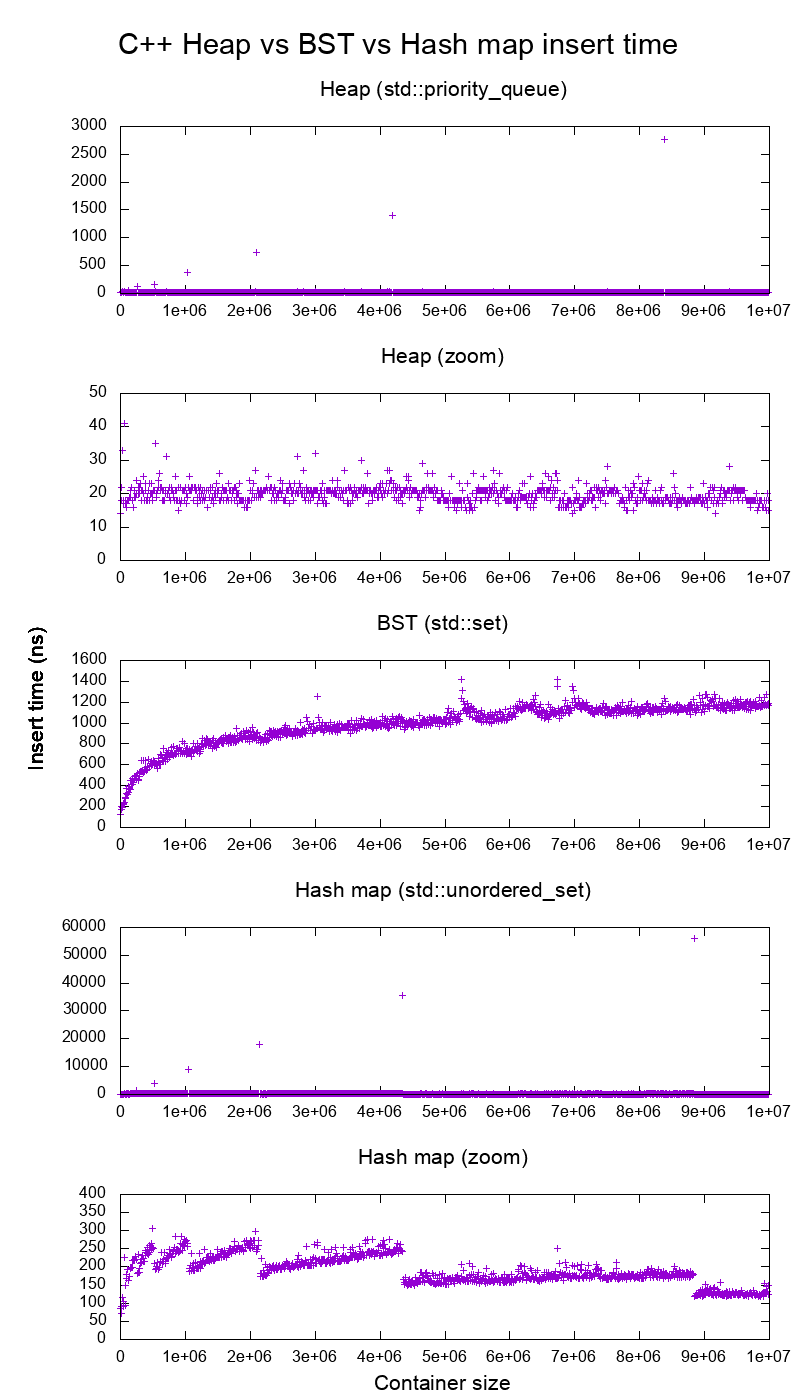
Average insertion time into heaps, binary search tree and hash maps of the C++ standard library by Ciro Santilli (2015)
Source. Used in the Stack Overflow answer to Heap vs Binary Search Tree (BST). One of Section "The best articles by Ciro Santilli".
Top view of an open Oxford Nanopore MinION
. Source. This is Ciro Santilli's hand on the Wikipedia article: en.wikipedia.org/wiki/Oxford_Nanopore_Technologies. He put it there after working a bit on Section "How to use an Oxford Nanopore MinION to extract DNA from river water and determine which bacteria live in it" :-) And he would love to document more experiments like that one Section "Videos of all key physics experiments", but opportunities are extremely rare.A quick 2D continuous AI game prototype for reinforcement learning written in Matter.js, you can view it on a separate page at cirosantilli.com/_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport. This is a for-fun-only prototype for Ciro's 2D reinforcement learning games, C++ or maybe Python (for the deep learning ecosystem) seems inevitable for a serious version of such a project. But it is cute how much you can do with a few lines of Matter.js!
HTML snippet:
<iframe src="_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport" width="1000" height="850"></iframe> Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects Publish from local markup files Created 2024-09-04 Updated 2025-07-16

- cirosantilli.com (static)
- ourbigbook.com/cirosantilli (dynamic)

Visual Studio Code extension installation
. 
Forester Created 2024-10-12 Updated 2025-07-16
Intro/docs: www.jonmsterling.com/jms-005P.xml. It is very hard to find information in that system however, largely because they don't seem to have a proper recursive cross file table of contents.
This is the project with the closest philosophy to OurBigBook that Ciro Santilli has ever found. It just tends to be even more idealistic than, OurBigBook in general, which is insane!
"Docs" at: www.jonmsterling.com/foreign-forester-jms-005P.xml Sample repo at: github.com/jonsterling/forest but all parts of interest are in submodules on the authors private Git server.
Example:
- sample source file: git.sr.ht/~jonsterling/public-trees/tree/2356f52303c588fadc2136ffaa168e9e5fbe346c/item/jms-005P.tree
- appears rendered at: www.jonmsterling.com/foreign-forester-jms-005P.xml
Author's main social media account seems to be: mathstodon.xyz/@jonmsterling e.g. mathstodon.xyz/@jonmsterling/111359099228291730 His home page:
They have
\Include like OurBigBook, nice: www.jonmsterling.com/jms-007L.xml, but OMG that name \transclude{xxx-NNNN}!! It seems to be possible to have human readable IDs too if you want: www.jonmsterling.com/foreign-forester-armaëlguéneau.xml is under trees/public/roladex/armaëlguéneau.tree.Headers have open/close:OurBigBook considered this, but went with
\subtree[jms-00YG]{}parent= instead finally to avoid huge lists of close parenthesis at the end of deep nodes.One really cool thing is that the headers render internal links as clickable, which brings it all closer to the "knowledge base as a formal ontology" approach.
The markup has relatively few insane constructs, notably you need explicit open paragraphs everywhere
\p{}?! OMG, too idealistic, not enough pragmatism. There are however a few insane constructs:The markup is documented at: www.jonmsterling.com/foreign-forester-jms-007N.xml
Jon has some very good theory of personal knowledge base, rationalizing several points that Ciro Santilli had in his mind but hadn't fully put into words, which is quite cool.
OCaml dependency is not so bad, but it relies on actually LaTeX for maths, which is bad. Maybe using JavaScript for OurBigBook wasn't such a bad choice after all, KaTeX just works.
Viewing the generated output HTML directly requires
security.fileuri.strict_origin_policy which is sad, but using a local server solves it. So it appears to actually pull pieces together with JavaScript? Also output files have .xml extension, the idealism! They are reconsidering that though: www.jonmsterling.com/foreign-forester-jms-005P.xml#tree-8720.The Ctrl+K article dropdown search navigation is quite cool.
\rel and \meta allows for arbitrary ontologies between nodes as semantic triples. But they suffer from one fatal flaw: the relations are headers in themselves. We often want to explain why a relation is true, give intuition to it, and refer to it from other nodes. This is obviously how the brain works: relations are nodes just like objects.They do appear to be putting full trees on every toplevel regardless how deep and with JavaScript turned off e.g.:
which is cool but will take lots of storage. In OurBigBook Ciro Santilli only does that on OurBigBook Web where each page can be dynamically generated.
OurBigBook.com Updated 2025-10-27
The website is the reference instance of OurBigBook Web, which is part of the OurBigBook Project, the other main part of the project are software that users can run locally to publish their content such as the OurBigBook CLI.
The project documentation is present at: docs.ourbigbook.com#ourbigbook-web-user-manual
Intro to the OurBigBook Project
. Source. 

OurBigBook's weird specialization towards the weird overly niche interests of its creator Ciro Santilli, notably "I want to create the perfect documentation for every atom in the universe, is undoubtedly partly to blame for the project's failure to gain even a single user outside of its own creator.
OurBigBook Library Updated 2025-07-16
Ciro's Edict #9 Advances Updated 2025-07-16
OurBigBook Web error reporting starting to look amazing.
Source. In any case, the outcome of that is that the tech has improved. And I have done a relatively good job of clearly publishing any "more user visible" improvements to docs.ourbigbook.com/news and social media such as though it is important to note that there have been more than one "fix a hard bug" weeks that were not published because they would just bore readers.
During this period the main focus has been on improving OurBigBook Web, i.e. the dynamic website that powers OurBigBook.com. There are two reasons for that:As a result, Web is now way less buggy and much more usable.
- Web is what has the OurBigBook topics feature for mind-melding, which is the killer feature of OurBigBook compared to other note taking apps and therefore deserves the highest levels of priorityStatic website generation is an indispensable escape valve that ensures that your content can be published forever even if OurBigBook.com goes down one day, which it won't as long as I live. But the innovation is Web.
- static website generation was closer to good enough, but web was much further and is fundamentally harder.I'm extremely satisfied with OurBigBook static website generation and haven't touched it as much. It wasn't easy to reach this state, but I'm there.But Web is a different and much more complex beast.Making CLI software that will run on a person's local computer under full trust and building a bunch of HTML from lightweight markup in bulk is one thing.But making a public dynamic website that has to continuously maintain a coherent database state on granular updates, while giving users some trust but not enough for them to blow everything up is on a totally different level. See e.g. the recent SPAM attack we've had to fend off.And then there's also the issue of front-end being mega-hard to get right.

{kind=link}
If you look through the list of Web updates, there is nothing specifically mind blowing. The core ideas have largely crystallized, and we are just trying to making them click. I have a few more punches up my sleeve, but the core is decided.
OurBigBook Web search
. Source. This is one of the many basic quality of life improvements that have been done on OurBigBook Web.
OurBigBook Web article announcement
. Source. Another cute new feature, you can send an email to your followers about a new amazing article you created.Web process has been somewhat slower than what I'd like. Of course, it is the case of any project that things are easily said than done. But there are two other main structural factors that have played into it:
- For example, we could have put him on childcare a bit earlier, but due to inexperience we've kept him a bit longer than we maybe should have.Things are well sorted out now, but not matter how good your support system is, at the end of the day, and more often night, it is you the parents that have to deal with a lot of inevitable baby issues. Unless you want them to turn into psychopaths and drug addicts that is, which I don't. I've reached the point of semi failure middle age that the baby feels like my best moonshot.But at least with the donations I was able to work on OurBigBook at all. Because if it weren't for that, I would have to focus entirely on the generic job instead and OurBigBook would have been put on hold.
- the choice of Web stack. I was allured by Next.js. I can see the beauty and usefulness of a Node.js render front-end that also runs on backend and hydration. That is awesome.But:
- React is insanely hard to learn and understand. Furthermore, it is also hard to understand the performance problem that it solves, and actually have a benchmark where this problem is solved faster than just delivering some HTML files with ad-hoc Js on top.
- the lack (or perhaps excess of shitty) actual web framework like Ruby on Rails and Django means that I have to rediscover the wheel many times over for all the essential support activities like testing, login and so one
At this point a rewrite is out of the question. I've managed to master things well enough to get a decent result, and given up on the few things that I couldn't for the life of me achieve, after documenting them very well for posterity of course.
Aside from Web, there was only one thing that received a significant improvement, and that was the OurBigBook VS Code extension. The extension is not perfect, and it is not the "final UI", which has to be some WYSIWYG implementation, and there are some fundamental limitations that cannot be overcome without patching VS Code itself. However, the extension is already extremely usable, and I'm writing this on it right now. Basics like syntax highlighting, jump to definition and autocomplete are very useful and usable.
Long story short, the project is so far a complete failure on the most important metric: number of regular users, which current sits at exactly one: myself.
There were notable users who found the project online and who actually tried to use the website for some content and provided extremely valuable feedback:Unfortunately after the period of a few weeks they stopped using it to follow their other priorities instead. Which is of course totally fine, however sad.
I still believe that the OurBigBook Web feature is a significant tech innovation that could make the website go big.
I also believe that the project gets many fundamentals of braindumping right, notably the infinitely deep table of contents without forced scoping, e.g.:does not make Calculus have an ID orr URL of
- Mathematics
- Calculusmathematics/calculus, rather it's just calculus.But there is a fundamental difficulty in reaching critical mass to that self-sustaining point, as people don't seem to be convinced by these logical "my system is better" argument alone, as opposed to having them Google into stuff they need now and then understand that the project is awesome.
A closely related critical mass issue is that existing big multiuser knowledge base websites such as Stack Overflow and Wikipedia have a tremendous advantage on PageRank. No matter how useless a Wikipedia article about something is, it will always be on top of Google within a week of creation for title hits. And since the main goal of publishing your stuff is to get it seen, it makes much more sense for writers to publish on such existing websites whenever possible, because anywhere else it is way way less likely to be seen by anybody.
Even I end up writing way more on Stack Overflow than on OurBigBook as a programmer. But I still believe that there is a value to OurBigBook, for the usual reasons of:
Perhaps what saddens me the most is that even on GitHub stars/Twitter/Hacker news terms there is almost no interest in the project despite the fact that I consider that it has innovations, while many other note taking apps as well in the thousands of stars. Maybe I'm just delusional and all the tech that I'm doing is completely useless?
Part of the issue is probably linked to the fact that most other note taking apps focus on "help me organize my ideas so I can make more money" and often completely ignore "I want to publish my knowledge", and stuff that helps you make money is always easier to sell and promote.
OurBigBook on the other hand a huge focus on "I want to publish me knowledge". It aims almost single mindedly in being the best tool ever for that. However this doesn't make money for people, and therefore there are going to be way less potential users.
I do believe strongly that all it takes is a few users for the project to snowball. For some people, once you start braindumping, it is very addictive, and you never want to stop basically. So with only a few of those we can open large parts of undergrad knowledge to the world. But these people are few, and so far I haven't been able to find even a single one like me, and on top of that convince them that I have created the ultimate system for their knowledge publishing desires.
Another general lesson is that I should perhaps aimed for greater compatibility with existing systems such as Obsidian. Taking something that many people already know and use can have a huge impact on acceptance. E.g. anything that touches Obsidian can reach thousands of stars: github.com/KosmosisDire/obsidian-webpage-export. Note taking apps that aim for "markdown" compatibility also tend to fare better, even if in the end you inevitably have to extend the Markdown for some of your features. And WYSIWYG, which I want but don't have, is perhaps the ultimate familiarity.
Another issue compared to other platforms is that OurBigBook just came out late. Obsidian launched in 2020. Roam Research and Trillium Notes also came earlier. And it is hard to fight the advantage already gained by those on the "I'm going to take some personal notes" area. I do believe however that there a strong separation between "these are my personal notes" and "I want to publish these". Once you decide to publish your knowledge, you immediately start to write in a different way, and it is very hard to convert pre-existing "private" notes into ones suitable for public consumption.