
Incoming links: Linux kernel
Home Updated 2026-05-30
Check out: OurBigBook.com, the best way to publish your scientific knowledge. It's an open source note taking system that can publish from lightweight markup files in your computer both to a multi-user mind melding dynamic website, or as a static website. It's like Wikipedia + GitHub + Stack Overflow + Obsidian mashed up. Source code: github.com/ourbigbook/ourbigbook.
Sponsor me to work on this project. For 1M USD I will quit my job and work on OurBigBook full time for three more years to try and kickstart The Higher Education Revolution. Status: ~44k / 400k USD. At 4M USD I retire/tenure and work on open STEM forever. How to donate: Section "Sponsor Ciro Santilli's work on OurBigBook.com".
I first quit my job 1st June 2024 to work on the project for 1 year after I reached my initial 100k goal mostly via a 1000 Monero donation.
Mission: to live in a world where you can learn university-level mathematics, physics, chemistry, biology and engineering from perfect free open source books that anyone can write to get famous. More rationale: Section "OurBigBook.com"
Explaining things is my superpower, e.g. I was top user #39 on Stack Overflow in 2023[ref][ref] and I have a few 1k+ star educational GitHub repositories[ref][ref][ref][ref]. Now I want to bring that level of awesomeness to masters level Mathematics and Physics. But I can't do it alone! So I created OurBigBook.com to allow everyone to work together towards the perfect book of everything.
My life's goal is to bring hardcore university-level STEM open educational content to all ages. Sponsor me at github.com/sponsors/cirosantilli starting from 1$/month so I can work full time on it. Further information: Section "Sponsor Ciro Santilli's work on OurBigBook.com". Achieving what I call "free gifted education" is my Nirvana.
This website is written in OurBigBook Markup, and it is published on both cirosantilli.com (static website) and outbigbook.om/cirosantilli (multi-user OurBigBook Web instance). Its source code is located at: github.com/cirosantilli/cirosantilli.github.io and also at
cirosantilli.com/_dir and it is licensed under CC BY-SA 4.0 unless otherwise noted.To contact Ciro, see: Section "How to contact Ciro Santilli". He likes to talk with random people of the Internet.
GitHub | Stack Overflow | LinkedIn | YouTube | Twitter | Wikipedia | Zhihu 知乎 | Weibo 微博 | Other accounts

Besides that, I'm also a freedom of speech slacktivist and recreational cyclist. I like Chinese traditional music and classic Brazilian pop. Opinions are my own, but they could be yours too. Tax the rich.
Let's create an educational system with:
- no distinction between university and high school, students just go as fast as they can to what they really want without stupid university entry exams
- fully open source learning material
- on-demand examinations that anyone can easily take without prerequisites
- granular entry selection only for space in specific laboratories or participation in specific novel research projects
I offer:
- online private tutoring for:
- any STEM university course
- passionate younger STEM students (any age) who want to learn university level material and beyond. Can your kid be the next Fields Medalist or Nobel Prize winner? I'm here to help, especially if you are filthy rich! I focus moving students forward as fast as they want on and on producing useful novel tutorials and results
Let your child be my Emile, and me be their Adolfo Amidei, and let's see how far they can go! I will help take your child:and achieve their ambitious STEM goals!- into the best universities
- into the best PhD programs
- educational consulting for institutions looking to improve their STEM courses
- do you know that course or teacher that consistently gets bad reviews every year? I'll work with the teacher to turn the problem around!
- are you looking to create a consistent open educational resources offering to increase your institutions internationally visibility? I can help with that too.
My approach is to:For minors, parents are welcome to join video calls, and all interactions with the student will be recorded and made available to parents.
- propose interesting research projects. The starting point is always deciding the end goal: Section "Backward design"
- learn what is needed to do the project together with the student(s)
- publish any novel results or tutorials/tools produced freely licensed online, and encourage the student to do the same (Section "Let students learn by teaching", digital garden)
I have a proven track of explaining complex concepts in an interesting and useful way. I work for the learner. Teaching statement at: Section "How to teach". Pricing to be discussed. Contact details at: Section "How to contact Ciro Santilli".
I am particularly excited about pointing people to the potential next big things, my top picks these days are:I am also generally interested in:
- quantum computing
- AGI research, in particular AI code generation, automated theorem proving and robotics
- assorted molecular biology technologies
- 20th century physics, notably AMO and condensed matter
- the history of science, and in particular trying to look at seminal papers of a field

The problem with education by Ciro Santilli
. Source. In this video Ciro Santilli exposes his fundamental philosophy regarding why Education is broken. This philosophy was the key motivation behind the failed OurBigBook Project.Introduction to the OurBigBook Project
. Source. OurBigBook Web topics demo
. Source. The OurBigBook topic feature allows users to "merge their minds" in a "sort by upvote"-stack overflow-like manner for each subject. This is the killer feature of OurBigBook Web. More information at: docs.ourbigbook.com/ourbigbook-web-topics.OurBigBook dynamic article tree demo
. Source. The OurBigBook dynamic tree feature allows any of your headers to be the toplevel h1 header of a page, while still displaying its descendants. SEO loves this, and it also allows users to always get their content on the correct granularity. More information at: docs.ourbigbook.com/ourbigbook-web-dynamic-article-tree.OurBigBook local editing and publishing demo
. Source. With OurBigBook you can store your content as plaintext files in a Lightweight markup, and then publish that to either OurBigBook.com to get awesome multi-user features, or as a static website where you are in full control. More information at: docs.ourbigbook.com/publish-your-content.Top Down 2D continuous game with Urho3D C++ SDL and Box2D for Reinforcement learning by Ciro Santilli (2018)
Source. More information: Section "Ciro's 2D reinforcement learning games". This is Ciro's underwhelming stab at the fundamental question: Can AGI be trained in simulations?. This project could be taken much further.
-------------------------------------
| Force of Will 3 U U |
| --------------------------------- |
| | //////////// | |
| | ////() ()\////\ | |
| | ///_\ (--) \///\ | |
| | ) //// \_____///\\ | |
| | ) \ / / / / | |
| | ) / \ | | / _/ | |
| | ) \ ( ( / / / / \ | |
| | / ) ( ) / ( )/( ) \ | |
| | \(_)/(_)/ /UUUU \ \\\/ | | |
| .---------------------------------. |
| Interrupt |
| ,---------------------------------, |
| | You may pay 1 life and remove a | |
| | blue card in your hand from the | |
| | game instead of paying Force of | |
| | Will's casting cost. Effects | |
| | that prevent or redirect damage | |
| | cannot be used to counter this | |
| | loss of life. | |
| | Counter target spell. | |
| `---------------------------------` |
| l
| Illus. Terese Nelsen |
-------------------------------------Code 1. .
Artist unknown, uploaded December 2014. Part of Section "Cool data embedded in the Bitcoin blockchain" where Ciro Santilli maintains a curated list of such interesting inscriptions.
This was a small project done by Ciro for artistic purposes that received some attention due to the incredible hype surrounding cryptocurrencies at the time. Ciro Santilli's views on cryptocurrencies are summarized at: Section "Are cryptocurrencies useful?".

YellowRobot.jpgJPG image fully embedded in the Bitcoin blockchain depicting some kind of cut material art depicting a yellow robot, inscribed on January 29, 2017.
Ciro Santilli found this image and others during his research for Section "Cool data embedded in the Bitcoin blockchain" by searching for image fingerprints on every transaction payload of the blockchain with a script.
The image was uploaded by EMBII, co-creator of the AtomSea & EMBII upload mechanism, which was responsible for a large part of the image inscriptions in the Bitcoin blockchain.
The associated message reads:This is one of Ciro Santilli's favorite AtomSea & EMBII uploads, as it perfectly encapsules the "medium as an art form" approach to blockchain art, where even non-novel works can be recontextualized into something interesting, here depicting an opposition between the ephemeral and the immutable.
Chiharu [EMBII's Japanese wife] and I found this little yellow robot while exploring Chicago. It will be covered by tar or eventually removed but this tribute will remain. N 41.880778 E -87.629210
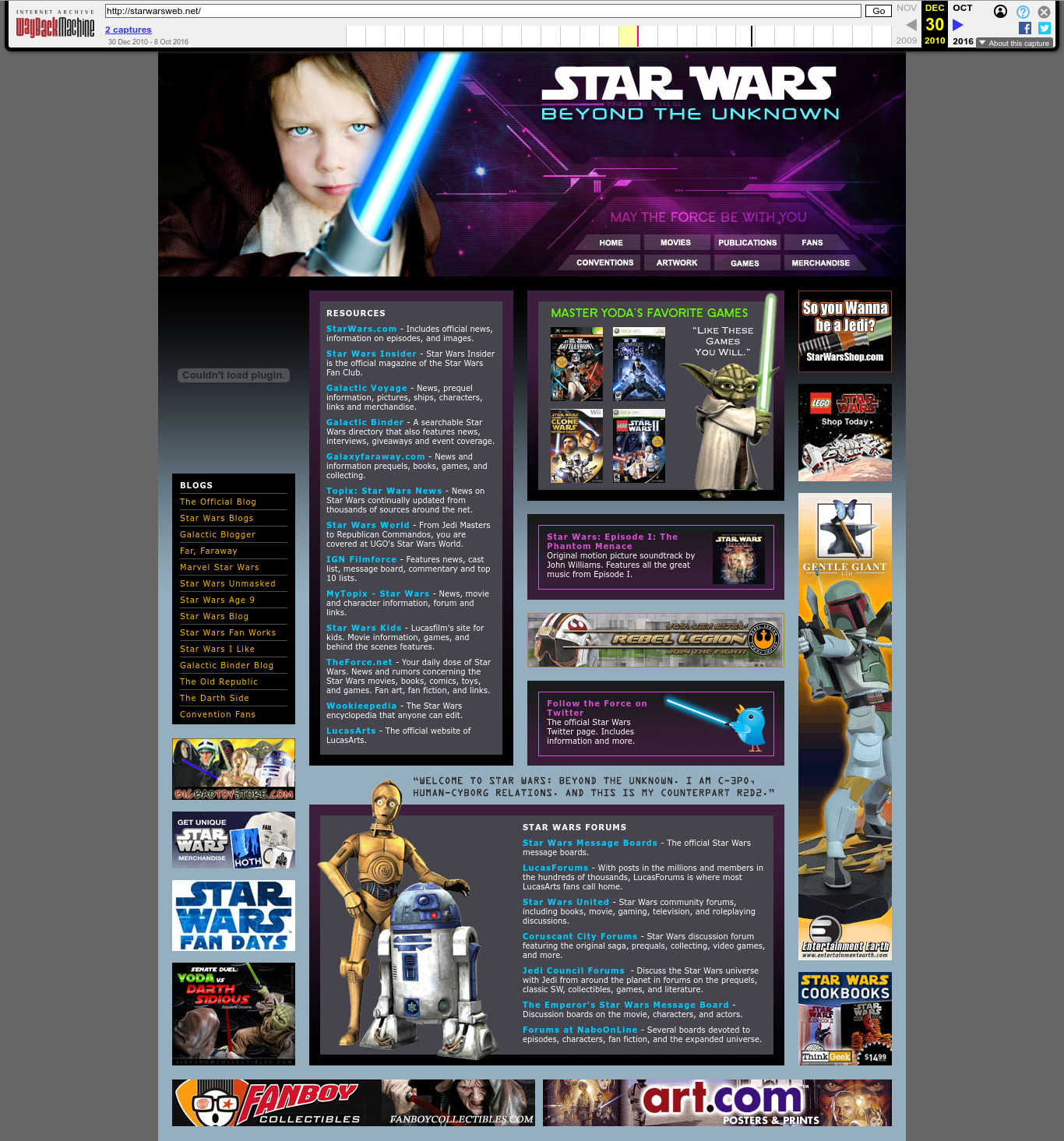
2010 Wayback Machine archive of starwarsweb.net
. This website was used as one of the CIA 2010 covert communication websites, a covert system the CIA used to communicate with its assets. More details at: Section "CIA 2010 covert communication websites".
Ciro Santilli had some naughty OSINT fun finding some of the websites of this defunct network in 2023 after he heard about the 2022 Reuters report on the matter, which for the first time gave away 7 concrete websites out of a claimed 885 total found. As of November 2023, Ciro had found about 350 of them.

2010 Wayback Machine archive of noticiasmusica.net
. This is another website that was used as one of the CIA 2010 covert communication websites. This website is written in Brazilian Portuguese, and therefore suggests that the CIA had assets in Brazil at the time, and thus was spying on a "fellow democracy".
Although Snowden's revelations made it extremely obvious to the world that the USA spies upon everyone outside of the Five Eyes, including fellow democracies, it is rare to have such a direct a concrete proof of it visible live right on the Wayback Machine. Other targeted democracies include France, Germany, Italy and Spain. More details at: USA spying on its own allies.
This investigative report by Ciro Santilli was featured on the Daily Mail after 404 Media reported on it in 2025.

Diagram of the fundamental theorem on homomorphisms by Ciro Santilli (2020)
Shows the relationship between group homomorphisms and normal subgroups.
Used in the Stack Exchange answer to What is the intuition behind normal subgroups? One of Section "The best articles by Ciro Santilli".

Spacetime diagram illustrating how faster-than-light travel implies time travel by Ciro Santilli (2021)
Used in the Stack Exchange answer to Does faster than light travel imply travelling back in time?. One of Section "The best articles by Ciro Santilli".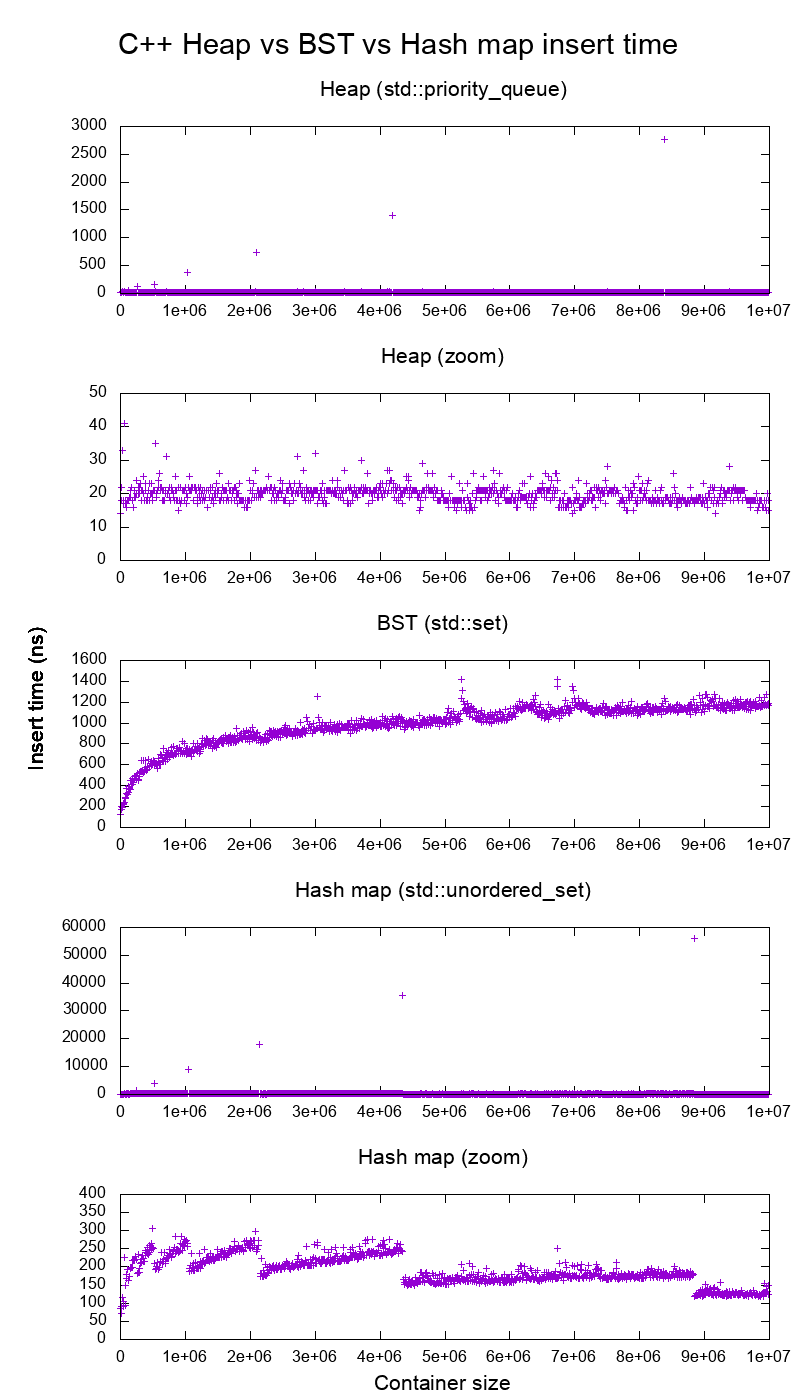
Average insertion time into heaps, binary search tree and hash maps of the C++ standard library by Ciro Santilli (2015)
Source. Used in the Stack Overflow answer to Heap vs Binary Search Tree (BST). One of Section "The best articles by Ciro Santilli".
Top view of an open Oxford Nanopore MinION
. Source. This is Ciro Santilli's hand on the Wikipedia article: en.wikipedia.org/wiki/Oxford_Nanopore_Technologies. He put it there after working a bit on Section "How to use an Oxford Nanopore MinION to extract DNA from river water and determine which bacteria live in it" :-) And he would love to document more experiments like that one Section "Videos of all key physics experiments", but opportunities are extremely rare.A quick 2D continuous AI game prototype for reinforcement learning written in Matter.js, you can view it on a separate page at cirosantilli.com/_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport. This is a for-fun-only prototype for Ciro's 2D reinforcement learning games, C++ or maybe Python (for the deep learning ecosystem) seems inevitable for a serious version of such a project. But it is cute how much you can do with a few lines of Matter.js!
HTML snippet:
<iframe src="_raw/js/matterjs/examples.html#top-down-asdw-fixed-viewport" width="1000" height="850"></iframe> The best articles by Ciro Santilli Updated 2025-07-16
These are the best articles ever authored by Ciro Santilli, most of them in the format of Stack Overflow answers.
Ciro posts update about new articles on his Twitter accounts.
Some random generally less technical in-tree essays will be present at: Section "Essays by Ciro Santilli".
- Trended on Hacker News:
- CIA 2010 covert communication websites on 2023-06-11. 190 points, a mild success.
- x86 Bare Metal Examples on 2019-03-19. 513 points. The third time something related to that repo trends. Hacker news people really like that repo!
- again 2020-06-27 (archive). 200 points, repository traffic jumped from 25 daily unique visitors to 4.6k unique visitors on the day
- How to run a program without an operating system? on 2018-11-26 (archive). 394 points. Covers x86 and ARM
- ELF Hello World Tutorial on 2017-05-17 (archive). 334 points.
- x86 Paging Tutorial on 2017-03-02. Number 1 Google search result for "x86 Paging" in 2017-08. 142 points.
- x86 assembly
- What does "multicore" assembly language look like?
- What is the function of the push / pop instructions used on registers in x86 assembly? Going down to memory spills, register allocation and graph coloring.
- Linux kernel
- What do the flags in /proc/cpuinfo mean?
- How does kernel get an executable binary file running under linux?
- How to debug the Linux kernel with GDB and QEMU?
- Can the sys_execve() system call in the Linux kernel receive both absolute or relative paths?
- What is the difference between the kernel space and the user space?
- Is there any API for determining the physical address from virtual address in Linux?
- Why do people write the
#!/usr/bin/envpython shebang on the first line of a Python script? - How to solve "Kernel Panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)"?
- Single program Linux distro
- QEMU
- gcc and Binutils:
- How do linkers and address relocation works?
- What is incremental linking or partial linking?
- GOLD (
-fuse-ld=gold) linker vs the traditional GNU ld and LLVM ldd - What is the -fPIE option for position-independent executables in GCC and ld? Concrete examples by running program through GDB twice, and an assembly hello world with absolute vs PC relative load.
- How many GCC optimization levels are there?
- Why does GCC create a shared object instead of an executable binary according to file?
- C/C++: almost all of those fall into "disassemble all the things" category. Ciro also does "standards dissection" and "a new version of the standard is out" answers, but those are boring:
- What does "static" mean in a C program?
- In C++ source, what is the effect of
extern "C"? - Char array vs Char Pointer in C
- How to compile glibc from source and use it?
- When should
static_cast,dynamic_cast,const_castandreinterpret_castbe used? - What exactly is
std::atomicin C++?. This answer was originally more appropriately entitled "Let's disassemble some stuff", and got three downvotes, so Ciro changed it to a more professional title, and it started getting upvotes. People judge books by their covers. notmain.o 0000000000000000 0000000000000017 W MyTemplate<int>::f(int) main.o 0000000000000000 0000000000000017 W MyTemplate<int>::f(int)Code 1.. From: What is explicit template instantiation in C++ and when to use it?nmoutputs showing that objects are redefined multiple times across files if you don't use template instantiation properly
- IEEE 754
- What is difference between quiet NaN and signaling NaN?
- In Java, what does NaN mean?
Without subnormals: +---+---+-------+---------------+-------------------------------+ exponent | ? | 0 | 1 | 2 | 3 | +---+---+-------+---------------+-------------------------------+ | | | | | | v v v v v v ----------------------------------------------------------------- floats * **** * * * * * * * * * * * * ----------------------------------------------------------------- ^ ^ ^ ^ ^ ^ | | | | | | 0 | 2^-126 2^-125 2^-124 2^-123 | 2^-127 With subnormals: +-------+-------+---------------+-------------------------------+ exponent | 0 | 1 | 2 | 3 | +-------+-------+---------------+-------------------------------+ | | | | | v v v v v ----------------------------------------------------------------- floats * * * * * * * * * * * * * * * * * ----------------------------------------------------------------- ^ ^ ^ ^ ^ ^ | | | | | | 0 | 2^-126 2^-125 2^-124 2^-123 | 2^-127
- Computer science
- Algorithms
- Is it necessary for NP problems to be decision problems?
- Polynomial time and exponential time. Answered focusing on the definition of "exponential time".
- What is the smallest Turing machine where it is unknown if it halts or not?. Answer focusing on "blank tape" initial condition only. Large parts of it are summarizing the Busy Beaver Challenge, but some additions were made.
- Algorithms
- Git
| 0 | 4 | 8 | C | |-------------|--------------|-------------|----------------| 0 | DIRC | Version | File count | ctime ...| 0 | ... | mtime | device | 2 | inode | mode | UID | GID | 2 | File size | Entry SHA-1 ...| 4 | ... | Flags | Index SHA-1 ...| 4 | ... |tree {tree_sha} {parents} author {author_name} <{author_email}> {author_date_seconds} {author_date_timezone} committer {committer_name} <{committer_email}> {committer_date_seconds} {committer_date_timezone} {commit message}- How do I clone a subdirectory only of a Git repository?
- Python
- Web technology
- OpenGL
- Node.js
- Ruby on Rails
- POSIX
- What is POSIX? Huge classified overview of the most important things that POSIX specifies.
- Systems programming
- What do the terms "CPU bound" and "I/O bound" mean?
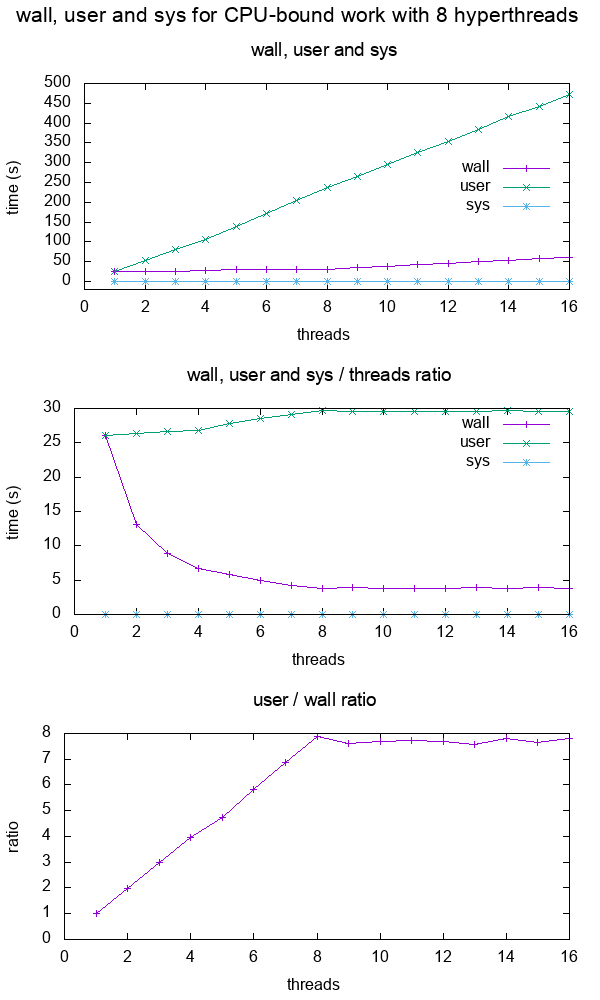
Figure 12. Plot of "real", "user" and "sys" mean times of the output of time for CPU-bound workload with 8 threads. Source. From: What do 'real', 'user' and 'sys' mean in the output of time?+--------+ +------------+ +------+ | device |>---------------->| function 0 |>----->| BAR0 | | | | | +------+ | |>------------+ | | | | | | | +------+ ... ... | | |>----->| BAR1 | | | | | | +------+ | |>--------+ | | | +--------+ | | ... ... ... | | | | | | | | +------+ | | | |>----->| BAR5 | | | +------------+ +------+ | | | | | | +------------+ +------+ | +--->| function 1 |>----->| BAR0 | | | | +------+ | | | | | | +------+ | | |>----->| BAR1 | | | | +------+ | | | | ... ... ... | | | | | | +------+ | | |>----->| BAR5 | | +------------+ +------+ | | | ... | | | +------------+ +------+ +------->| function 7 |>----->| BAR0 | | | +------+ | | | | +------+ | |>----->| BAR1 | | | +------+ | | ... ... ... | | | | +------+ | |>----->| BAR5 | +------------+ +------+Code 5.Logical struture PCIe device, functions and BARs. From: What is the Base Address Register (BAR) in PCIe?
- Electronics
- Raspberry Pi

Figure 13. . Image from answer to: How to hook up a Raspberry Pi via Ethernet to a laptop without a router? 
Figure 14. . Image from answer to: How to hook up a Raspberry Pi via Ethernet to a laptop without a router? 
Figure 15. . Image from answer to: How to emulate the Raspberry Pi 2 on QEMU? 
Figure 16. . Image from answer to: How to run a C program with no OS on the Raspberry Pi?
- Raspberry Pi
- Computer security
- Media
Video 2. . Source. The original question was deleted, lol...: How to programmatically synthesize music?- How to resize a picture using ffmpeg's sws_scale()?
- Is there any decent speech recognition software for Linux? ran a few examples manually on
vosk-apiand compared to ground truth.
- Eclipse
- Computer hardware
- Scientific visualization software
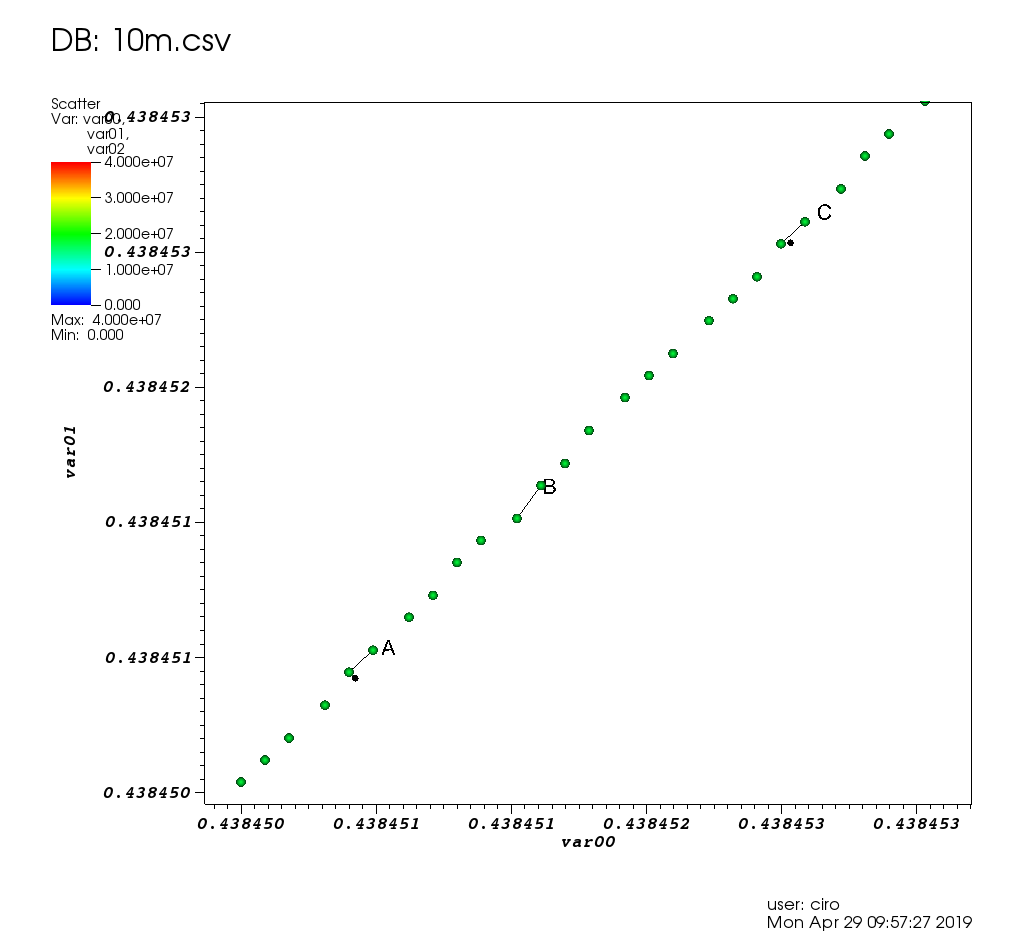
Figure 17. VisIt zoom in 10 million straight line plot with some manually marked points. Source. From: Section "Survey of open source interactive plotting software with a 10 million point scatter plot benchmark by Ciro Santilli"
- Numerical analysis
Video 3. Real-time heat equation OpenGL visualization with interactive mouse cursor using relaxation method by Ciro Santilli (2016)Source.
- Computational physics
- Register transfer level languages like Verilog and VHDL
- Verilog:

Figure 19. . See also: Section "Verilator interactive example"
- Verilog:
- Android
- Debugging
- Program optimization
- What is tail call optimization?

Figure 21. . Source. The answer compares gprof, valgrind callgrind, perf and gperftools on a single simple executable.
- Data
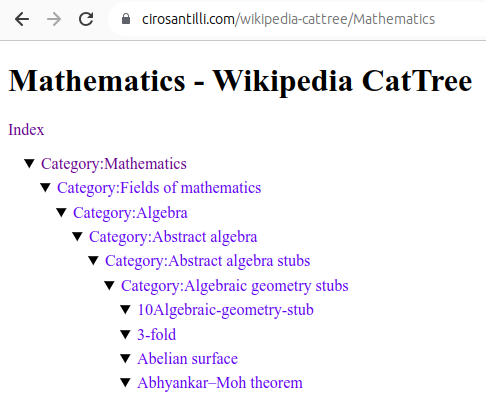
Figure 22. Mathematics dump of Wikipedia CatTree. Source. In this project, Ciro Santilli explored extracting the category and article tree out of the Wikipedia dumps.
- Mathematics
Figure 23. Diagram of the fundamental theorem on homomorphisms by Ciro Santilli (2020)Shows the relationship between group homomorphisms and normal subgroups.- Section "Formalization of mathematics": some early thoughts that could be expanded. Ciro almost had a stroke when he understood this stuff in his teens.

Figure 24. Simple example of the Discrete Fourier transform. Source. That was missing from Wikipedia page: en.wikipedia.org/wiki/Discrete_Fourier_transform!
- Network programming
- Physics
- Biology
- Quantum computing
- Section "Quantum computing is just matrix multiplication"

Figure 28. Visualization of the continuous deformation of states as we walk around the Bloch sphere represented as photon polarization arrows. From: Understanding the Bloch sphere.
- Bitcoin
- GIMP

Figure 29. GIMP screenshot part of how to combine two images side-by-side in GIMP?.
- Home DIY

Figure 30. Total_Blackout_Cassette_Roller_Blind_With_Curtains.Source. From: Section "How to blackout your window without drilling"
- China








Compile Linux kernel for Ubuntu Created 2025-05-07 Updated 2025-07-16
This section describes our attempts at compiling the Linux kernel for Ubuntu so as to use the exact patches and build configuration as used for a given Ubuntu release. The same toolchain would also be ideal, but perhaps this would require a Linux distribution buildable from source.
canonical-kteam-docs.readthedocs-hosted.com/en/public/how-to/build-kernel.html seems promising it says that for Ubuntu 24.04 and above you should do the following which was tested on Ubuntu 24.10:
sudo cp /etc/apt/sources.list /etc/apt/sources.list~
sudo sed -Ei 's/^# deb-src /deb-src /' /etc/apt/sources.list
sudo apt-get update
sudo apt build-dep -y linux linux-image-unsigned-$(uname -r)
sudo apt install -y fakeroot llvm libncurses-dev dwarves
apt source linux-image-unsigned-$(uname -r)
~/tmp/ubuntu/linux-6.11.0
cd linux-6.11.0
chmod a+x debian/rules
chmod a+x debian/scripts/*
chmod a+x debian/scripts/misc/*
fakeroot debian/rules clean
fakeroot debian/rules binaryThe build is extremely slow compared to a build of a more embedded and specifically targeted minimal kernel, and took about 2 hours on P14s. Their philosophy is likely to enable as many drivers as possible so that a single download will work for everyone. Which makes sense, fair enough. It would be cute though if there was a smarter way. Oh well.
linux-6.11.0/debian/build/build-generic How computers work? Updated 2025-07-16
A computer is a highly layered system, and so you have to decide which layers you are the most interested in studying.
Although the layer are somewhat independent, they also sometimes interact, and when that happens it usually hurts your brain. E.g., if compilers were perfect, no one optimizing software would have to know anything about microarchitecture. But if you want to go hardcore enough, you might have to learn some lower layer.
It must also be said that like in any industry, certain layers are hidden in commercial secrecy mysteries making it harder to actually learn them. In computing, the lower level you go, the more closed source things tend to become.
But as you climb down into the abyss of low level hardcoreness, don't forget that making usefulness is more important than being hardcore: Figure 1. "xkcd 378: Real Programmers".
First, the most important thing you should know about this subject: cirosantilli.com/linux-kernel-module-cheat/should-you-waste-your-life-with-systems-programming
Here's a summary from low-level to high-level:
- semiconductor physical implementation this level is of course the most closed, but it is fun to try and peek into it from any openings given by commercials and academia:
- photolithography, and notably photomask design
- register transfer level
- interactive Verilator fun: Is it possible to do interactive user input and output simulation in VHDL or Verilog?
- more importantly, and much harder/maybe impossible with open source, would be to try and set up a open source standard cell library and supporting software to obtain power, performance and area estimates
- Are there good open source standard cell libraries to learn IC synthesis with EDA tools? on Quora
- the most open source ones are some initiatives targeting FPGAs, e.g. symbiflow.github.io/, www.clifford.at/icestorm/
- qflow is an initiative targeting actual integrated circuits
- microarchitecture: a good way to play with this is to try and run some minimal userland examples on gem5 userland simulation with logging, e.g. see on the Linux Kernel Module Cheat:This should be done at the same time as books/website/courses that explain the microarchitecture basics.
- instruction set architecture: a good approach to learn this is to manually write some userland assembly with assertions as done in the Linux Kernel Module Cheat e.g. at:
- github.com/cirosantilli/linux-kernel-module-cheat/blob/9b6552ab6c66cb14d531eff903c4e78f3561e9ca/userland/arch/x86_64/add.S
- cirosantilli.com/linux-kernel-module-cheat/x86-userland-assembly
- learn a bit about calling conventions, e.g. by calling C standard library functions from assembly:
- you can also try and understand what some simple C programs compile to. Things can get a bit hard though when
-O3is used. Some cute examples:
- executable file format, notably executable and Linkable Format. Particularly important is to understand the basics of:
- address relocation: How do linkers and address relocation work?
- position independent code: What is the -fPIE option for position-independent executables in GCC and ld?
- how to observe which symbols are present in object files, e.g.:
- how C++ uses name mangling What is the effect of extern "C" in C++?
- how C++ template instantiation can help reduce link time and size: Explicit template instantiation - when is it used?
- operating system. There are two ways to approach this:
- learn about the Linux kernel Linux kernel. A good starting point is to learn about its main interfaces. This is well shown at Linux Kernel Module Cheat:
- system calls
- write some system calls in
- pure assembly:
- C GCC inline assembly:
- write some system calls in
- learn about kernel modules and their interfaces. Notably, learn about to demystify special files such
/dev/randomand so on: - learn how to do a minimal Linux kernel disk image/boot to userland hello world: What is the smallest possible Linux implementation?
- learn how to GDB Step debug the Linux kernel itself. Once you know this, you will feel that "given enough patience, I could understand anything that I wanted about the kernel", and you can then proceed to not learn almost anything about it and carry on with your life
- system calls
- write your own (mini-) OS, or study a minimal educational OS, e.g. as in:
- learn about the Linux kernel Linux kernel. A good starting point is to learn about its main interfaces. This is well shown at Linux Kernel Module Cheat:
- programming language

Human brain Updated 2025-07-16
Ciro Santilli feels it is not for his generation though, and that is one of the philosophical things that saddens him the most in this world.
On the other hand, Ciro's playing with the Linux kernel and other complex software which no single human can every fully understand cheer him up a bit. But still, the high level view, that we can have...
For now, Ciro's 2D reinforcement learning games.
Linux insides Updated 2025-07-16
Documents the Linux kernel. Somewhat of a competitor to Linux Kernel Module Cheat, but more wordy and less automated.
Linux Kernel Module Cheat Updated 2025-07-16
This is the most important technical tutorial project that Ciro Santilli has done in his life so far as of 2019.
The scope is insane and unprecedented, and goes beyond Linux kernel-land alone, which is where it started.
It ended up eating every system programming content Ciro had previously written! Including:
so that that repo would better be called "System Programming Cheat". But "Linux Kernel Module Cheat" sounds more hardcore ;-)
Other major things that could be added there as well in the future are:
- github.com/cirosantilli/algorithm-cheat
- computer architecture tutorials with gem5
Due to this project, some have considered Ciro to be (archive):which made Ciro smile, although "Linux kernel documenter God" would have been more precise.
some kind of Linux kernel god.
[ 1.451857] input: AT Translated Set 2 keyboard as /devices/platform/i8042/s1│loading @0xffffffffc0000000: ../kernel_modules-1.0//timer.ko
[ 1.454310] ledtrig-cpu: registered to indicate activity on CPUs │(gdb) b lkmc_timer_callback
[ 1.455621] usbcore: registered new interface driver usbhid │Breakpoint 1 at 0xffffffffc0000000: file /home/ciro/bak/git/linux-kernel-module
[ 1.455811] usbhid: USB HID core driver │-cheat/out/x86_64/buildroot/build/kernel_modules-1.0/./timer.c, line 28.
[ 1.462044] NET: Registered protocol family 10 │(gdb) c
[ 1.467911] Segment Routing with IPv6 │Continuing.
[ 1.468407] sit: IPv6, IPv4 and MPLS over IPv4 tunneling driver │
[ 1.470859] NET: Registered protocol family 17 │Breakpoint 1, lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 1.472017] 9pnet: Installing 9P2000 support │ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 1.475461] sched_clock: Marking stable (1473574872, 0)->(1554017593, -80442)│kernel_modules-1.0/./timer.c:28
[ 1.479419] ALSA device list: │28 {
[ 1.479567] No soundcards found. │(gdb) c
[ 1.619187] ata2.00: ATAPI: QEMU DVD-ROM, 2.5+, max UDMA/100 │Continuing.
[ 1.622954] ata2.00: configured for MWDMA2 │
[ 1.644048] scsi 1:0:0:0: CD-ROM QEMU QEMU DVD-ROM 2.5+ P5│Breakpoint 1, lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 1.741966] tsc: Refined TSC clocksource calibration: 2904.010 MHz │ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 1.742796] clocksource: tsc: mask: 0xffffffffffffffff max_cycles: 0x29dc0f4s│kernel_modules-1.0/./timer.c:28
[ 1.743648] clocksource: Switched to clocksource tsc │28 {
[ 2.072945] input: ImExPS/2 Generic Explorer Mouse as /devices/platform/i8043│(gdb) bt
[ 2.078641] EXT4-fs (vda): couldn't mount as ext3 due to feature incompatibis│#0 lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 2.080350] EXT4-fs (vda): mounting ext2 file system using the ext4 subsystem│ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 2.088978] EXT4-fs (vda): mounted filesystem without journal. Opts: (null) │kernel_modules-1.0/./timer.c:28
[ 2.089872] VFS: Mounted root (ext2 filesystem) readonly on device 254:0. │#1 0xffffffff810ab494 in call_timer_fn (timer=0xffffffffc0002000 <mytimer>,
[ 2.097168] devtmpfs: mounted │ fn=0xffffffffc0000000 <lkmc_timer_callback>) at kernel/time/timer.c:1326
[ 2.126472] Freeing unused kernel memory: 1264K │#2 0xffffffff810ab71f in expire_timers (head=<optimized out>,
[ 2.126706] Write protecting the kernel read-only data: 16384k │ base=<optimized out>) at kernel/time/timer.c:1363
[ 2.129388] Freeing unused kernel memory: 2024K │#3 __run_timers (base=<optimized out>) at kernel/time/timer.c:1666
[ 2.139370] Freeing unused kernel memory: 1284K │#4 run_timer_softirq (h=<optimized out>) at kernel/time/timer.c:1692
[ 2.246231] EXT4-fs (vda): warning: mounting unchecked fs, running e2fsck isd│#5 0xffffffff81a000cc in __do_softirq () at kernel/softirq.c:285
[ 2.259574] EXT4-fs (vda): re-mounted. Opts: block_validity,barrier,user_xatr│#6 0xffffffff810577cc in invoke_softirq () at kernel/softirq.c:365
hello S98 │#7 irq_exit () at kernel/softirq.c:405
│#8 0xffffffff818021ba in exiting_irq () at ./arch/x86/include/asm/apic.h:541
Apr 15 23:59:23 login[49]: root login on 'console' │#9 smp_apic_timer_interrupt (regs=<optimized out>)
hello /root/.profile │ at arch/x86/kernel/apic/apic.c:1052
# insmod /timer.ko │#10 0xffffffff8180190f in apic_timer_interrupt ()
[ 6.791945] timer: loading out-of-tree module taints kernel. │ at arch/x86/entry/entry_64.S:857
# [ 7.821621] 4294894248 │#11 0xffffffff82003df8 in init_thread_union ()
[ 8.851385] 4294894504 │#12 0x0000000000000000 in ?? ()
│(gdb) Mailing list Updated 2025-07-16
The only explanation is that the dinosaurs who created the projects are unable to adapt to new superior technologies.
Yes, Ciro is talking to you, big fundamental projects from last century: Linux kernel, GNU Compiler Collection (gcc.gnu.org/lists.html), Binutils (sourceware.org/binutils/), etc.
Some of you are already using Bugzilla for the bugs, so kudos. But if you've seen their benefit, why you still use the mailing list for patches?
Advantages of mailing lists:
- threaded replies, which almost no issue tracker has. GitHub feature request: github.com/isaacs/github/issues/837
Disadvantages: everything else:
- cannot subscribed to a single thread. Which forces you to create an email filter for each one of them you subscribe to.
- no metadata, notably the notion of closing / merging, but also upvotesYou have to read thirty messages before you can know if the bug was solved or not.
- it is insanely hard to reply to messages from before you were subscribed: webapps.stackexchange.com/questions/23197/reply-to-mailman-archived-message/115088#115088
- hard to apply patches locally to test them out: stackoverflow.com/questions/5062389/how-to-use-git-am-to-apply-patches-from-email-messages/49082916#49082916Unless they use Patchwork, which adds one more website on top of the mess.And then Gmail corrupts your patches, and you are forced to use
git send-email, which does not work on some network configurations: stackoverflow.com/questions/28038662/how-to-solve-unable-to-initialize-smtp-properly-when-using-using-git-send-ema or setup ThunderBird. - often have to subscribe to post at all, thus cluttering your inbox further
- you can edit posts to make them clearer.Yes, people could vandalize their answers when they get mad, and threads might stop making sense after edits. But this can be solved with an undeletable post history like Stack Overflow has (but not any other tracker does).Or archive.org :-)In any case, what do you think will happen more often and have greater impact:
- people vandalize their posts
- people fix their silly typos and improve content
- searchable by author, keyword, etc. without Google. Yes, mailing list trackers could have decent implementations to overcome that. But no, GNU Mailman which everyone uses does not have it. Google barely indexes it.
- people have to learn about top posting vs inline posting, and this requires infinite education of new users
- On mailing lists: either put a comment in the middle of a huge patch and let other people find it, or (more likely) copy paste the part of the patch that you are talking about.
- most mail web UIs suck.OK, this is not an unsolvable or intrinsic problem, but still a problem.E.g.:
ezmlmit is not possible to see the entire content in a single page: gcc.gnu.org/ml/gcc/2015-07/threads.html.The alternative: do like LLVM and send attachments. Yes, I we all love opening up attachments on our browsers.The real solution: everyone can create branches and pull requests. Also has the benefit of running CI on the pull requests.
Not sure:
- you can have infinitely many trackers to replicate data in case apocalypse happens in some part of the world.Although I'm not sure this is an advantage, as you don't know anymore which one is the canonical trackers an advantage, as you don't know anymore which one is the canonical tracker.And all web interfaces already have an API to export messages, and someone has already scripted it to import from any web UI to any web UI for you.
Node (server) Updated 2025-07-16
It runs one instance of the Linux kernel and has one IP address. Each node is therefore a complete computer. As such is must also contain RAM memory, disk storage and a network interface controller.
The Linux kernel responds to ICMP directly Updated 2025-07-16
There is no userland process for it, it is handled directly by the Linux kernel: unix.stackexchange.com/questions/439801/what-linux-process-is-responsible-for-responding-to-pings/768739#768739
I shouldn't be doing this on funded OurBigBook time which is until the end of May, but I was getting too nervous and decided to start a casual job search to test the waters.
In particular I want to see if I can get past the HR lady step without toning down my online profiles. If nothing works out for the next round I'll be hiding anything too spicy like:Another interesting point is to see if French companies are more likely to reply given that Ciro Santilli studied at École Polytechnique which the French worship.
- prominently seeking funding for OurBigBook on my LinkedIn profile
- CIA 2010 covert communication websites references. This will be my first job hunt since I have published that article. Wish me luck.
- gay Putin profile picture on Stack Overflow

Gay Putin, currently used in Ciro Santilli's Stack Overflow profile
. Ciro's profiles may be a bit too much for the HR ladies who reject his job applications on the spot. To be fair, perhaps not enough years of experience for certain applications and job hopping may have something to do with it too. But since they don't ever tell you anything not to get sued, we'll never know.I'm looking in particular either for:
- machine learning-adjacent jobs in companies that seem to be doing something that could further AGI, e.g. automatic code generation or robotics would be ideal
- quantum computing
- systems programming, which is what I actually have work experience with
I spent the last two weeks doing that:
- one week browsing everything of interest in London and Paris and sending applications to anything that seemed both relevant and interesting. Maintaining an application list at: Section "Job application by Ciro Santilli".
- one week on a very laborious but somewhat interesting take home exercise for Linux kernel engineer a Canonical, makers of Ubuntu.I had a week to finish 5 practical coding and packaging questions, and I tried to do everything as perfectly as possible, but I somewhat underestimated the amount of work and wait needed to do everything and didn't manage to finish question 4 and missed 5. Oops let's see how that goes.At least this had a few good outcomes for the Internet as I tried to document things as nicely as I could where they were missing from Google as usual:
- I re-tested Linux Kernel Module Cheat and made some small improvements. Things still worked from a Ubuntu 24.10 host (using Docker to Ubuntu 22.04), and I also checked that kernel 6.8 builds and GDB step debugs after adding the newly required config
CONFIG_DEBUG_INFO_DWARF_TOOLCHAIN_DEFAULT, also mentioned that at: Why are there no debug symbols in my vmlinux when using gdb with /proc/kcore? - I contributed some simple updates to github.com/martinezjavier/ldd3 getting it closer to work on Linux kernel v6.8. That repository aims to keep the venerable examples from Linux kernel module book LDD3 alive on newer kernels, and is a very good source for kernel module developers.
- How to compile a Linux kernel module?: wrote a quick Ciro-approved tutorial
- Dynamic array in Linux kernel module: I gave an educational example of a dynamic byte array (like std::string) using the kvmalloc family of allocators
- quickemu: this is a good emulator manager and I think I'll be using it for Ubuntu images when needed from now on. I wrote:
- How to run Ubuntu desktop on QEMU?: an introductory tutorial to the software as their README is not that good as is often the case. It's hard for project authors to predict what new users want or not. This is my second answer to this question, the previous one focusing on a more manual approach without third party helpers.
- How to share folder between guest/host? (Quickemu): I explained how to setup a 9p mount to share a directory between guest and host
- Error :: You must put some 'source' URIs in your sources.list: updated this answer for Ubuntu 24.04. This issue comes up when you want to do either of:which don't work by default, and my answer explains how to do it from the GUI and CLI. The CLI method is specially important for Docker images. Since Ubuntu doesn't offer a stable CLI method for this, the method breaks from time to time and we have to find the new config file to edit.
sudo apt build-dep sudo apt source - What is hardware enablement (HWE)?: I learned a bit better how Ubuntu structures its kernel releases for each Ubuntu release
Some of the main issues I had were:- compiling Linux kernel for Ubuntu is extremely slow. I was used to compiling for embedded system with Buildroot, which finishes in minutes, but for Ubuntu is hours, presumably because they enable as many drivers as possible to make a single ISO work on as many different computers as possible, which makes sense, but also makes development harder
- my QEMU setup for Ubuntu was not quite as streamlined and I relearned a few things and set up quickemu. By chance I had recently come across quickemu for testing OurBigBook on MacOS, but I had to learn a bit how to set it up reasonably too
- I re-tested Linux Kernel Module Cheat and made some small improvements. Things still worked from a Ubuntu 24.10 host (using Docker to Ubuntu 22.04), and I also checked that kernel 6.8 builds and GDB step debugs after adding the newly required config

Updates Two Linux Kernel Module Cheat videos Created 2025-05-13 Updated 2025-07-16
I made not one but two quick presentation videos about my project Linux Kernel Module Cheat, an emulation setup to study and develop the Linux kernel and more:
- www.youtube.com/watch?v=HDJFyCma32U: a presentation of me talking about it, edited up from my earlier presentation at Aratu Week 2024
- www.youtube.com/watch?v=fgDhe1tN50o: a demo of me running actually the project
I had meant to do this editing for a while and kept pushing it off because editing hurts, but finally sat down did it, partly prompted by my quick recent updates made to the projects part of post OurBigBook job search round 2025. At first I was thinking of making a single video, but after I recorded the demo a bit it seemed like two separate ones would make more sense.
I also created a bug report for Kdenlive, the video editor that I used, for a freeze that happens if you try to shift + delete the last item of the timeline: bugs.kde.org/show_bug.cgi?id=504103. Kdenlive is a good editor, but unfortunately it has new freezes and crashes relatively often.
One more useless task that I get off my head, on to the next!
Linux Kernel Module Cheat presentation
. Source. Linux Kernel Module Cheat demo
. Source. User mode emulation Updated 2025-07-16
User mode emulation refers to the ability of certain emulators to emulate userland code running on top of a specific operating system, usually Linux.
For example, QEMU allows you to run a variety of userland ELF programs directly on it, without an underlying Linux kernel running.
User mode emulation is achieved by implementing system calls and special filesystems such as
/dev manually on the emulator one by one.The general tradeoff is that simulation is less acurate as it may lack certain highly advanced kernel functionality you haven't implemented yet. But it is much easier to run executables with it, and you don't have to wait for boot to finish before running, you just run executables directly from the command line.
x86 Paging Tutorial Application Updated 2025-07-16
Paging makes it easier to compile and run two programs or threads at the same time on a single computer.
For example, when you compile two programs, the compiler does not know if they are going to be running at the same time or not.
And thread stacks, that must be contiguous and keep growing down until they overwrite each other, are an even bigger issue!
But if two programs use the same address and run at the same time, this is obviously going to break them!
Paging solves this problem beautifully by adding one degree of indirection:
(logical) ------------> (physical)
pagingWhere:
As far as programs are concerned, they think they can use any address between 0 and 4 GiB (2^32,
FFFFFFFF) on 32-bit systems.The OS then sets up paging so that identical logical addresses will go into different physical addresses and not overwrite each other.
This makes it much simpler to compile programs and run them at the same time.
Paging achieves that goal, and in addition:
- the switch between programs is very fast, because it is implemented by hardware
- the memory of both programs can grow and shrink as needed without too much fragmentation
- one program can never access the memory of another program, even if it wanted to.This is good both for security, and to prevent bugs in one program from crashing other programs.
Or if you like non-funny jokes:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}