
Incoming links: Ubuntu
Aegisub Updated 2025-07-16
First import video with:They don't have an
aegisub-3.2 ourbigbook-parent.mkvaegisub executable without the version number. Amazing.If you already have a subtitle file that you want to edit, then just pass it on as well:
aegisub-3.2 ourbigbook-parent.mkv ourbigbook-parent.assEnter: finish editing the current entry and start a new one.
The best articles by Ciro Santilli Updated 2025-07-16
These are the best articles ever authored by Ciro Santilli, most of them in the format of Stack Overflow answers.
Ciro posts update about new articles on his Twitter accounts.
Some random generally less technical in-tree essays will be present at: Section "Essays by Ciro Santilli".
- Trended on Hacker News:
- CIA 2010 covert communication websites on 2023-06-11. 190 points, a mild success.
- x86 Bare Metal Examples on 2019-03-19. 513 points. The third time something related to that repo trends. Hacker news people really like that repo!
- again 2020-06-27 (archive). 200 points, repository traffic jumped from 25 daily unique visitors to 4.6k unique visitors on the day
- How to run a program without an operating system? on 2018-11-26 (archive). 394 points. Covers x86 and ARM
- ELF Hello World Tutorial on 2017-05-17 (archive). 334 points.
- x86 Paging Tutorial on 2017-03-02. Number 1 Google search result for "x86 Paging" in 2017-08. 142 points.
- x86 assembly
- What does "multicore" assembly language look like?
- What is the function of the push / pop instructions used on registers in x86 assembly? Going down to memory spills, register allocation and graph coloring.
- Linux kernel
- What do the flags in /proc/cpuinfo mean?
- How does kernel get an executable binary file running under linux?
- How to debug the Linux kernel with GDB and QEMU?
- Can the sys_execve() system call in the Linux kernel receive both absolute or relative paths?
- What is the difference between the kernel space and the user space?
- Is there any API for determining the physical address from virtual address in Linux?
- Why do people write the
#!/usr/bin/envpython shebang on the first line of a Python script? - How to solve "Kernel Panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)"?
- Single program Linux distro
- QEMU
- gcc and Binutils:
- How do linkers and address relocation works?
- What is incremental linking or partial linking?
- GOLD (
-fuse-ld=gold) linker vs the traditional GNU ld and LLVM ldd - What is the -fPIE option for position-independent executables in GCC and ld? Concrete examples by running program through GDB twice, and an assembly hello world with absolute vs PC relative load.
- How many GCC optimization levels are there?
- Why does GCC create a shared object instead of an executable binary according to file?
- C/C++: almost all of those fall into "disassemble all the things" category. Ciro also does "standards dissection" and "a new version of the standard is out" answers, but those are boring:
- What does "static" mean in a C program?
- In C++ source, what is the effect of
extern "C"? - Char array vs Char Pointer in C
- How to compile glibc from source and use it?
- When should
static_cast,dynamic_cast,const_castandreinterpret_castbe used? - What exactly is
std::atomicin C++?. This answer was originally more appropriately entitled "Let's disassemble some stuff", and got three downvotes, so Ciro changed it to a more professional title, and it started getting upvotes. People judge books by their covers. notmain.o 0000000000000000 0000000000000017 W MyTemplate<int>::f(int) main.o 0000000000000000 0000000000000017 W MyTemplate<int>::f(int)Code 1.. From: What is explicit template instantiation in C++ and when to use it?nmoutputs showing that objects are redefined multiple times across files if you don't use template instantiation properly
- IEEE 754
- What is difference between quiet NaN and signaling NaN?
- In Java, what does NaN mean?
Without subnormals: +---+---+-------+---------------+-------------------------------+ exponent | ? | 0 | 1 | 2 | 3 | +---+---+-------+---------------+-------------------------------+ | | | | | | v v v v v v ----------------------------------------------------------------- floats * **** * * * * * * * * * * * * ----------------------------------------------------------------- ^ ^ ^ ^ ^ ^ | | | | | | 0 | 2^-126 2^-125 2^-124 2^-123 | 2^-127 With subnormals: +-------+-------+---------------+-------------------------------+ exponent | 0 | 1 | 2 | 3 | +-------+-------+---------------+-------------------------------+ | | | | | v v v v v ----------------------------------------------------------------- floats * * * * * * * * * * * * * * * * * ----------------------------------------------------------------- ^ ^ ^ ^ ^ ^ | | | | | | 0 | 2^-126 2^-125 2^-124 2^-123 | 2^-127
- Computer science
- Algorithms
- Is it necessary for NP problems to be decision problems?
- Polynomial time and exponential time. Answered focusing on the definition of "exponential time".
- What is the smallest Turing machine where it is unknown if it halts or not?. Answer focusing on "blank tape" initial condition only. Large parts of it are summarizing the Busy Beaver Challenge, but some additions were made.
- Algorithms
- Git
| 0 | 4 | 8 | C | |-------------|--------------|-------------|----------------| 0 | DIRC | Version | File count | ctime ...| 0 | ... | mtime | device | 2 | inode | mode | UID | GID | 2 | File size | Entry SHA-1 ...| 4 | ... | Flags | Index SHA-1 ...| 4 | ... |tree {tree_sha} {parents} author {author_name} <{author_email}> {author_date_seconds} {author_date_timezone} committer {committer_name} <{committer_email}> {committer_date_seconds} {committer_date_timezone} {commit message}- How do I clone a subdirectory only of a Git repository?
- Python
- Web technology
- OpenGL
- Node.js
- Ruby on Rails
- POSIX
- What is POSIX? Huge classified overview of the most important things that POSIX specifies.
- Systems programming
- What do the terms "CPU bound" and "I/O bound" mean?
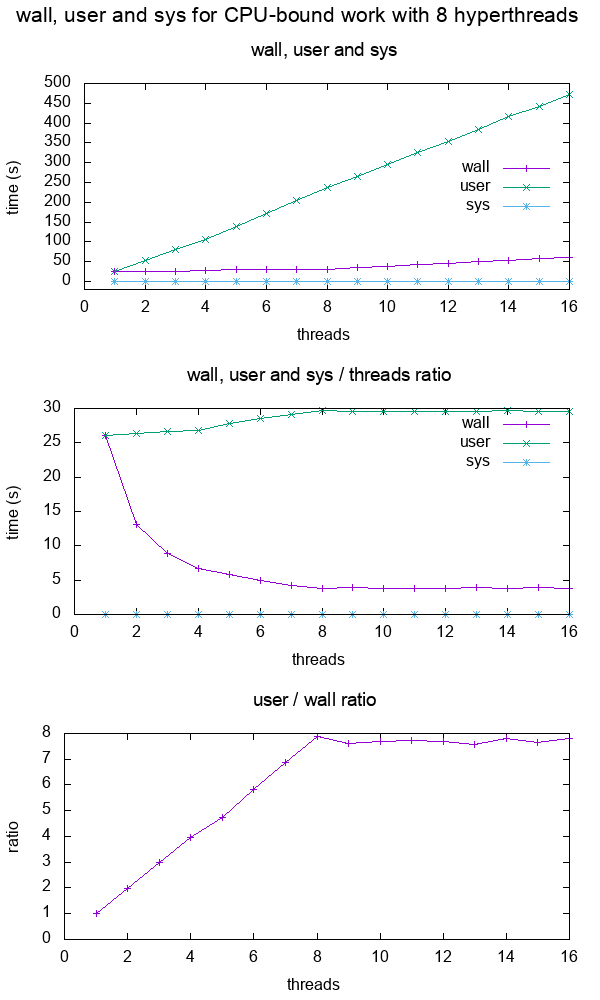
Figure 12. Plot of "real", "user" and "sys" mean times of the output of time for CPU-bound workload with 8 threads. Source. From: What do 'real', 'user' and 'sys' mean in the output of time?+--------+ +------------+ +------+ | device |>---------------->| function 0 |>----->| BAR0 | | | | | +------+ | |>------------+ | | | | | | | +------+ ... ... | | |>----->| BAR1 | | | | | | +------+ | |>--------+ | | | +--------+ | | ... ... ... | | | | | | | | +------+ | | | |>----->| BAR5 | | | +------------+ +------+ | | | | | | +------------+ +------+ | +--->| function 1 |>----->| BAR0 | | | | +------+ | | | | | | +------+ | | |>----->| BAR1 | | | | +------+ | | | | ... ... ... | | | | | | +------+ | | |>----->| BAR5 | | +------------+ +------+ | | | ... | | | +------------+ +------+ +------->| function 7 |>----->| BAR0 | | | +------+ | | | | +------+ | |>----->| BAR1 | | | +------+ | | ... ... ... | | | | +------+ | |>----->| BAR5 | +------------+ +------+Code 5.Logical struture PCIe device, functions and BARs. From: What is the Base Address Register (BAR) in PCIe?
- Electronics
- Raspberry Pi

Figure 13. . Image from answer to: How to hook up a Raspberry Pi via Ethernet to a laptop without a router? 
Figure 14. . Image from answer to: How to hook up a Raspberry Pi via Ethernet to a laptop without a router? 
Figure 15. . Image from answer to: How to emulate the Raspberry Pi 2 on QEMU? 
Figure 16. . Image from answer to: How to run a C program with no OS on the Raspberry Pi?
- Raspberry Pi
- Computer security
- Media
Video 2. . Source. The original question was deleted, lol...: How to programmatically synthesize music?- How to resize a picture using ffmpeg's sws_scale()?
- Is there any decent speech recognition software for Linux? ran a few examples manually on
vosk-apiand compared to ground truth.
- Eclipse
- Computer hardware
- Scientific visualization software
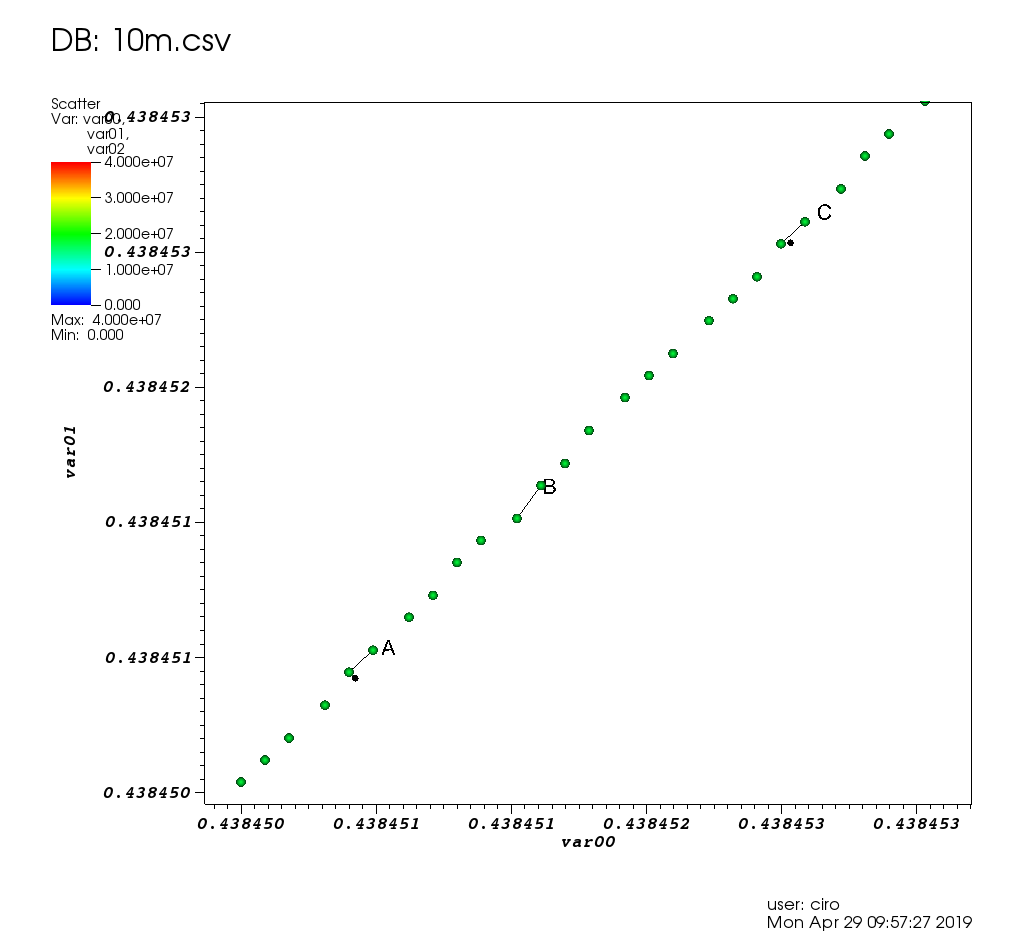
Figure 17. VisIt zoom in 10 million straight line plot with some manually marked points. Source. From: Section "Survey of open source interactive plotting software with a 10 million point scatter plot benchmark by Ciro Santilli"
- Numerical analysis
Video 3. Real-time heat equation OpenGL visualization with interactive mouse cursor using relaxation method by Ciro Santilli (2016)Source.
- Computational physics
- Register transfer level languages like Verilog and VHDL
- Verilog:

Figure 19. . See also: Section "Verilator interactive example"
- Verilog:
- Android
- Debugging
- Program optimization
- What is tail call optimization?

Figure 21. . Source. The answer compares gprof, valgrind callgrind, perf and gperftools on a single simple executable.
- Data
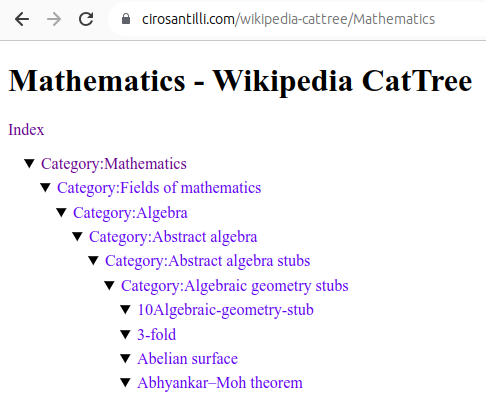
Figure 22. Mathematics dump of Wikipedia CatTree. Source. In this project, Ciro Santilli explored extracting the category and article tree out of the Wikipedia dumps.
- Mathematics

Figure 23. Diagram of the fundamental theorem on homomorphisms by Ciro Santilli (2020)Shows the relationship between group homomorphisms and normal subgroups.- Section "Formalization of mathematics": some early thoughts that could be expanded. Ciro almost had a stroke when he understood this stuff in his teens.

Figure 24. Simple example of the Discrete Fourier transform. Source. That was missing from Wikipedia page: en.wikipedia.org/wiki/Discrete_Fourier_transform!
- Network programming
- Physics
- Biology
- Quantum computing
- Section "Quantum computing is just matrix multiplication"

Figure 28. Visualization of the continuous deformation of states as we walk around the Bloch sphere represented as photon polarization arrows. From: Understanding the Bloch sphere.
- Bitcoin
- GIMP

Figure 29. GIMP screenshot part of how to combine two images side-by-side in GIMP?.
- Home DIY

Figure 30. Total_Blackout_Cassette_Roller_Blind_With_Curtains.Source. From: Section "How to blackout your window without drilling"
- China










Bristol (synthesizer) Updated 2025-07-16
Simulates vintage hardware synthesizers, and includes some pretty complex ones!
Aims to show an UI that looks exactly like the synthesizers in question.
Build bsdgames from source Created 2024-12-13 Updated 2025-07-16
Many of the games are disabled by default on Ubuntu. But we can enable some games and build from source with:
apt-get source bsdgames
cd bsdgames-*
sed -ri '/^bsd_games_cfg_no_build_dirs=/s/ number / /' config.params
./configure
make -jHere we enabled the game number, so now we can:which gives:
number/number 123one hundred twenty-three.We can also "install" it locally with:which puts the games locally under:which you can add to your
make installdebian/bsdgames/usr/games/numberPATH environment variable. Ciro Santilli Updated 2025-07-16
Quick facts:
- Nationalities: Italian and Brazilian
- Grew up in: Brazil
- Relationship status 2017-: married
- Given name pronunciation: take your pick from Ciro Santilli's given name
- Chinese name: 三西猴, means "three western monkeys". Phonetic approximation to SANtilli CIRO. More info at: Ciro Santilli's Chinese name. Semi-unintentionally reminds Chinese people of Sun Wukong (孙悟空). This association is further slightly strengthened by the phonetic choice of 三 San, which Ciro later noticed matches the middle character of Tang Sanzang (唐三藏), the monk in Journey to the West. The given name 西猴 was given by Ciro Santilli's wife, then recent girlfriend, as a semi-joke, and he took it up because the best way to take a joke is to play along with the joker. 三 was chosen by Ciro himself.
- laptop: high end Lenovo ThinkPad
- distro: latest Ubuntu release
- Vim or Emacs: vi/vim. But for The Love, will someone please make an open source C++ integrated development environment that actually just works?
- tabs or spaces: spaces
- Mailing list or Git(Hub|Lab): Git(Hub|Lab), with passion, see Section "Mailing list"
- system or unit tests: system
- programming languages: Python and C++. He'll learn Rust and Haskell once he's rich. As of the 2020s, Rust was picking up some serious steam, so Ciro might end up eating his own words there.
- musical instruments to listen: Chinese Guqin and electric Jazz-fusion guitar
- metric or imperial: metric, for The Love. Science? Standardization? 21st century anyone?
- QWERTY or Dvorak: QWERTY, alas
- birth name: Ciro Duran Santilli
Other people with the same name are listed at Section "Ciro Santilli's homonyms".

Sun Wukong (孙悟空) is a playful and obscenely powerful monkey Journey to the West. He protects Buddhist monk Tang Sanzang, and likes eating fruit, just like Ciro. Oh, and Goku from Dragon Ball is based on him. His japanese name is "Sun Wukong" (same Chinese characters with different Japanese pronunciation) for the love. His given name "Wukong" means literally "the one who mastered the void", which is clearly a Dharma name and fucking awesome in multiple ways. This is another sad instance of a Chinese thing better known in the West as Japanese.
It is worth noting however that although Wukong is extremely charming, Ciro's favorite novel of the Four Great Classic Novels is Water Margin. Journey to the West is just a monster of the week for kids, but Water Margin is a fight for justice saga. Sorry Wukong!

The photo was taken in an open event organized by the awesome Cambridge Synthetic Biology outreach group, more or less the same people who organize: www.meetup.com/Cambridge-Synthetic-Biology-Meetup/ and who helped organize Section "How to use an Oxford Nanopore MinION to extract DNA from river water and determine which bacteria live in it".
Taking part in such activities is what Ciro tries to do to overcome his lifelong regret of not having done more experimental stuff at university. Would he have had the patience to handle all the bullshit of the physical word without going back to the informational sciences? Maybe, maybe not. But now he will probably never know?!
Notice the orange high visibility cycling jersey under the lab coat, from someone who had just ridden in from work as fast as possible as part of his "lunch break". It is more fun when it is hard.

Ciro Santilli fantasizes that he would have make a good scribe in the middle ages, partly due to his self diagnosed graphomania, but also appreciation for foreign languages, and his mild obsession with the natural sciences.
OurBigBook.com is Ciro's view of a modern day scriptorium, except that now the illuminations are YouTube videos.
Chill and eat your bread in peace comes to mind. A scribe, in a library, reading and writing the entire day in peace and quiet. The life!
The job of a Internet-age scribe is basically that of making knowledge more open, legally extracting it from closed copyrighted sources, and explaining your understanding of it to the wider world under Creative Commons licenses on the web. And in the process of greater openness, given a well organized system, we are able combine the knowledge of many different people, and thus make things more understandable than any single/few creator closed source source could ever achieve.


Ciro Santilli waving hello in infrared.
More info at: Figure "Ciro Santilli waving hello in infrared". cirosantilli/parsec-benchmark Created 2024-07-29 Updated 2025-07-16
Ciro Santilli's fork of PARSEC. This fork was made to improve the build system and better support newer targets, including newer Ubuntu and Buildroot.
Ciro Santilli's hardware Lenovo ThinkPad P51 (2017) log Updated 2025-07-16
- battery life:
- 2023-04: on-browser streaming + light browsing on Ubuntu 22.10: about 2h45. Too low! Gotta try buying a new battery.
- 2022-01-04 updated firmward after noticing that ubuntu 21.10 does not wake up from suspend seemed to happen every time when not connected to external power.
dmidecodediff excerpt:used the "Ubuntu Software" GUI as mentioned at: support.lenovo.com/gb/en/solutions/ht510810-how-to-do-software-updates-linux. Kudos for making this accessible to newbs.BIOS Information Vendor: LENOVO - Version: N1UET40W (1.14 ) - Release Date: 09/28/2017 + Version: N1UET71W (1.45 ) + Release Date: 07/18/2018After doing that, another update became available to: 0.1.56, clicked it and was much faster than the previous one, and didn't auto reboot. After manual reboot,dmidecodediffed again:plus a bunch of other lines.BIOS Information Vendor: LENOVO - Version: N1UET71W (1.45 ) - Release Date: 07/18/2018 + Version: N1UET82W (1.56 ) + Release Date: 08/12/2021 - 2021-06-05 upgraded to Ubuntu 21.04 with a clean install from an ISO. SelectedAfter this, the GUI felt fast, who would have thought that erasing a bunch of stuff would make the system faster!
- "Minimal installation"
- "Erase disk and install Ubuntu". Notably, this erased the Microsoft Windows that came with the computer and was never used not even once
- "Erase disk ans use ZFS"
- Encrypt the new Ubuntu installation for security
lsblkcontains:andzd0 230:0 0 500M 0 disk └─keystore-rpool 253:0 0 484M 0 crypt /run/keystore/rpool nvme0n1 259:0 0 476.9G 0 disk ├─nvme0n1p1 259:1 0 512M 0 part /boot/efi ├─nvme0n1p2 259:2 0 2G 0 part │ └─cryptoswap 253:1 0 2G 0 crypt ├─nvme0n1p3 259:3 0 2G 0 part └─nvme0n1p4 259:4 0 472.4G 0 partlsblk -f:zd0 crypto_LUKS 2 └─keystore-rpool ext4 1.0 keystore-rpool nvme0n1 ├─nvme0n1p1 vfat FAT32 ├─nvme0n1p2 crypto_LUKS 2 │ └─cryptoswap ├─nvme0n1p3 zfs_member 5000 bpool └─nvme0n1p4 zfs_member 5000 rpooThen:contains:grep '[rb]pool' /proc/mountswhich gives an idea of how the above map to mountpoints.rpool/ROOT/ubuntu_uvs1fq / zfs rw,relatime,xattr,posixacl 0 0 rpool/USERDATA/ciro_czngbg /home/ciro zfs rw,relatime,xattr,posixacl 0 0 rpool/USERDATA/root_czngbg /root zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/srv /srv zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/usr/local /usr/local zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/games /var/games zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/log /var/log zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/lib /var/lib zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/mail /var/mail zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/snap /var/snap zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/www /var/www zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/spool /var/spool zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/lib/AccountsService /var/lib/AccountsService zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/lib/NetworkManager /var/lib/NetworkManager zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/lib/apt /var/lib/apt zfs rw,relatime,xattr,posixacl 0 0 rpool/ROOT/ubuntu_uvs1fq/var/lib/dpkg /var/lib/dpkg zfs rw,relatime,xattr,posixacl 0 0 bpool/BOOT/ubuntu_uvs1fq /boot zfs rw,nodev,relatime,xattr,posixacl 0 0
2020-06-06: dropped some lemon juice on the bottom left of touchpad. Bottom left button not working anymore... I'm an idiot. There are many other alternatives, but very aggravating, I'll replace it for sure. Can't find the exact replacement part or any videos showing its replacement online easliy, dang. For the T430: www.youtube.com/watch?v=F3lzV9uXRjU Asked at: forums.lenovo.com/t5/ThinkPad-P-and-W-Series-Mobile-Workstations/P51-left-bottom-button-below-trackpad-mouse-left-click-stopped-working-possible-to-replace/m-p/5019903 Also I could not access it because you need to remove the HDD first: www.youtube.com/watch?v=5Klawxc7T_Y and I can't pull it out even with considerable force, unlike in the video... And OMG, those button caps are impossible to re-install once removed!!! Then when I put the whole thing back together, the upper buttons were not working anymore. FUUUUUUUUCK. When first opening I pulled on it without properly removing the cap and it came off, but it didn't look broken in any way and I put it back in. Keyboard works thank God, so right black connector is fine, left white one oppears to be the one for upper keys and trackpoint, both of which stopped working. The hardware manual confirms that they are both part of the same device, so basically a mouse :-) TODO can it be bought separately from te keyboard? Doesn't look like it, photo of keyboard part includes those buttons. The manual also confirms that the bottom buttons are one device with the trackpad "trackpad with buttons", thus forming the second entire mouse.
2019-04-17: popup asking about "ThinkPad P51 Management Engine Update" from from 182.29.3287 to 184.60.3561, said yes.
- partition setup: askubuntu.com/questions/343268/how-to-use-manual-partitioning-during-installation/976430#976430
- BIOS:
- for NVIDIA driver:
- for KVM, required by Android Emulator: enable virtualization extensions
- TODO fix the brightness keys:
Ciro Santilli's hardware Polytechnique USB flash drives Updated 2025-07-16
~8GB,
lsblk reports 7796176 * 1KB = 7983284224 bytes.They are shaped like bicornes, which is super cool, but also super impractical!
Markings: "AX ÉCOLE POLYTECHNIQUE PROMOTION X2009"
From Ubuntu 20.04 on an ext4 formatted one:With Linux Unified Key Setup + ext4 the results are similar, maybe hdparam bypasses it?
/dev/sdb:
Timing cached reads: 28656 MB in 1.99 seconds = 14421.31 MB/sec
SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 0a 00 00 00 00 20 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Timing buffered disk reads: 42 MB in 3.03 seconds = 13.88 MB/sec/dev/sdb:
Timing cached reads: 28326 MB in 1.99 seconds = 14251.55 MB/sec
SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 0a 00 00 00 00 20 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Timing buffered disk reads: 38 MB in 3.11 seconds = 12.23 MB/secgnome-disks LUKS + ext4 benchmark with default params also gives about 14 MB/s. Ciro Santilli's Open Source Enlightenment Updated 2025-07-16
Firstly, in 2012, while he was at École Polytechnique, Ciro Santilli was introduced to LaTeX (thank God for French mathematical obsession), and his mind was blown:he though. Why isn't everyone doing that!
One particular event stood out: Ciro made a small change to his teacher's course material, who blessed be him (dude's a legend, Ciro just noticed he has some Chinese publications with another French dude, e.g. www.amazon.co.uk/高效算法-应试与提高必修128例-克里斯托弗-Christoph-Durr/dp/B078SJQPVK "High-efficiency algorithm competitions 128 examples", did he write it the Chinese himself?? Must be of course to complement the notoriously low French professor salaries), made it available, and then Ciro gave him back the .tex file. Ciro was just a bit worried about how the teacher would be able to tell what he had changed in the file to validate the change. The teacher just said of course, "no problem, I'll just use
diff". Ciro had never heard of diff. Let alone Git of course, though yes, this was a bit early in Git's history version control systems had been around since forever of course. This was 2011 or 2012, about 4 or 5 years into a superior education curricula with various courses involving computers, some requiring quite a lot of "fill these empty functions" style programming. Education is a joke. Anyways, this was a prelude to exactly what Ciro wanted to do in OurBigBook.com. This might have been the one actually: webia.lip6.fr/~durrc/Iut/Notes580.pdfNot long afterwards, Ciro started playing with Linux. Until then, Ciro had had some contacts with the mysterious operating system at university, and was a bit puzzled what the point of it was! He clearly remembers:University should be forced to use only open source software and hardware in undergrad teaching courses by law BTW.
- at the University of São Paulo that they had some "UNIX" computers in some classes, and at the library
- at École Polytechnique, he took a course about mathematical analysis and there was a "lab" where students were supposed to use FreeFem, great initiative BTW. And Ciro distinctly remembers being paried with a nice Chilian colleague, and the guy was alreay super at ease with the shell: "cd", "ls", etc. WTF was all that!
Then came an Ubuntu live disk on his own machine, and finally a measly 40GB dual book partition in a Microsoft Windows machine on a laptop. At first, it took a lot of time to learn all the crazy new terminal stuff! Yes, at this point, Ubuntu was already usable enough without the terminal, an accomplishment actually. But as a programmer, Ciro felt obliged to learn. Many hours were spent reading man pages at the library. But it all just felt so right, and sometimes powerful... true wizardry.
And ten years later, Ciro was seriously considering buying a computer without Windows pre-installed. He had not used Windows a single tie on a personal machine even once in those ten years!
Finally, to finish things off Ciro found two websites that changed his life forever, and made be believe that there was an alternative: Stack Overflow and GitHub.
Ciro Santilli's Stack Overflow contributions Updated 2026-01-30

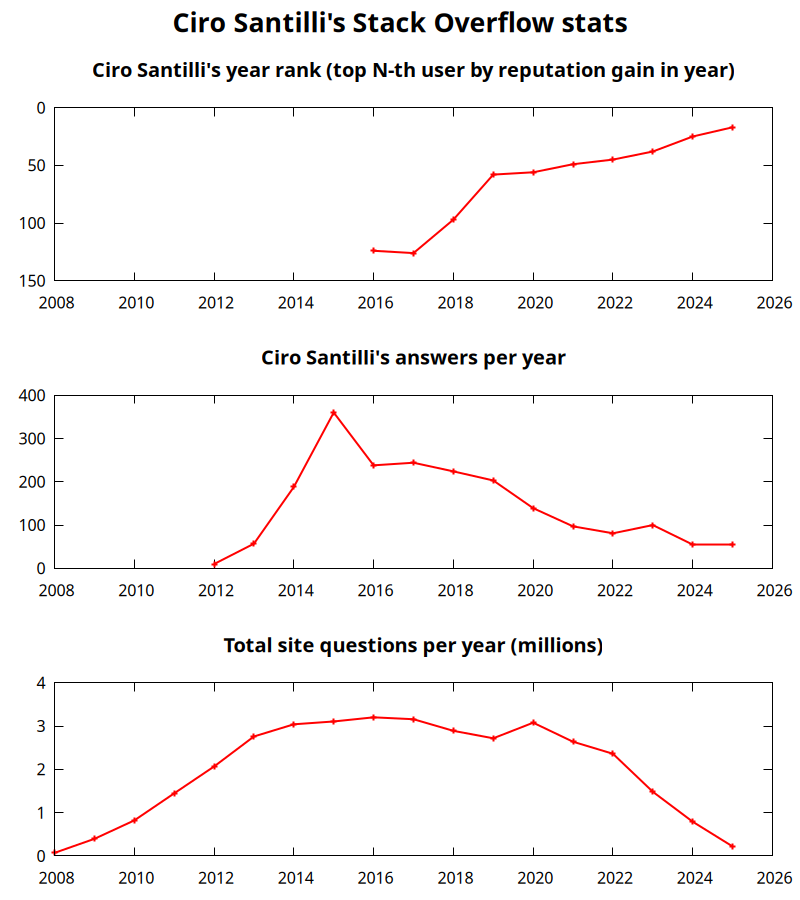
Data compiled for the plot: ciro-santilli-stack-overflow-stats.csv
- top obtained manually from pages such s=as: stackexchange.com/leagues/1/year/stackoverflow/2023-01-01
- answer count obtained with this Stack Exchange Data Explorer data.stackexchange.com/stackoverflow/query/433214/count-of-answers-by-user-over-time?UserId=895245
- total questions obtained with: data.stackexchange.com/stackoverflow/query/1926608/total-questions-asked-per-year-on-stack-overflow
Plot generated with gnuplot with ciro-santilli-stack-overflow-stats.gnuplot
Ciro Santilli's Stack Overflow contributions have, unsurprisingly, centered around the subjects he has worked with: systems programming and web development, and necessary tooling to get those done, such as Git, Python, Bash and Ubuntu.
His best answers are listed at: Section "The best articles by Ciro Santilli".
Stack Overflow has been the initial centerpiece of Ciro Santilli's campaign for freedom of speech in China, until Ciro noticed that GitHub might be potentially even more effective for it.
In Stack Overflow Ciro likes to:
- answer important questions found through Google which he needs to solve an actual problem he has right now, and for which none of the existing answers satisfied him, and close duplicates.
- monitor less known tags which very few people know a lot about and where the knowledge sharing desperately lacking, but in which Ciro specializes and therefore has some uncommon knowledge to share
In practice it also happens that Ciro:
- Googles for his own answers to remember some detail he wrote down but with slightly different terms that were closer to mind at the time, and find other similar questions for which he has the perfect answer.
- learns something new by chance, e.g. some new flashy feature of a new version of the C++ standard, thinks "this is awesome, there must be a Stack Overflow question for it", and then there is a question and he answers it
When he gets an upvote on one of his more obscure answers, Ciro often re-reads it, and often finds improvements to be made and makes them.
He doesn't like to refresh the homepage looking for easy reputation on widely known subjects. See also: online forums that lock threads after some time are evil.
The result is that Ciro ends up getting relatively a lot of reputation without much work! The term passive income, much beloved by fake investment gurus, comes to mind. But now it's "passive reputation"! And it is useless! Yay!
For this reason, Necromancer is Ciro's favorite badge (get 5 upvotes on a question older than 60 days), and as of July 2019, he became the #1 user with the most of this badge. Announcement on Twitter.
The number two at the time was VonC (see also: Section "Epic Stack Overflow users"), who had about 16 times more answers than Ciro in total! From this query: data.stackexchange.com/stackoverflow/query/1072396?&Date=2019-07-01&UserId=895245 it can be seen that as of July 2019, 1216 out of his 1329 answers were answered 60 days after the questions and constitute potential necromancers! Compare that to VonC's 1643 potential necromancers out of 21767 answers!
VonC eventually took back the lead in 2022, dude's a machine!!! twitter.com/cirosantilli/status/1546389532014247936
Someone at Ciro's work once said something along:and this does ring true in Stack Overflow as well. When you are answering stuff, it means that you either didn't know, or that the information wasn't well available, and so your specific application is progressing slowly because of that. Once the generic prerequisites are well solved and answered, you will spend much more time on your business specific things rather than anything else that can be factored out across projects, and so you will get more "directly useful work" done, and less Stack Overflow answers. Of course, without the prior research in place, you can't get the final product done either.
In terms of per year reputation ranks, Ciro was in the top 100 in of the 2018 ranking with 38,710 reputation gained in that year: stackexchange.com/leagues/1/year/stackoverflow/2018-01-01?sort=reputationchange&page=4 (archive). He reached top 50 in 2022. Note that daily reputation is mostly capped to 200 per day, leading to a maximum 73000 per year. It is possible to overcome this limit either with bounties or accepts, and Ciro finds it amazing that some people actually break the 73k limit by far with accepts, e.g. Gordon Linoff reached 135k in 2018 (archive)! However, this is something that Ciro will never do, because it implies answering thousands and thousands of useless semi duplicate questions as fast as possible to get the accept. Ciro's reputation comes purely from upvotes on important question, and is therefore sustainable without any extra effort once achieved. Interestingly, Ciro appeared on top of the quarter SE rankings around 2019-11: web.archive.org/web/20191112100606/https://stackexchange.com/leagues but it was just a bug ;-)
There is no joy like answering an old question, and watching your better answer go up little by little until it dominates all others.
Stack Overflow reputation is of course, in itself, meaningless. People who contribute to popular subjects like web development will always have infinitely more reputation than those that contribute to low level subjects.
What happens on the specialized topics though is that you end up getting to know all the 5 users who contribute 95% of the content pretty soon as you study those subjects.
Like everything that man does, the majority of Ciro's answers are more or less superficial subjects that many people know but few have the patience to explain well, or they are updates to important questions reflecting upstream developments. But as long as they save 15 minutes from someone's life, that's fine.
There is great beauty when you are involved in a programming problem, and you suddenly remember: wait, I answered something related a few years ago! And especially so when you can go back and improve your old answer with new insight. This has great value, because when you were more newbie, you would have typed different words into Google Search than you would now. So by updating posts from when you were a newbie, you are helping other newbies more, as they are more likely to be also searching for those keywords. It is also very nice to have some head start on the answer's upvote count and not have to bootstrap yet another answer from 0 upvotes and have to go through all the competition!
For example, Ciro's most upvoted answer as of July 2019 is stackoverflow.com/questions/18875674/whats-the-difference-between-dependencies-devdependencies-and-peerdependencies/22004559#22004559 was written when he spent his first week playing with NodeJS (he was having a look at Overleaf, later merged into Overleaf, for education), which he didn't touch again for several years, and still hasn't "mastered" as of 2019! This did teach a concrete life lesson to Ciro however: it is impossible to know what is the most useful thing you can do right now very precisely. The best bet is to follow your instincts and do as much awesome stuff as you can, and then, with some luck, some of those attempts will cover an use case.
Ciro tends to take most pride on his systems programming answers, which is a subject that truly relatively few people know about. He likes it when he goes insanely deep into a subject, way beyond what OP had in mind, exposing full root causes and broader causes, see e.g.:
- stackoverflow.com/questions/1778538/how-many-gcc-optimization-levels-are-there/30308151#30308151
- stackoverflow.com/questions/34519521/why-does-gcc-create-a-shared-object-instead-of-an-executable-binary-according-to/55704865#55704865
- stackoverflow.com/questions/8352535/how-does-kernel-get-an-executable-binary-file-running-under-linux/31394861#31394861
Ciro also derives great joy from his "media related answers" (3D graphics, audio, video), which are immensely fun to write, and sometimes borderline art, see answers such as those under "OpenGL" and "Media" under the best articles by Ciro Articles or even simpler answers such as:

There is something of greater value in perfectly presented technical knowledge, that goes beyond than simply getting something done. The pleasure of understanding and mastering something, and perhaps of the explanation itself. Sometimes when answering, Ciro feels like a tailor, where ASCII is his cloth. See also: Section "The art of programming", Section "Physics and the illusion of life".
Ciro's deep understanding of Stack Overflow mechanisms and its shortcomings also helped shape his ideas for: OurBigBook.com. So it is a bit funny to think that after all time Ciro spent on the website, he actually wants to destroy it and replace it with something better. There can be no innovation without some damage. It also led to Ciro's creation of Stack Overflow Vote Fraud Script.
After answering so many questions, he ended up converging to a more or less consistent style, which he formalized at:Like any other style guide, this answer style guide, once fully incorporated and memorized, allows Ciro to write answers faster, without thinking about formatting issues.
- meta.stackexchange.com/questions/18614/style-guide-for-questions-and-answers/326746#326746. Key self-quote:
- meta.stackexchange.com/questions/10647/how-do-i-write-a-good-title/311903#311903. Question title style only. After a few years later more people agreeing with that post which now had -12 votes: meta.stackoverflow.com/questions/422082/should-we-add-option-use-complete-sentences-to-first-answers-queue
Ciro also made a question title style guide: meta.stackexchange.com/questions/10647/how-do-i-write-a-good-title/311903#311903 but for some reason the Stack Overflow community prefers their semi-defined title meta-language to proper English. Go figure.
Ciro started contributing to Stack Overflow in 2012 when he was at École Polytechnique.
Like all things that end up shaping the course of one's life, Ciro started contributing without thinking too much about it.
His first answer was to the LaTeX question: Standalone diagrams with TikZ?, which reflects the fact that this happened while Ciro was reaching his Ciro Santilli's Open Source Enlightenment.
Ciro's first upvote was for his 2012 question: How to run a Python script portably without specifying its full path?
When he started contributing, Ciro was still a newbie. One early event he will never forget was when someone mentioned a "man page", and Ciro commented saying that there was a typo!
When Ciro reached 15 points and gained the ability to upvote, it felt like a major milestone, he even took a screenshot of the browser! 1k, 10k and 100k were also particularly exciting. When the 100k cup (archive) arrived in 2018, Ciro made a show-off Facebook post (archive). At some point though, your brain stops caring, and automatically filters out any upvotes you get except on the answers that you are really proud of and which don't yet have lots of upvotes. The last remaining useless gamed achievement that Ciro looked forward to was legendary (archive), and which he achieved on 2021-02-16.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
From the start, Ciro's motivations for contributing to Stack Overflow have been a virtuous circle of:
- save the world through free education
- It feels especially amazing when people in the real world start taking note of you, and either close friends tell you straight out that you're a Stack Overflow God, or as you slowly and indirectly find out that less close know or came to you due to your amazing contributions.
It is also amazing when you start having a repertoire of answers, and as you are writing a new answer, you remember: "hey, the knowledge of that answer would be so welcome here", and so you link to the other answer as well at the perfect point. This somewhat achieves does what OurBigBook.com aims to do: for each small section of a tutorial, gather the best answers by multiple people.
Another one is Aaron Hall, who is also very high on the necromancer list, answers in Python which is a topic Ciro cares about, and states on his profile:so another necromancer.
Follow me on Twitter and tell me what canonical questions you would like me to respond to!
Way to go.
Ciro also asks some questions on a ratio of about 1 question per 10 answers. But Ciro's questions tend to be about extremely niche that no one knows/cares about, and a high percentage of them ends up getting self answered either at asking time or after later research.
Some fun reactions to Ciro's Stack Overflow activity:
- Eric B comments[ref] on Ciro's answer to the question "What does multicore assembly language look like?":
Holy shit, Ciro made it his masters degree to write OP an answer. What a long and detailed answer, thanks!
Compile Linux kernel for Ubuntu Created 2025-05-07 Updated 2025-07-16
This section describes our attempts at compiling the Linux kernel for Ubuntu so as to use the exact patches and build configuration as used for a given Ubuntu release. The same toolchain would also be ideal, but perhaps this would require a Linux distribution buildable from source.
canonical-kteam-docs.readthedocs-hosted.com/en/public/how-to/build-kernel.html seems promising it says that for Ubuntu 24.04 and above you should do the following which was tested on Ubuntu 24.10:
sudo cp /etc/apt/sources.list /etc/apt/sources.list~
sudo sed -Ei 's/^# deb-src /deb-src /' /etc/apt/sources.list
sudo apt-get update
sudo apt build-dep -y linux linux-image-unsigned-$(uname -r)
sudo apt install -y fakeroot llvm libncurses-dev dwarves
apt source linux-image-unsigned-$(uname -r)
~/tmp/ubuntu/linux-6.11.0
cd linux-6.11.0
chmod a+x debian/rules
chmod a+x debian/scripts/*
chmod a+x debian/scripts/misc/*
fakeroot debian/rules clean
fakeroot debian/rules binaryThe build is extremely slow compared to a build of a more embedded and specifically targeted minimal kernel, and took about 2 hours on P14s. Their philosophy is likely to enable as many drivers as possible so that a single download will work for everyone. Which makes sense, fair enough. It would be cute though if there was a smarter way. Oh well.
linux-6.11.0/debian/build/build-generic Csound Updated 2025-07-16
XML file format (but with 99% of the action of interest in a domain-specific language on the
CsInstruments and CsScore elements) that can be played and the reference implementation. Offers complex effects out-of-box apparently.Allows you to easily define instruments with seemingly arbitrary mathematical functions, and then use them to play notes at given time intervals.
The instrument functions can be parametrized, and each note played can have different parameters.
The instrument definition actually defines a block diagram graph, much like a hardware synthesizer would.
Csound is so not-bloated that it contains an UI system. And it includes an interactive virtual MIDI keyboard that interacts with parameter knobs: www.csounds.com/manual/html/MidiTop.html
But hey, it's fun. And like any other good domain-specific language, debugging it is barbaric of course.
If only it had been written in Python... the array manipulation boilerplate would be likely perfect for NumPy, and this would have been exactly what Ciro Santilli wanted!
CSound states that one of its design goals is backward compatibility, and it shows. Some of the stuff is utterly arcane, e.g. you have to remember what
GEN10, GEN11, etc. mean instead of having named enums.It just worked on Ubuntu 20.04 no questions asked:which runs this file: github.com/csound/csound/blob/92409ecce053d707360a5794f5f4f6bf5ebf5d24/examples/xanadu.csd and this plays a relly cool sound demo:
sudo apt install csound
git clone https://github.com/csound/csound
cd csound
git checkout 92409ecce053d707360a5794f5f4f6bf5ebf5d24
csound examples/xanadu.csdSave to file instead of playing:or direct ogg output:or pipe to stdout to FFmpeg TODO: stackoverflow.com/questions/64970503/how-to-pipe-csound-output-to-ffmpeg-for-conversion-without-an-intermediate-file
csound -o xanadu.wav xanadu.csdcsound --ogg -o xanadu.ogg xanadu.csdTODO find the most amazing set of songs made with it on GitHub? Some examples:
- www.csounds.com/toots/index.html has a good 101 on instrument design
- Csound FLOSS manual
- iainmccurdy.org/csound.html about 100 CC BY-SA examples. Each is a minimal study showing a specific technique, not a full composition, some seem advanced. Dude's a beast.
- github.com/csound/csound/tree/f2e70825fb543a6b15011c6984371f61ab2a00dd/tests/soak in-tree minimal examples
- github.com/csound/manual/tree/4049b286493d972ff7248b5596e47e7ae97a0cf9/examples contains the examples for the manual which is rendered at: It's insane, but it's fun! Ah those newbs who separate manuals from main tree.
- linuxsynths.com/CsoundPatchesDemos/csound.html on LinuxSynths
- github.com/csound/examples/tree/ae578159328178142c1055c7f78e28b42eb29774/csd as a few dozen examples
- freaknet.org/martin/audio/csound/ 10 pieces with source
Documentation-wise, it's a bit lacking. The only dude who can explain it really well, Dr Richard Boulanger, made the "The Csound Book" closed source, so, congrats, this will forever hurt the popularity of Csound.
Examples:
- csound/sine.csd
- csound/amplitude_frequency.csd
- csound/linen.csd: simple attack/release envelope, documented at: www.csounds.com/manual/html/linen.html
- csound/chorus.csd: chorus effect
- csound/bend.csd: bend using
linseg - csound/vibrato.csd
- csound/crossfade_generators.csd
- csound/table.csd
- csound/virtual_keyboard.csd
Csound FLOSS manual Updated 2025-07-16
Includes introduction to the basic sound synthesis and their implementation in Csound.
Examples run on browser via Emscripten and just worked on Ubuntu 20.04!
Examples can also be downloaded all at once from: www.csound-tutorial.net/floss_manual/ Shame not in Git as standalone files.
E. Coli Whole Cell Model by Covert Lab Updated 2025-07-16
github.com/CovertLab/WholeCellEcoliRelease is a whole cell simulation model created by Covert Lab and other collaborators.
The project is written in Python, hurray!
But according to te README, it seems to be the use a code drop model with on-request access to master. Ciro Santilli asked at rationale on GitHub discussion, and they confirmed as expected that it is to:
- to prevent their publication ideas from being stolen. Who would steal publication ideas with public proof in an issue tracker without crediting original authors? Academia is broken. Academia should be the most open form of knowledge sharing. But instead we get this silly competition for publication points.
- to prevent noise from non-collaborators. But they only get like 2 issues as year on such a meganiche subject... Did you know that you can ignore people, and even block them if they are particularly annoying? Much more likely is that no one will every hear about your project and that it will die with its last graduate student slave.
The project is a followup to the earlier M. genitalium whole cell model by Covert lab which modelled Mycoplasma genitalium. E. Coli has 8x more genes (500 vs 4k), but it the undisputed bacterial model organism and as such has been studied much more thoroughly. It also reproduces faster than Mycoplasma (20 minutes vs a few hours), which is a huge advantages for validation/exploratory experiments.
The project has a partial dependency on the proprietary optimization software CPLEX which is freeware, for students, not sure what it is used for exactly, from the comment in the
requirements.txt the dependency is only partial.This project makes Ciro Santilli think of the E. Coli as an optimization problem. Given such external nutrient/temperature condition, which DNA sequence makes the cell grow the fastest? Balancing metabolites feels like designing a Factorio speedrun.
There is one major thing missing thing in the current model: promoters/transcription factor interactions are not modelled due to lack/low quality of experimental data: github.com/CovertLab/WholeCellEcoliRelease/issues/21. They just have a magic direct "transcription factor to gene" relationship, encoded at reconstruction/ecoli/flat/foldChanges.tsv in terms of type "if this is present, such protein is expressed 10x more". Transcription units are not implemented at all it appears.
Everything in this section refers to version 7e4cc9e57de76752df0f4e32eca95fb653ea64e4, the code drop from November 2020, and was tested on Ubuntu 21.04 with a docker install of
docker.pkg.github.com/covertlab/wholecellecolirelease/wcm-full with image id 502c3e604265, unless otherwise noted. E. Coli Whole Cell Model by Covert Lab Install and first run Updated 2025-07-16
At 7e4cc9e57de76752df0f4e32eca95fb653ea64e4 you basically need to use the Docker image on Ubuntu 21.04 due to pip breaking changes... (not their fault). Perhaps pyenv would solve things, but who has the patience for that?!?!
The Docker setup from README does just work. The image download is a bit tedius, as it requires you to create a GitHub API key as described in the README, but there must be reasons for that.
Once the image is downloaded, you really want to run is from the root of the source tree:This mounts the host source under The meaning of each of the analysis commands is described at Section "Output overview".
sudo docker run --name=wcm -it -v "$(pwd):/wcEcoli" docker.pkg.github.com/covertlab/wholecellecolirelease/wcm-full/wcEcoli, so you can easily edit and view output images from your host. Once inside Docker we can compile, run the simulation, and analyze results with:make clean compile &&
python runscripts/manual/runFitter.py &&
python runscripts/manual/runSim.py &&
python runscripts/manual/analysisVariant.py &&
python runscripts/manual/analysisCohort.py &&
python runscripts/manual/analysisMultigen.py &&
python runscripts/manual/analysisSingle.pyAs a Docker refresher, after you stop the container, e.g. by restarting your computer or running
sudo docker stop wcm, you can get back into it with:sudo docker start wcm
sudo docker run -it wcm bashrunscripts/manual/runFitter.py takes about 15 minutes, and it generates files such as reconstruction/ecoli/dataclasses/process/two_component_system.py (related) which is required to run the simulation, it is basically a part of the build.runSim.py does the main simulation, progress output contains lines of type:Time (s) Dry mass Dry mass Protein RNA Small mol Expected
(fg) fold change fold change fold change fold change fold change
======== ======== =========== =========== =========== =========== ===========
0.00 403.09 1.000 1.000 1.000 1.000 1.000
0.20 403.18 1.000 1.000 1.000 1.000 1.000 2569.18 783.09 1.943 1.910 2.005 1.950 1.963
Simulation finished:
- Length: 0:42:49
- Runtime: 0:09:13 EPUB Updated 2025-07-16
This is a good thing. It basically contains an entire website, with HTML and assets inside a single ZIP, and a little bit of metadata.
It is incomprehensible why browsers don't just implement it as they already have all the web part, and also ZIP stuff:
GHDL Updated 2025-07-16
Examples under vhdl.
Run all examples, which have assertions in them:
cd vhdl
./runFiles:
- Examples
- Basic
- vhdl/hello_world_tb.vhdl: hello world
- vhdl/min_tb.vhdl: min
- vhdl/assert_tb.vhdl: assert
- Lexer
- vhdl/comments_tb.vhdl: comments
- vhdl/case_insensitive_tb.vhdl: case insensitive
- vhdl/whitespace_tb.vhdl: whitespace
- vhdl/literals_tb.vhdl: literals
- Flow control
- vhdl/procedure_tb.vhdl: procedure
- vhdl/function_tb.vhdl: function
- vhdl/operators_tb.vhdl: operators
- Types
- vhdl/integer_types_tb.vhdl: integer types
- vhdl/array_tb.vhdl: array
- vhdl/record_tb.vhdl.bak: record. TODO fails with "GHDL Bug occurred" on GHDL 1.0.0
- vhdl/generic_tb.vhdl: generic
- vhdl/package_test_tb.vhdl: Packages
- vhdl/standard_package_tb.vhdl: standard package
- textio
* vhdl/write_tb.vhdl: write
* vhdl/read_tb.vhdl: read - vhdl/std_logic_tb.vhdl: std_logic
- vhdl/stop_delta_tb.vhdl:
--stop-delta
- Basic
- Applications
- Combinatoric
- vhdl/adder.vhdl: adder
- vhdl/sqrt8_tb.vhdl: sqrt8
- Sequential
- vhdl/clock_tb.vhdl: clock
- vhdl/counter.vhdl: counter
- Combinatoric
- Helpers
* vhdl/template_tb.vhdl: template
gothinkster/realworld Updated 2025-07-16
Ahh, you can't have new ideas anymore!
Basically puts together every backend with Front-end web framework to create the exact same website.
The reference live demo can be found at: demo.realworld.io/#/ It is based on Angular.js as it links to: github.com/gothinkster/angularjs-realworld-example-app TODO backend?
There are however also live demos of other frontends, e.g.:Note that all those frontends communicate with the same backend.
- React: react-redux.realworld.io. But note that tag addition at post creation is broken there as of March 2021, but not on master: github.com/gothinkster/react-redux-realworld-example-app/issues/151#issuecomment-808417846 so they forgot to update the live server.
- Vue.js: vue-vuex-realworld.netlify.app
As of 2021 Devs are seemed a bit too focused on monetizing the project through their "how to use this project" premium tutorial, and documentation could be better: just getting the hello world of the most popular backend with the most popular frontend is not easy... come on.
github.com/gothinkster/realworld/issues/578 asks for community support, as devs have moved on since unfortunately.
Remember:
- by default, the frontends hardcode the upstream public data API:
https://conduit.productionready.io/apiso you have to hack their code to match the port of the backend. And each backend can have a different port. - when you switch between backends, you must first manually clear client-side storage cookies/local new run will fail due to authentication issues!
Important missing things from the minimum base app:
- server-side rendering:
- github.com/arrlancore/nextjs-ssr-real-world-app-example. As advertised, that global instance does render with JavaScript disabled! Proposed for upstream at: github.com/gothinkster/realworld/issues/423
- github.com/gothinkster/realworld/issues/266
- no javaScript bi-directional communication library built-in... come on: github.com/gothinkster/realworld/issues/107
- email notifications however as tested on the live demo: demo.realworld.io/#/
- error handling is broken/missing/inconsistent across apps
First you should the most popular backend/frontend combination running, which is the most likely to be working. We managed to run on Ubuntu 20.10, React + Node.js Express.js as described at github.com/gothinkster/node-express-realworld-example-app/pull/116:Then just:on both server and client, and then visit the client URL: localhost:4100/
- github.com/cirosantilli/node-express-realworld-example-app/tree/mongo4 which has a simple patch on top of github.com/gothinkster/node-express-realworld-example-app/tree/ba04b70c31af81ca7935096740a6e083563b3a4a for MongoDB 4 supportThis requires you to first install MongoDB on Ubuntu and ensure you can login to it from the command line.
- github.com/gothinkster/react-redux-realworld-example-app/tree/9186292054dc37567e707602a15a0884d6bdae35 patched to use the correct server host/port
localhost:3000:diff --git a/src/agent.js b/src/agent.js index adfbd72..e3cdc7f 100644 --- a/src/agent.js +++ b/src/agent.js @@ -3,7 +3,7 @@ import _superagent from 'superagent'; const superagent = superagentPromise(_superagent, global.Promise); -const API_ROOT = 'https://conduit.productionready.io/api'; +const API_ROOT = 'http://localhost:3030/api'; const encode = encodeURIComponent; const responseBody = res => res.body;
npm install
npm startYou have to hit the Enter key to add tags, it's terrible: github.com/gothinkster/react-redux-realworld-example-app/issues/151#issuecomment-808417846
One cool thing is that the main repo has unified backend API tests:so the per-repository tests are basically useless, and that single test can test everything for any backend! There is no frontend testing however: github.com/gothinkster/realworld/issues/269 so newb.
git clone https://github.com/gothinkster/realworld
cd realworld
git checkout e7adc6b06b459e578d7d4a6738c1c050598ba431
cd api
APIURL=http://localhost:3000/api USERNAME="u$(date +%s)" ./run-api-tests.sh How to hardcode subtitle into a video with FFmpeg? Updated 2025-07-16
To change font size: stackoverflow.com/questions/21363334/how-to-add-font-size-in-subtitles-in-ffmpeg-video-filterThe default appears to be 24, so just multiply that by whatever seems like a reasonable factor.
ffmpeg -i input.mp4 -vf "subtitles=subtitle.srt:force_style='Fontsize=64'" output.mp4Note howver that .ass subtitle files can contain style information, which ffmpeg respects. Aegisub can produce and preview such styles, making .ass one of the best options.